1. 학습한 내용
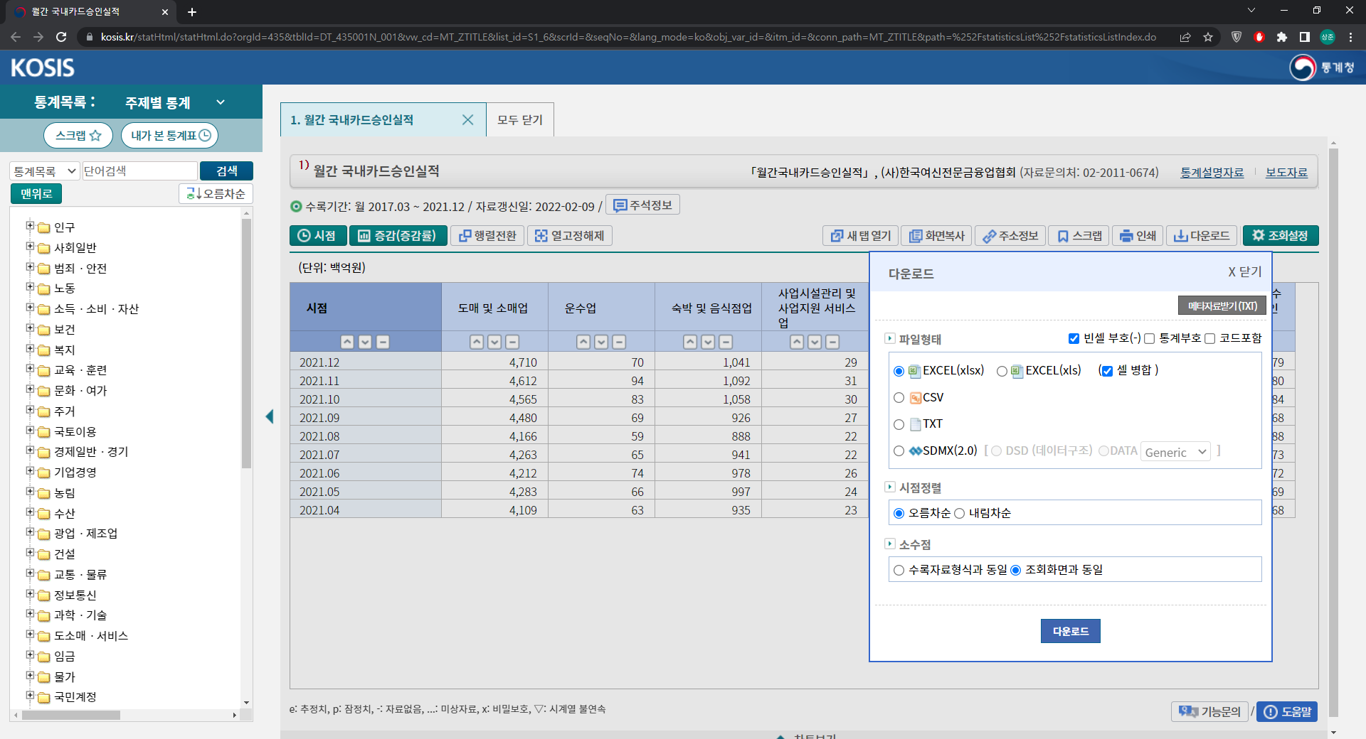
① KOSIS 국가통계포털
https://kosis.kr/index/index.do
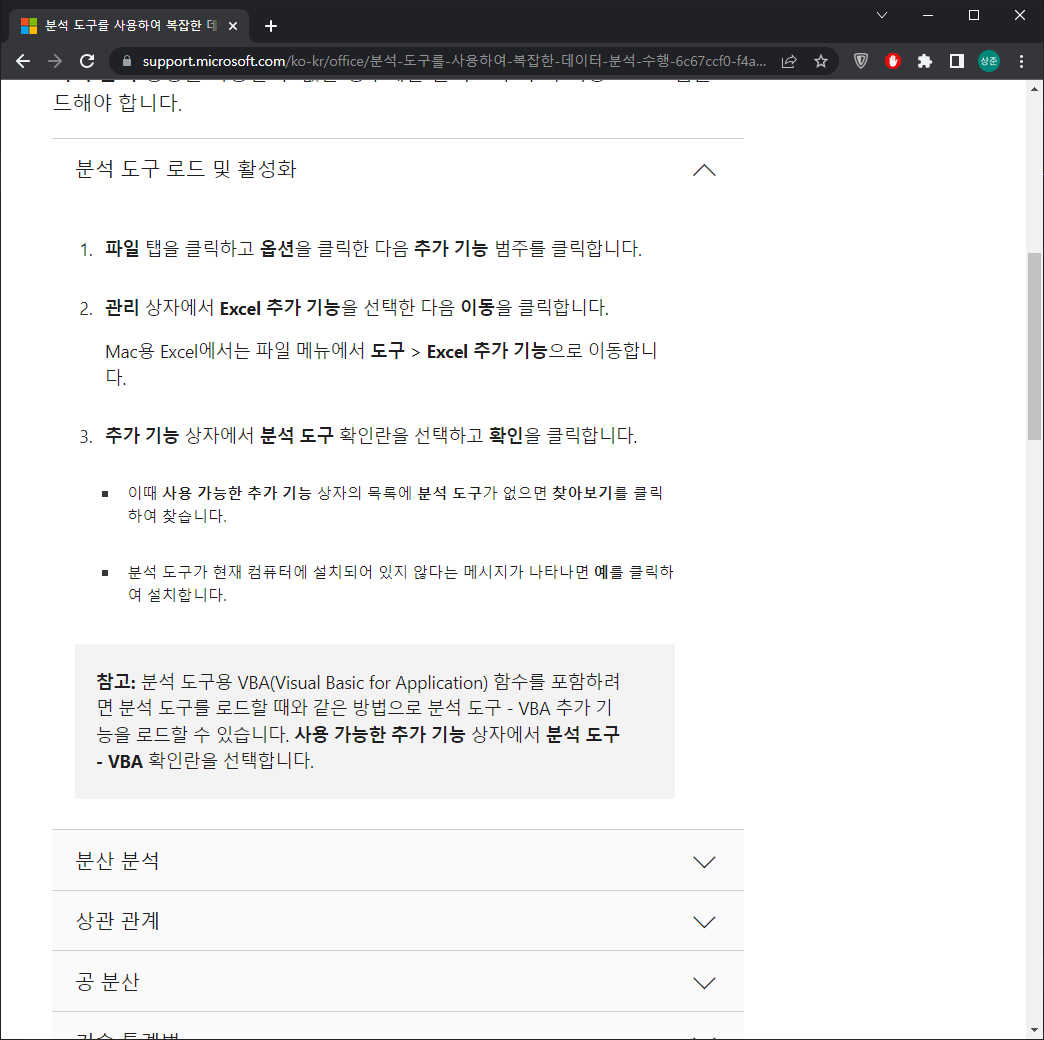
② 엑셀 데이터 분석
- 분석 도구 로드 및 활성화
③ Numpy
- Numpy 소개
NumPy(Numerical Python)는 파이썬에서 과학적 계산을 위한 핵심 라이브러리이다. NumPy는 다차원 배열 객체와 배열과 함께 작동하는 도구들을 제공한다. 하지만 NumPy 자체로는 고수준의 데이터 분석 기능을 제공하지 않기 때문에 NumPy 배열과 배열 기반 컴퓨팅의 이해를 통해 pandas와 같은 도구를 좀 더 효율적으로 사용하는 것이 필요하다.
import numpy as np
## ndarray 생성
arr = np.array([1,2,3,4])
print(arr)
# [1 2 3 4]
np.zeros((3,3))
# array([[0., 0., 0.],
# [0., 0., 0.],
# [0., 0., 0.]])
np.ones((2,2))
# array([[1., 1.],
# [1., 1.]])
np.empty((4,4))
# array([[2.05833592e-312, 2.33419537e-312, 0.00000000e+000, 0.00000000e+000],
# [0.00000000e+000, 0.00000000e+000, 0.00000000e+000, 0.00000000e+000],
# [0.00000000e+000, 0.00000000e+000, 0.00000000e+000, 0.00000000e+000],
# [0.00000000e+000, 0.00000000e+000, 0.00000000e+000, 0.00000000e+000]])
np.arange(10)
# array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
arr = np.array([[1,2,3,],[4,5,6]])
print(arr)
# [[1 2 3]
# [4 5 6]]
arr.shape
# (2, 3)
arr.ndim
# 2
arr.dtype
# dtype('int64')
arr_int = np.array([1,2,3,4])
arr_int.dtype
# dtype('int64')
arr_float = arr_int.astype(np.float64)
arr_float.dtype
# dtype('float64')
arr_str = np.array(['1','2','3'])
arr_str.dtype
# dtype('<U1')
arr_int = arr_str.astype(np.int64)
arr_int.dtype
# dtype('int64')
## 배열 연산
arr1 = np.array([[1,2],[3,4]])
arr2 = np.array([[5,6],[7,8]])
arr1 + arr2
# array([[ 6, 8],
# [10, 12]])
np.add(arr1, arr2)
# array([[ 6, 8],
# [10, 12]])
arr1 * arr2
# array([[ 5, 12],
# [21, 32]])
np.multiply(arr1, arr2)
# array([[ 5, 12],
# [21, 32]])
# dot 함수를 사용한 행렬의 곱 계산
arr1.dot(arr2) # 배열 객체의 인스턴스 메소드로 dot 함수 사용
# array([[19, 22],
# [43, 50]])
np.dot(arr1, arr2)
# array([[19, 22],
# [43, 50]])
## 배열 슬라이싱
arr = np.array([[1,2,3],[4,5,6],[7,8,9]])
arr_1 = arr[:2,1:3]
print(arr_1)
# [[2 3]
# [5 6]]
## 정수 배열 인덱싱
arr = np.array([[1,2,3],[4,5,6],[7,8,9]])
arr[0,2] #0행 2열 값에 접근
# 3
arr[[0,1,2],[2,0,1]] #0,1,2 행의 2,0,1열 값에 접근
# array([3, 4, 8])
## Boolean 배열 인덱싱
arr = np.array([[1,2,3],[4,5,6]])
idx = arr > 3 # arr에서 3보다 큰 값을 찾아서 같은 Shape의 True or False 값을 가진 배열로 생성
print(idx)
# [[False False False]
# [ True True True]]
print(arr[idx])
# [4 5 6]
##winequality-red.csv 파일 불러오기
redwine = np.loadtxt(fname = 'samples/winequality-red.csv', delimiter=';', skiprows = 1)
print(redwine)
# [[ 7.4 0.7 0. ... 0.56 9.4 5. ]
# [ 7.8 0.88 0. ... 0.68 9.8 5. ]
# [ 7.8 0.76 0.04 ... 0.65 9.8 5. ]
# ...
# [ 6.3 0.51 0.13 ... 0.75 11. 6. ]
# [ 5.9 0.645 0.12 ... 0.71 10.2 5. ]
# [ 6. 0.31 0.47 ... 0.66 11. 6. ]]
print(redwine.sum())
# 152084.78194
print(redwine.mean())
# 7.926036165311652
print(redwine.mean(axis=0))
# [ 8.31963727 0.52782051 0.27097561 2.5388055 0.08746654 15.87492183
# 46.46779237 0.99674668 3.3111132 0.65814884 10.42298311 5.63602251]
print(redwine[:,0].mean())
# 8.31963727329581
print(redwine.max(axis=0))
# [ 15.9 1.58 1. 15.5 0.611 72. 289.
# 1.00369 4.01 2. 14.9 8. ]
print(redwine.min(axis=0))
# [4.6 0.12 0. 0.9 0.012 1. 6. 0.99007 2.74
# 0.33 8.4 3. ]④ Pandas
Pandas에서 제공하는 데이터 자료구조는 Series와 Dataframe 두가지가 존재하는데 Series는 시계열과 유사한 데이터로서 index와 value가 존재하고 Dataframe은 딕셔너리데이터를 매트릭스 형태로 만들어 준 것 같은 frame을 가지고 있다. 이런 데이터 구조를 통해 시계열, 비시계열 데이터를 통합하여 다룰 수 있다.
- Series
from pandas import Series, DataFrame
import pandas as pd
fruit = Series([2500, 3800, 1200, 6000], index = ['apple', 'banana', 'pear', 'cherry'])
fruit
# apple 2500
# banana 3800
# pear 1200
# cherry 6000
# dtype: int64
### values index
fruit = Series([2500, 3800, 1200, 6000], index = ['apple', 'banana', 'pear', 'cherry'])
print(fruit.values)
# [2500 3800 1200 6000]
print(fruit.index)
# Index(['apple', 'banana', 'pear', 'cherry'], dtype='object')
### Seires()
fruitData = {'apple':2500, 'banana':3800, 'pear':1200, 'cherry':6000}
fruit = Series(fruitData)
type(fruitData)
# dict
type(fruit)
# pandas.core.series.Series
## name
fruit = Series([2500, 3800, 1200, 6000],index = ['apple','banana','pear','cherry'])
fruit.name = 'fruitPrice'
fruit.index.name = 'fruitName'
print(fruit)
# fruitName
# apple 2500
# banana 3800
# pear 1200
# cherry 6000
# Name: fruitPrice, dtype: int64- Dataframe
## Dataframe()
fruitData = {'fruitName':['apple','banana','cherry','pear'],
'fruitPrice': [2500,3800,6000,1200],
'num': [10,5,3,8]}
fruitFrame = DataFrame(fruitData)
print(fruitFrame)
# fruitName fruitPrice num
# 0 apple 2500 10
# 1 banana 3800 5
# 2 cherry 6000 3
# 3 pear 1200 8
## columns
fruitFrame = DataFrame(fruitData, columns = ['fruitPrice','num','fruitName'])
print(fruitFrame)
# fruitPrice num fruitName
# 0 2500 10 apple
# 1 3800 5 banana
# 2 6000 3 cherry
# 3 1200 8 pear
fruitFrame['fruitName']
# 0 apple
# 1 banana
# 2 cherry
# 3 pear
# Name: fruitName, dtype: object
fruitFrame.fruitName
# 0 apple
# 1 banana
# 2 cherry
# 3 pear
# Name: fruitName, dtype: object
fruitFrame['Year'] = 2016
print(fruitFrame)
# fruitPrice num fruitName Year
# 0 2500 10 apple 2016
# 1 3800 5 banana 2016
# 2 6000 3 cherry 2016
# 3 1200 8 pear 2016
variable = Series([4,2,1],index = [0,2,3])
fruitFrame['stock'] = variable
print(fruitFrame)
# fruitPrice num fruitName Year stock
# 0 2500 10 apple 2016 4.0
# 1 3800 5 banana 2016 NaN
# 2 6000 3 cherry 2016 2.0
# 3 1200 8 pear 2016 1.0- 자료 다루기
fruit = Series([2500,3800,1200,6000],index=['apple','banana','pear','cherry'])
new_fruit = fruit.drop('banana')
print(fruit)
# apple 2500
# banana 3800
# pear 1200
# cherry 6000
# dtype: int64
print(new_fruit)
# apple 2500
# pear 1200
# cherry 6000
# dtype: int64
fruitData = {'fruitName':['apple','banana','cherry','pear'],
'fruitPrice':[2500,3800,6000,1200],
'num':[10,5,3,8]}
fruitName = fruitData['fruitName']
fruitName
# ['apple', 'banana', 'cherry', 'pear']
fruitFrame = DataFrame(fruitData, index = fruitName, columns = ['fruitPrice','num'])
fruitFrame2 = fruitFrame.drop(['apple','cherry'])
print(fruitFrame)
# fruitPrice num
# apple 2500 10
# banana 3800 5
# cherry 6000 3
# pear 1200 8
print(fruitFrame2)
# fruitPrice num
# banana 3800 5
# pear 1200 8
fruitFrame3 = fruitFrame.drop('num', axis=1)
print(fruitFrame)
# fruitPrice num
# apple 2500 10
# banana 3800 5
# cherry 6000 3
# pear 1200 8
print(fruitFrame3)
# fruitPrice
# apple 2500
# banana 3800
# cherry 6000
# pear 1200- 항목 추출하기
fruit = Series([2500,3800,1200,6000],index=['apple','banana','pear','cherry'])
fruit['apple':'pear']
# apple 2500
# banana 3800
# pear 1200
# dtype: int64
fruitData = {'fruitName':['apple','banana','cherry','pear'],
'fruitPrice':[2500,3800,6000,1200],
'num':[10,5,3,8]}
fruitName = fruitData['fruitName']
fruitFrame = DataFrame(fruitData, index = fruitName, columns = ['fruitPrice','num'])
print(fruitFrame)
# fruitPrice num
# apple 2500 10
# banana 3800 5
# cherry 6000 3
# pear 1200 8
fruitFrame['fruitPrice']
# apple 2500
# banana 3800
# cherry 6000
# pear 1200
# Name: fruitPrice, dtype: int64
print(fruitFrame['apple':'banana'])
# fruitPrice num
# apple 2500 10
# banana 3800 5- 데이터의 기본연산
fruit1 = Series([5,9,10,3], index = ['apple','banana','cherry','pear'])
fruit2 = Series([3,2,9,5,10], index = ['apple','orange','banana','cherry','mango'])
print(fruit1)
# apple 5
# banana 9
# cherry 10
# pear 3
# dtype: int64
print(fruit2)
# apple 3
# orange 2
# banana 9
# cherry 5
# mango 10
# dtype: int64
fruit1 + fruit2
# apple 8.0
# banana 18.0
# cherry 15.0
# mango NaN
# orange NaN
# pear NaN
# dtype: float64
fruitData1 = {'Ohio' : [4,8,3,5],'Texas' : [0,1,2,3]}
fruitFrame1 = DataFrame(fruitData1,columns=['Ohio','Texas'],index = ['apple','banana','cherry','pear'])
fruitData2 = {'Ohio' : [3,0,2,1,7],'Colorado':[5,4,3,6,0]}
fruitFrame2 = DataFrame(fruitData2,columns =['Ohio','Colorado'],index = ['apple','orange','banana','cherry','mango'])
print(fruitFrame1)
# Ohio Texas
# apple 4 0
# banana 8 1
# cherry 3 2
# pear 5 3
print(fruitFrame2)
# Ohio Colorado
# apple 3 5
# orange 0 4
# banana 2 3
# cherry 1 6
# mango 7 0
print(fruitFrame1 + fruitFrame2)
# Colorado Ohio Texas
# apple NaN 7.0 NaN
# banana NaN 10.0 NaN
# cherry NaN 4.0 NaN
# mango NaN NaN NaN
# orange NaN NaN NaN
# pear NaN NaN NaN- 데이터의 정렬
fruit = Series([2500,3800,1200,6000],index=['apple','banana','pear','cherry'])
fruit.sort_values(ascending=False)
# cherry 6000
# banana 3800
# apple 2500
# pear 1200
# dtype: int64
fruitData = {'fruitName':['pear','banana','apple','cherry'],
'fruitPrice':[2500,3800,6000,1200],
'num':[10,5,3,8]}
fruitName = fruitData['fruitName']
fruitFrame = DataFrame(fruitData, index = fruitName, columns = ['num','fruitPrice'])
print(fruitFrame)
# num fruitPrice
# pear 10 2500
# banana 5 3800
# apple 3 6000
# cherry 8 1200
print(fruitFrame.sort_index())
# num fruitPrice
# apple 3 6000
# banana 5 3800
# cherry 8 1200
# pear 10 2500
print(fruitFrame.sort_index(axis = 1))
# fruitPrice num
# pear 2500 10
# banana 3800 5
# apple 6000 3
# cherry 1200 8
print(fruitFrame.sort_values(by=['fruitPrice']))
# num fruitPrice
# cherry 8 1200
# pear 10 2500
# banana 5 3800
# apple 3 6000- 기초분석
german = pd.read_csv('http://freakonometrics.free.fr/german_credit.csv')
list(german.columns.values)
# ['Creditability',
# 'Account Balance',
# 'Duration of Credit (month)',
# 'Payment Status of Previous Credit',
# 'Purpose',
# 'Credit Amount',
# 'Value Savings/Stocks',
# 'Length of current employment',
# 'Instalment per cent',
# 'Sex & Marital Status',
# 'Guarantors',
# 'Duration in Current address',
# 'Most valuable available asset',
# 'Age (years)',
# 'Concurrent Credits',
# 'Type of apartment',
# 'No of Credits at this Bank',
# 'Occupation',
# 'No of dependents',
# 'Telephone',
# 'Foreign Worker']
german_sample=german[['Creditability','Duration of Credit (month)','Purpose','Credit Amount']]
print(german_sample)
# Creditability Duration of Credit (month) Purpose Credit Amount
# 0 1 18 2 1049
# 1 1 9 0 2799
# 2 1 12 9 841
# 3 1 12 0 2122
# 4 1 12 0 2171
# .. ... ... ... ...
# 995 0 24 3 1987
# 996 0 24 0 2303
# 997 0 21 0 12680
# 998 0 12 3 6468
# 999 0 30 2 6350
#
# [1000 rows x 4 columns]
german_sample.min()
# Creditability 0
# Duration of Credit (month) 4
# Purpose 0
# Credit Amount 250
# dtype: int64
german_sample.max()
# Creditability 1
# Duration of Credit (month) 72
# Purpose 10
# Credit Amount 18424
# dtype: int64
german_sample.mean()
# Creditability 0.700
# Duration of Credit (month) 20.903
# Purpose 2.828
# Credit Amount 3271.248
# dtype: float64
#요약통계
german_sample.describe
# <bound method NDFrame.describe of Creditability Duration of Credit (month) Purpose Credit Amount
# 0 1 18 2 1049
# 1 1 9 0 2799
# 2 1 12 9 841
# 3 1 12 0 2122
# 4 1 12 0 2171
# .. ... ... ... ...
# 995 0 24 3 1987
# 996 0 24 0 2303
# 997 0 21 0 12680
# 998 0 12 3 6468
# 999 0 30 2 6350
#
# [1000 rows x 4 columns]>- 상관관계와 공분산
german_sample=german[['Duration of Credit (month)','Credit Amount','Age (years)']]
print(german_sample.head())
# Duration of Credit (month) Credit Amount Age (years)
# 0 18 1049 21
# 1 9 2799 36
# 2 12 841 23
# 3 12 2122 39
# 4 12 2171 38
#상관계수
print(german_sample.corr())
# Duration of Credit (month) Credit Amount \
# Duration of Credit (month) 1.000000 0.624988
# Credit Amount 0.624988 1.000000
# Age (years) -0.037550 0.032273
#
# Age (years)
# Duration of Credit (month) -0.037550
# Credit Amount 0.032273
# Age (years) 1.000000
#공분산
print(german_sample.cov())
# Duration of Credit (month) Credit Amount \
# Duration of Credit (month) 145.415006 2.127401e+04
# Credit Amount 21274.007063 7.967927e+06
# Age (years) -5.140567 1.034203e+03
#
# Age (years)
# Duration of Credit (month) -5.140567
# Credit Amount 1034.202787
# Age (years) 128.883119- Group by를 이용한 계산 및 요약 통계
german_sample = german[['Credit Amount','Type of apartment']]
print(german_sample)
# Credit Amount Type of apartment
# 0 1049 1
# 1 2799 1
# 2 841 1
# 3 2122 1
# 4 2171 2
# .. ... ...
# 995 1987 1
# 996 2303 2
# 997 12680 3
# 998 6468 2
# 999 6350 2
#
# [1000 rows x 2 columns]
german_grouped = german_sample['Credit Amount'].groupby(german_sample['Type of apartment'])
german_grouped.mean()
# Type of apartment
# 1 3122.553073
# 2 3067.257703
# 3 4881.205607
# Name: Credit Amount, dtype: float64
german_sample = german[['Credit Amount','Type of apartment','Purpose']]
german_grouped2=german_sample['Credit Amount'].groupby([german_sample['Purpose'],german_sample['Type of apartment']])
german_grouped2.mean()
# Purpose Type of apartment
# 0 1 2597.225000
# 2 2811.024242
# 3 5138.689655
# 1 1 5037.086957
# 2 4915.222222
# 3 6609.923077
# 2 1 2727.354167
# 2 3107.450820
# 3 4100.181818
# 3 1 2199.763158
# 2 2540.533040
# 3 2417.333333
# 4 1 1255.500000
# 2 1546.500000
# 5 1 1522.000000
# 2 2866.000000
# 3 2750.666667
# 6 1 3156.444444
# 2 2492.423077
# 3 4387.266667
# 8 1 902.000000
# 2 1243.875000
# 9 1 5614.125000
# 2 3800.592105
# 3 4931.800000
# 10 2 8576.111111
# 3 7109.000000
# Name: Credit Amount, dtype: float642. 학습내용 중 어려웠던 점
- Nothing
3. 해결방법
- Nothing
4. 학습소감
- Microsoft MVP 김영욱 강사님의 강의 내용을 들을 수 있어서 영광입니다.

daegu-ai-school