본 포스팅은 스스로 공부한 내용을 정리하고 기록하기 위하여 올리는 내용이며, 잘못된 내용이 있을 수도 있음을 미리 밝힙니다. 잘못된 내용이 있거나, 더 좋은 방법이 있다면 댓글로 남겨주시기 바랍니다.
대용량 데이터에서 조회 성능 이슈
- PostRepository
JDBC를 사용하였습니다.
public void bulkInsert(List<Post> posts) throws SQLException {
String sql = """
INSERT INTO post (memberId, contents, createdDate, createdAt)
VALUES (?, ?, ?, ?)
""";
try (Connection con = DBConnectionUtil.getConnection();
PreparedStatement pstmt = con.prepareStatement(sql)) {
for (Post post : posts) {
pstmt.setLong(1, post.getMemberId());
pstmt.setString(2, post.getContents());
LocalDate createdDate = post.getCreatedDate();
if (createdDate != null) {
pstmt.setDate(3, Date.valueOf(createdDate));
} else {
pstmt.setDate(3, null);
}
LocalDateTime createdAt = post.getCreatedAt();
if (createdAt != null) {
pstmt.setTimestamp(4, Timestamp.valueOf(createdAt));
} else {
pstmt.setTimestamp(4, null);
}
pstmt.addBatch();
}
pstmt.executeBatch();
} catch (SQLException e) {
log.error("db error", e);
throw e;
}
}
- PostBulkInsertTest
EasyRandom을 사용하였습니다.
@Test
public void bulkInsert() throws SQLException {
var easyRandom = PostFixtureFactory.get(
3L,
LocalDate.of(1970, 1, 1),
LocalDate.of(2022, 4, 1)
);
var stopWatch = new StopWatch();
stopWatch.start();
int _1만 = 10000;
var posts = IntStream.range(0, _1만 * 100)
.parallel()
.mapToObj(i -> easyRandom.nextObject(Post.class))
.toList();
stopWatch.stop();
System.out.println("객체 생성 시간 : " + stopWatch.getTotalTimeSeconds());
var queryStopWatch = new StopWatch();
queryStopWatch.start();
postRepository.bulkInsert(posts);
queryStopWatch.stop();
System.out.println("DB 인서트 시간 : " + queryStopWatch.getTotalTimeSeconds());
}대용량 데이터에서 조회 성능을 확인하기 위하여 bulkInsert 함수를 구현하여 4백만 건의 데이터를 insert 해주었습니다.
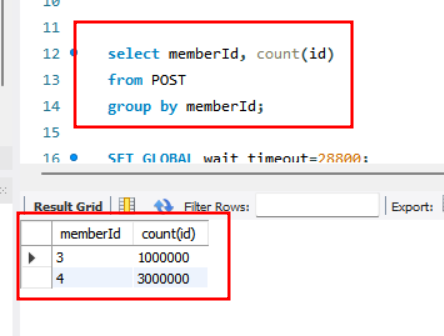
memberId=3 에 1백만건, memberId=4 에 3백만건의 데이터를 insert 해주었습니다.
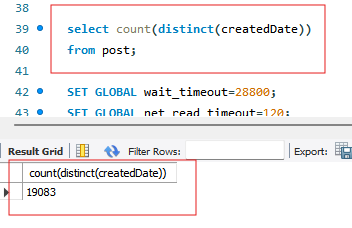
createdDate의 날짜는 1970년 부터 2022년 사이에 골고루 분포하도록 데이터를 insert 해주었습니다.
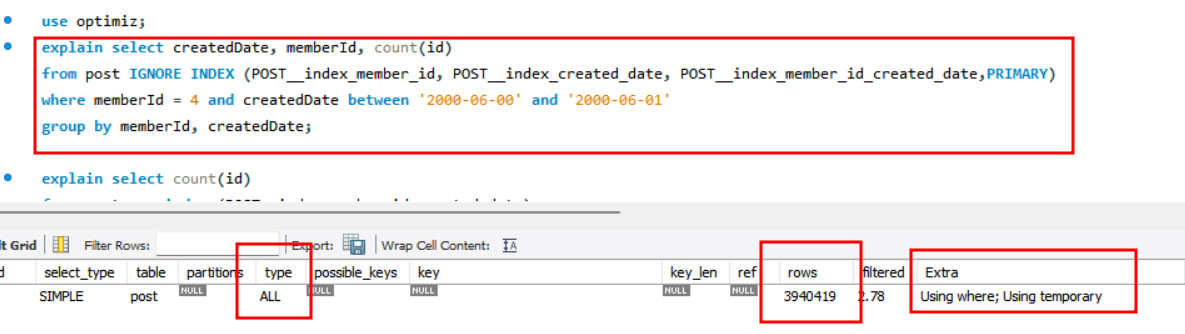
explain 키워드를 통해 탐색한 데이터의 개수를 측정하였습니다.
index를 사용하지 않았기 때문에 ALL type으로 거의 모든 데이터를 탐색하였습니다.
해결과정

각각 memberId, createdDate, memeberId+createdDate 로 index 를 만들어주었습니다.
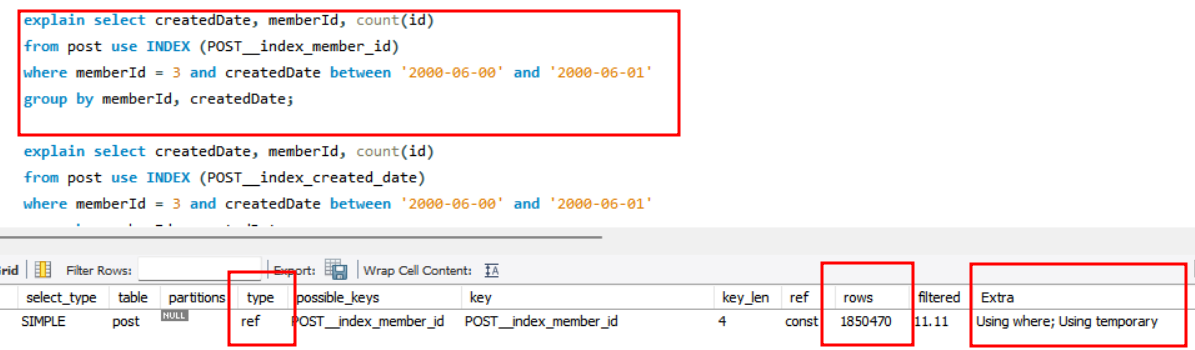
memberId 를 인덱스 키로 지정하였을 경우에는 ref type 으로 변경이되었지만, memberId =3 에 해당하는 값이 1백만건이나 되므로 인덱스를 활용하지 않고 여전히 많은 수의 레코드를 조회하는 것을 확인할 수 있었습니다.
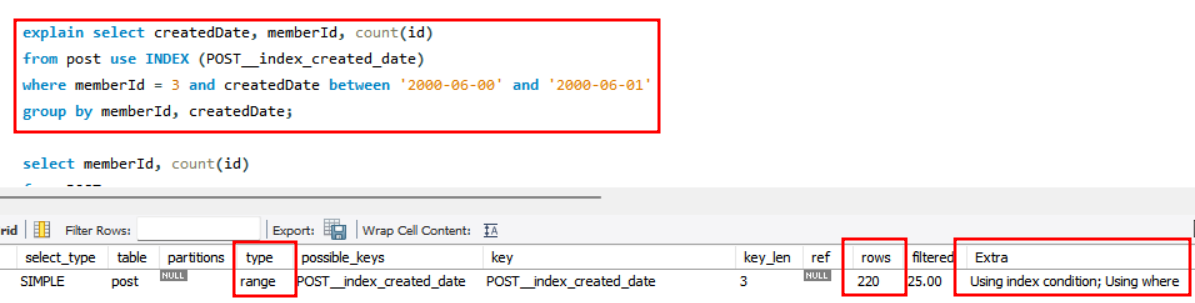
createdDate를 인덱스 키로 지정하였을 경우에는, range type, 220개의 레코드를 조회하는 것을 확인할 수 있었습니다. 이는 createdDate 의 카디널리티가 19000정도이므로, 4백만/19000 = 210 개의 레코드만 조회해도 되기 때문입니다.
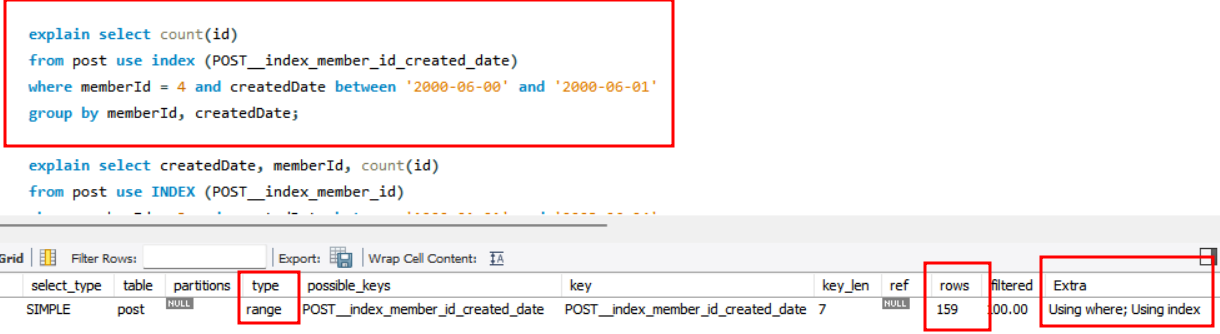
memberId와 createdDate를 복합키로 사용했을때 range type , 159개의 레코드를 탐색하는 것을 확인하였습니다.
복합키를 사용하여 커버링인덱스를 사용하였을때 가장 최적화된 쿼리 실행이 가능한것을 확인하였습니다.
