문제 상황
작업을 하다가 준실시간 성 데이터를 주기적으로 저장해야 할 일이 생겼다. 보통 이런 일이 있으면 따로 마련된 redis 나 MongoDB 등의 저장소에 저장하는 것이 일반적이다. 하지만 여기서 문제가 생겼다. 데이터를 저장해야 하는 주기가 매우 짧았고 (2초에 1번 혹은 10초에 1번) 저장해야 하는 데이터의 크기도 작지 않아서 DB에 적지 않은 무리가 갔던 것이다. 이렇게 I/O 하는 데이터의 횟수도 많고 크기도 많은데 DB를 써야할까 하는 의문이 생겼고 결국엔 로컬 메모리에 저장해보자! 라는 결론을 내리게 됐다.
이 서버는 kubernetes 위에서 돌아가고 있었고 많은 노드로 구성되어 있었으므로 로컬 메모리에 저장하기 위해서는 pod 간의 통신이 필수적이었다. 예를 들어서 A-1이라는 데이터를 a 라는 pod가 가지고 있다면 A-2 라는 데이터가 b pod에 도착했을 때 a pod 로 전송하는 작업이 필요했었던 것이다. 이 알고리즘을 적용했던 이야기를 해보려고 한다.
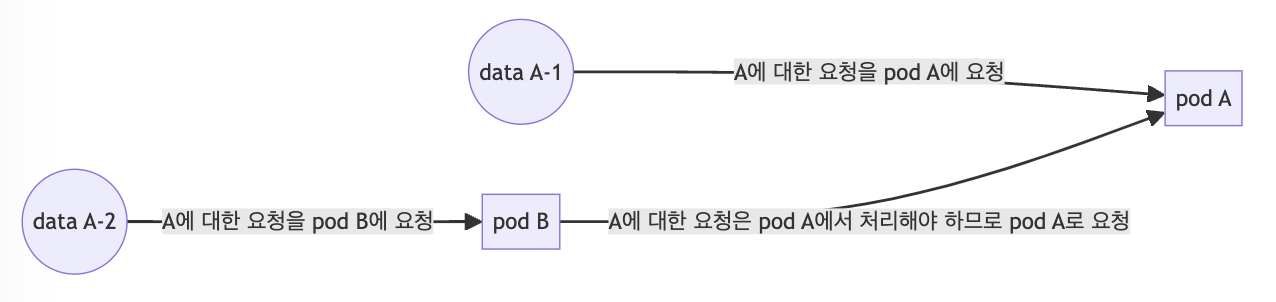
kubernetes pod to pod communication이란?
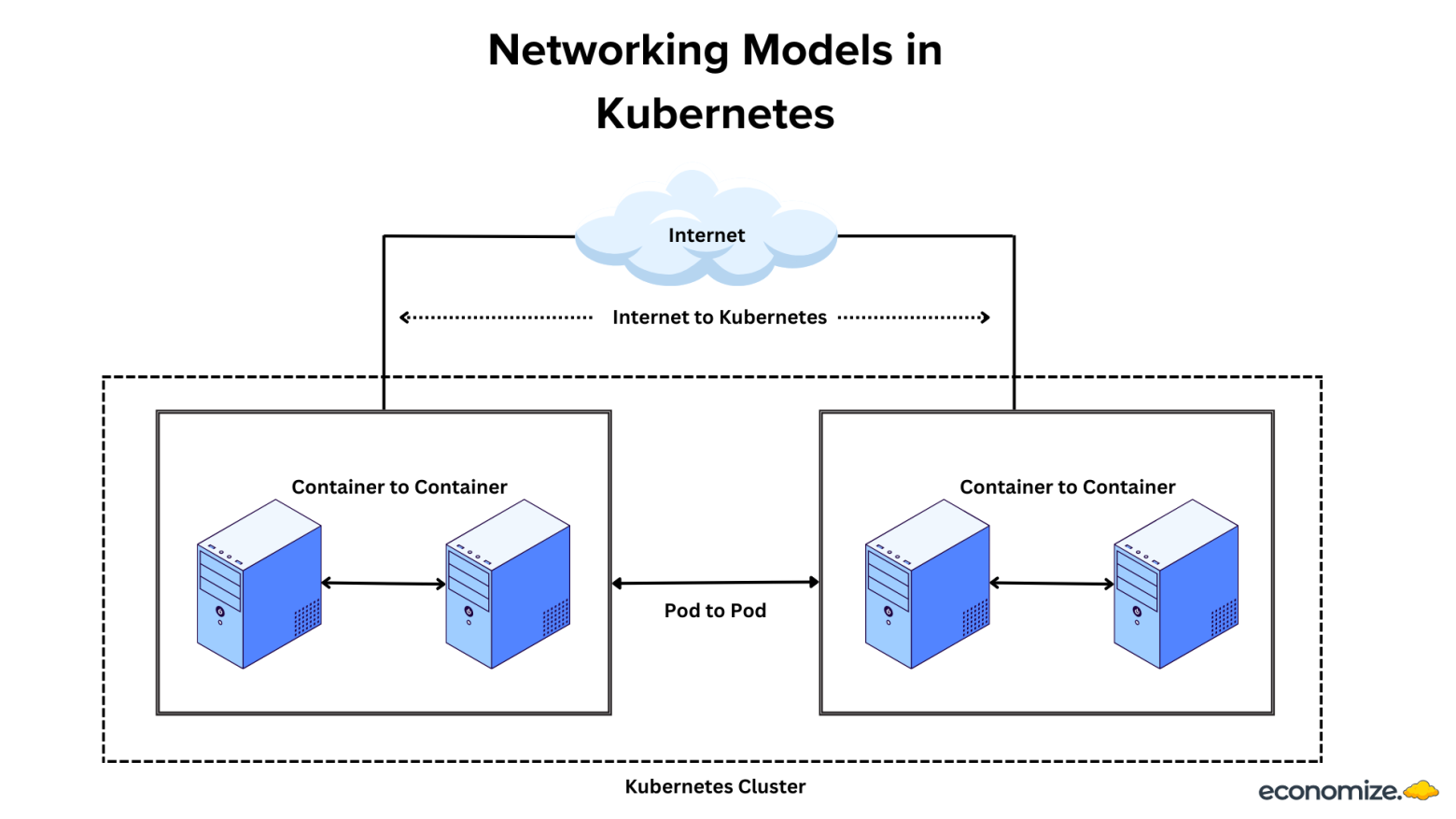
쿠버네티스 내부의 pod 들은 각각의 ip 주소를 할당받는다. 해당 ip 주소를 이용해서 pod에 접근하는 기법이다. 말 그대로 ip 주소를 통해 직접 접근하므로 매우 직관적인 방법이라고 생각한다. 하지만 다른 노드에 존재하는 pod에 접근할 경우 해당 노드를 경유해야 한다.
구현 방법
코드를 설명하기 보다는 알고리즘 위주로 설명을 해볼까 한다. 간단하게 먼저 개괄적으로 설명하자면 Redis에 pod의 ip 주소와 해당 pod에 저장될 데이터에 대한 정보를 함께 저장한다. 이후 데이터에 대한 요청이 들어올 때마다 어떤 pod에서 처리될지 Redis를 보고 판단해야 하므로 이 Redis가 굉장히 중요한 역할을 한다. 그림과 함께 상세 설명을 해보면 아래와 같다.
1. Redis에 매핑 정보 저장
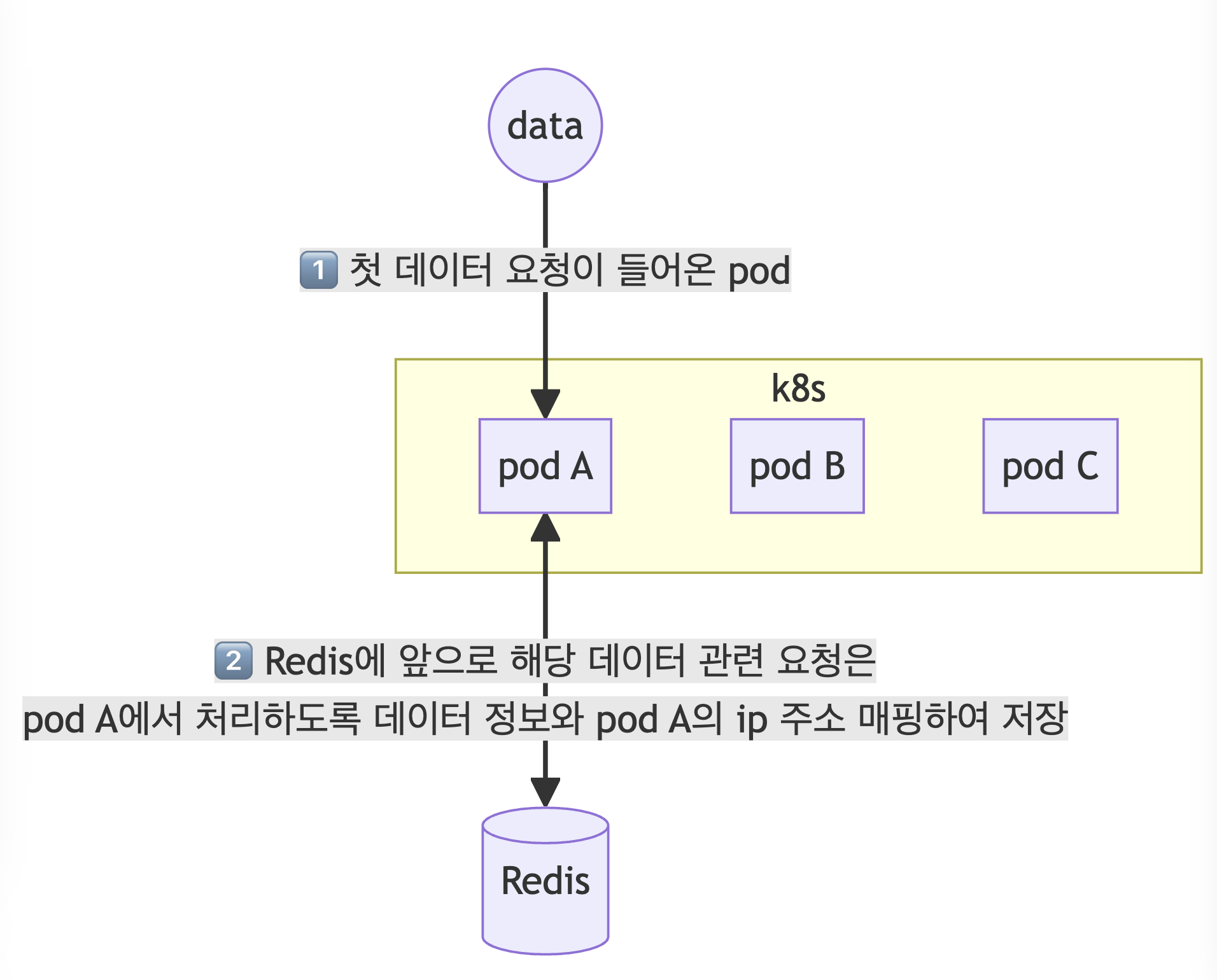
kubernetes 에 어떤 데이터에 대한 첫 요청이 들어올 경우 관련 정보는 해당 pod의 ip 정보와 함께 Redis에 저장된다.
2. 매핑된 pod로 데이터 라우팅
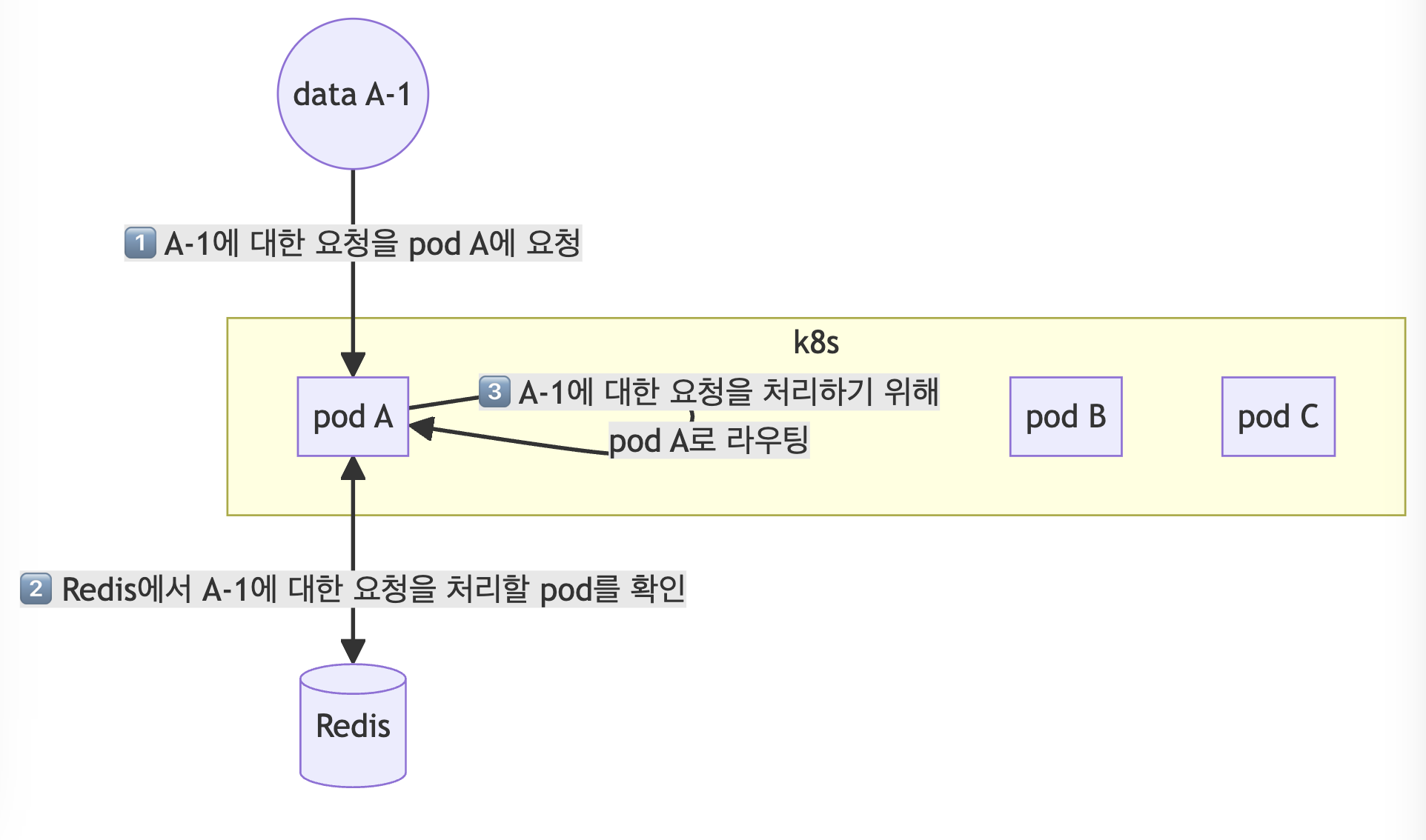
pod A 에서 처리할 요청이 pod A 로 왔다면 이를 Redis를 이용해서 확인한 후 재라우팅 해서 처리한다.
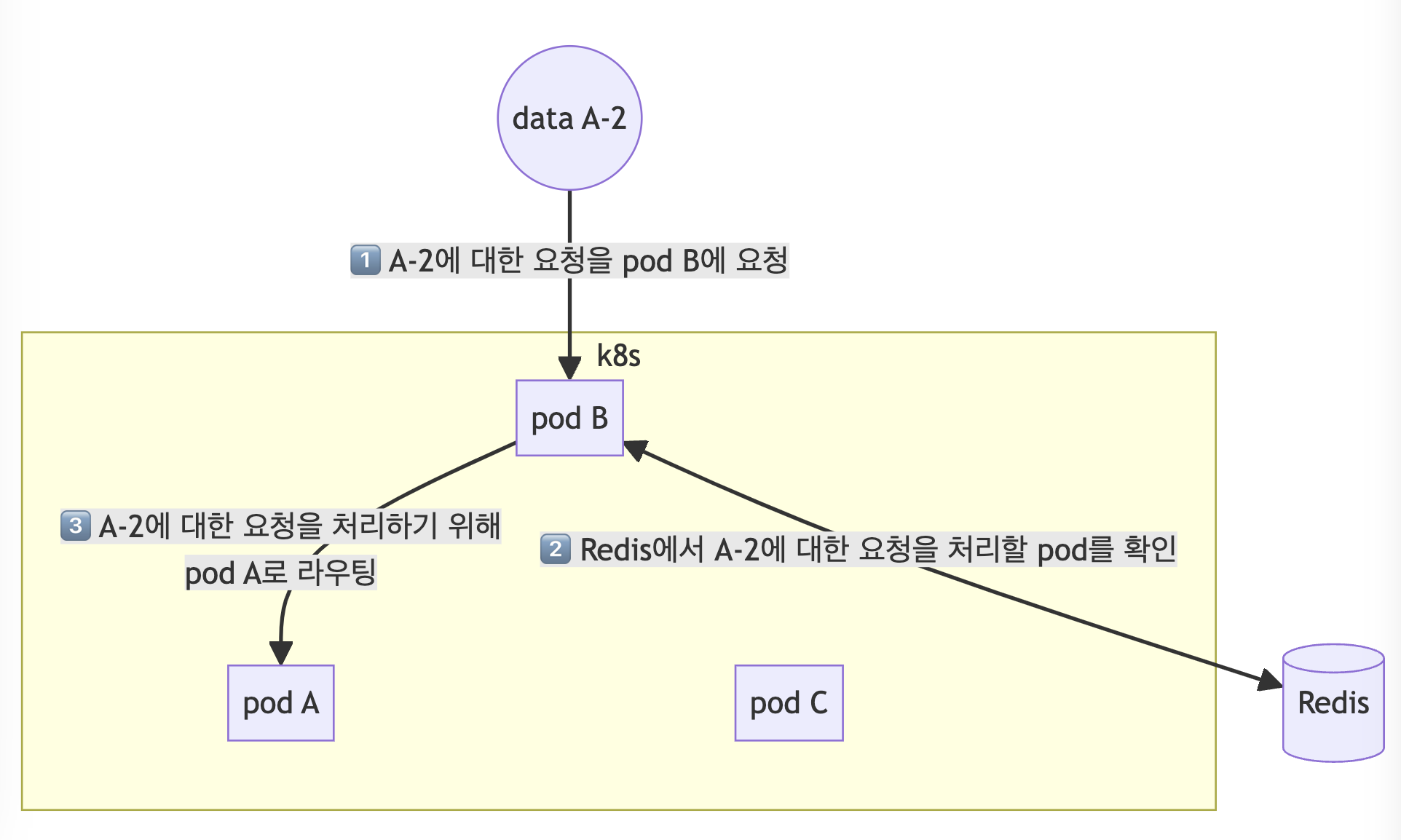
pod A 에서 처리할 요청이 pod B 로 왔다면 마찬가지로 Redis를 이용해서 라우팅될 pod의 ip 주소를 확인한 후 해당 pod으로 라우팅한다.
후기
- kubernetes 안에서 pod 끼리 데이터를 주고 받는다는 개념이 생소했는데 적용해보니 어렵지 않았고 이를 이용해서 저장소를 사용하지 않으니 저장소에 대한 관리 포인트가 하나 줄어 유지보수가 용이해져서 알맞은 최적화 기법이었다고 생각한다.
- 다만 로컬 메모리가 데이터를 저장하기에 최적화된 장소는 아니므로 다양한 케이스에 대한 방어 코드 작업을 해야 했다. 예를 들면 갑자기 pod이 종료되는 등의 상황으로 데이터가 유실되었을 때의 처리 혹은 데이터가 계속 남아있을 때의 처리를 해야 했다.
- 로컬 메모리의 사용량이 매우 커져서 배포할 때 메모리 부족으로 pod 이 죽기도 했다. 그래서 쿠버네티스의 메모리 상황을 모니터링하며 jvm heap과 pod의 메모리 사용량을 조절해야 했다.
- 기존의 Redis나 Mongo 등의 저장소에 저장할 때 높은 IO 횟수와 상대적으로 큰 IO하는 데이터 크기로 저장소의 스펙이 매우 커지고 장애 위험도 컸었는데 이를 줄인 것만으로 큰 수확이었다.
참고 자료
- kubernetes cluster networking : https://kubernetes.io/docs/concepts/cluster-administration/networking/
- The 4 Types of Kubernetes Cluster Networking Models Explained : https://blog.economize.cloud/kubernetes-cluster-networking-types/#elementor-toc__heading-anchor-3
