📍 데이터 유형
✔️ 변수
공통의 측정 방법으로 얻은 같은 성질의 값이다.
즉, 똑같은 기준과 도구를 사용해 조사하여 측정 대상마다 결과값이 다르게 나오는 것을 의미한다.
한 번에 몇 개의 변수를 보느냐에 따라 n변수라고 표현한다.
- 차원
데이터를 좌표 공간으로 생각하면 변수를 차원이라 칭할 수 있다.
1차원은 직선, 2차원은 평면, 3차원은 공간으로 표현할 수 있으나,
3차원 초과로 넘어간 차원은 표현하기 어려워지기 때문에 조심해야 한다.
- 차원의 저주
차원이 많아질수록 데이터 공간이 커져 패턴을 찾기가 어려워지는 것을 말한다.
상술하였듯 3차원이 넘어가면 표현 및 패턴 찾기가 어려워지므로 그 이상으로 차원을 늘리지 않을 수 있도록 변수 조정에 신경 써야 한다.
📍 데이터 분포
대략적인 데이터의 경향을 파악할 수 있게 해 주는 값이다.
✔️ 이산형 양적 변수
가로축은 숫자, 세로축은 데이터의 개수(빈도 등)을 표기하는 변수이다.
ex) 주사위 던진 횟수 등
✔️ 연속형 양적 변수
구간폭(범위)에 따라 표현이 달라지므로 적절한 범위를 가로축에 포함하여 사용해야 한다.
ex) 키 분포
✔️ 범주형 변수
가로축에는 각 범주, 세로축에는 범주에 속하는 개수를 표기한다.
ex) 좋아하는 메뉴
📍 통계량
수집한 데이터로 계산을 수행하여 얻은 값을 말한다.
✔️ 기술통계량
데이터 그 자체의 성질을 기술 및 요약하는 통계량을 말한다.
대푯값으로 평균/중앙값/최빈값을 가지며,
데이터 퍼짐 정도를 나타내는 것은 분산/표준편차가 있다.
- 평균값
모든 값을 더한 뒤 값의 개수로 나눈 값이다.
- 중앙값
크기 순으로 값을 정렬했을 때 한가운데 위치하는 값이다.
데이터 개수가 홀수라면 정중앙,
짝수라면 정중앙의 두 개의 숫자의 평균이 중앙값이 된다.
- 최빈값
데이터 중 가장 자주 나타나는 값이다.
- 분산
표본의 각 값과 평균이 어느 정도 떨어져 있는지 평가하는 것이다.
데이터의 퍼짐 상태를 정량화하는 역할을 한다.
- 표준편차
분산에 제곱근을 취한 값이다.
극단적인 성질 파악 없이 원래 단위와 일치해 정량화된 지표로 알기 쉽게 표현된다.
가진 특징이 분산과 비슷한 경향을 보인다.
💡 분산, 표준편차 특징
(측정값) - (평균) / (데이터 개수) 이므로 항상 0보다 큰 값을 가지며,
모든 값이 같다면 분포가 없는 것과 같으므로 분포가 0이 된다.
또한 데이터 퍼짐 정도가 크다면 분포값이 커진다.
✔️ 이상값
드물게 극단적으로 나타나는 큰 값이나 작은 값이다.
평균값 및 표준편차와 2-3배 차이 나는 형태를 보인다.
평균값은 모든 값을 고려하기 때문에 이상치의 영향을 많이 받으므로,
상대적인 크기인 중앙값이나 빈도가 낮은 최빈값을 사용하는 것이 좋다.
📍 분포 시각화 방법
✔️ 상자 수염 그림
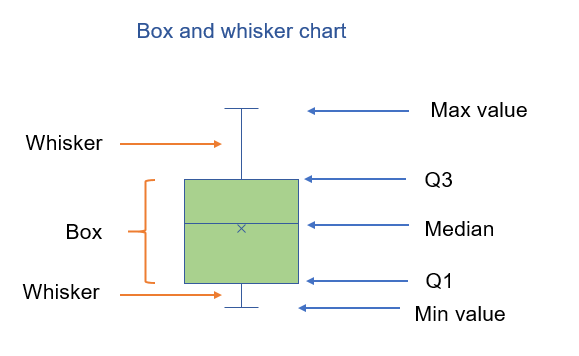
상자와 수염으로 구성돼 있으며 각각 데이터 분포를 특정 짓는 통계량을 나타낸다.
Q1인 1사분위 수는 큰 쪽 부터 세었을 때 1/4 위치에 있는 값이며,
Q3인 3사분위 수는 작은 쪽 부터 세었을 때 1/4 위치에 있는 값을 말한다.
상위 절반과 하위 절반을 나눈 위치의 제 2사분위 수는 중앙값을 지칭한다.
상하위로 길게 늘어진 수염은 상자 길이(Q1 - Q3)의 1.5배를 늘인 범위 안에서의 최대/최소값을 나타낸다.
최대/최소값 내에 포함되지 않는 부분을 이상치라고 하며 동그란 점으로 퍼지게 표현된다.
✔️ 막대 그래프 오차 막대
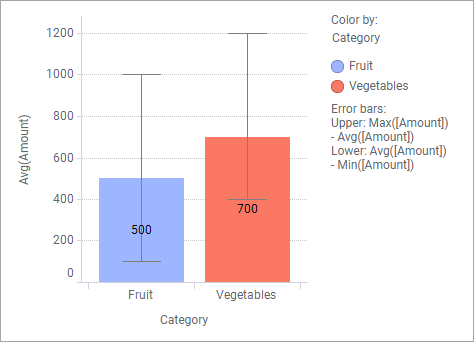
막대 그래프 높이로 나타내고 표준편차를 평균값에서 아래위로 늘려 표기한다.
✔️ 바이올린 플롯
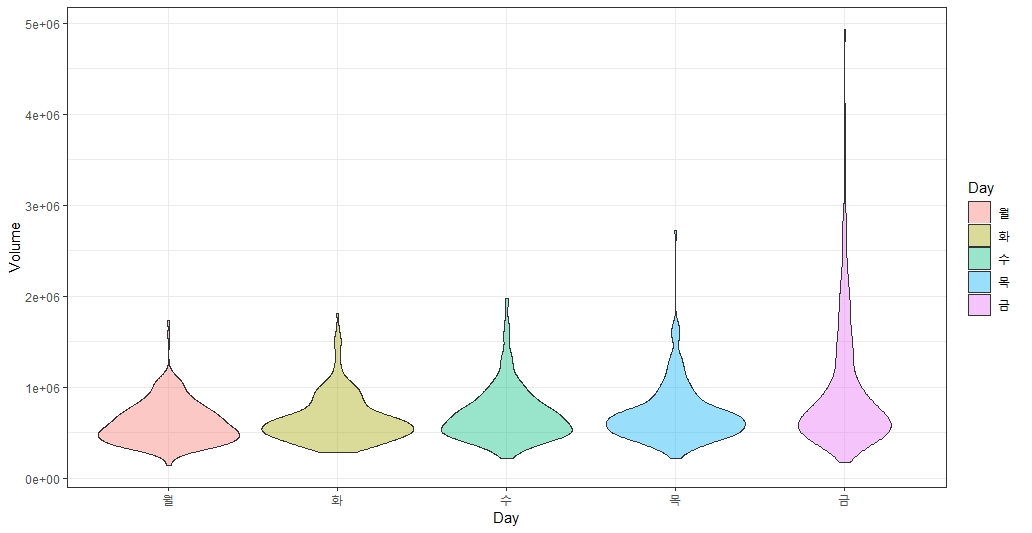
히스토그램을 부드럽게 표현한 것이며,
어디쯤에 데이터가 존재하기 쉬운지 추정할 수 있다.
✔️ 스웜 플롯
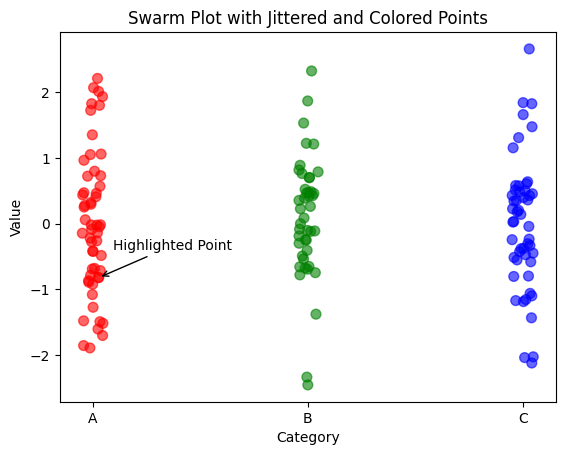
값이 겹치지 않도록 점을 찍어 각 데이터가 어디에 있는지 자세하게 나타낸다.
평균값/중앙값은 알 수 없으나 분포 형태나 자세한 위치 정보를 확인할 수 있다.
✔️ 스웜 플롯 + 상자 수염 그림
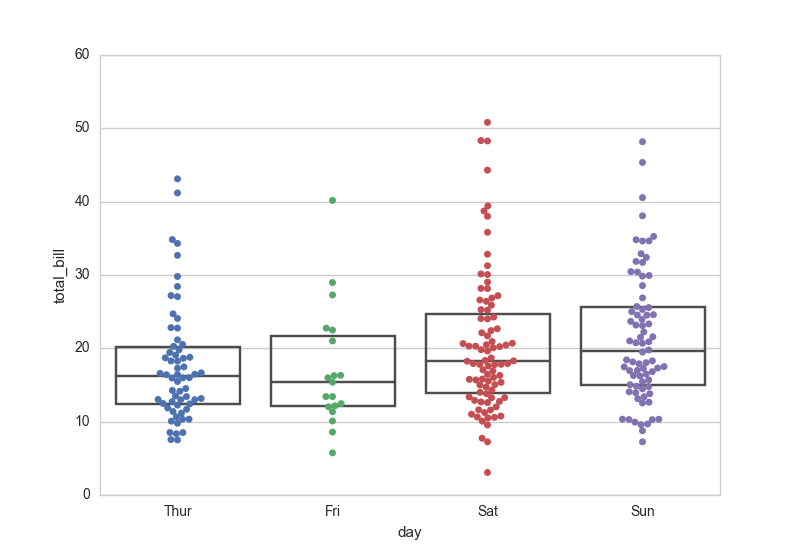
평균값/중앙값이 없는 스웜 플롯의 단점을 보완,
통계량 나타내는 박스플롯과 함께 표기해
데이터가 어디에 위치해 있는지 자세하게 나타냄과 동시에 통계량도 확인이 가능하다.
📍 확률
발생 여부가 불확실한 사건의 발생 가능성을 숫자로 표현한 것이다.
✔️ 확률변수
X와 같이 확률이 달라지는 변수다.
✔️ 실현값
확률변수가 실제로 취하는 값이다.
✔️ 확률분포
가로축에 확률변수, 세로축에 발생 가능성을 표기한 분포이다.
이산형일 경우 세로축이 확률 그 자체이며,
연속형일 때는 값에 범위를 두고 구한다.
범주형일 경우 가로축 순서에 의미가 없다.
- 확률밀도함수
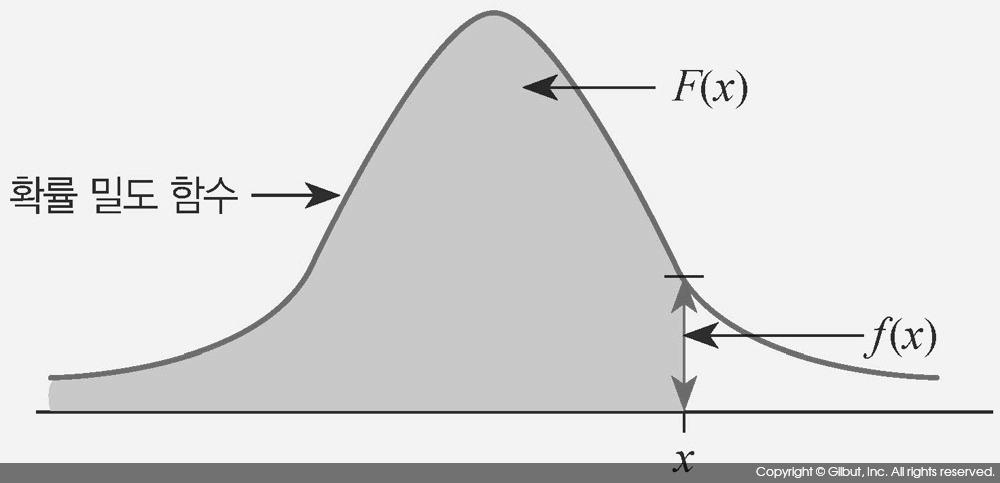
상대적인 발생 가능성을 말하며, 연속형일 때 사용한다.
범위에 속할 확률을 구하고 싶다면 적분 후 넓이를 구하는 것이 방법이다.
💡 확률분포의 중요성
추론통계는 표본에서 모집단의 성질을 추정하기 때문에 관측과 이해에 어려움이 있다.
현실의 모집단을 수학의 확률분포로 / 표본을 실현값으로 가정해 분석하여
다루기 어려운 대상을 쉬운 대상으로 치환해 추정함으로써 모집단 이해를 쉽게 할 수 있다.
✔️ 기댓값
변수가 확률적으로 얼마나 발생하기 쉬운지 평균적인 값으로 나타낸 것이다.
확률이 가중치 역할을 하는 평균을 구하는 것이라 할 수 있다.
이산형일 경우 각 실현값과 실현값이 발생할 확률을 곱하여 더하여 계산하고,
연속형일 경우 실현값 x 와 그에 대응하는 확률밀도를 곱한 후 적분하여 계산한다.
- 분산
확률분포가 기댓값 주변에 얼마나 퍼져 있는지 나타내는 값이다.
기댓값과 차이를 제곱한 숫자로 판단하며,
이산형일 경우 실현값에서 기댓값을 빼어 제곱한 값과 각 실현값의 확률을 곱하여 계산하고,
연속형일 경우 실현값에서 기댓값을 빼어 제곱한 값과 그에 대응하는 확률밀도를 곱해 적분하여 계산한다.
- 표준편차
단순히 분산에 제곱근을 취한 값이다.
💡 분산 표준편차 특징
각 값이 0 이상이어야 하며,
모두 같은 값이 나타나는 경우 퍼짐이 없다는 뜻이므로 0이다.
기댓값에서 떨어진 값이 많을수록 값이 커진다.
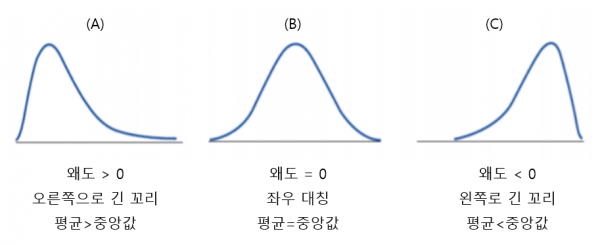
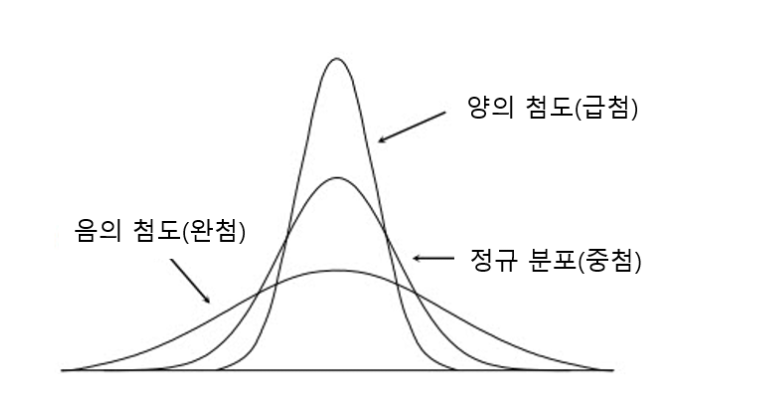
💡 왜도와 첨도
- 왜도
분포가 좌우대칭에서 얼마큼 벗어나 있는지를 나타낸다.- 첨도
분포가 얼마나 뾰족한지, 그래프 꼬리가 차지하는 비율의 크기를 나타낸다.
✔️ 동시확률분포
확률변수 2개를 동시에 생각할 때의 확률분포
한쪽이 어떤 값을 취하든 다른 한쪽의 확률은 변하지 않는 독립 관계다.
P(X,Y) = P(X) x P(Y)
두 변수가 동시에 값을 가지는 확률 구조이며, 두 변수 간의 관계 설명이 필요할 때 사용한다.
✔️ 조건부 확률
한쪽 확률변수 Y의 정보가 주어졌을 때 다른 한쪽 확률변수 X의 확률을 말한다.
P(X|Y) = Y는 조건, X는 확률변수, 즉
Y의 정보를 얻으면 X를 알 수 있는 형태다.
독립할 경우에는 P(X|Y) = P(X) 의 관계가 성립한다.
📍 정규분포
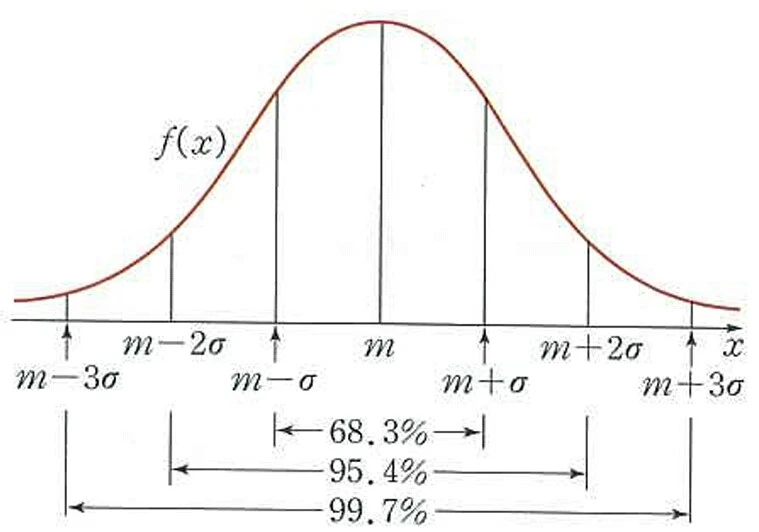
평균 중심으로 좌우가 대칭이 종 모양의 확률분포다.
파라미터 즉 확률분포 및 모델 형태를 결정하는 고정값이 평균과 표준편차로 구성돼 있으며,
두 개의 파라미터로 인해 정규 분포 모양이 달라진다.
데이터 밀집 구조가 평균에서 멀어질수록 극단적인 값일 확률이 낮아진다.
✔️ 표준화
(측정값) - (평균) / (표준편차) 를 이용해 평균을 0, 표준편차를 1로 만드는 것이다.
데이터를 평균을 기준으로 다시 표현하는 방법이며,
본래의 평균 및 표준편차와 상관없이 분포 안에서 어디쯤 위치하는지 알 수 있다.
