[Paper Review] - Soft Contrastive Learning for Time Series (SoftCLT), ICLR 2024
[Paper Review]
[Main Contribution]
- 시계열 데이터에 특화된 Soft Contrasive Learning 전략을 제안
- 다양한 다운스트림 작업에서 기존 contrasive learning 방법론 모델들보다 좋은 성능을 보임
- plug - and - play 방식이기 때문에 다른 모델 프레임워크에 쉽게 적용시킬 수 있음. (모듈화)

기존 Contrasive Learning을 활용한 방법론들은 시계열 특성을 반영하기 위해 다양한 시도를 함.
- instance - wise
- Temporal
- Hierarchical
그러나 시계열 특성을 고려하면서 hard assignment에서 soft assignment로 바꾼 시도는 없었음
이 논문에서 제안한 SoftCLT는 instance-wise, Temporal, Hierarchical, Soft assignment를 모두 고려함
또한, SoftCLT는 대부분의 Contrasive learning 들이 Embedding space 상에서 유사도를 측정하는 반면에
시계열 데이터는 Data space 상에서 유사도를 비교하는것이 효과적이라고 주장
[SoftCLT overview]
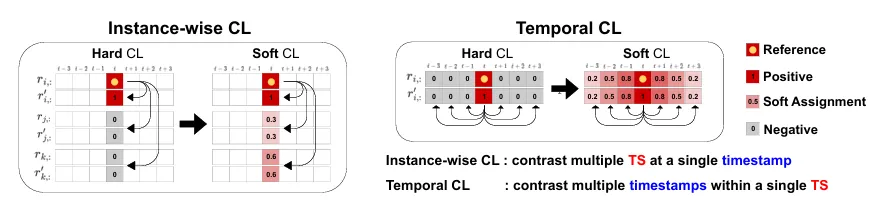
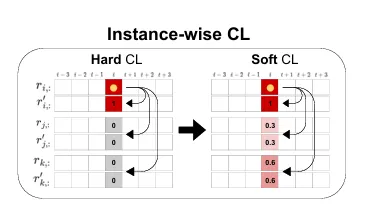
기존 Hard assignment경우, positive는 1, negative는 0으로 판별
- 문제점 : 임의로 threshold에 대해서 데이터가 강제적으로 분리되면서 모호함에 대한 문제
Soft assignment의 경우, 시계열 특성을 반영하여 유사도를 측정하고, 보다 더 풍부한 정보를 학습할 수 있도록 유도(모호한 부분이 없도록 유도할수 있다. )
(시계열 특성을 반영하기 위한 두가지 방법론 제시)
- instance-wise CL : 시계열 데이터 간의 거리를 기반으로 인스턴스 간의 관계를 학습
- Temporal CL : timestamp간의 차이를 기반으로 동일 시계열 내의 시간적 관계를 학습
[논문 Definition]
- 비선형 임베딩 함수 **를 학습하여 임베딩 벡터** 를 생성하는 것이 목표
1. [Soft Instance-wise Contrasive Learning]
→ Soft assignment Definition
- Soft Assignment의 최대값을 제한하는 역할
- 두 샘플이 얼마나 유사한지 측정하는 거리 함수 (DTW, Euclidean distance, cosine distance, TAM(time allignment measurement)).
(positive든 negative든 sampling을 하기위해서는)
- Argumentation을 통해 시계열 데이터를 증가하고, 아래를 정의를 가정

Contrasive learning은 cross entropy loss로 학습가능
따라서 유사도 학습을 위해 softmax 수식을 정의
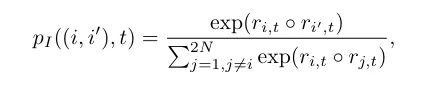
cf) InfoNCE loss
Contrasive learning에서 주로 쓰이는 loss function
loss function
- 첫번째 Term은 instance i와 positive pair i+N의 유사성을 나타내는 소프트맥스 확률
- 첫번째 텀은 positive pair의 loss를 나타내고, 두번째 텀은 positive pair 제외하고 나머지 pair들의 loss를 soft assignment값으로 가중하여 계산하는 텀
- 이것을 통해 positive pair는 가까워지게 나머지 pair멀어지게 학습
- [Soft Temporal Contrastive Learning]
→ Soft Assignment Definition
Argumentation을 통해 시계열 데이터를 증가하고, 아래를 정의를 가정

Contrasive learning은 cross entropy loss로 학습가능
따라서 유사도 학습을 위해 softmax 수식을 정의
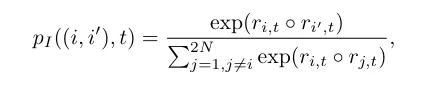
[Soft Temporal Contrastive Learning]
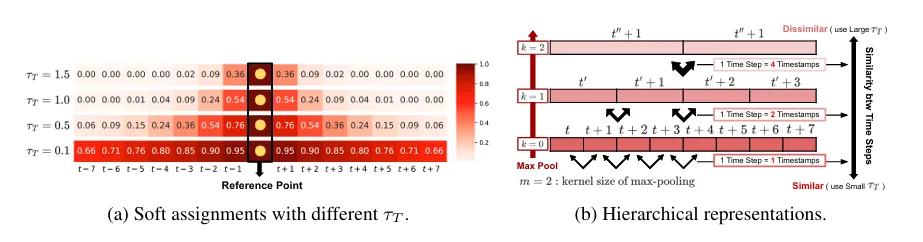
- TS2Vec 논문의 hierarchical contrastive loss 차용
- hierarchical contrastive loss , hierarchical representation 은 시계열 데이터의 복잡한 패턴, 구조를 효과적으로 학습할 수 있도록 함.
- Max pooling을 통해 각 타임스탬프를 통합
- Depth가 깊어질수록 그 의미가 점점 모호해지기 때문에 dissimiliarity가 증가함.
- 이러한 특성을 토대로 soft assignment를 조절하는 를 조정
- sharpness가 낮을수록 완만하게 assignment
- 이런식으로 계측정 표현 특징들을 잘 학습할 수 있도록 loss function을 구성
loss function
최종 손실 함수 정의
람다 1-람다는 각각의 가중치를 나타냄
실험결과
- SCL자체가 plug and play 방식이기 때문에 기존의 CL 모델에 이걸 모듈처럼 넣어서 성능이 얼마나 높아졌는지를 확인 가능
- classification
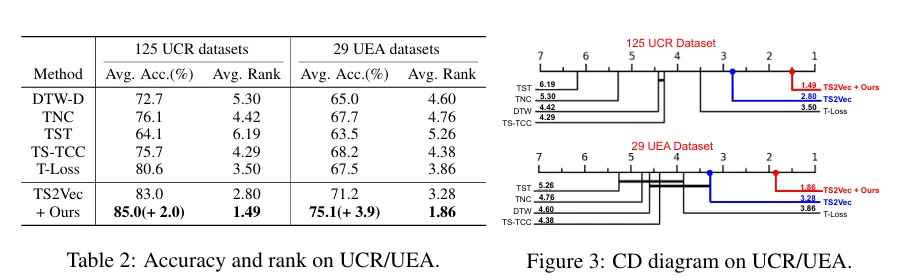
UCR : 단변량 시계열 벤치마크 데이터셋
UEA : 다변량 시계열 분류를 위한 벤치마크 데이터
TS2Vec(2022)은 hierarchical contrastive loss를 도입한 논문
- Semi & Self-supervised classification
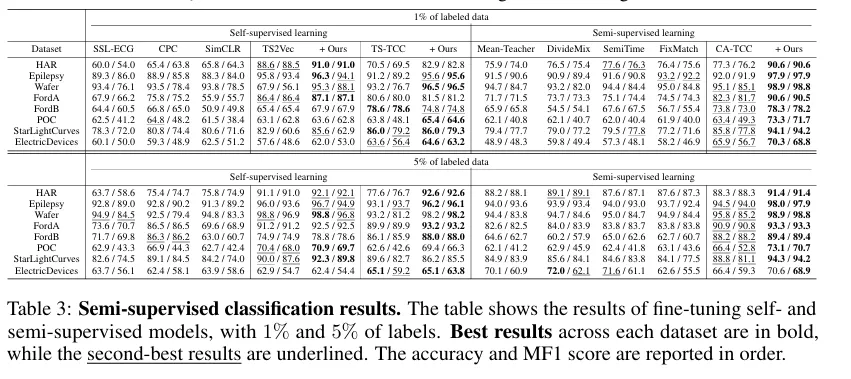
- 1% label 데이터를 사용한 경우 실험
- 5% label 데이터를 사용한 경우 실험
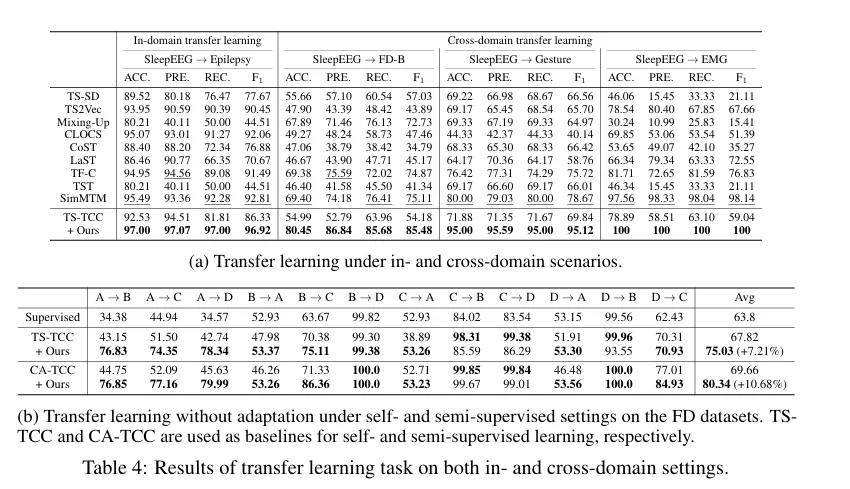
- in & Cross domain transfer learning
- Anomaly Detection
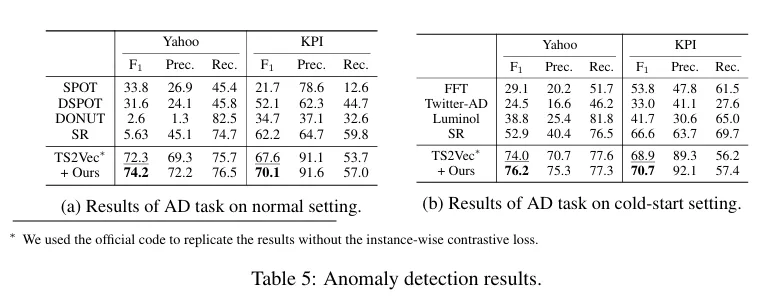
Conclusion
- 이 연구는 시계열 데이터 특성을 고려하여 Soft Contrasive Learning을 적용
- plug and play 방식으로 구현해서 다른 프레임워크에 자유롭게 적용가능
- 확실히 기존 contrastive learning 방법론들보다 시계열 task에서 뛰어난 성능을 보이는것은 맞으나, 지금 현 시점에서는 SOTA인지는 확인이 필요함.
