과적합(overfitting)이 발생하는 이유
- 데이터 수가 적은 경우
- 모델의 파라미터가 많은 경우
- 딥러닝 모델은 고전 머신러닝 모델에 비해 압도적으로 파라미터가 많기 때문에 과적합이 되기 쉽다
과적합 방지 기법
1. 데이터 관련 기법
-
데이터 양 증가: 충분한 데이터가 있으면 모델이 일반적인 패턴을 학습하여 과적합을 방지할 수 있습니다. 데이터가 부족한 경우에는 데이터 증강(Data Augmentation) 기법을 사용하게 된다.
- 데이터 증강(Data Augmentation): 모델의 학습 과정에서 데이터의 양과 다양성을 인위적으로 늘리는 기법입니다. 이는 모델의 일반화 성능을 향상시키고 과적합을 방지하는 데 매우 효과적입니다. 데이터 증강은 특히 이미지 처리와 같은 비정형 데이터에서 자주 사용됩니다.
- 예를 들어, 이미지 데이터의 경우 이미지를 회전, 확대, 축소하거나 노이즈를 추가하는 등의 방법이 있습니다.
이미지 데이터 증강 기법
다양한 이미지 변형 기법을 사용하여 데이터 증강을 수행할 수 있습니다.
- 회전(Rotation): 이미지를 일정 각도로 회전시킵니다.
- 이동(Translation): 이미지를 수평 또는 수직 방향으로 이동시킵니다.
- 확대 및 축소(Scaling): 이미지를 확대하거나 축소합니다.
- 뒤집기(Flipping): 이미지를 좌우 또는 상하로 뒤집습니다.
- 잘라내기(Cropping): 이미지의 일부분을 잘라내어 사용합니다.
- 노이즈 추가(Add Noise): 이미지에 무작위 노이즈를 추가합니다.
- 밝기 변화(Change Brightness): 이미지의 밝기를 조절합니다.
- 왜곡(Distortion): 이미지를 비틀거나 왜곡시킵니다.
2. 모델 관련 기법
- 드롭아웃(Dropout): 학습 과정에서 임의의 뉴런을 비활성화(즉, "드롭")하여 모델의 복잡도를 줄이고, 특정 뉴런에 대한 의존도를 낮추어 일반화 성능을 향상시킵니다.
작동 원리
- 뉴런 비활성화: 학습 중에 각 학습 단계에서 뉴런을 무작위로 비활성화합니다. 비활성화된 뉴런은 해당 학습 단계 동안 입력 및 출력을 무시합니다.
- 확률적 드롭: 각 뉴런이 드롭아웃될 확률을 설정합니다. 일반적으로 0.5 (50%)의 비율이 많이 사용되며, 이는 뉴런의 절반을 비활성화한다는 의미입니다.
- 앙상블 효과: 드롭아웃은 학습 과정에서 다양한 서브 네트워크를 훈련시키는 것과 유사합니다. 이는 마치 여러 모델을 앙상블하여 사용하는 효과를 냅니다.
- 예측 시 활성화: 예측 단계에서는 모든 뉴런을 사용합니다. 학습 시 드롭아웃으로 비활성화된 뉴런의 효과를 보상하기 위해 뉴런의 출력을 드롭아웃 확률로 나눕니다.
예시
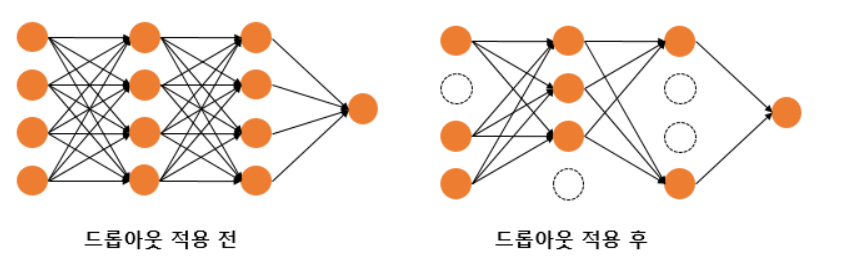
- 예를 들어 드롭아웃의 비율을 0.5로 한다면 학습 과정마다 랜덤으로 절반의 뉴런을 사용하지 않고, 절반의 뉴런만을 사용합니다.
- 드롭아웃은 신경망 학습 시에만 사용하고, 예측 시에는 사용하지 않는 것이 일반적입니다. 학습 시에 인공 신경망이 특정 뉴런 또는 특정 조합에 너무 의존적이게 되는 것을 방지해주고, 매번 랜덤 선택으로 뉴런들을 사용하지 않으므로 서로 다른 신경망들을 앙상블하여 사용하는 것 같은 효과를 내어 과적합을 방지합니다.
- Early Stopping: 학습 과정에서 검증 데이터(validation set)의 성능을 지속적으로 모니터링하여, 성능이 더 이상 향상되지 않으면 학습을 중단
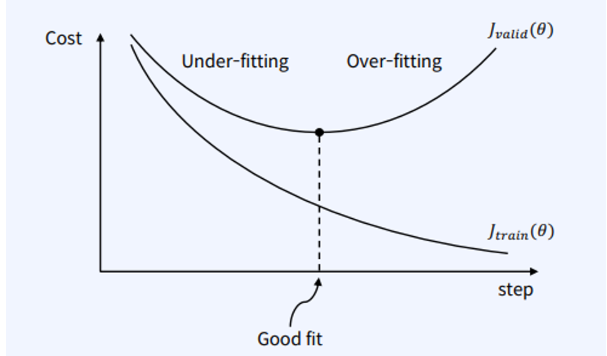
작동 원리
- 훈련 데이터와 검증 데이터: 모델을 학습할 때 데이터를 훈련 데이터(training set)와 검증 데이터(validation set)로 나눕니다. 훈련 데이터는 모델의 가중치를 학습하는 데 사용되고, 검증 데이터는 모델의 일반화 성능을 평가하는 데 사용됩니다.
- 모니터링: 학습 과정에서 각 에포크(epoch)마다 검증 데이터에 대한 성능(예: 손실(loss) 또는 정확도(accuracy))을 평가합니다.
- 중단 조건: 검증 데이터의 성능이 일정 횟수(patience) 동안 향상되지 않으면 학습을 중단합니다. 여기서 patience는 성능이 향상되지 않는 에포크 수를 의미합니다. 이 값을 설정하여 모델이 너무 빨리 멈추지 않도록 조절할 수 있습니다.
주요 매개변수
- monitor: 모니터링할 성능 지표를 지정합니다. 일반적으로 'val_loss' 또는 'val_accuracy'를 사용합니다.
- patience: 성능이 향상되지 않는 에포크 수를 지정합니다. 이 값 동안 성능이 향상되지 않으면 학습을 중단합니다.
- restore_best_weights: 학습 종료 시점에 검증 성능이 가장 좋았을 때의 가중치를 복원합니다. 이를 통해 최적의 모델을 얻을 수 있습니다.
3. 규제화(Regularization)
-
L1 및 L2 정규화: 손실 함수에 가중치 패널티를 추가하여 모델의 복잡도를 제한.
- L1 규제: 모든 가중치의 절대값 합을 비용 함수에 추가합니다. 이로 인해 일부 가중치가 0이 되어 특정 특성이 모델에 사용되지 않게 됩니다.
- 비용 함수에 λ∑|w|를 추가.
- L2 규제: 모든 가중치의 제곱합을 비용 함수에 추가합니다. 이로 인해 가중치 값이 0에 가깝게 되지만 완전히 0이 되지는 않습니다.
- 비용 함수에 λ∑w²를 추가.
- 인공 신경망에서는 가중치 감쇠(weight decay)라고도 불립니다.
- L1 규제: 모든 가중치의 절대값 합을 비용 함수에 추가합니다. 이로 인해 일부 가중치가 0이 되어 특정 특성이 모델에 사용되지 않게 됩니다.
-
배치 정규화(Batch Normalization): 각 배치마다 입력을 정규화하여 학습을 안정화하고 과적합을 방지합니다.
요약
딥러닝 모델의 과적합을 방지하기 위해서는 데이터 양을 늘리거나 모델의 복잡도를 줄이는 등 여러 가지 기법을 사용가능.
데이터 증강, 드롭아웃, 가중치 규제 등 다양한 방법들을 적절히 조합하여 사용하면 과적합 문제를 효과적으로 완화할 수 있습니다. 각 기법을 잘 이해하고 상황에 맞게 적용하는 것이 중요
학습 회고
- 기존 ML을 배우면서 overfitting 방지 방법에 대해서 배워 L1,L2 regularization에 대해서는 알고있었다.
- 이외의 내용에 대해서는 이번의 정리를 통해서 알게되었고 아직 이미지 데이터를 다뤄보진 않아 데이터 증강 방법에 대해서는 후에 더 공부를 해야 좀 더 이해 할 수 있을거같다.

Self supervised Learning, Time Series, Multimodal Learning