3줄 요약
- LLM의 단점 중 할루시네이션 발생과 오래된 정보를 제공하는 문제를 해결하기 위해 등장
- 외부에 별도의 DB를 연결해서 모델의 생성능력과 사실 관계 파악을 개선하고 더 정확한 정보를 얻음
- 비용이 적게 들며 범용성 있고 답변의 정보 출처를 제공할 수 있음
개념

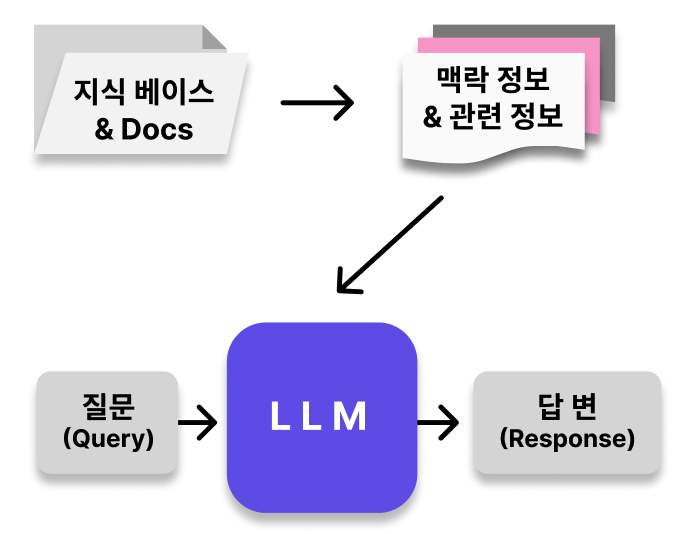
RAG(Retrieval-Augmented Generation)는 대규모 언어 모델(LLM)이 응답을 생성하기 전에 신뢰할 수 있는 외부 지식 베이스를 참조하도록 하는 프로세스이다.
대규모 언어 모델(LLM)은 방대한 양의 데이터를 기반으로 학습되며 수십억 개의 매개 변수를 사용한다.
이 과정에서 비용이 막대하게 들며 내가 원하는 전문적인 답을 내기 위해서는 꾸준히 학습시켜야 하는 등 개선점이 존재하는데, RAG는 이를 개선하여 다양한 상황에서 관련성, 정확성 및 유용성을 유지하기 위한 비용 효율적인 접근 방식이다.
등장 이유
- 기존 LLM이 가졌던 아래와 같은 문제 해결을 위해
(다들 한 번은 겪어봤을것 같다)
- 답변이 없을 때 허위 정보를 제공
- 오래되었거나 너무 일반적인 정보를 제공
- 신뢰할 수 없는 출처로부터 응답을 생성
- 용어 혼동으로 인해 응답이 정확하지 않기도 함.
RAG의 주요 구성 요소
- 질의 인코더(Query Encoder): 사용자의 질문을 이해하기 위한 언어 모델입니다. 주어진 질문을 벡터 형태로 인코딩함
- 지식 검색기(Knowledge Retriever): 인코딩된 질문을 바탕으로 외부 지식 베이스에서 관련 정보를 검색함
- 지식 증강 생성기(Knowledge-Augmented Generator): 검색된 지식을 활용하여 질문에 대한 답변을 생성하는 언어 모델이며 LLM과 유사하지만, 검색된 지식을 추가 입력으로 받아 보다 정확하고 풍부한 답변을 생성
파인 튜닝(Fine Tuning - 미세 조정)이랑 다른거야?
- 두 개념 모두 '사전 학습'이 필요하며 LLM이 가진 문제를 해결하고 더 정확한 정보를 전달하기 위해 등장한 개념이다.
- 하지만 목적이 다른 개념으로, 파인 튜닝은 레이블된 텍스트 데이터를 토대로 LLM을 추가 학습 시키며 도메인에 특화시키는 방향으로 발전.
- 반면 RAG는 검색 알고리즘과 외부 데이터베이스의 인덱싱을 통해 정보의 질을 올리며, 추가 학습이 필요하지 않으나, 도메인 특화를 위해 추가 학습을 시킬 수 있음.
- 또 사용자 측면에서 보면, RAG는 외부 지식의 실시간 검색과 응답 생성에 유리하며, 넓은 범위의 정보 접근이 필요할 때 유용함.
반대로 파인튜닝은 반대로 특정 도메인이나 작업에 최적화된 모델을 만들 때 유리함.
관련 필수 개념
- 벡터 데이터베이스: 텍스트를 벡터로 저장하여 빠른 유사도 검색을 가능케 하는 RAG의 핵심 요소
- 임베딩: 텍스트를 숫자 벡터로 변환하는 과정으로, 질문과 문서 간 유사도 계산에 사용
- 프롬프트 엔지니어링: 검색된 정보를 LLM에 효과적으로 전달하기 위한 입력 설계 기법
- 정보 신선도: 외부 데이터베이스를 통해 최신 정보를 제공할 수 있는 RAG의 장점
- 확장성: 새로운 정보를 쉽게 추가하여 시스템을 지속적으로 확장 가능
- 소스 추적: 생성된 응답의 출처를 추적하여 투명성과 신뢰성 향상
- 멀티모달 RAG: 텍스트뿐만 아니라 이미지, 오디오 등 다양한 형태의 데이터를 포함하는 확장된 RAG 시스템
- 성능 평가 지표: 정확도, 관련성, 응답 시간 등 RAG 시스템의 효과성을 측정하는 주요 지표

Ai agent 설계를 잘 하고싶은 개발자