
프론트엔드 개발자가 MCP로 DB 작업 빠르게 끝낸 후기
왜 Supabase인가
요즘 AI로 프로젝트 시작하는 사람이 진짜 많아지고 있다.
예전엔 백엔드/DB 쪽에서 가장 진입장벽이 낮은 게 Firebase였을지 모르지만, 현재는 Supabase라고 생각한다.
이유는.. 개인적으로는 다음과 같다.
- PostgreSQL 기반인데 SQL 몰라도 Dashboard에서 클릭으로 테이블 만들 수 있고, 엑셀 만 할 줄 알면 배울 수 있다!
- 인증, 스토리지, 실시간 구독이 다 내장되어 있어서 별도 서버 구축이 필요 없고, 심지어 Firebase처럼 소셜로그인도 도와준다.(물론 사업자나 개발자 계정 필요)
- 클라이언트 SDK가 잘 되어 있어서 프론트엔드 개발자가 바로 쓸 수 있다
(이게 가장 큰 장점중 하나인 것 같다) - 무료 티어가 꽤 넉넉하다 — 프로젝트 2개, DB 500MB, Storage 1GB, 월 5만 API 호출. 사이드 프로젝트나 MVP 단계에서는 과금 걱정 없이 충분하다
- ✨️M✨️C✨️P✨️가 있다 - 그저 빛✨️..
Supabase 프로젝트 생성 ~ 연결까지
1단계: 프로젝트 만들기
- supabase.com 접속 → Start your project 클릭
- GitHub 계정으로 로그인(SSO로 해도 된다 그냥 되는거로!)
- New Project 클릭
- Organization 선택 (처음이면 자동 생성됨)
- 프로젝트 이름, DB 비밀번호, Region 설정 → Create new project
- 2~3분 기다리면 프로젝트가 올라온다
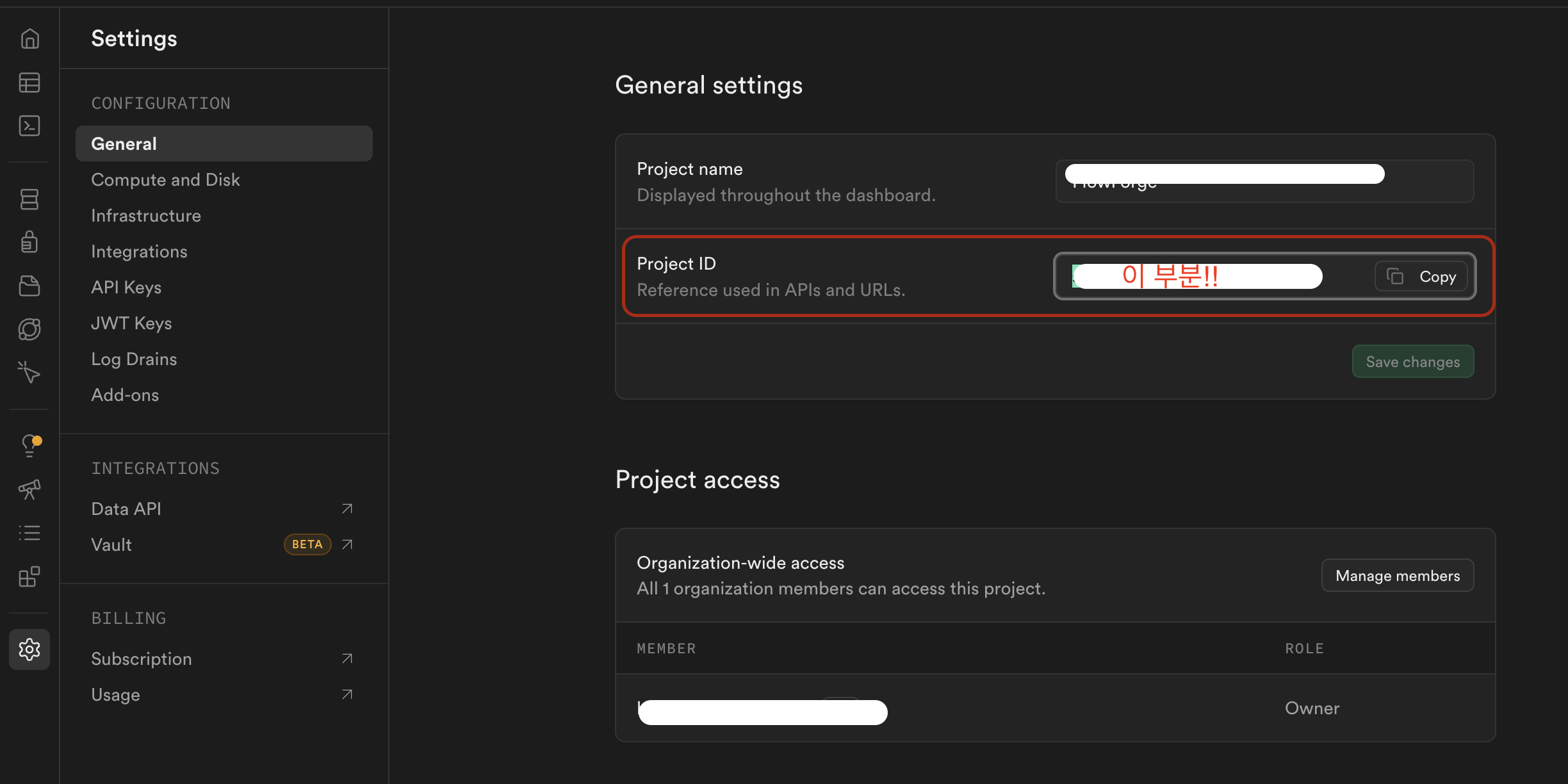
2단계: project_ref 확인
프로젝트가 만들어지면 Dashboard URL이 이런 형태다:
https://supabase.com/dashboard/project/abcdefghijklmnop
^^^^^^^^^^^^^^^^
이 부분이 project_refSettings > General 순서로 눌러서 확인해보자
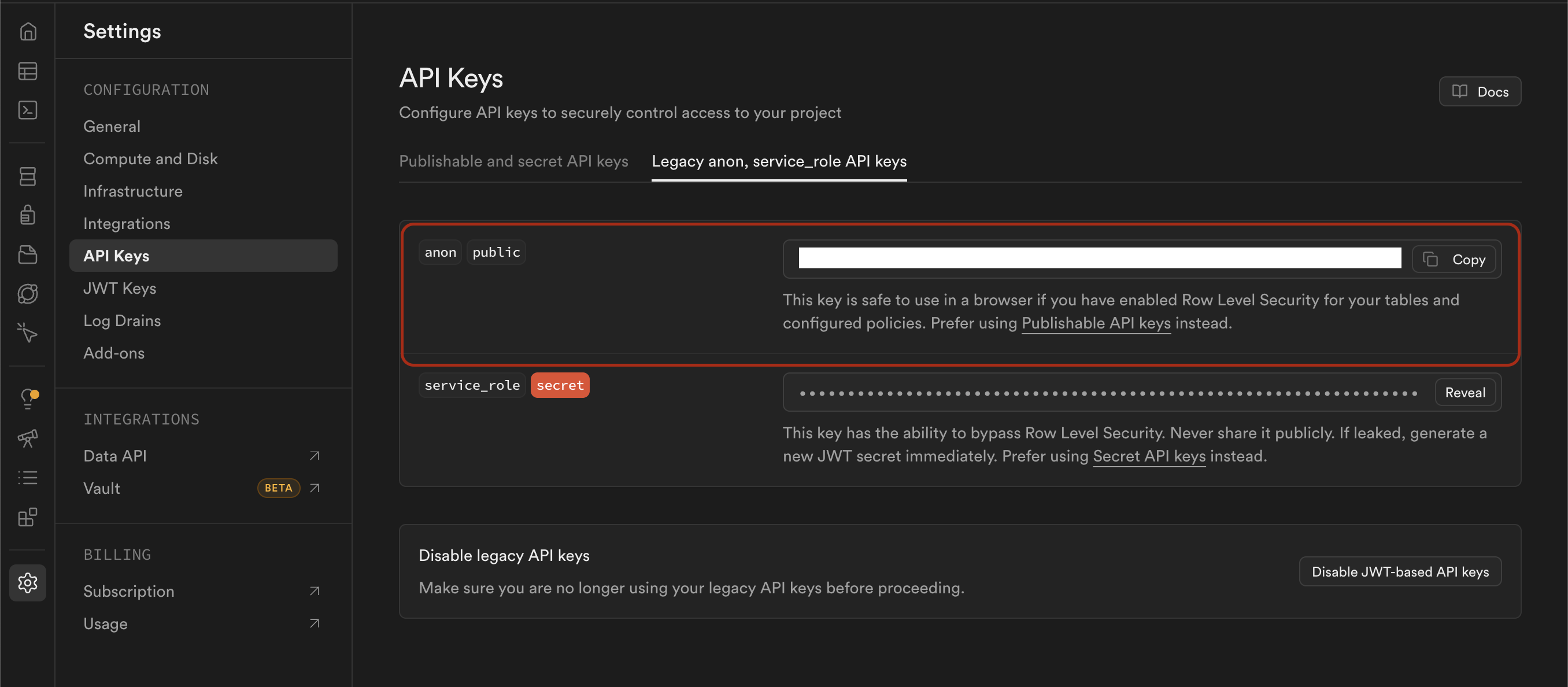
3단계: 클라이언트 연결 키 확인
Settings > API에 가면 두 가지 키가 있다:
| 키 | 용도 | 클라이언트 노출 |
|---|---|---|
anon (public) | 프론트엔드 SDK용. RLS가 적용됨 | OK |
service_role (secret) | 관리자/백엔드용. RLS 우회 | 절대 노출 금지 |
프론트엔드 앱에서는 anon 키 + Project URL만 있으면 바로 연결 가능하다.
import { createClient } from '@supabase/supabase-js'
const supabase = createClient(
'https://abcdefghijklmnop.supabase.co', // Project URL
'eyJhbGciOiJIUzI1NiIsInR5...' // anon key
)여기까지 오면 Supabase 쓸 준비 완료인데, MCP로 연결하면 이거보다 더 빨리 할 수도 있다.
Another 3단계: Claude Code + MCP로 터미널에서 바로 DB 조작하기
근데 이 글의 핵심은 Dashboard를 왔다갔다하는 게 아니라, Claude Code 안에서 DB까지 한 번에 다루는 것이며, AI로 Supabase를 사용하는 대부분이 그것 때문에 이 글을 읽는다고 생각한다. 그걸 가능하게 해주는 게 Supabase MCP 서버이며 너무 간단하다.
Supabase 대시보드의 상단에서 (Connect) 버튼을 눌러서 MCP로 가면 친절하게 Claude와 연동되는 커맨드를 준다.
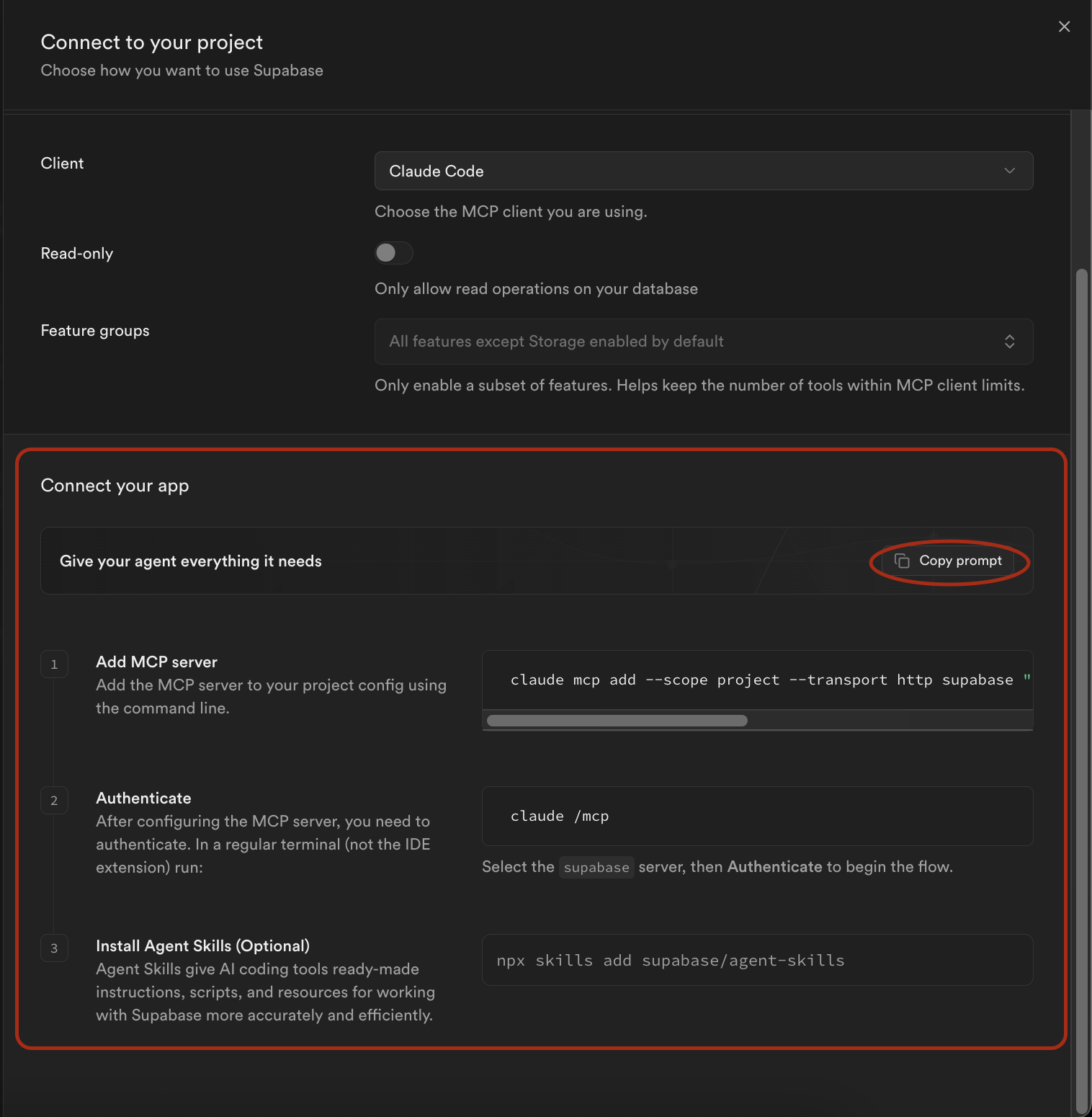
이대로 진행하면 대부분 Claude가 알아서 해주며, 너무너무 쉽고 빠르다.
하지만 FM(?)대로 연동하는 설명도 갖고왔다.
프로젝트 루트에 .mcp.json 파일 만들고 2단계에서 찾은 프로젝트 레퍼런스를 집어넣는다.
{
"mcpServers": {
"supabase": {
"type": "url",
"url": "https://mcp.supabase.com/mcp?project_ref=아까_확인한_project_ref"
}
}
}그 다음 Claude Code를 실행하면 처음에 브라우저가 뜨면서 OAuth 인증을 요청하는데, 연동을 진행하면 웹 브라우저로 이동해서 Supabase 계정으로 승인 한 번만 하면 끝이다. 이후로는 Claude Code가 mcp__supabase__* 도구들을 자동으로 인식하며 날 도와준다.
연결 확인은 Claude Code에서 "테이블 목록 보여줘" 라고 하면 list_tables가 작동하면서 현재 DB 상태를 바로 가져온다. 그러면 실질적으로는 Dashboard 열 필요가 거의 없다.
이 상태에서 "이 JSON 파일 읽어서 DB에 넣어줘"라고 하면, Claude가 로컬 파일 읽기부터 SQL 생성(대부분 초보자들이 어려워 하는), 그리고 마지막으로 MCP로 실행까지 한 호흡에 처리 가능하다! 아마 대부분 이렇게 하지 않았을까 싶다.
실전 Supabase 적용, Flutter와 연동한다면?
Flutter 앱에 하드코딩된 로컬 데이터(Dart 상수 + JSON 파일)를 Supabase DB로 옮겨야 했다. 테이블 14개, 시드 데이터 253행, RLS 정책 32개.
기존이라면 이런 흐름이다:
VS Code에서 JSON 열기 → 브라우저에서 Supabase Dashboard 열기
→ 머리로 SQL 변환 → SQL Editor에 붙여넣기 → 에러
→ 다시 VS Code로 돌아와서 JSON 확인 → 반복Supabase MCP를 쓰면 이렇게 바뀐다:
Claude가 로컬 JSON 읽기 → Claude가 SQL 생성 + 실행 → 에러 시 즉시 수정
→ 전 과정 한 대화에서 완료"Dashboard 안 열어도 된다"도 좋은 포인트지만, 내가 보기에는 로컬 코드와 DB 사이의 컨텍스트가 끊기지 않는 것이 핵심인 것 같다.
Claude가 양쪽을 동시에 보면서 변환하니까 초보적인 실수인 데이터 타입 불일치나 FK 누락이 거의 안 생겼다.
그렇다면 이제 Supabase를 사용하기 위한 기초 지식만 공부해보자.
"DB란 대충 데이터를 많이 넣는 창고구나?" 라는 정도만 알고있다면 충분히 할 수 있다.
먼저, 편의점으로 이해하는 DB 기초
PostgreSQL 핵심 개념을 편의점에 빗대서 빠르게 정리한다. 이미 아는 사람은 실전 파트로 넘어가도 된다.
테이블 = 진열대
편의점에 진열대가 여러 개 있다. 음료 진열대, 과자 진열대, 도시락 진열대. DB에서 테이블이 바로 그것이다. 각 진열대(테이블)에는 같은 종류의 상품(데이터)이 정해진 규격으로 놓여 있는 느낌이다.
| 편의점 | PostgreSQL |
|---|---|
| 편의점 전체 | 데이터베이스 |
| 진열대 (음료, 과자, 도시락) | 테이블 (products, sales, partners) |
| 상품 한 개 | 로우(row) 한 건 |
| 가격표 항목 (이름, 가격, 유통기한) | 컬럼 (name, price, expiry) |
각 컬럼에는 타입이 정해져 있다. 가격에 "맛있음"이라고 적을 수 없듯이, price 컬럼에는 숫자만 들어간다. TypeScript의 타입 시스템과 같은 느낌이다.
FK(Foreign Key) = 발주서의 납품업체 코드
편의점에서 발주서를 작성할 때, 납품업체를 이름으로 적지 않고 업체 코드로 적는다. "업체 코드 A001의 콜라 30박스" 이런 식이다. 그 업체 코드가 FK(Foreign Key)다.
-- 납품업체 진열대 (부모)
CREATE TABLE suppliers (
id TEXT PRIMARY KEY,
name TEXT NOT NULL
);
-- 발주서 진열대 (자식) — supplier_id가 FK
CREATE TABLE orders (
id UUID PRIMARY KEY,
supplier_id TEXT REFERENCES suppliers(id), -- "이 발주는 이 업체 거"
item TEXT,
quantity INT
);REFERENCES suppliers(id) = "이 값은 반드시 suppliers 테이블에 있는 업체여야 한다." 존재하지 않는 업체에 발주할 수 없는 것처럼, FK가 데이터의 정합성을 지켜준다.
부모-자식 규칙도 편의점으로:
- 납품업체(부모) 등록 → 그 다음에 발주서(자식) 작성 가능
- 업체를 삭제하려면? 그 업체 발주서(자식)부터 정리해야 한다
ON DELETE CASCADE= 업체 삭제하면 관련 발주서도 자동 폐기
RLS = 알바생 vs 점장 권한
편의점 POS 시스템에서 알바생은 결제만 할 수 있고, 점장만 매출 보고서를 볼 수 있다. RLS(Row Level Security)가 정확히 이것이다. 같은 데이터인데 누가 접근하느냐에 따라 보이는 게 달라진다.
-- 점장만 매입 단가를 볼 수 있다
CREATE POLICY "점장만 매입가 조회" ON products
FOR SELECT
USING (
(SELECT role FROM profiles WHERE id = auth.uid()) = 'manager'
);프론트엔드에서 if (user.role !== 'manager') return [] 하는 거랑 뭐가 다르냐면 — 프론트는 데이터가 이미 브라우저에 왔는데 그냥 안 보여주는 것이다. 개발자 도구 열면 다 보인다. RLS는 DB 단에서 아예 안 준다. 데이터가 네트워크를 타지도 않는다.
뷰(View) = 일일 매출 요약표
점장이 매일 아침 보는 매출 요약표 같은 느낌이다. 여러 진열대(테이블)의 데이터를 한 장으로 모아놓은 것이다. 원본 데이터를 건드리지 않고, 필요한 정보만 뽑아서 보여주는 가상 테이블이다.
CREATE VIEW daily_sales_summary AS
SELECT date, SUM(amount) as total, COUNT(*) as order_count
FROM sales
GROUP BY date;MCP 핵심 도구 3개
편의점 비유는 여기까지다. 이제부터 실전에서 쓰는 MCP 도구를 알아보자.
| 도구 | 용도 | 편의점 비유 |
|---|---|---|
apply_migration | DDL (CREATE TABLE, ALTER) | 새 진열대 설치 |
execute_sql | DML (INSERT, SELECT) | 상품 진열/조회 |
list_tables | 테이블 목록 + 행 수 + RLS 확인 | 매장 배치도 + 재고 요약 |
주의: 스키마 변경(CREATE/ALTER)은 반드시
apply_migration으로 해야 한다.execute_sql로 하면 마이그레이션 이력에 안 남아서 나중에 추적이 안 된다.
실전: 로컬 데이터를 DB로 옮긴 전체 과정
아까 비유했던 편의점, 이제 진짜로 만들어보자. 편의점 POS 시스템을 예시로 진행한다.
Step 1 — 스키마 설계 + 테이블 생성
아까 편의점에서 진열대 만든다고 했는데, SQL로는 이렇게 생겼다:
-- apply_migration(name: "create_store_tables")
CREATE TABLE product_categories (
id TEXT PRIMARY KEY,
name TEXT NOT NULL, -- 음료, 과자, 도시락, 생활용품
sort_order INT DEFAULT 0
);
CREATE TABLE products (
id TEXT PRIMARY KEY,
category_id TEXT REFERENCES product_categories(id), -- FK: 이 상품은 이 카테고리 소속
name TEXT NOT NULL, -- 콜라, 새우깡, 삼각김밥
price INT NOT NULL,
barcode TEXT
);이걸 직접 다 짤 필요는 없다. Claude에게 이렇게 요청하면 된다:
💬 Claude에게 이렇게 말한다:
"내 프로젝트의
docs/supabase-schema.md파일을 읽어서 테이블을 만들어줘. FK 의존성 순서대로 마이그레이션을 분리해서 실행해."
설계 문서가 없어도 괜찮다. 기존 코드를 보여주면서 요청할 수도 있다:
💬 설계 문서 없이 요청하는 경우:
"
src/data/models/폴더에 있는 모델 클래스들을 읽어서, 이 구조에 맞는 Supabase 테이블을 만들어줘. FK 관계도 잡아주고."
Claude가 모델 클래스를 분석해서 테이블 구조를 제안하고, 승인하면 apply_migration으로 바로 실행한다.
FK 의존성 순서가 중요하다. 납품업체 등록 안 하고 발주서 쓸 수 없는 것처럼, 부모 테이블부터 만들어야 한다:
product_categories → products → product_details
suppliers → inventory
(카테고리 먼저) (상품 다음) (상세 정보는 상품 다음에)마이그레이션도 역할별로 분리했다:
1. create_store_tables → 상품/카테고리/납품업체 테이블
2. create_sales_tables → 매출/매출항목 테이블
3. create_staff_tables → 직원/근무기록 테이블
4. create_indexes → 인덱스
5. enable_rls → RLS 정책한 방에 다 넣으면 어디서 에러가 터졌는지 찾기 어렵다. 이 분리도 Claude에게 "역할별로 나눠서 마이그레이션 해줘"라고 하면 알아서 해준다.
Step 2 — 데이터 시딩 (INSERT)
여기서 MCP의 진가가 나온다. Claude에게 이렇게 말하면 된다:
💬 Claude에게 이렇게 말한다:
"
assets/data/products.json파일을 읽어서 products 테이블에 넣어줘."
이러면 Claude가 로컬 JSON을 읽고 → SQL INSERT문을 만들고 → execute_sql로 바로 실행한다. 한 흐름이다.
소스 코드에 하드코딩된 데이터도 마찬가지다:
💬 하드코딩된 상수를 옮기는 경우:
"
lib/data/product_repository.dart에 하드코딩된 상품 데이터를 읽어서 products 테이블에 INSERT 해줘. category_id FK도 맞춰서."
Claude가 소스 코드의 상수를 분석해서 SQL로 변환하고, FK 관계까지 맞춰서 넣어준다. 이게 수동으로 하면 가장 귀찮은 작업인데, Claude가 양쪽 파일을 동시에 보고 있으니까 타입 변환 실수가 안 생긴다.
데이터 소스 매핑 예시:
하드코딩 (product_repository.dart) → products 테이블
JSON (assets/data/categories.json) → product_categories 테이블
JSON (assets/data/suppliers.json) → suppliers 테이블
JSON (assets/data/inventory.json) → inventory 테이블JSON의 중첩 객체도 JSONB로 깔끔하게 들어간다:
INSERT INTO products (id, category_id, name, price, nutrition) VALUES (
'cola-500',
'beverage',
'코카콜라 500ml',
1800,
'{"calories":210,"sugar":53,"caffeine":60}'::jsonb
);대량 데이터는 배치 분할이 필요하다. 이것도 직접 나눌 필요 없이:
💬 대량 데이터 요청:
"
assets/data/inventory.json에서 전체 재고 데이터를 inventory 테이블에 넣어줘. 양이 많으면 배치로 나눠서."
데이터가 100개 이상이면 한 번에 넣을 때 SQL 길이 제한에 걸리는데, Claude가 알아서 배치로 나눠서 실행해준다.
각 INSERT 후에는 확인도 한마디면 된다:
💬 "지금까지 넣은 데이터 행 수 확인해줘"
product_categories: 4 ✓
products: 120 ✓
suppliers: 8 ✓
inventory: 350 ✓Step 3 — RLS 정책
RLS도 Claude에게 맡길 수 있다:
💬 Claude에게 이렇게 말한다:
"상품/카테고리 테이블은 누구나 읽을 수 있게, 매출/근무기록 테이블은 해당 직원 본인 데이터만 접근 가능하게 RLS 설정해줘."
Claude가 테이블 구조를 보고 적절한 패턴을 골라서 적용해준다. 결과적으로 두 패턴이 사용된다:
패턴 A: 공개 읽기 — 상품 정보는 누구나 볼 수 있다:
ALTER TABLE products ENABLE ROW LEVEL SECURITY;
CREATE POLICY "Public read" ON products
FOR SELECT USING (true);
-- INSERT/UPDATE/DELETE 정책 없음 → 관리자(service_role)만 수정 가능패턴 B: 본인 데이터만 — 내 근무기록은 나만 볼 수 있다:
ALTER TABLE shift_logs ENABLE ROW LEVEL SECURITY;
CREATE POLICY "Own data only" ON shift_logs
FOR SELECT USING (auth.uid() = staff_id);
CREATE POLICY "Own insert" ON shift_logs
FOR INSERT WITH CHECK (auth.uid() = staff_id);테이블에 staff_id가 없는 경우(자식 테이블)는 부모를 타고 올라간다:
-- sale_items에는 staff_id가 없다. sale_id만 있다.
-- → sales 테이블을 경유해서 소유권 확인
CREATE POLICY "Own sale items" ON sale_items
FOR SELECT USING (
EXISTS (
SELECT 1 FROM sales
WHERE sales.id = sale_items.sale_id
AND sales.staff_id = auth.uid()
)
);삽질 포인트: 정책만 만들고
ENABLE ROW LEVEL SECURITY를 빠뜨리면 RLS가 작동 안 한다.list_tables의rls_enabled필드로 꼭 확인해야 한다.
삽질 방지 체크리스트
실전에서 걸린 것들을 정리한다:
| 삽질 | 해결 |
|---|---|
apply_migration vs execute_sql 혼동 | 스키마(CREATE/ALTER) = migration, 데이터(INSERT) = execute |
| FK 순서 안 지킴 | 부모 테이블 먼저. categories → products → product_details |
| RLS ENABLE 빠뜨림 | list_tables로 rls_enabled 확인 |
| OAuth URL 줄 바꿈 | 터미널에서 긴 URL이 잘림. open "전체URL" (macOS) 또는 브라우저에 직접 붙여넣기 |
auth.uid() 안 됨 | 로그인 구현 전이면 직원 테이블은 RLS에 막힘. 상품 데이터 먼저 연동 |
핵심 정리
- MCP 도구 3개만 기억하자:
apply_migration(스키마),execute_sql(데이터),list_tables(검증) - FK 순서: 부모 먼저, 자식 나중. 마이그레이션은 역할별로 분리한다
- RLS 패턴 2개: 공개 읽기(
USING (true)) / 본인 데이터(auth.uid() = user_id) - 설계 문서 먼저: CREATE TABLE DDL을 미리 정리해두면 MCP 실행은 복붙 수준이다
- 레퍼런스 vs 유저 데이터 분리: 인증 없이 바로 쓸 수 있는 것과 로그인 후 쓸 수 있는 것을 나눠두면 단계적 연동이 가능하다
한 줄 감상
솔직히 제일 놀란 건 속도보다 에러가 안 난다는 것 이었다. 기존에는 JSON 보고 SQL 쓰면서 타입 틀리고, FK 빠뜨리고, 작은따옴표 이스케이프 깜빡하고... 그런 자잘한 삽질이 작업 시간의 절반이었는데, Claude가 양쪽 파일을 동시에 보고 있으니까 그런 실수가 구조적으로 안 생긴다.
"AI가 코드를 짜준다" 아니면 "AI가 딸깍해준다"보다 "AI가 두 시스템 사이의 번역기가 된다"가 MCP의 진짜 가치인 것 같다.
DB 작업이 어려운 게 SQL 문법이 어려워서가 아니라, 내 코드와 DB 사이를 왔다갔다하면서 컨텍스트를 유지하는 게 어려운 것 같다. 우선 기초만 내 머릿속에 들어가 있다면 이제 나머지는 다 쉬워진다.
