MIPS Pipeline
-
IF : Instruction fetch from memory
(reading instruction memory from PC) -
ID : Instruction decode and register read
(what instruction means) -
EX : Execute operation or calculate address
(by ALU) -
MEM : Access memory operand
-
WB : Write result back to register
Performance
각 stage에서의 time을 다음과 같이 가정하자
- register read or write : 100ps
- other stage : 200ps
-
lw total time
= 200 + 100 + 200 + 200 + 100
= 800ps -
sw total time
= 200 + 100 + 200 + 200
= 700ps -
R-format total time
= 200 + 100 + 200 + 100
= 600ps -
beq total time
= 200 + 100 + 200
= 500ps
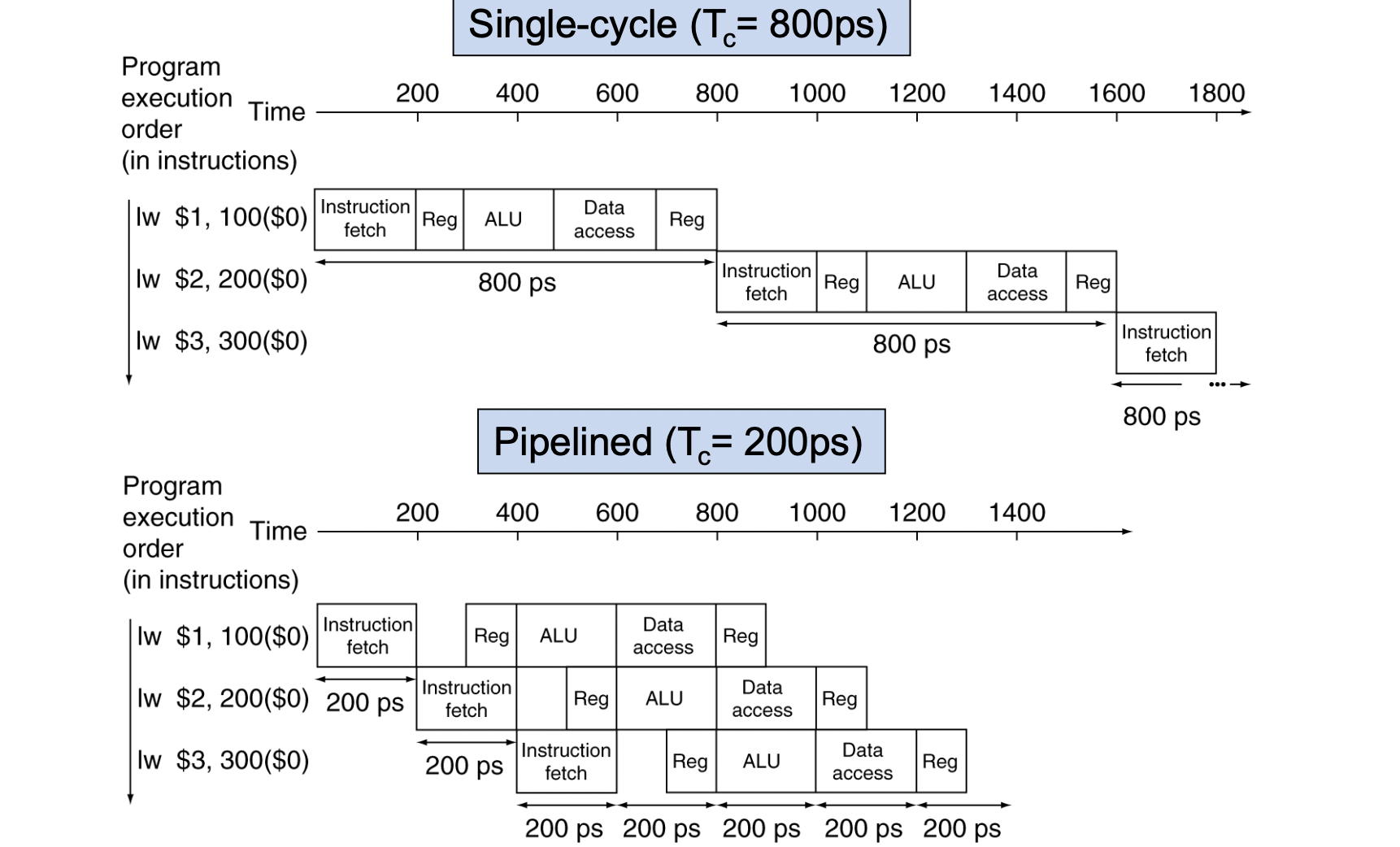
- 첫 번째와 네 번째 instruction 사이의 시간을 생각해 보면,
single cycle일 때는 800 3 = 2400ps이고
pipelined에서는 200 3 = 600ps임을 확인할 수 있다.
Speedup
-
단계들이 완벽하게 균형을 이루고 있을 때 (all stages are balanced)
명령어 사이의 시간(pipelined)
= 명령어 사이의 시간(nonpipelined) / 파이프 단계 수 -
이상적인 조건 하에 pipelining에 의한 속도 향상은 파이프 단계 수와 거의 같다
-
균형을 이루고 있지 않으면, speedup is less
ISA Design
MIPS ISA는 pipelining을 위해 설계되었다
(MIPS is good for a pipeline technique)
-
All instructions are 32-bits
(모든 명령어는 같은 길이를 갖는다)-
이는 첫 번째 pipeline에서 명령어를 가져오고
그 명령어들을 두 번째 단계에서 해독하는 것을 훨씬 쉽게 해준다
(Easier to fetch and decode in one cycle) -
c.f. x86같은 경우 명령어 길이가 1바이트부터 15바이트까지 변하기 때문에 파이프라이닝이 매우 힘들다
-
-
Few and regular instruction formats
(몇 가지 안 되는 명령어 형식을 가지고 있다)- 모든 명령어에서 근원지 레지스터 필드는 같은 위치에 있기 때문에,
두 번째 단계에서 하드웨어가
어떤 종류의 명령어가 인출되었는지 결정하는 동안
레지스터 파일 읽기를 동시에 할 수 있다.
(Can decode and read register in one step)
- 모든 명령어에서 근원지 레지스터 필드는 같은 위치에 있기 때문에,
-
Load / Store addressing
(메모리 피연산자가 load와 store 명령어에서만 나타난다)- 3번째 단계에서 메모리 주소를 계산하고
4번째 단계에서 메모리에 접근한다
- 3번째 단계에서 메모리 주소를 계산하고
-
Alignment of memory operands
(피연산자는 메모리에 정령되어 있어야 한다)- 하나의 데이터 전송 명령어가 두 번의 메모리 접근을 요구할까 봐 걱정할 필요 없다
(Memory access takes only one cycle)
- 하나의 데이터 전송 명령어가 두 번의 메모리 접근을 요구할까 봐 걱정할 필요 없다
Hazards
Cannot start next instruction in next cycle
-> 3가지 이유가 있다.
- Structure hazards
- a required resource is busy
- 세탁기&건조기가 붙어 있는 경우, 친구가 바빠서 빨래를 치우지 않은 경우
- Data hazards
- Need to wait for previous instruction to complete its data read/write
(어떤 명령어가 앞선 명령어에 종속성을 가질 때)
- Need to wait for previous instruction to complete its data read/write
- Control hazards
- Deciding on control action depends on previous instruction
(다른 명령어들이 실행 중에 한 명령어의 결과 값에 기반을 둔 결정을 할 필요가 있을 때)
- Deciding on control action depends on previous instruction
