Hazard
Structure Hazards
-
Conflict for use of a resource
-
load와 store는 data access를 요구한다.
만약 메모리가 하나라면, 둘이 동시에 메모리에 접근하려 할 때, structure hazard가 발생하게 된다

-
위 그림에서 첫 번째(lw)와 네 번째(add)가 clock cycle 3에서 같이 메모리에 접근하려 하고 있다.
-
이러한 사이클에서는 instruction fetch가 stall하게 되고, bubble을 발생시킨다
-
Hence, pipelined datapath requires seperate instruction/data memories or seperate instruction/data caches
Data Hazards
-
instruction depends on completion of data access by a previous instruction
-
add $s0, $t0, $t1
sub $t2, $s0, $t3
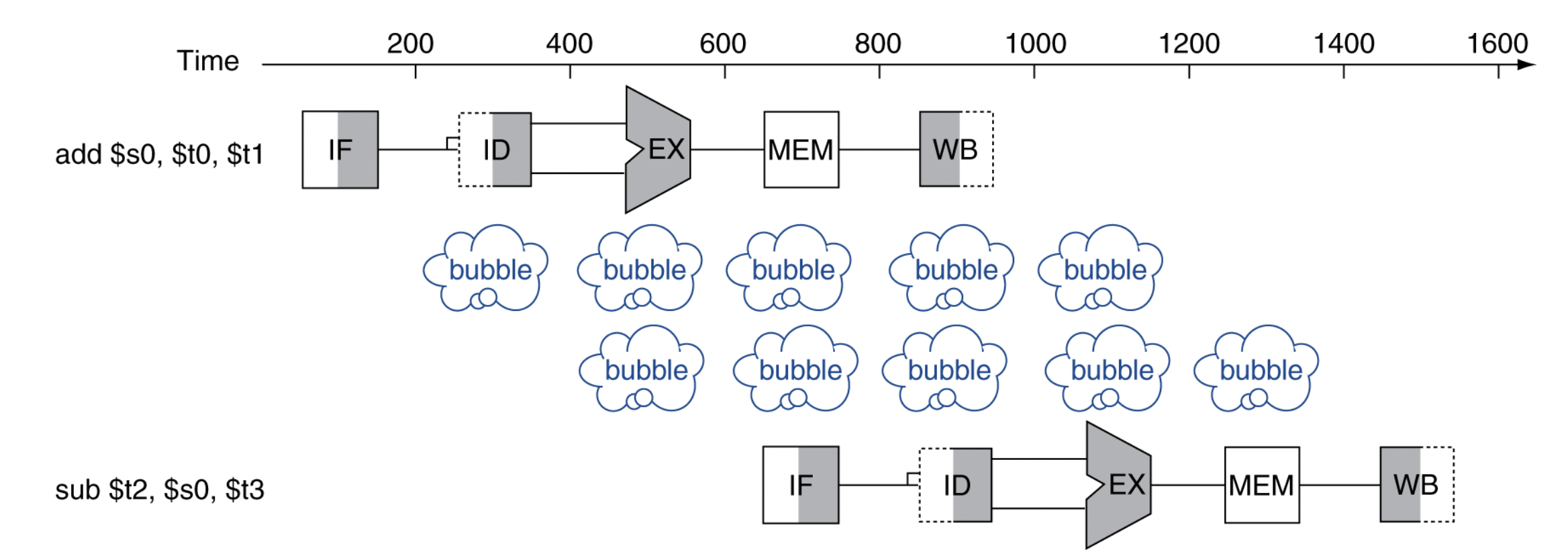
-
첫 번째(add)에서 $s0에 값이 써지는 순간은 WB이다.
두 번째(sub)에서는 $s0를 ID에서 읽으려고 한다 -
그래서 중간에 "nop instruction"을 삽입한다
nop : special instruction not doing anything -
이러한 이슈를 해결하기 위해 fowarding을 사용한다
Forwarding (aka Bypassing)
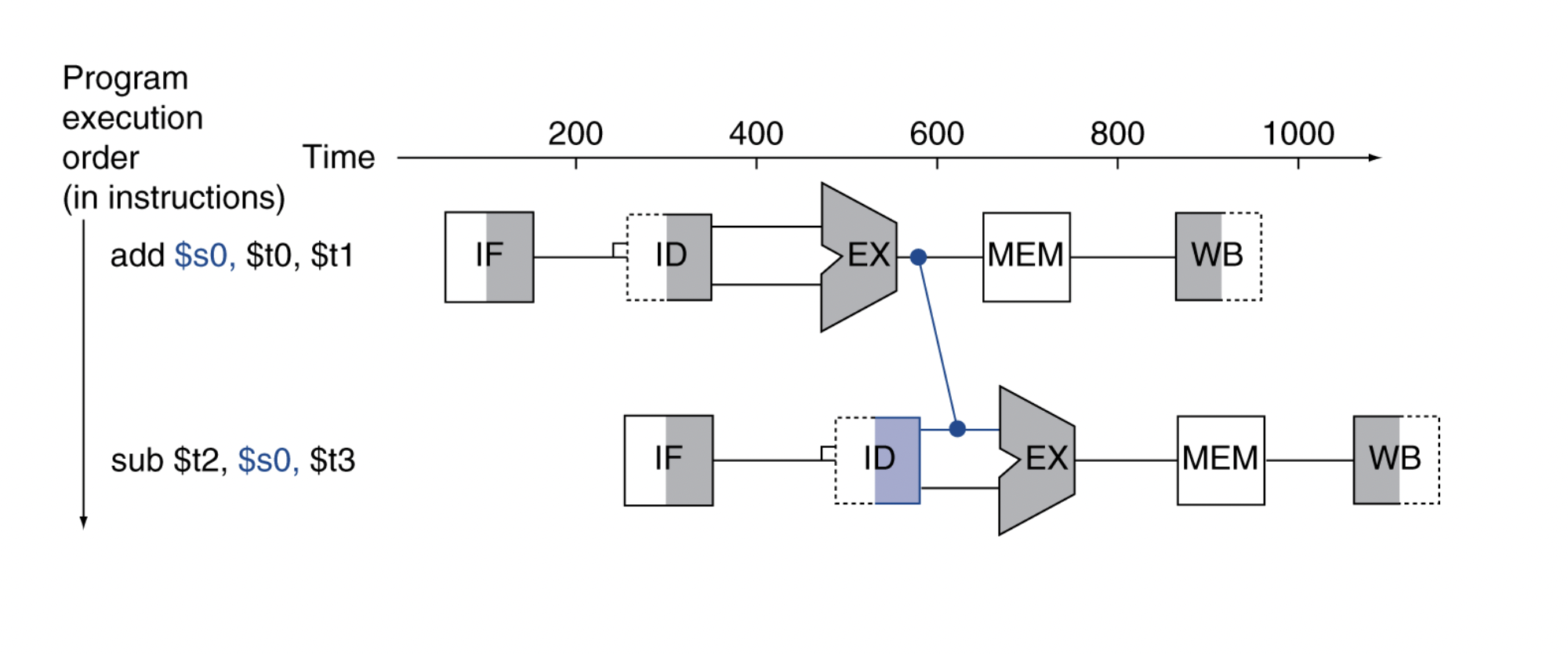
-
register에 값이 저장되는 걸 굳이 기다리지 않고
계산이 끝나자마자 결과를 사용한다 -
require extra connections in the datapath
-
당연하지만 목적지 단계가 근원지 단계보다 시간상 늦을 경우에만 fowarding 통로가 유효하다
Can't foward backward in time
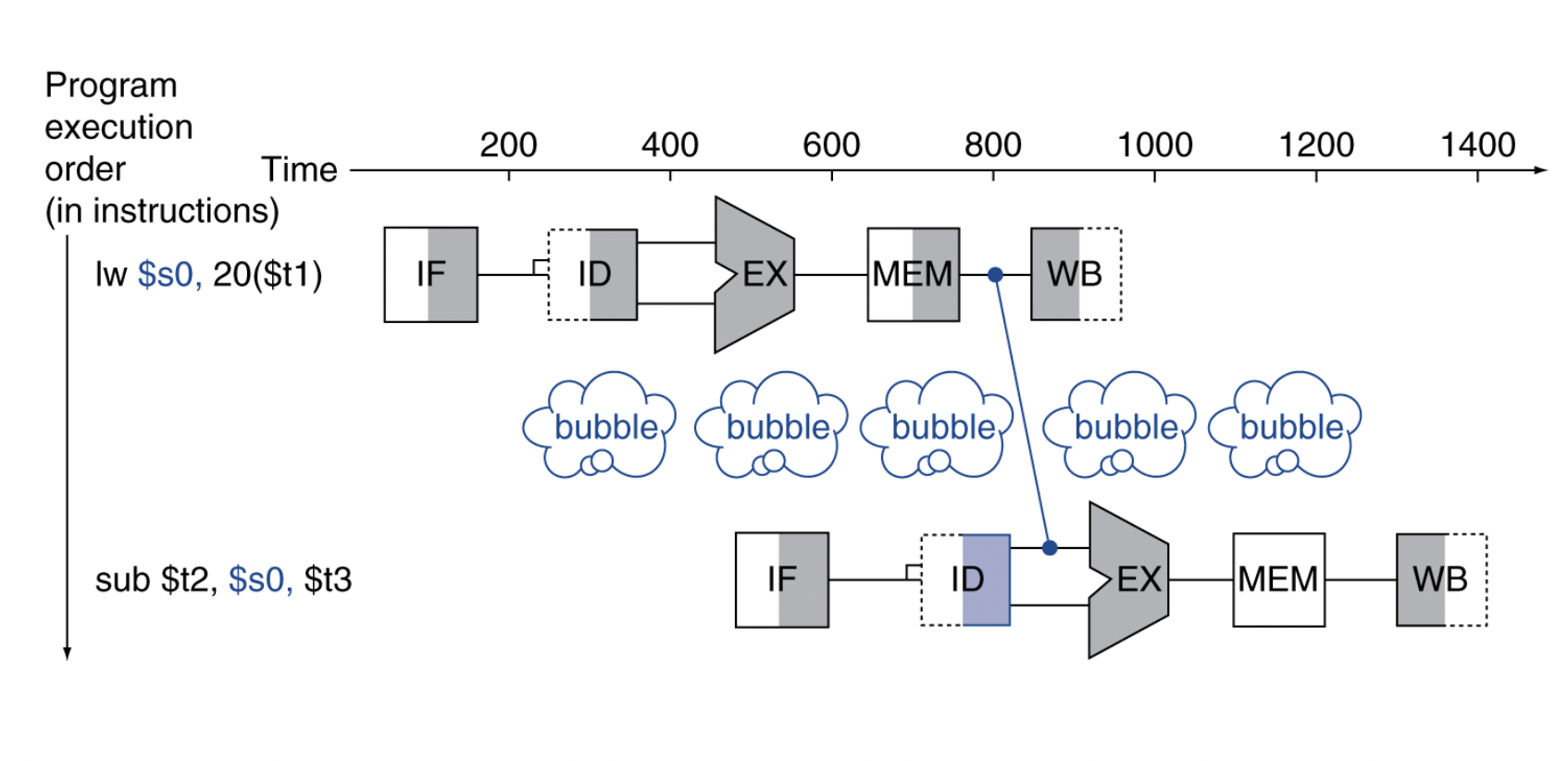
Load-Use Data Hazard
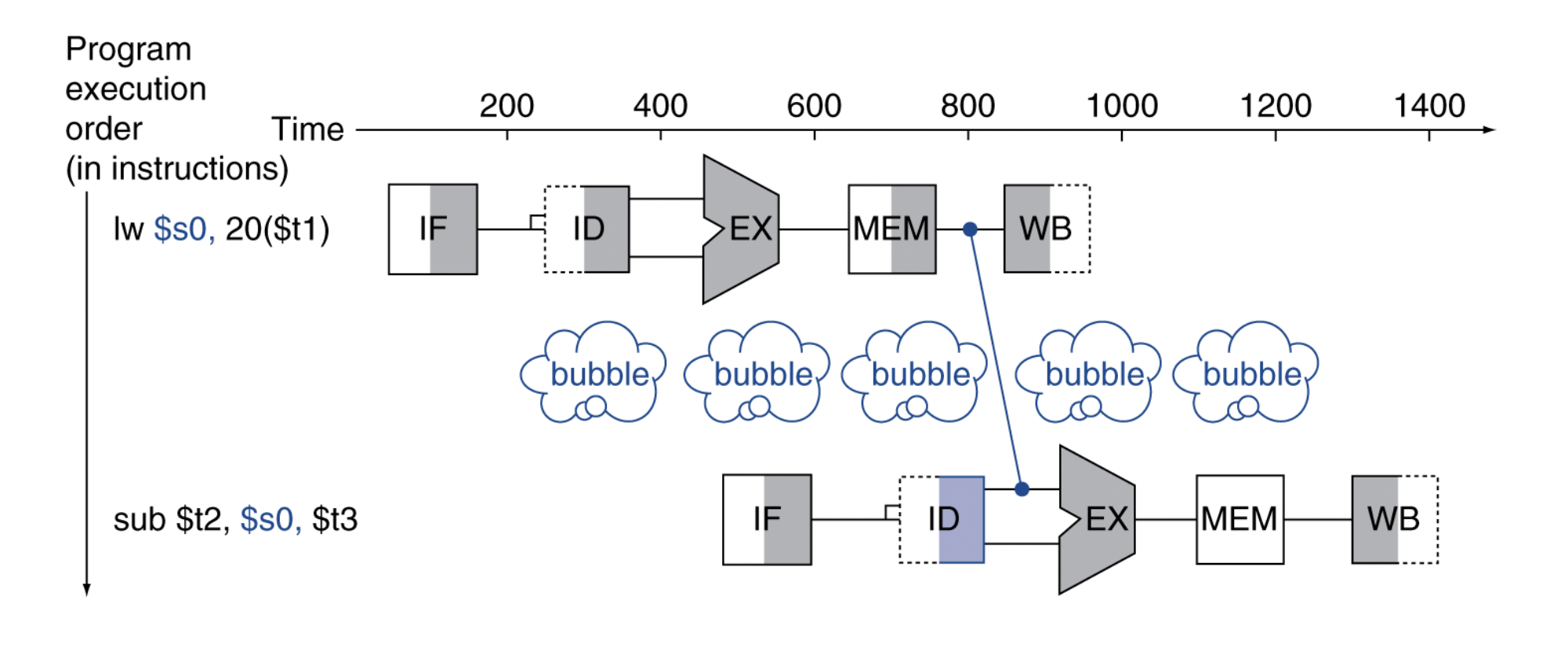
-
load 명령어 다음에 R type 명령어가 데이터를 사용하려고 하면
forwarding을 해도 bubble이 필요하다 -
Value is NOT computed when needed.
-
No way to avoid bubble in this case, it's the only way
Code Scheduling to Avoid Stalls
// c code
a = b + e;
c = b + f;위 C code를 어셈블리 code로 나타내면,

- 왼쪽 경우에서, 두 add가 모두 바로 앞에 lw가 있기 때문에 stall이 걸린다
- 오른쪽 경우처럼, 먼저 load를 다 해버리고 순차적으로 add를 진행하면 stall이 하나도 생기지 않기 때문에 2 cycle을 절약할 수 있다.
Control Hazards
- Branch determines flow of control
- 다음 instruction에 fetching하는 것은 branch의 결과에 의존한다
- 하지만 pipeline은 바로 다음 clock cycle에서 branch 다음의 명령어를 준비해야 하는데, 그게 뭐가 되어야 할 지 알지 못한다.
왜냐하면 이제 방금 branch 명령어를 받았기 때문이다.
-
첫 번째 방법 : 결과 나올 때까지 bubble 넣고, 결과 나오면 다음 진행한다
가정 : to compare registers and compute target early in the pipeling (in ID stage), add hardware.
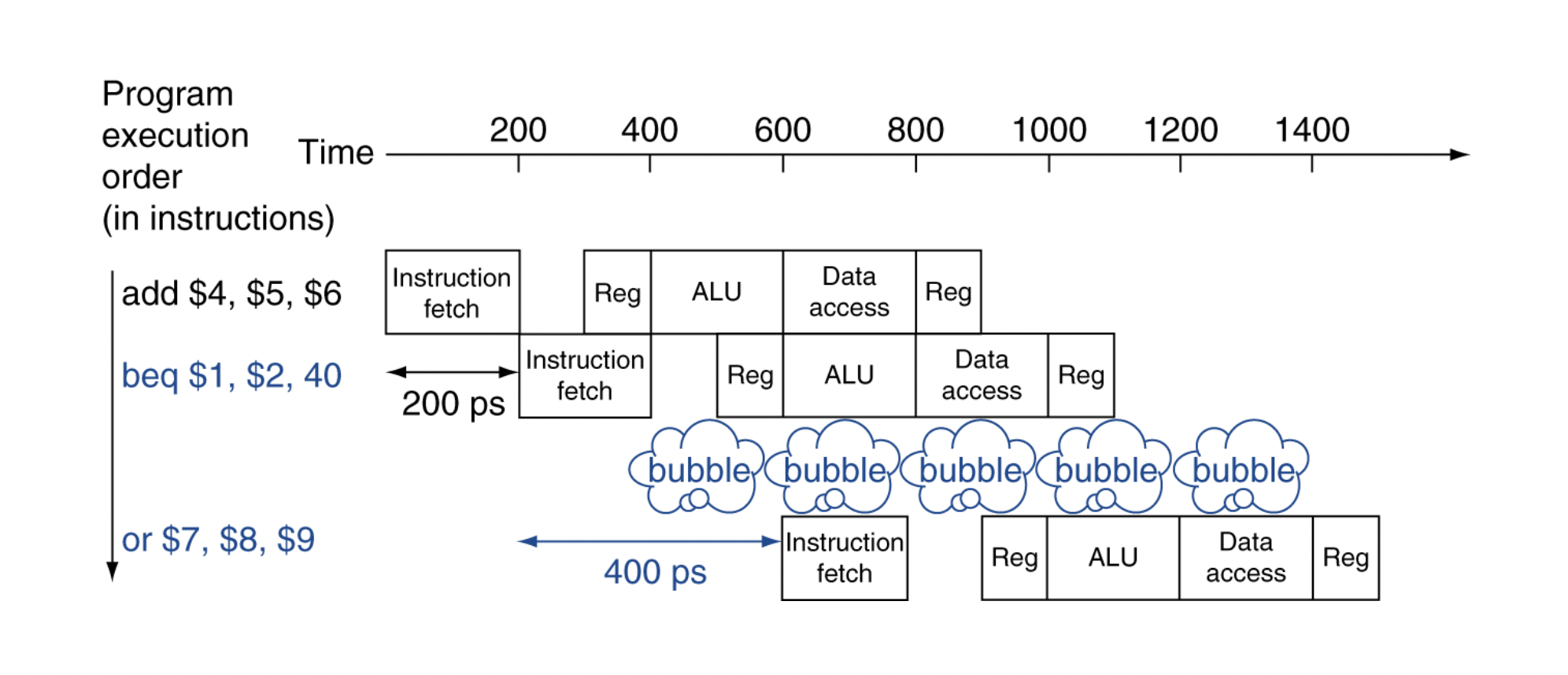
-
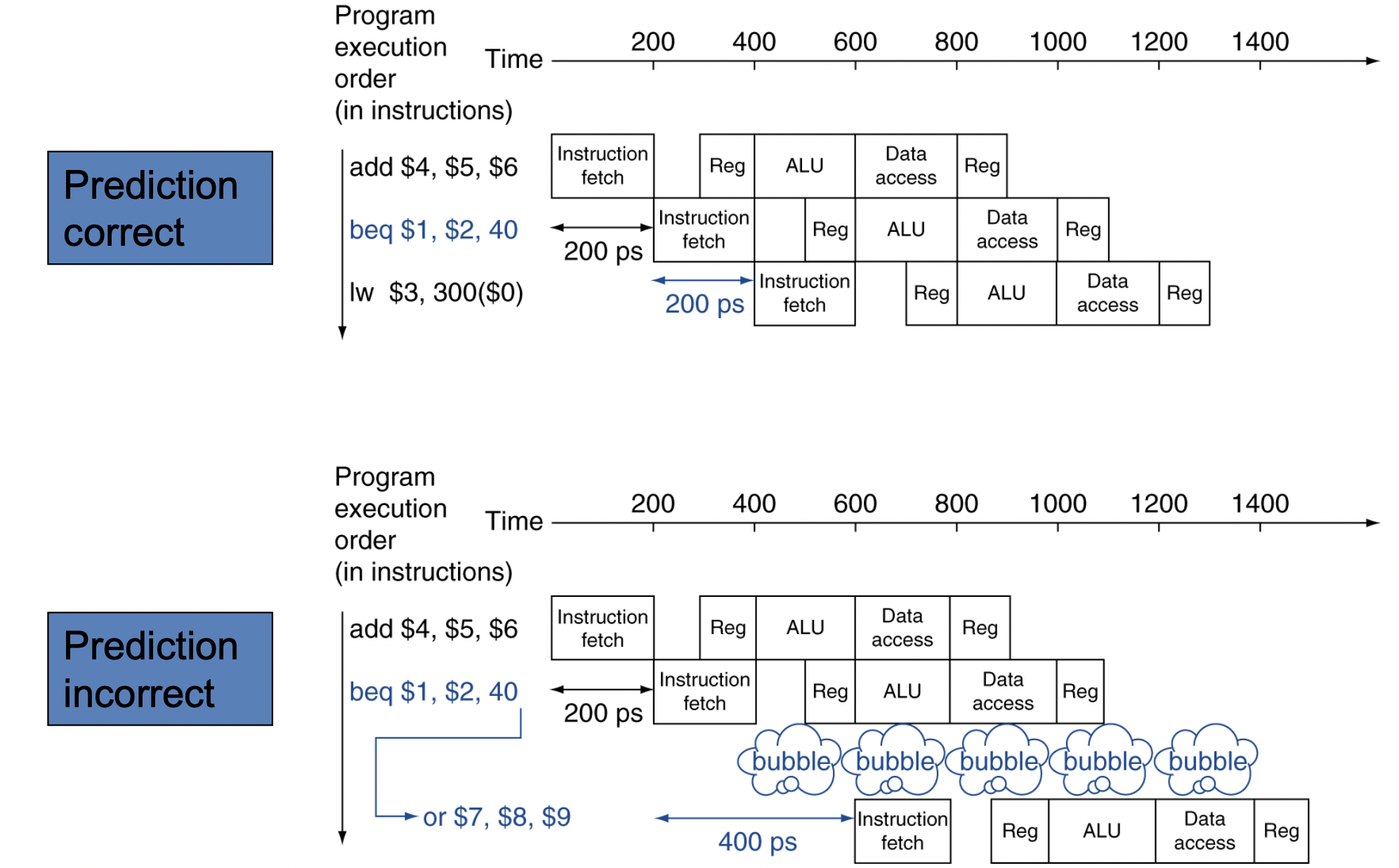
두 번째 방법 : branch가 무조건 실패한다고 예측한다
-
예측이 맞으면 최고 속도로 진행되고, 예측이 틀리면(분기가 일어나면) bubble이 추가된다.
Summary
- Pipelining은 instruction throughput을 향상시켜서 성능을 올려준다.
- execute multiple instructions in parallel
- each instruction has the same latency
- Instruction set design affects complexity of pipeline implementation
