
Introduction
이번에 리뷰할 논문은 Byte Latent Transformer논문이다.
기존의 encoding 방식이 정말 최선인지에 대해 의문점을 제시하고 byte단위의 encoding방식이 token단위의 encoding보다 낫다는 것을 보여는 논문이다.
왜 Byte기반 encoding을 하는 것이 좋을까?
기존의 LLM은 input을 subword나 token단위로 나눠 사용하는데 이 과정을 tokenizer를 사용하여 처리한다. 이때 tokenizer는 미리 정의한 vocab을 기반으로 작동을 하기 때문에, 특정 언어에 최적화되어 있는 경우가 많다. 다국어 데이터를 처리할때는 vocab의 사이즈가 굉장히 커지기 때문에 계산량이 많아져 모델이 무거워지는 문제도 발생한다. 이때 token단위가 아닌 byte단위로 input을 나눠서 사용하면 vocab자체가 필요없기 때문에 모델이 무거워지는 문제도 피할 수 있고 여러 데이터(코드, 이모지)에 대해서 균등한 추론이 가능해지는 것이다.
Byte Latent Transformer

Byte를 사용해서 모델에 집어 넣는다는 생각은 매우 좋지만, Byte의 개수도 생각을 해야한다. 거의 대부분 문장을 token단위로 나누는 것보다 Byte로 나누는 개수가 훨씬 많기 때문에 모델의 연산량이 많아진다는 문제가 있다.(하나의 input당 모델 전체를 forwarding하는 것은 동일하기 때문) 이를 막기 위해 patching이라는 개념이 도입되었다.
pathing이란 Byte input의 일부에 대해서 Local Encoder를 사용하여
하나의 묶음으로 묶어주는 것이다. 정보를 압축하여 latent space에 놓는 것이다. 그리고 이 latent sapce를 각각 patch라고 부른다.
여기에 필요한 것이 하나 더 있는데 문장을 하나의 패치로 만드는 것은 아무 의미가 없기 때문에 Byte를 나누는 기준도 만들어주어야한다.
정의된 Entropy값이 아래 그래프의 빨간 선을 넘을 경우 이 Byte를 해당 패치의 마지막 Byte로 정의한다.

아래 그래프의 회색 선이 patch의 구분 단위이다.
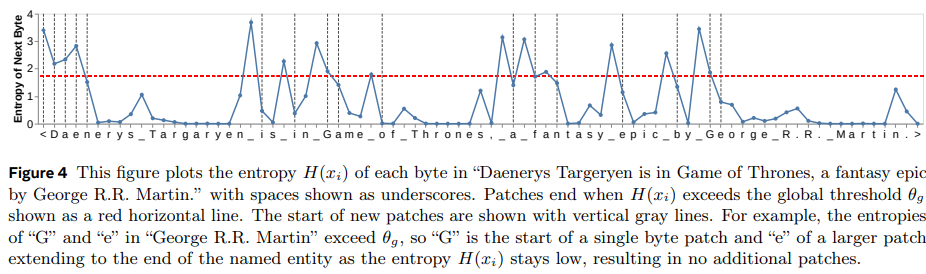
그렇다면 를 어떻게 계산할까?
수식의미( Global Constraint )
- : i번째 byte를 예측한 값
- : 이전 byte들을 참고해서 byte를 예측할 확률
여기에는 엔트로피를 측정하는 작은 모델을 하나 두었다고 한다.
이렇게 측정된 예측의 불확실성 값을 사용하여 경계를 나누는 것이다.
-
: byte들을 계속해서 현재 만들고 있는 patch에 집어넣음
-
: 현재 patch단위를 끊고 다음 patch 만들기 시작
장점
- 데이터의 불확실성에 따라 계산 자원을 동적으로 분배.
- 예측 난이도가 낮은 구간(반복적 패턴 등)은 큰 패치로 묶어 효율성 증대.
이렇게 묶인 byte값에 대해 Local Encoder에 넣기 전 N-gram의 방식을 적용시켜준다.
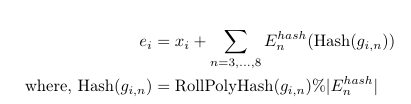
각각의 들은 one-hot 형태로 표현된다. (이 의 개수라고 한다면 두번째 는 0000 0001로 표현가능)
이렇게 만들어진 와 N-gram의 값을 Hashing한 값의 평균값과 더해준 것을 local encoder의 input으로 사용하는 것이다.
이후 그렇게 만들어진 byte의 embedding들을 묶어서
로 표현한다.
- : byte의 embedding
- : 시작 byte( patching의 첫 byte )
- : 끝 byte
이후 이렇게 만들어진 에 를 local encoder에 집어넣는다.

는 우리가 구한 에 대해 pooling을 적용한 값이다.
풀링 방법:
맥스 풀링(Max Pooling): 패치 내 바이트 임베딩 중 최대값을 선택.
평균 풀링(Average Pooling): 패치 내 바이트 임베딩의 평균을 계산.
BLT는 기본적으로 맥스 풀링을 사용.
pooling을 적용하여 embedding을 고정된 크기의 vector로 맞춰준다고 한다.
이후 Multi-Headed Cross-Attention을 적용한다.
공식은 다음과 같다.
- : 초기 patch표현
- : 패치 에 표함된 바이트 임베딩들
이 과정에서 바이트 수준의 정보를 통합하여 보고 생성할 byte의 정보를 포함하고 있는 patch를 생성한다.
이후 완성된 patch를 잠재정보를 분석하는 latent Transformer로 넣는 것이다.
Local encoder와 Local Decoder의 계산과정을 그림으로 표현하면 다음과 같다.

Transformer에서 Local Decoder의 과정을 정리하자면 다음과 같다.
패치 표현을 바이트 시퀀스로 디코딩
-
글로벌 트랜스포머의 출력을 입력으로 받아, 각 패치를 바이트 단위로 복원.
-
바이트 단위로 다음 값을 예측:
바이트 시퀀스를 점진적으로 생성(AutoRegressive 방식). -
패치와 바이트 간 관계 유지:
패치 수준에서 요약된 정보를 바이트 수준으로 정확히 확장.
patch에서 byte로 돌리는 과정의 수식

Transformer를 거쳐온 patch를 와 이전에 Decoding된 byte의 hidden state 가 같이 사용된다.
초기 입력상태를 라고 한다면, Decoder의 크로스 어텐션 연산은 다음과 같다.
Query 연산
- : 디코더 번째에서 나온 i번쨰 hidden state
- : Query 생성에 사용되는 선형변환
Key, Value연산
- : 패치 표현 에 대한 선형변환과 split
이 Q, K, V에 대해 Attention을 수행한다.
이후 Decoder의 Hidden state는 다음의 식으로 업데이트된다.
- W_o: 출력의 선형변환
바이트 복원
최종 decoder hidden state 를 사용하여 byte를 예측한다.
- : 바이트 크기의 embeddig dim V크기의 선형변환 행렬
결과적으로 각 바이트에 대한 확률분포를 출력할 수 있는 것이다.
Experiments
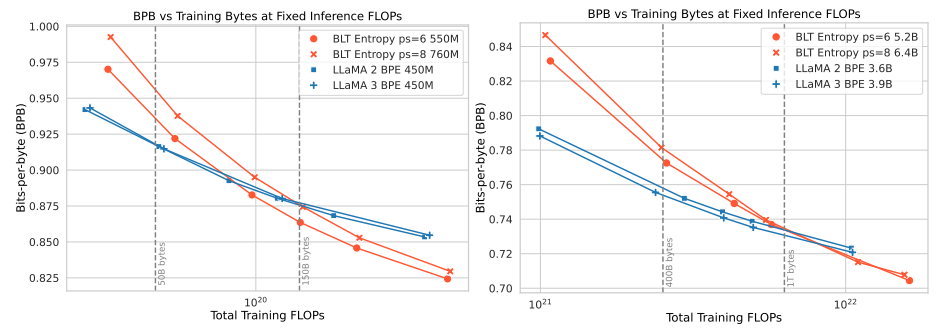
추론시 GPU의 점유율은 고정시킨 채로 모델의 크기를 키울 수 있다.
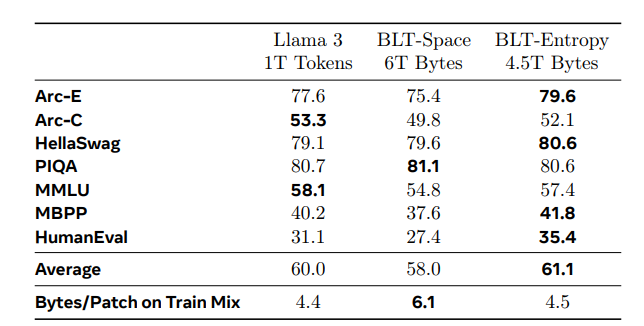
동일한 Training Bucket 상에서 BLT가 성능이 가장 좋은 것을 알 수 있다.
Downsteram task
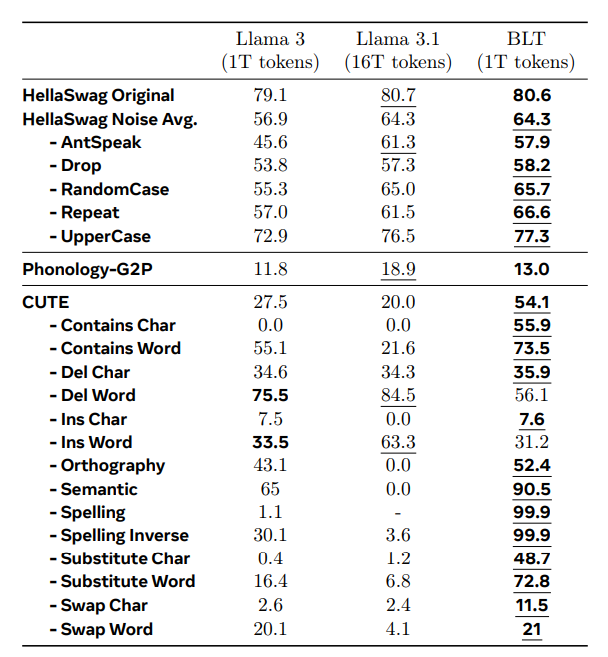
노이즈가 포함된 데이터에서 좋은 성능을 보인다는 것을 확인할 수 있다.
문자단위의 처리가 필요한 경우에도 다른 모델보다 좋은 성능을 보인다.
