
Introduction
Transformer가 거의 모든 분야를 장악한 후 대부분의 연구진들은 Transformer를 뛰어넘을 아키텍쳐가 나올 것인가? 라고 생각한다.
현재 Mamba가 Transformer를 대체할 아키텍쳐라고 불리고 있다.
추론 속도가 transformer보다 빠르지만 성능은 비슷한 수준이라고 한다.
앞으로 계속해서 발전시킨다면 Transformer보다 성능이 좋아질 수도 있다고 생각한다.
이 글에서는 Mamba가 어떻게 이전 연구의 단점을 극복하고 작동하는지에 대해서 살펴보려고 한다.
Mamba의 비교대상인 Transformer
우선 Transformer의 텍스트 생성모델을 간단하게 살펴보자. Transformer의 장점은 입력 값이 무엇이든, 이전 시퀀스의 토큰을 참고할 수 있어서 해당 표현을 뽑아내기 쉽다는 점이다.
모델의 구성을 보면 텍스트를 받아서 Encoder에 들어가고 그 후에 Decoder블럭을 통과한다. 이 구조를 사용하여 생성모델을 만들 수 있다.
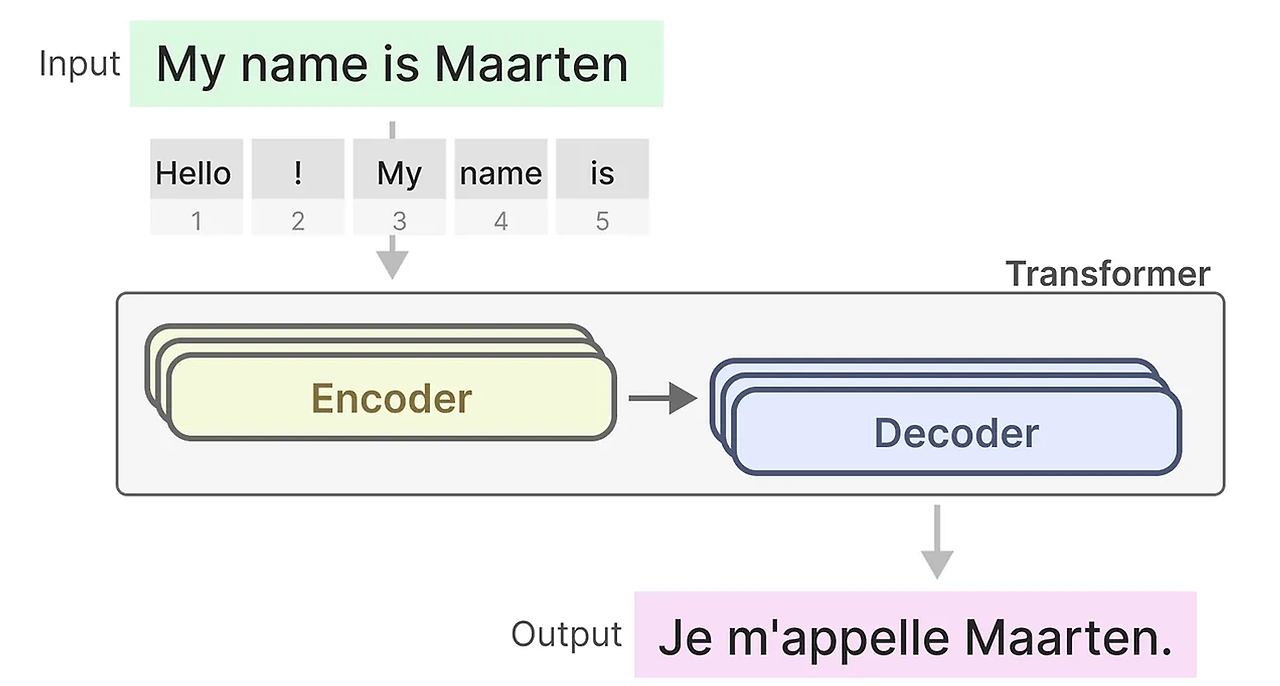
우리가 잘 알고있는 트랜스포머 기반 모델 GPT는 이 Transformer의 Decoder 블럭을 사용하여 텍스트를 완성하는 것이다.
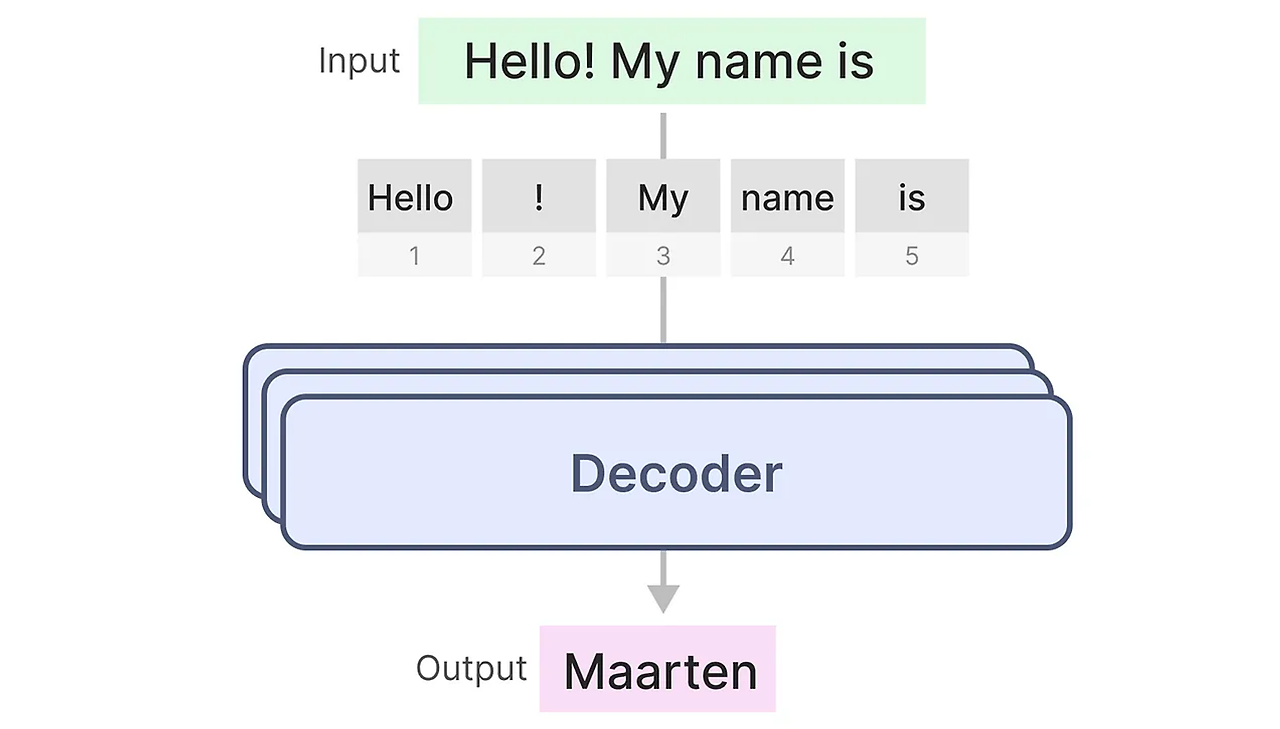
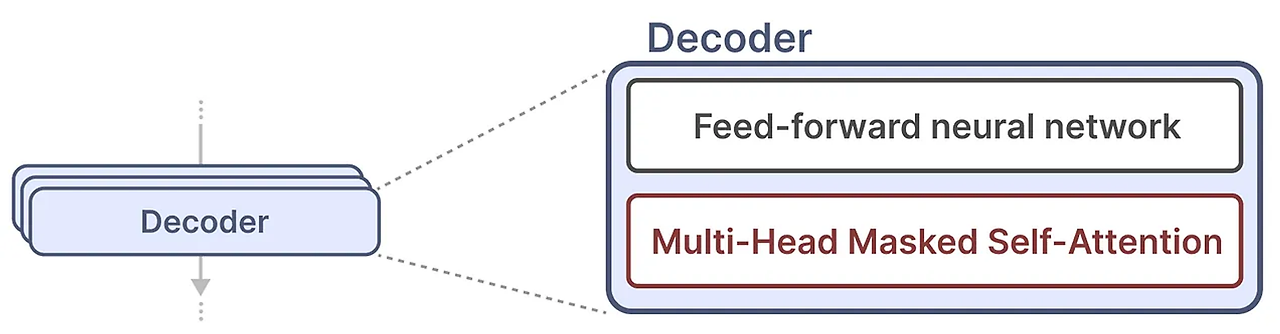
하나의 Decoder 블럭은 masked self-attention과 feed-forward 신경망으로 구성되어 있다.
self-attention은 모델을 구성하는 핵심요소 중 하나이다. self-attention은 전체 시퀀스에 대해서 압축되지 않은 관점을 제공하여 전체 문장에 대해 보다 정확한 표현을 할 수 있다. 각 토큰은 이전의 토큰과 비교하여 행렬을 생성하게 되고 행렬의 가중치는 이전 토큰들의 유사도이다. 이는 병렬처리가 가능하여 훈련 속도를 높일 수 있게 한다.
하지만 다음 토큰을 생성할 때, 일부 토큰을 생성했다고 하더라도 전체 시퀀스에 대한 attention을 다시 계산해야 한다.
길이가 L인 시퀀스에 대한 토큰을 계산하기 위해서는 만큰의 연산이 필요하다.
그리고 시퀀스 길이가 늘어날 수록 연산비용이 증가한다.

시퀀스 길이에 따른 연산비용 증가가 Transformer의 가장 큰 단점이다.
SSM
SSM역시 트랜스포머, RNN과 마찬가지로 시퀀스 정보를 처리할 수 있다.
SSM은 Mamba의 가장 중요한 구성요소이다.
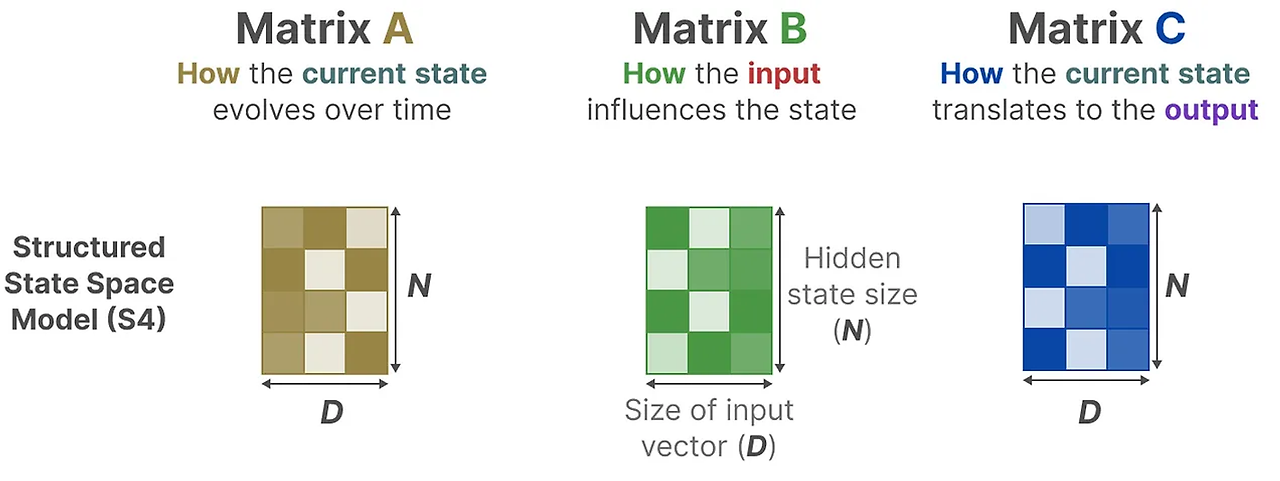
SSM은 연속형 변수를 저장해서 사용하는 방정식인데 우리는 시퀀스 정보를 처리하기 위해 이산화를 해서 사용한다.
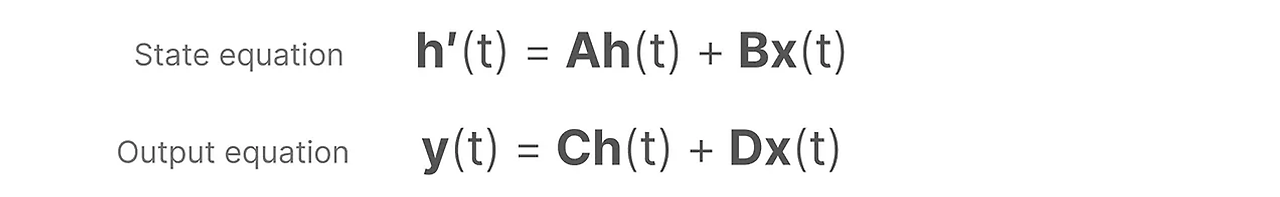
Mamba의 경우 이산화 과정은 ZOH를 사용한다.
Discrete time SSM의 수식을 보면 t가 커질수록 B와C는 고정된 상태에서 A만 계속해서 곱해지는 경향이 발생한다.
그렇기 때문에 이부분을 kernel로 정의하여 컨볼루션 형식으로 작성한다.

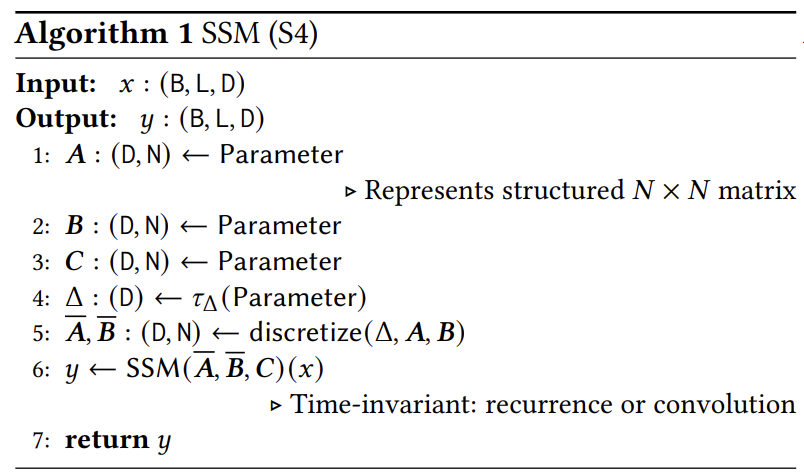
SSM을 풀어서 전개해보면 반복되는 계산이 많아 병렬화를 Traning시 속도가 느리다는 것을 알 수 있다. 그렇기 때문에 병렬화를 하여 Training을 효율적으로 한다.
병렬화는 Convolution을 사용하여 진행한다.
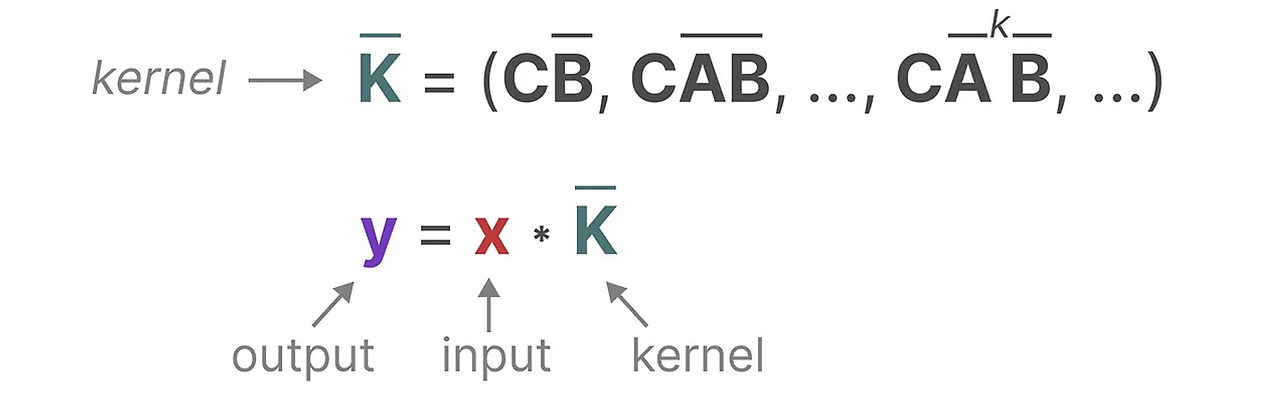
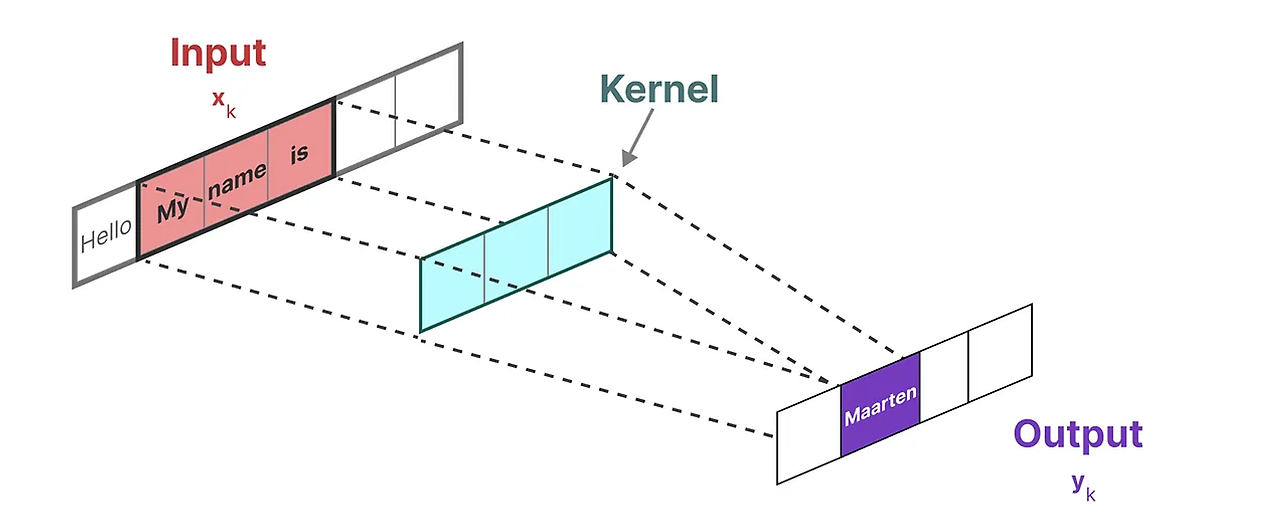
우리는 이 CNN의 "filter"를 나타내기 위해 사용할 Kernel을 SSM 공식에서 도출한다.
이 Kernel이 실제로 어떻게 작동하는지 보자. Convolution처럼 SS커널을 사용하여 각 token set을 통과하고 출력을 계산할 수 있다.
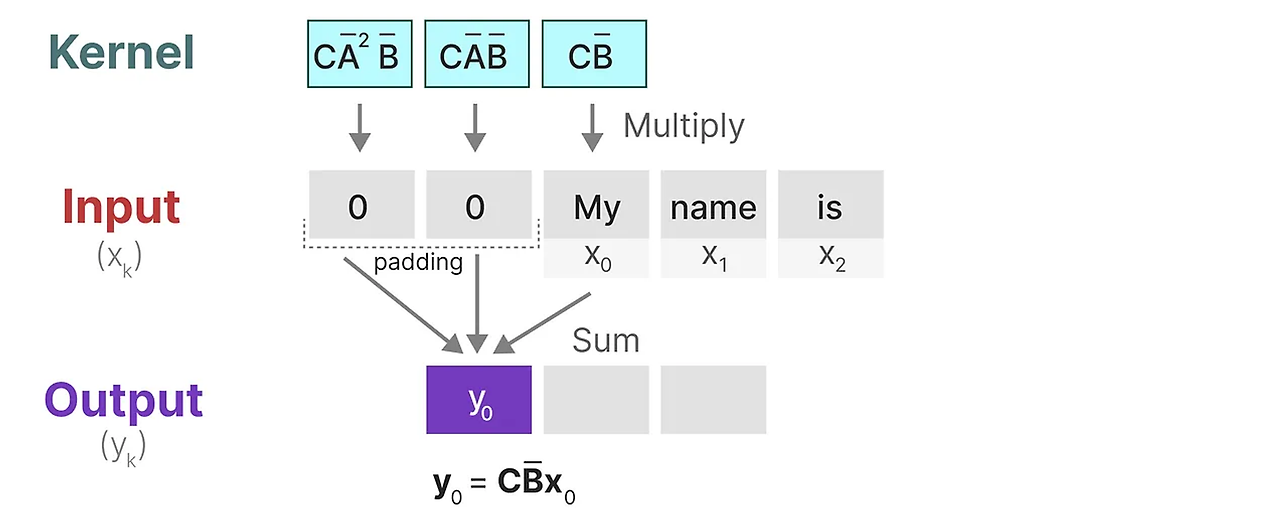
이것은 또한 padding이 출력에 미칠 수 있는 영향을 보여준다. 이해하기 쉽도록 시각화하기 위해 padding 순서를 변경했지만, 원래의 경우 대부분 문장 끝에 패딩을 적용한다.
다음 단계로, kernel은 다음 단계 계산을 수행하기 위해 이동한다
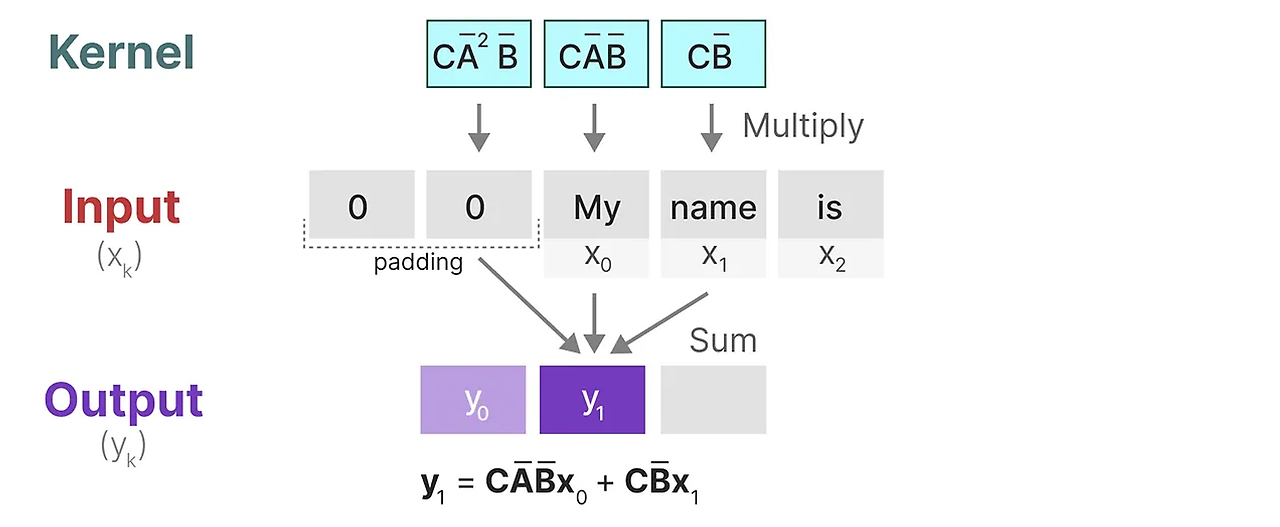
마지막 step에서, 우리는 커널의 전체 효과를 볼 수 있다.

SSM을 컨볼루션으로 표현하는 주요한 이점은 병렬적인 훈련이다. 하지만, 고정된 kernel의 크기 때문에, 컨볼루션의 추론은 RNN처럼 빠르고 무한하지 않다.
Convolution for LTI-SSM
Recurrent 모델은 이전 time-step 의 결과를 구해야 다음의 state를 계산할 수 있고, 이는 결국 sequence 길이가 길어질수록 학습이 상당히 느려지게 된다. 반면에 LSSL은 activation을 제거하면서 각 time-step 에 들어올 입력을 미리 알고 있다는 전제 하에, 전체 sequence에 대한 state를 한번에 구해낼 수 있다. 이는 근본적으로 이 모델이 Linear Time-Invariant (LTI) SSM, 즉 time-step t에 관계없이 항상 동일한 weight를 적용하는 형태를 전제했기 때문이다.
학습시에는 모델은 전체 입력을 미리 알고있으므로, 이 convolution 연산을 수행할 수 있다. 물론 완벽히 recurrent 방식처럼 무한한 길이에 대해 수행할 수 있는 것은 아니고, 대신 학습을 위해 모델을 fixed window size 의 convolution network로 근사한다고 이해해야 한다.
예를 들어 window size가 3인 경우, 다음과 같이 크기 3짜리 convolution kernel 를 만들 수 있는데,
=
이로부터 는 다음과 같이 계산된다.
학습시 모든 입력 를 이미 알고 있기 때문에, 전체 크기 K를 미리 구해놓으면 병렬 연산을 통해 모든 의 값을 한번에 계산할 수 있다.
물론 여기에는 이 kernel vector를 한번에 계산한다는 것이 전제가 된다.
참고로 행렬 는 HiPPO의 A에 해당한다.
SSM의 단점
여기까지 우리는 SSM의 작동방식과 장점에 대해 살펴보았다.
하지만 SSM은 치명적인 단점이 존재한다.
SSM을 지금까지 쓰지 않은 이유는 기억하는 장기 의존성은 뛰어나지만 특정 부분을 선택하는 작업에서는 성능이 굉장히 떨어지기 때문이다.
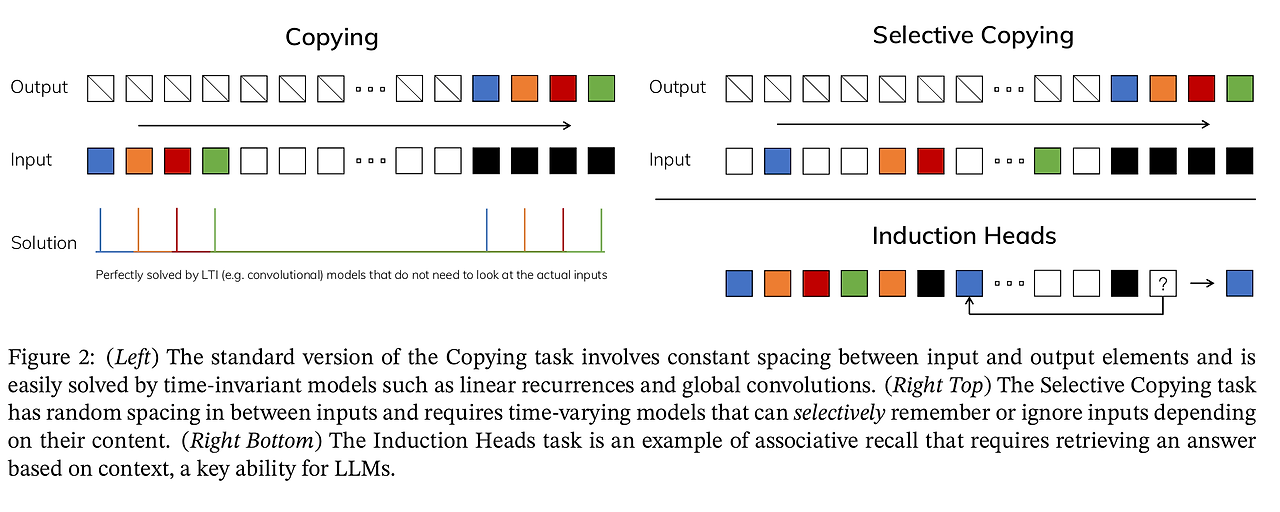
왼쪽의 예시는 입력을 한 번에 한 토큰씩 다시 쓰되, 시간 이동(Time-shift)을 적용한다. 이는 바닐라 SSM으로 수행할 수 있으며, 시간 지연은 컨볼루션 연산을 통해 학습할 수 있다.
하지만 선택적 복사의 경우(흰색 버튼을 제외한 나머지 색상을 추출)
이는 바닐라 SSM으로는 수행할 수 없는데, 이는 내용 인식 추론(content-aware reasoning)을 필요로 하기 때문이다. 바닐라 SSM은 시간 불변(Time invariant)하기 때문에 내용 인식 추론을 할 수 없다. 시간 불변이란 생성하는 모든 토큰에 대해 매개변수 A,B,C가 동일하다는 것을 의미한다.
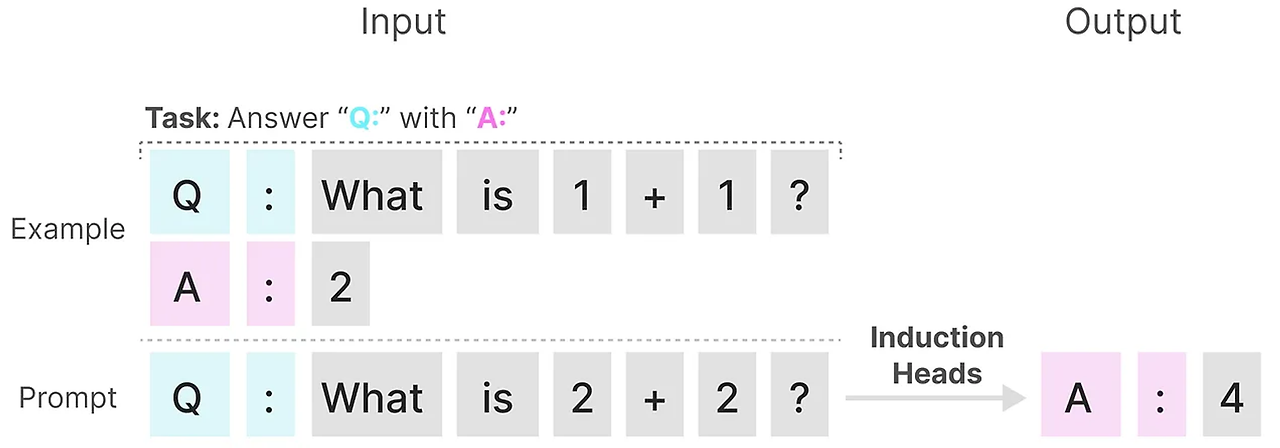
SSM의 성능이 떨어지는 두 번째 이유는 유도 헤드(induction heads) 때문이다.
아래의 예시에서 우리가 프롬프트를 제공한다고 가정해보자.
우리는 모델에서 Q후에 A응답을 제공하도록 가르치려고 한다. 그러나 SSM은 TI 특정을 가지고 있기 때문에 이전의 토큰 중 어떤 것을 기억할지 선택할 수 없다.
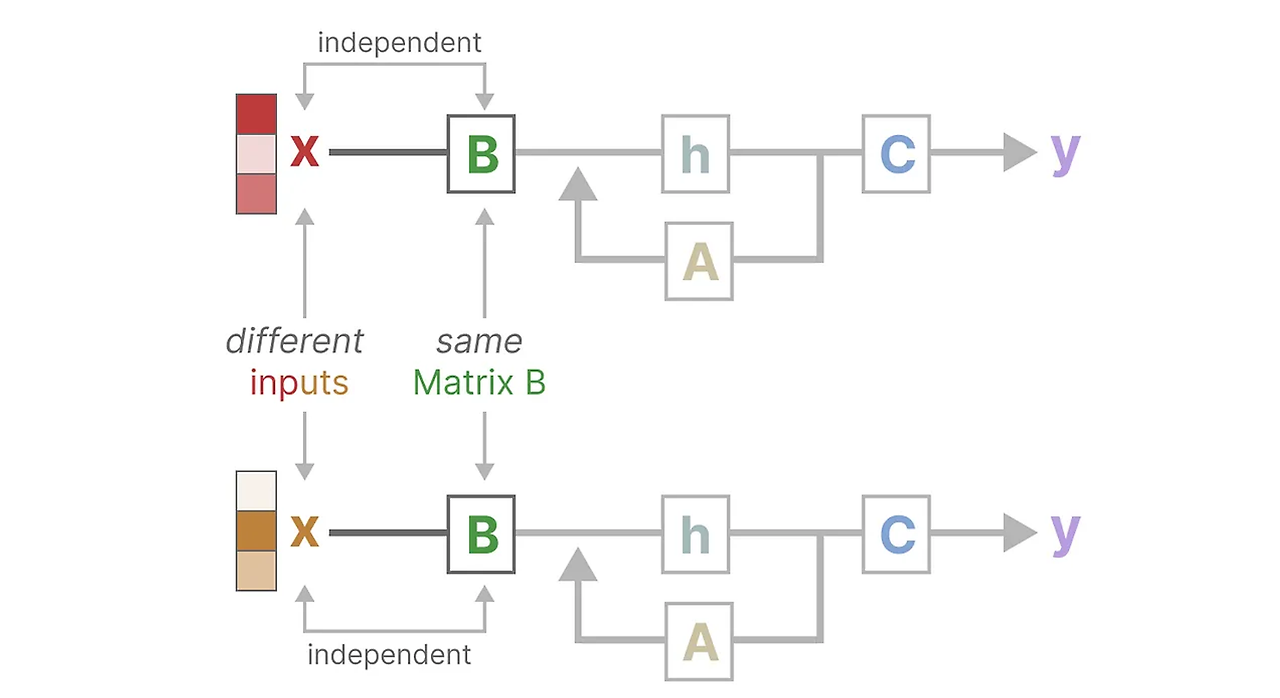
행렬의 관점으로 보자.
입력 x가 무엇이든지 상관없이 행렬 B는 동일하게 유지되기 때문에 x와 독립적이게 되고 마찬가지로 A와 C도 입력과 상관없이 고정이 되어있는 것이다.
따라서 프롬프트와 관계없이 SSM은 특정 응답을 제공하도록 훈련시키는 것이 매우 어렵다.
반면에 이러한 특정 문장을 뽑는 작업은 Transformer에서는 매우 쉽다.
트랜스포머는 어텐션을 사용하여 어떤 토큰에 집중을 할지 선택할 수 있기 때문이다.
SSM이 이러한 작업에서 성능이 떨어지는 것은 시간 불변성 SSM의 근본적인 문제, 즉 A, B, C 행렬의 정적인 특성으로 인한 내용 인식 문제를 시사한다.
Mamba
입력에 대해 independent 방식으로 처리하기 때문에 데이터를 효율적으로 선택하지 못하는 문제를 맘바에서는 선택 알고리즘을 추가하여 해결한다.
Mamba는 Transformer만큼 성능을 내면서 작은 크기를 유지하려고 하는데 이는 앞서 언급한 SSM처럼 데이터를 압축하면서 이뤄낼 수 있다. 하지만 정보를 선택적으로 압축하기 위해서는 입력에 따라 매개변수가 달라져야 한다.
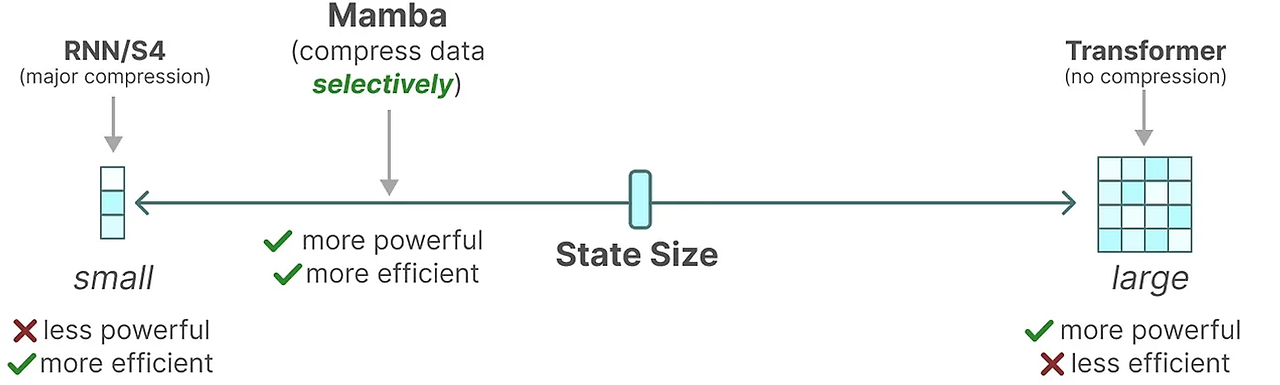

S4에서 행렬 A, B, C는 입력과 독립적이다. A, B, C의 차원 N, D는 정적이며 변하지 않는다.
대신, 맘바는 행렬 B와 C, 심지어 스텝 크기 를 입력에 의존한다.
이를 통해 모든 입력 토큰에 대해 서로 다른 B, C행렬을 가지도록 만든다. (매개변수를 변경)
따라서 행렬 A는 유지한채로 B, C의 유동적인 변화를 통해(입력값에 의존하여) 어떤 요소를 무시하고 선택할지 선택적으로 고를 수 있는 것이다.
여기서 다시 ZOH 이산화 방식을 살펴보자.

우리는 를 입력에 의존하도록 변경시킨다고 하였다. 이라고 가정을 해보자. 그렇게 된다면 는 1에 가까워지며 A값은 이전 hidden state값 그대로 들어가게 된다.
를 살펴보면 가 0이 되기 때문에 결과적으로 다음 hidden state값은 현재의 input이 무시된 채로 이전의 값이 그대로 들어간다는 것을 알 수 있다.
반대로 이라면 의 값이 커져 현재값을 더욱 중요하게 여기게 된다.
하지만 이제 B, C, 가 input에 따라 유동적이기 때문에 고정된 커널을 가정하는 Convolution방식을 더 이상 사용할 수 없다. (Time-invarient를 잃은 것!)
따라서 병렬화를 잃고 재귀적인 표현만을 사용할 수 있다.
여기서 저자는 속도의 개선을 위해 더이상 사용할 수 없는 Convolution 대신
Scan이라는 방식을 제안한다.
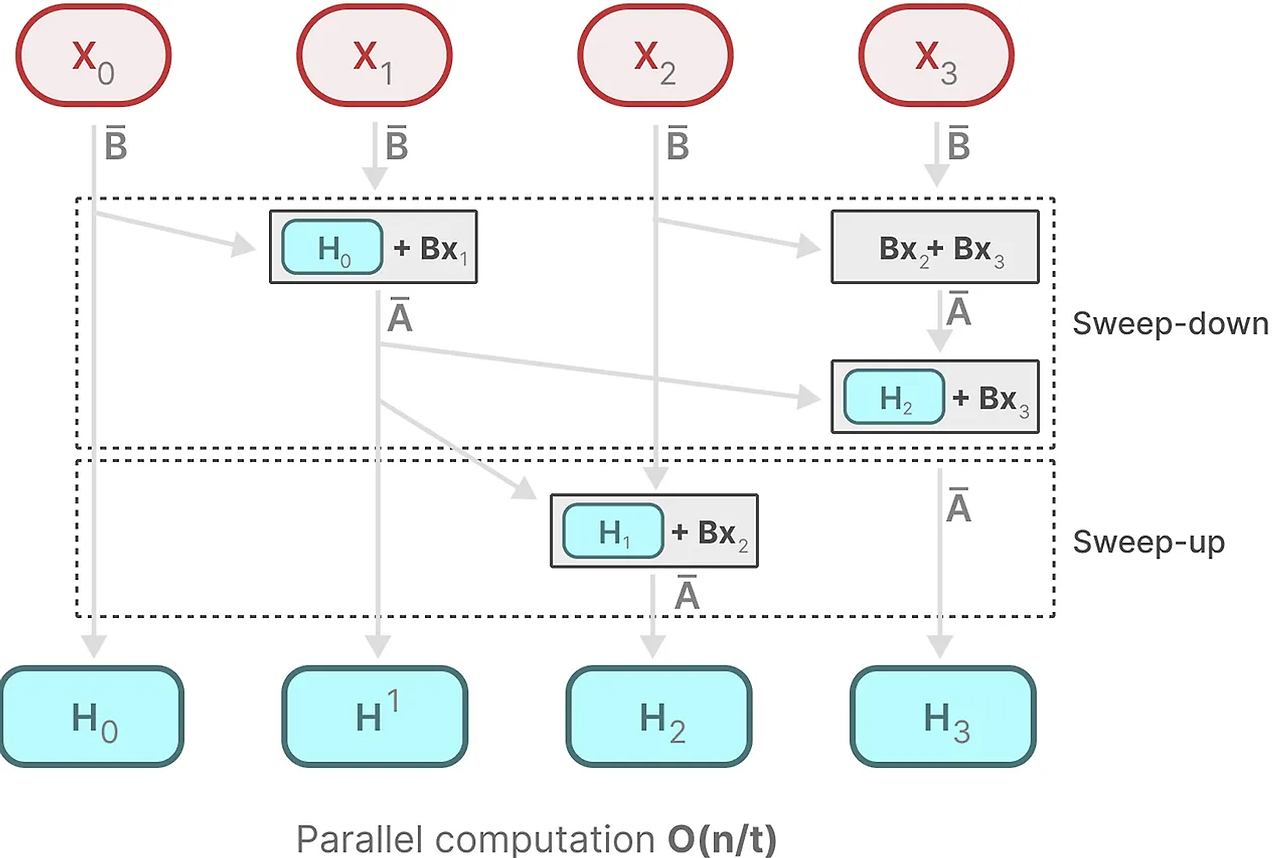
각 상태는 이전 상태(행렬 A에 의해 곱해진)와 현재 입력(행렬 B에 의해 곱해진)의 합이다. 이것을 Scan작업이라고 하며 루프를 이용하여 쉽게 계산할 수 있다. 여기서 Mamba는 병렬 Scan알고리즘을 사용하여 연산을 미리 할 수 있는 부분은 모두 수행하여 다음 연산시간을 줄인다.
(연산 순서가 중요하지 않다고 가정함)
여기까지 정리하자면 동적인 B, C행렬 그리고 병렬 Scan 알고리즘을 사용하여 동적이고 빠른 특성을 나타내는 선택적 스캔 알고리즘을 만들었다고 할 수 있다.
하드웨어 인식 알고리즘
최근 GPU의 단점 중 하나는 작지만 매우 효율적인 SRAM과 크지만 약간 덜 효율적인 DRAM 사이의 전송(IO) 속도가 제한되어 있다는 것이다. SRAM과 DRAM 사이에 정보를 자주 복사하는 것은 병목 현상이 된다.
딥러닝 프레임워크에서 텐서 연산 수행 시 , GPU의 HBM과 SRAM 간의 데이터 복사가 반복적으로 발생하게 되고 이것이 전체 수행 시간의 상당 부분을 차지하게 된다.
따라서 Mamba에서는 여러 개의 CUDA 커널을 하나의 커스텀 CUDA 커널로 융합하여 중간 결과를 HBM에 복사하지 않고 연산을 수행한다.
최종 결과만 HBM에 저장함으로써 연산 속도를 향상시킨 것이다.
Flash Attention에서도 비슷한 방식을 사용한다고 한다.
나중에 한번 찾아봐야겠다.
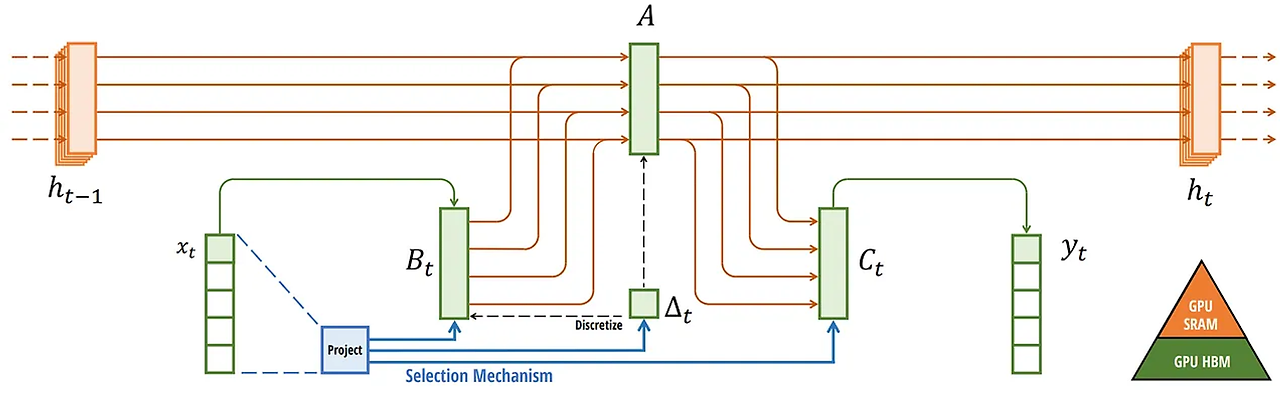
하드웨어 인식 알고리즘의 마지막 부분은 재계산이다.
중간 state들은 저장되지 않지만, Gradients를 계산하기 위해, backward pass에서 필요하다. 따라서, backward pass 동안 이러한 중간 states를 재계산한다. 이것은 비효율적으로 보일 수 있지만, 상대적으로 느린 DRAM에서 모든 중간 state를 읽는 것보다 훨씬 비용이 들지 않는다.
이제 최종 아키텍처를 아래의 그림과 같이 표현함으로써 묘사한 모든 구성요소를 나타낼 수 있다.
하드웨어 인식 알고리즘의 마지막 부분은 재계산이다.
중간 state들은 저장되지 않지만, Gradients를 계산하기 위해, backward pass에서 필요하다. 따라서, backward pass 동안 이러한 중간 states를 재계산한다. 이것은 비효율적으로 보일 수 있지만, 상대적으로 느린 DRAM에서 모든 중간 state를 읽는 것보다 훨씬 비용이 들지 않는다.
이제 최종 아키텍처를 아래의 그림과 같이 표현함으로써 묘사한 모든 구성요소를 나타낼 수 있다.
Mamba Block
우리가 지금까지 탐구한 Selective SSM은 Decoder Block에서 Self-attention을 나타내는 것과 같은 방식으로 블록을 구현할 수 있다.
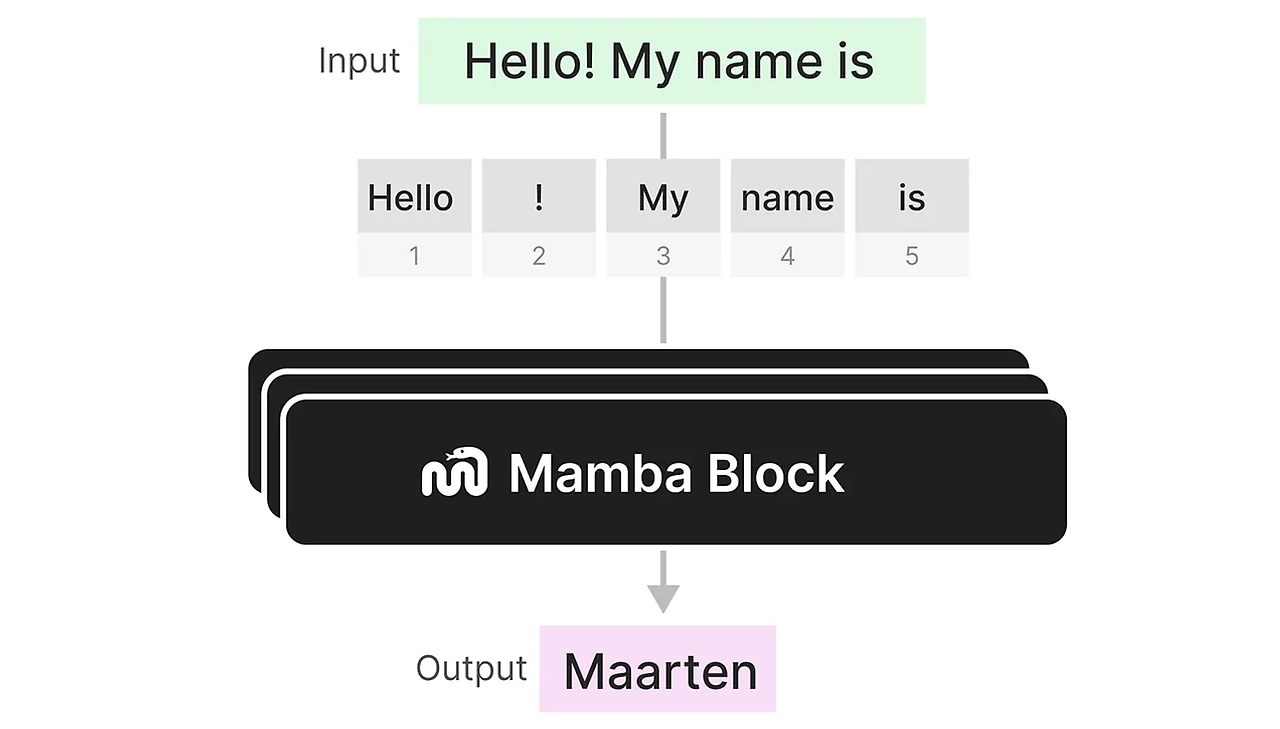
우리는 이제 여러 Mamba 블록을 쌓을 수 있으며, 그 출력을 Mamba 블록의 입력으로 사용할 수 있다.
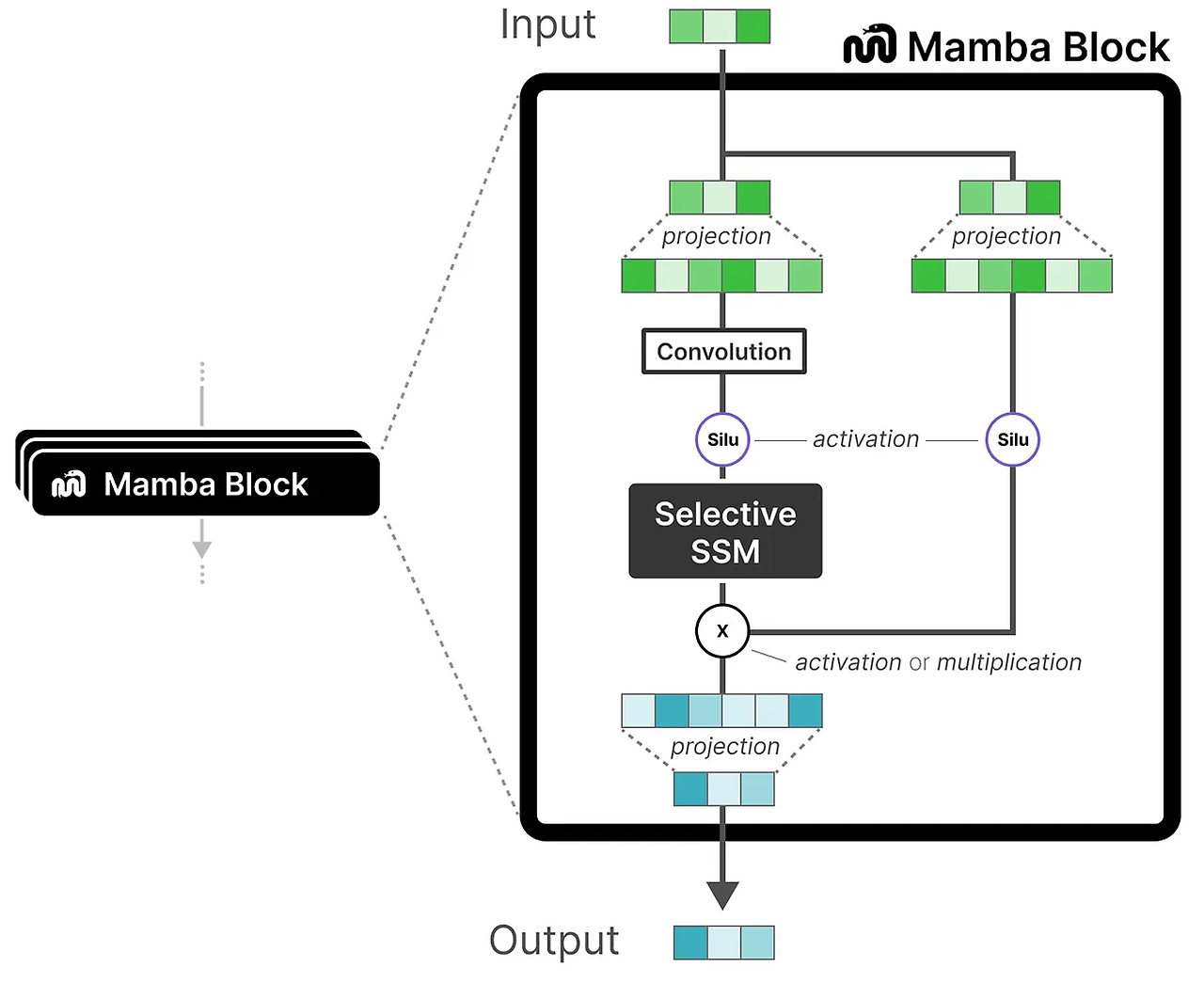
Selective SSM은 다음과 같은 특성을 가진다.
- 이산화를 통해 생성된 Recurrent SSM
- 장거리 의존성을 포착하기 위한 HiPPO intialization matrix A
- 정보를 선택적으로 압축하기 위한 Selective Scan 알고리즘
- 계산 속도를 높이기 위한 하드웨어 인식 알고리즘
Results
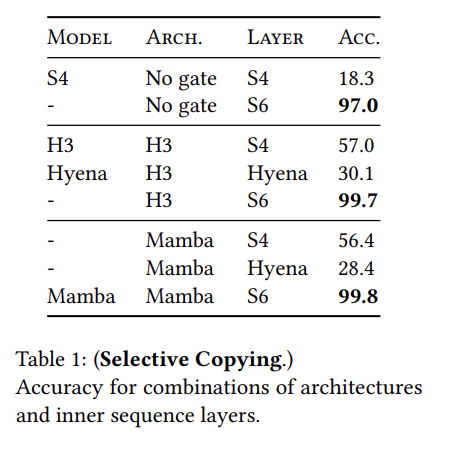
Mamba의 아키텍쳐가 Selective Copying task에 영향을 미치는 것을 확인했지만 가장 중요한 점은 Layer라는 점이 눈에 띄게 보였다. (S6가 selective방식을 적용한 SSM임)
S6를 적용한 모델이 전부 좋은 성능을 보인다는 점을 확인할 수 있었다.
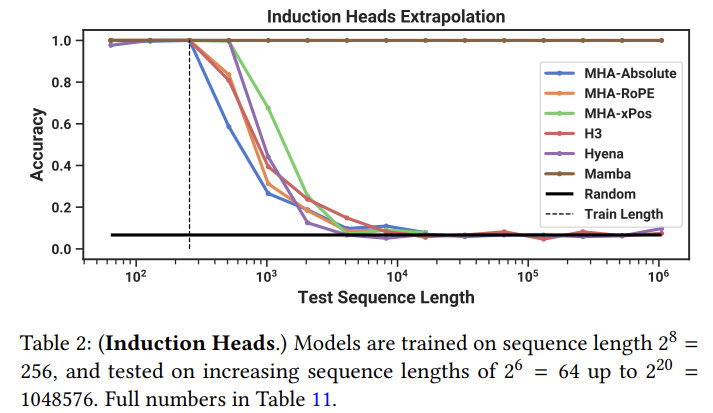
Extrapolation의 성능 또한 Test Sequence의 길이가 증가하는 것에 비해 성능이 높게 유지되는 것을 확인할 수 있었다.
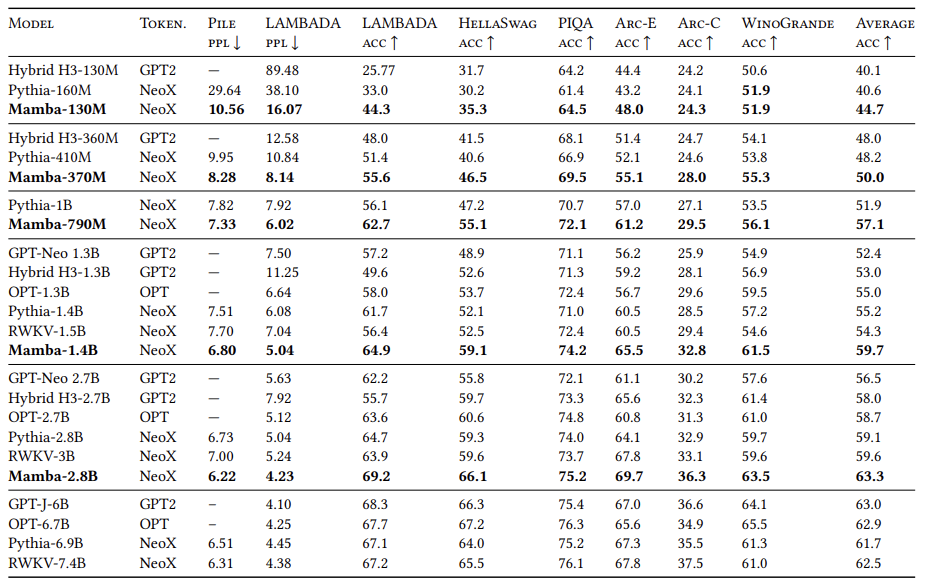
Non-Transformer기반의 모델이 다른 Transformer기반 모델들과 Downstream task에서 비슷한 성능을 낼 수 있다는 것을 보여주었다.
