DOLA: DECODING BY CONTRASTING LAYERS IMPROVES FACTUALITY IN LARGE LANGUAGE MODELS(2024)
자연어 논문리뷰

0.0 Overview
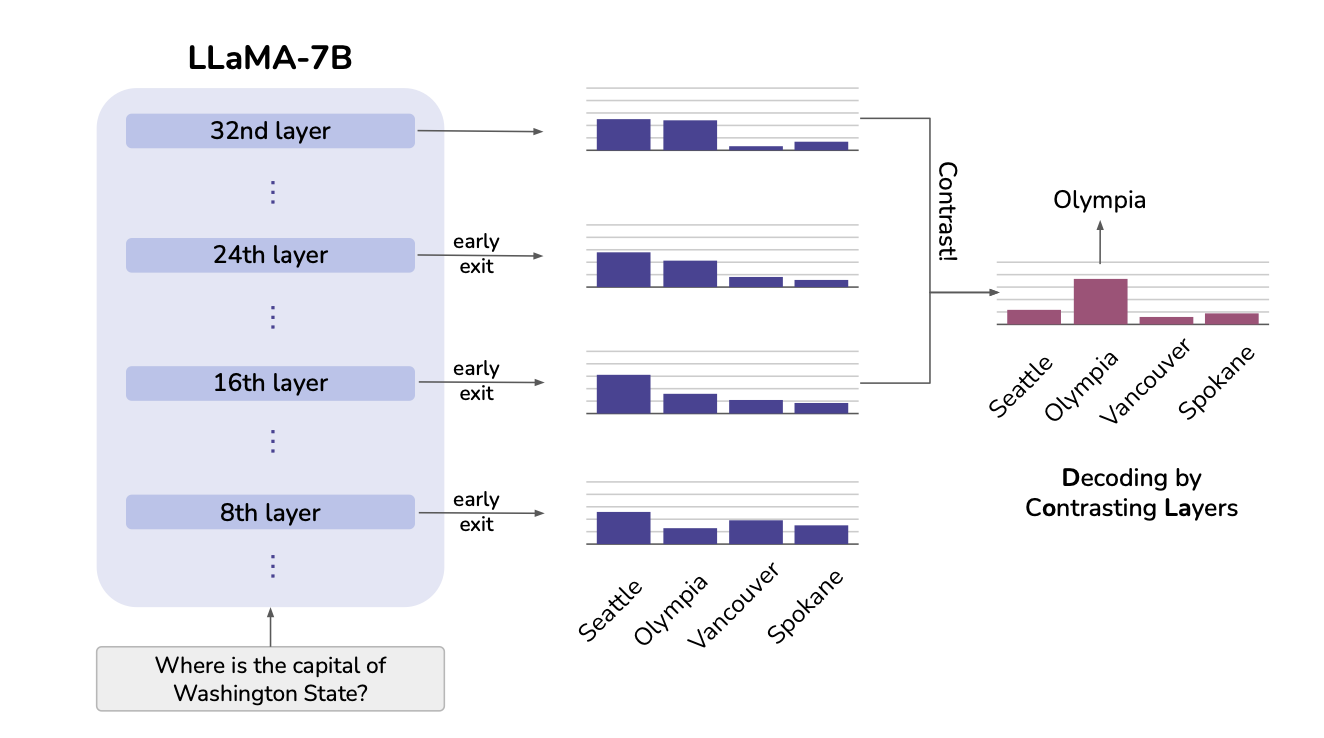
한 문장으로 표현하자면 DOLA는 model의 Forwarding 과정에서 중간 Layer/최종 Layer의 Token Probability 차이를 이용해서 Decoding을 하는 것이다.
그림에 나와있는 것처럼 early exit를 하여 중간 Layer에서의 token distribution을 구하고 마지막 Layer를 제외한 나머지 Layer 중 특정 Layer와 마지막 Layer간의 Contrasting을 통해 수정된 vocab distribution을 얻은 다음 특정 Decoding 방식을 사용해 Token을 생성하는 방법론이라고 생각하면 될 것 같다.
1.0 Background
Hallucination이 점점 중요해지고 있다.
LLM의 성능향상 + 새로운 능력에도 불구하고 Hallucination을 생성하는 경향이 존재한다.
이는 의료/법률 도메인 등 특정 도메인에 LM을 사용할 때 걸림돌이 된다.
예시)
암 환자에 대한 치료 솔루션에 Hallucination이 발생할 경우
- 암에 걸렸을때는 잠을 잘 자면 됩니다.
해외 기업 보고서에 대해 Hallucination이 발생한 경우
- 이 기업의 대표가 최근 무인도로 여행을 떠났습니다. 저도 가고싶군요
Contrastive Decoding
Large LM과 Small LM의 Token probability의 차이를 이용해서 Decoding하는 방법
- Motivation
1. Small LM은 Large LM에 비해 Open-ended Text Generation시 짧거나, 반복되거나, 무관하거나, 흥미롭지 않은 텍스트를 생성하는 경우가 많다.
2. Large LM은 Factual Knoweldge를 비롯한 바람직한 Output을 생성하는 것에 더 높은 확률을 가하는 경향이 있음
-> Contrastive Decoding을 통해1.과 같은 현상을 완화하고2.을 강화하고자 하는 방법이다.
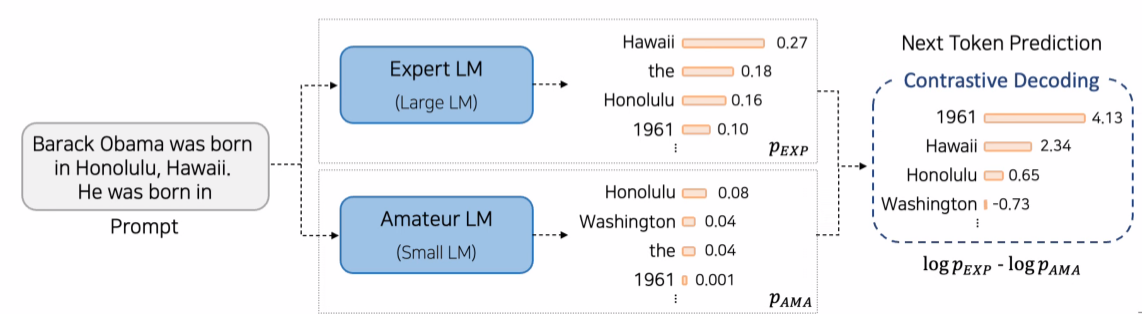
- Method
- Off-the- shelf Large LM(Expert)과 Small LM(Amateur)를 이용- Expert의 Log-Probability와 Amateur의 Log-Probability의 차이를 새로운 Token Probability로 사용함
- Expert LM에서의 Log-Probability가 너무 낮은 Token들은 비교대상에서 제외함
장점과 단점
- 장점
- Open-ended Text Generation Task에서 Greedy/Top-p/Top-k보다 높은 Fluency와 Coherence를 보임
- Model Training이 필요하지 않음 -> Off-the-shelf LM에 바로 적용이 가능함
- 단점
1. Expert LM과 Amatuer LM의 Vocabulary가 동일해야 사용가능하다.
2. Model이 두 개 필요하다.
💡 coherence?
: coherence란 텍스트가 나타내고자 하는 의미가 의미론적으로 적합한 지를 의미한다.
💡 Off-the shelf LM?
: 바로 쓸 수 있는 LM을 말하는 것 같다. (pre-trained model)
2.0 Method
최종 Transformer Layer의 Output을 이용함
- Next Token 를 생성할 때 Sequence =
가
1. Embedding Layer를 통과해 vector로 표현
2. Transformer Layer를 통과
3. Vocab Head 통과
4. Vocab Distribution산출
5. Decoding 방법에 따라 Next Token x_t 생성
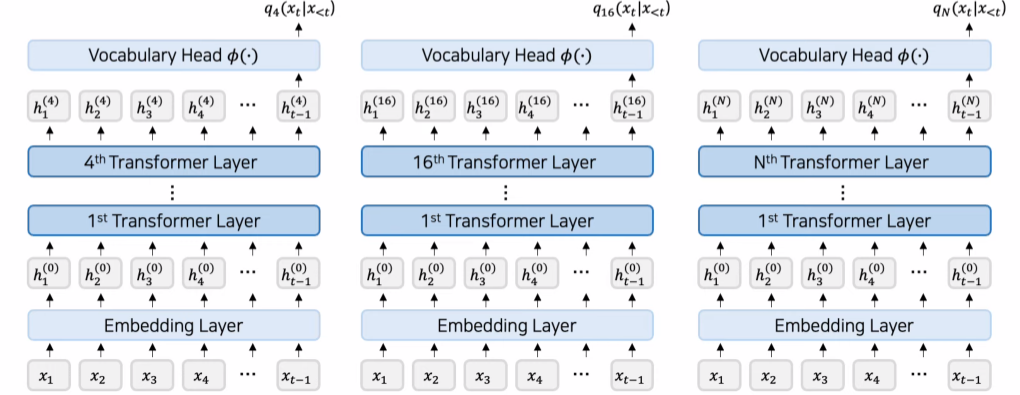
- DoLa: Early Exit
중간 Transformer의 Output도 사용함: =
- DoLa: Next Token Probability 산출 시 후반 Layer와 초기 Layer의 information을 Contrast함
-> Final Layer 외 Transformer Layer에 대해서도 Next Token Probability 산출 (Early Exit)
💡 Early Exit
N 개의 Layer가 있다면, 각각의 Layer에서 앞서 설명한 Next Token Prediction을 뽑아내는 것을 Early Exit이라 합니다.
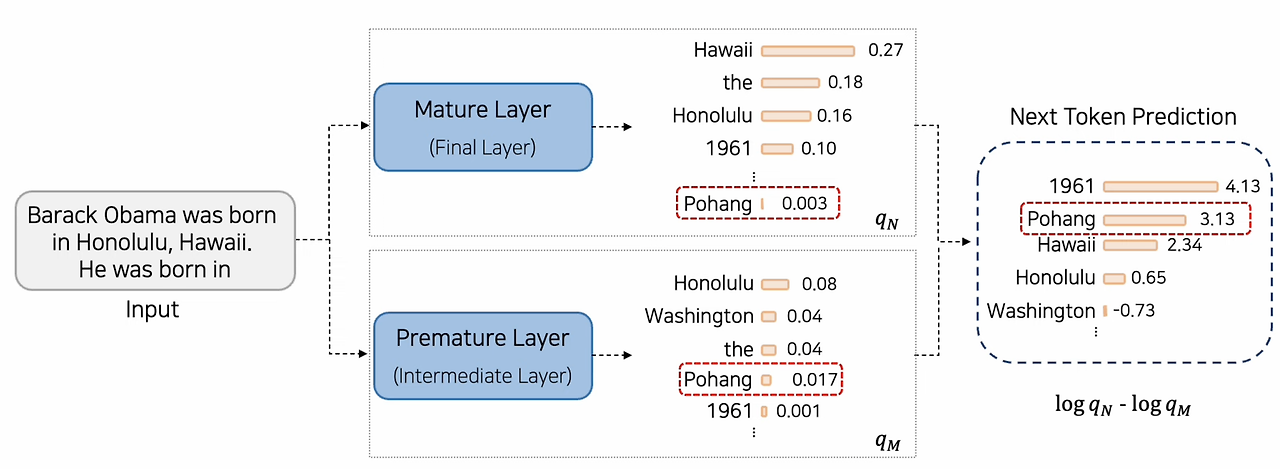
Dora의 Next Token Prediction
Next Token Probability 산출 시 후반 Layer와 초반 Layer의 정보를 Contrast함
- Final Layer(mature layer)의 Next Token Probability와 가장 차이가 큰 Layer(premature layer)를 사용
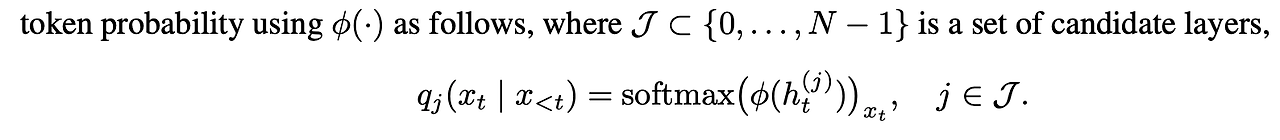

마지막 Layer인 N번째 Layer(mature layer)의 확률 분포와 이전의 j번째 Layer(premature layer)의 jenson shanon divergence를 사용하여 마지막 layer와 분포의 차이가 가장 큰 layer의 index값을 M으로 가져갑니다.
💡jenson shanon divergence(JSD)
KL-divergence와 거의 동일한 개념이라고 생각하면 된다. 단지 차이는 Symmetric함을 보장하기 위해 KL-divergence의 로그 뺄셈 순서를 바꿔서 한번 더 해주고 합한 것이라고 생각하면 된다.
KL-Divergence는 symmetric하지 않음
순서를 바꿔서 KL-Divergence를 한번 더 구한 후 평균값을 구함 -> JSD
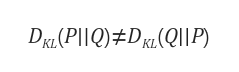
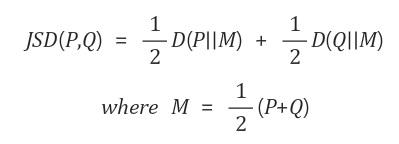
3.0 사전 분석
Early Exit Distribution과 Final Layer Distribution간 JSD 계산
model: LLaMA-7B (32-Layer)
- input: Who was the first Nigerian to win the Nobel Prize, in which year?
- output: Wole Soyinka was the first Nigerian to win the Nobel Prize, in 1986
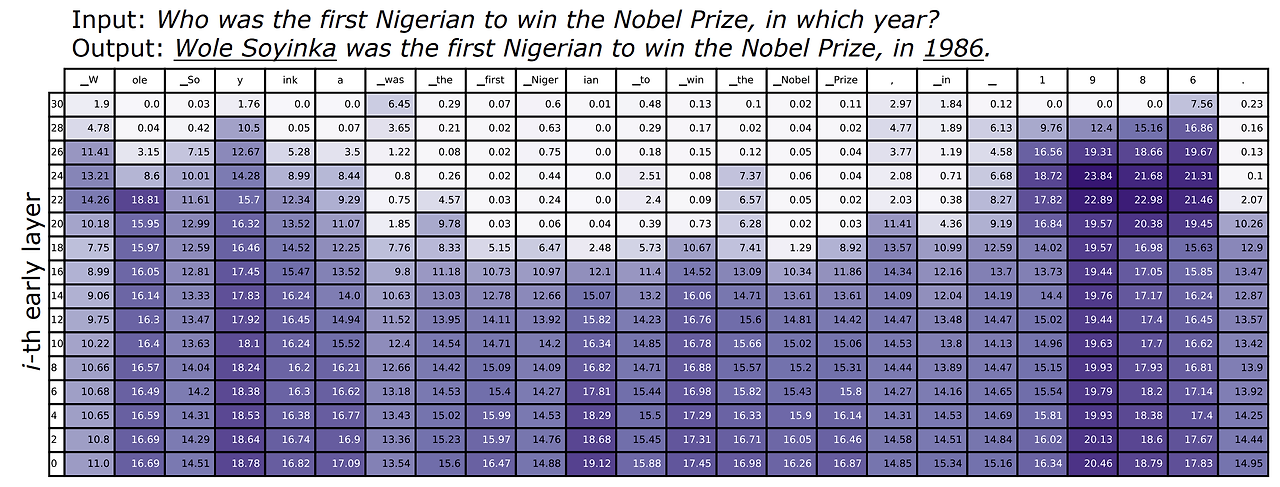
* 보라색이 클 수록 JSD값이 큰 것이다.
-
Factual Knowledge 가 필요한 Named Entity 또는 Date를 예측할 때, JSD는 후반 Layer에서 매우 높음 ( "Wole Soyinka", "1986" ) => LM은 후반 레이어에서도 Prediction을 바꾸고, Prediction에 Factual Knowledge를 주입하는 구나.
-
기능어 또는 Input에서 복사해온 토큰 ("first Nigerian', "Nobel Prize")을 예측할 경우, 중반 Layer에서 JSD가 매우 작다. -> Model이 어떤 Token을 생성할지 미리 결정한 것으로 보임.
발견한 패턴
Factual Knoweldge가 필요한 Named Entity 또는 Data를 예측할 때 JSD는 후반 Layer에서 매우 높음. ( ex.,
Wole Soyinka,1986)
-> LM은 후반 Layer에서도 Prediction을 바꾸고 Predictiond에 Factual Knowledge를 주힙하는 것으로 유추된다.기능어(e.g.,
was,the,to,in)또는 Input에서 복사하면 되는 쉬운 Token(e.g.,first Nigerian,Nobel Prize)를 예측할 경우 초반 Layer에서의 JSD만 큰 값을 가지고 이후 Layer에서는 JSD가 낮게 유지되는 것을 확인할 수 있음
-> Model이 어떤 Token을 생성할지 초반에 이미 결정했기 때문에 이후 Layer에서는 output의 분포가 크게 변하지 않는 것으로 유추된다.
사전분석 결론
-
후반 Layer에서와 같이 JSD 값이 급격히 변한 전/후 Layer를 Contrast 하면,후반 Layer의 Factual Internal Knowledge에 더 의존할 수 있을 것.
-
동적으로 Premature Layer를 선택하는 방법이 필요.
💡 왜 Factual Internal Knowledge에 더 의존할 수 있을까?
Dynamic Premature Layer Selection
Downstream Task 적용시
1. model을 layer 수에 따라 layer들을 2~4개의 부분집합 으로 나눔
2. Validation Set을 이용해 최적의 를 선정함
3. 선정된 J내의 layer들을 대상으로 Dynamic Premature Layer Selection하며 Decoding을 함(DoLa)
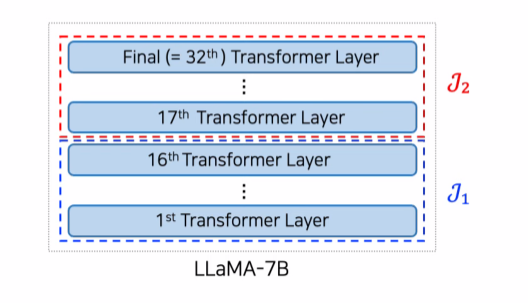
장점: Contrast 대상 Layer가 동적이기에 Data distribution에 덜 민감하다.
특정 layer의 구간을 선택하는 이유는 Task의 종류에 따라 좋은 성능을 보였던 premature layer가 달랐기 때문임 (Test때는 Validation에서 선택한 J를 사용함.)
DoLa-static
premature layer를 고정함
DoLa: Decoding step마다 Contrast대상 Premature layer를 선택을 위한 연산 수행 <-> DoLa-static: validation performance를 기준으로 단 하나의 premature layer 선택 후 고정
- DoLa-static의 단점
- Premature Layer 선택을 위한 computational cost가 크다. (dynamic은 최적의 layer를 선택했다면 선택된 J내에서만 비교함.)
- Data distribution에 민감 -> Test dataset에서도 좋은 성능을 보이기 위해서는 Test set이 Validation set과 비슷한 분포를 보여야함.
Contransting Predictions
- Mature Layer의 영향력이 Premature Layer의 영향력보다 상대적으로 커야 뽑히게 된다.
- Contrasting Decoding과 매우 유사함.
- Mature Layer N의 Log Probability - Premature Layer M의 Log Probability -> Next token probability임.
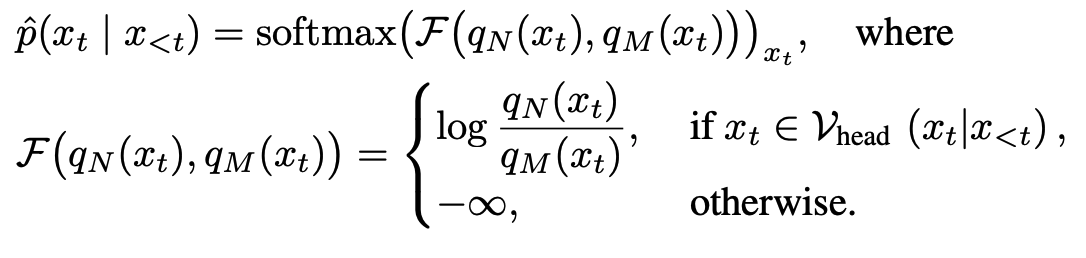
발생 가능한 문제
-
False Positive
타당하지 않은 토큰이 높은 probability를 가지게 되는 문제
(mature layer, premature layer모두 확률이 낮음에도 불구하고 mature layer의 확률값이 상대적으로 높아 타당하지 않은 token의 output probability가 높은 값을 가지게 되는 경우) -
False Negative
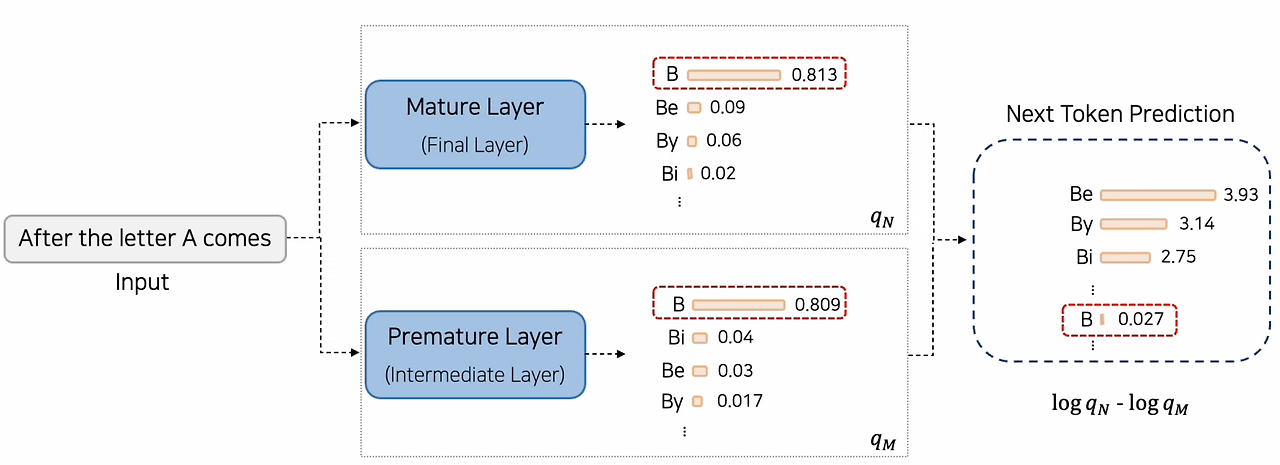
당연한 결과에 대해서 mature layer와 premature layer의 확률값 차이가 미미해서 output probability값이 낮아지는 경우 이 문제가 생긴다.
문제 해결
이 문제를 해결하기 위해 N번째 Layer 확률값에 threshold를 두었다.
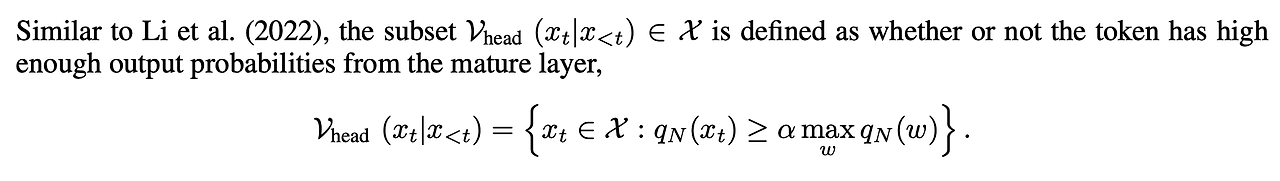
N번째 Layer에서 확률 값이 가장 높은 Token의 확률에 값을 곱한 값보다 확률이 높은 값들만 들어가는 집합 을 두고
만약 토큰이 집합 $에 들어간다면 기존의 방식대로 계산하고 들어가지 않는다면 softmax를 취하기 전 값을 음의 무한대로 보내버려 softmax값을 0으로 만들어버리는 방식을 사용해서 문제를 해결했다고 한다.
이 논문의 저자는 이 기법으로 False Positive, False Negative 문제를 모두 해결했다고 한다.
개인적으로 이 방식은 N번째 Layer의 확률값에 threshold를 둬서 False Positive 문제는 해결했지만 False Negative문제는 어떻게 해결한 것인지 잘 모르겠다. (False Negative는 해결하지 못했다고 생각한다. )
premature layer와 mature layer의 선정 기준이 JSD 이기 때문에 같은 token이 높은 확률값을 가진 분포 2개가 뽑힐 확률이 적기 때문에 이 문제를 전부 해결했다고 하는 것 같다.
4.0 Experiments
Setting
Dynamic Premature Layer Selection
LLaMA-7B (32 Layers) : 2 Bucket -> [0,16), [16, 32)
LLaMA-13B (40 Layers) : 2 Bucket -> [0,20), [20, 40)
LLaMA-33B (60 Layers) : 3 Bucket -> [0,20), [20, 40), [40, 60)
LLaMA-65B (80 Layers) : 4 Bucket -> [0,20), [20, 40), [40, 60), [60, 80)
효율성을 위해 짝수 Layer 들만 후보로 사용
Downstream Task 별 최적의 Bucket J를 찾기 위해 아래와 같이 Validation Data 사용
TruthfulQA-MC, FACTOR : Two-fold Validation
GSM8K, StrategyQA : GSM8K Training Set 10%
Vicunna QA : GSM8K에서의 최적 Bucket 사용
CD(Contrasting Decoding)의 경우, LLaMa-7B를 Amateur로 보고 진행
Multiple Choice
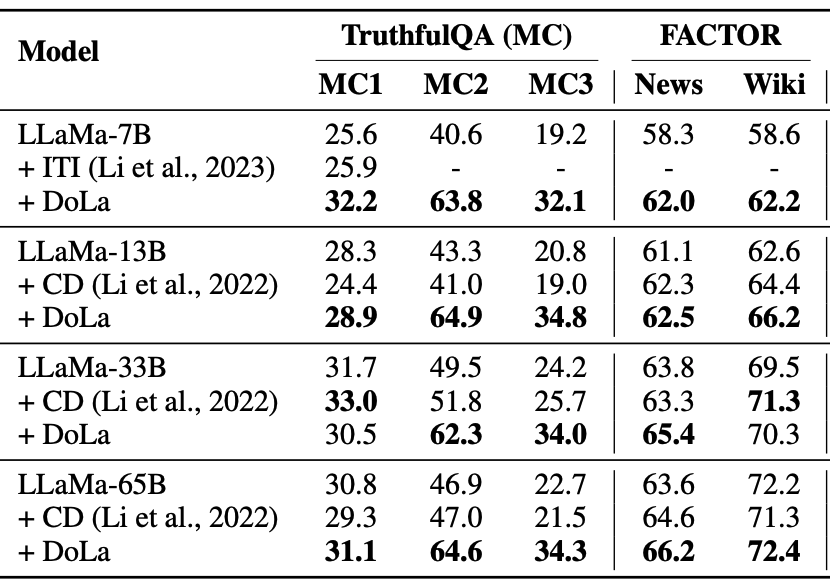
최적 Bucket
TruthfulQA-MC : 7B, 13B, 33B, 65B -> 후반 Layer
비교적 생성할 텍스트가 짧고, Fact가 중요한 데이터셋이기 때문에 후반 Layer가 선정되었다고 추측됨.
FACTOR : 7B, 13B, 33B, 65B -> 초반 Layer
길이가 긴 문장을 생성해야하는 데이터셋 ( 예측하기 쉬운 Token들이 다수 존재하는 문장 )
사전 분석과 유사한 결과.
모든 Model Size에서 Baseline 방법론보다 높은 성능을 냈다.
Open-Ended Generation
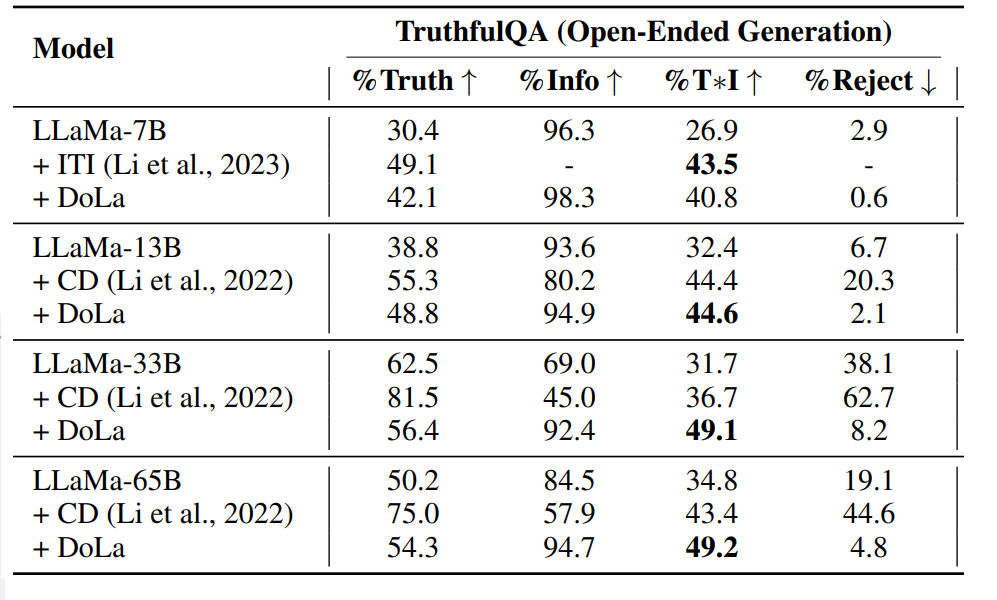
Truthfulness & Informativeness
Finetuning한 GPTs를 이용하여 성능을 측정했다.
'I have no comment" -> 진실성 100%, 정보 0%
Truth만 높은 CD의 경우, 제대로된 답안을 못했다고 판단해야할 것 같다. (Reject 도 더 높음)
CoT - StrategyQA Result
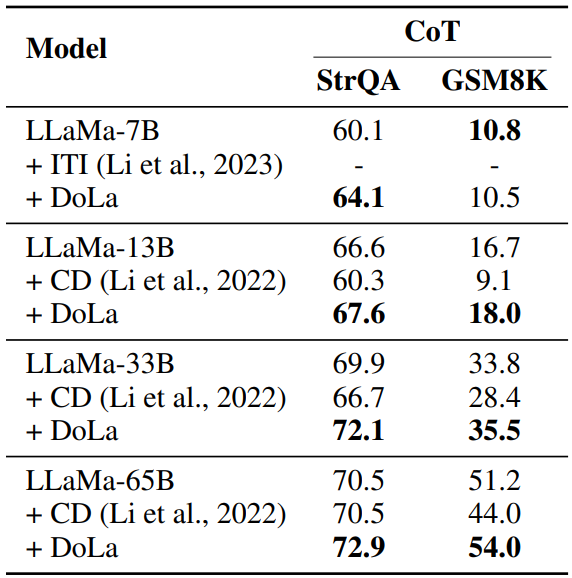
최적 Bucket은 다 초반 Layer로 나왔다.
Contrastive Decoding의 경우, Vanilla LLaMA에 비해 오히려 성능이 저하되었다.
Small LM의 Reasoning 능력을 오히려 방해한 결과일 수 있다.
반면 DoLa는 약 1 ~ 3 % 가량 acc가 더 높음.
Multi-hop Reasoning에서는 단일 모델의 다른 Layer과 Contrast 하는 것이 더 효과적이라는 결과.
Chatbot - VicunaQA (Open-ended)
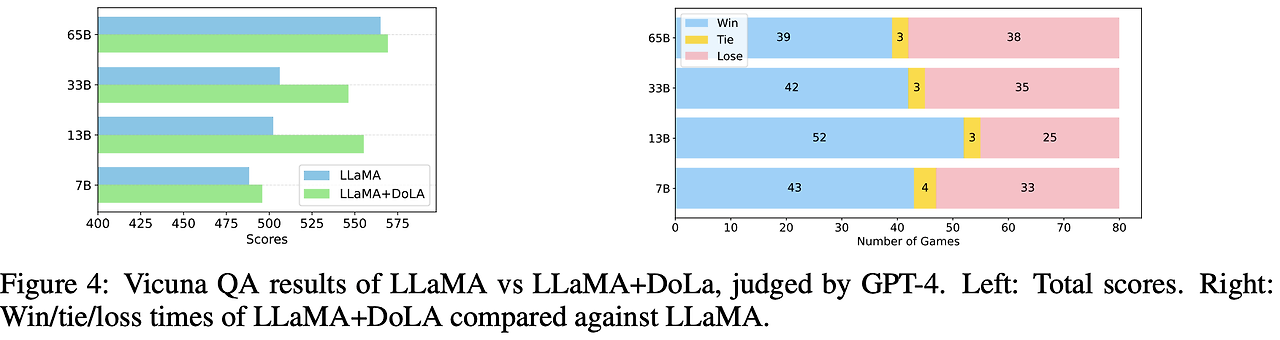
최적 Bucket은 초반 Layer로 나타났다.
Evaluator : GPT-4
Chatbot 에서도 DoLa가 효과적임을 보았고, 특히 13B, 33B에서 Baseline보다 크게 높은 성능을 보였다.
Static 하게 premature layer를 선택했을 때
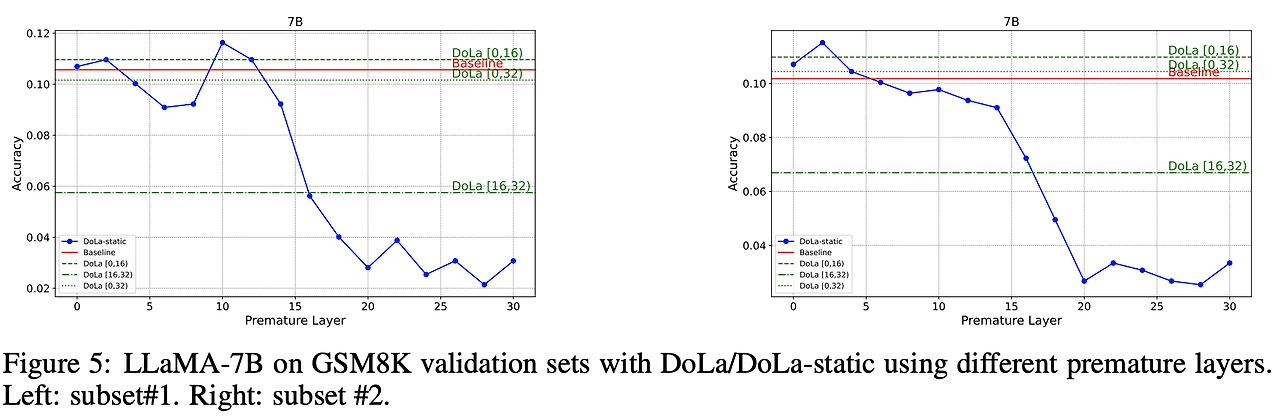
비교적 초기 Layer와 Contrast시에 DoLa-static이 GSM8k에서 더 높은 성능을 보였다.
- 특정 Layer와 Contrast시 DoLa보다 높은 성능
- But, 동일 데이터셋의 다른 instance들에 대해서는 최적 Layer가 바뀜
-> data distribution에 따라 최적의 Premature Layer는 달라짐, 따라서 N개 Layer별로 Validation 성능측정이 필요하다.
-> DoLa는 DoLa-static과 달리 꾸준히 높은 성능을 보이며 더 Robust한 방법임을 보여준다.
Latency 비교
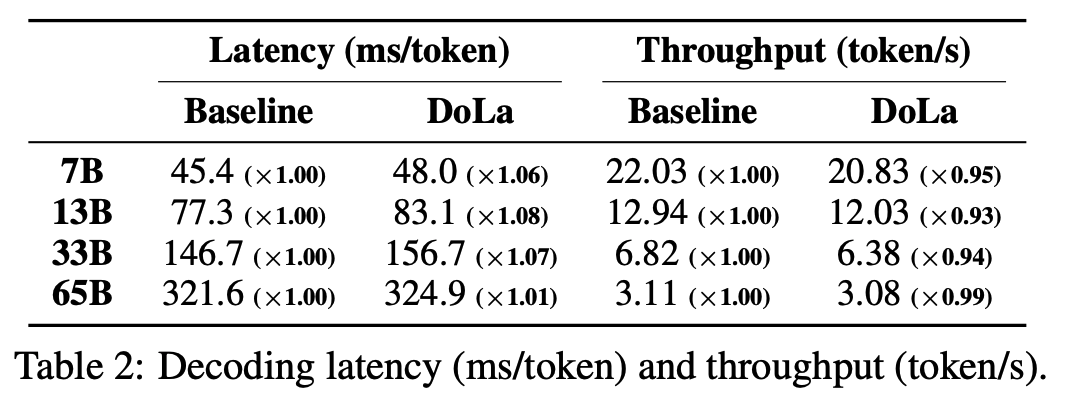
Baseline과 DoLa 모두 Greedy Decoding 이용
Latency가 약 1.01 ~ 1.08 배 증가
5.0 Concolusion
DoLa는 Information Retrieval 또는 Model Fine-tuning 없이 다양한 Task에서 Truthfulness를 향상시킨 방법론이다.
Decoding 과정에서 단일 LM의 중간 Layer과 Final Layer의 Contrast를 통해 Token Prob를 수정하는 방법론임.
Retrival Module과 함께 사용했을때 Hallucination을 더욱 완화할 수 있을 것이라고 말하고 있다.
