
0.0 Abstract
-
언어모델에 관한 기준 주장과 달리, llm은 인간이 학습할 수 없는 언어를 학습하는데 어려움을 겪는다는 연구 결과가 제시되었다.
-
연구진은 영어 데이터를 자연스럽지 않은 단어 순서와 문법 규칙으로 조작하여 다양한 복잡도의 불가능한 언어를 설계하였다.
-
실험은 GPT-2모델로 진행하였으며 이 모델을 불가능한 언어를 학습하는 것에서 영어와 비교하여 뚜렷한 한계를 보였다고 함.
-
이 연구는 LLM 구조를 다양한 불가능한 언어에 적용하여 보다 깊은 연구의 가능성을 탐구할 수 있는 기초를 마련하고자 했다고 함.
1.0 Introduction
기본 학습 코퍼스는 BabyLM 데이터셋이며 GPT-2 small model을 사용하였다.
-
LLM이 학습 가능한 언어와 불가능한 언어를 구분할 수 없다는 주장은 Chomsky 외 연구자들이 LLM이 "가능한 언어와 불가능한 언어를 구분할 수 없다."고 주장하며 제기되었다.
-
연구에서 정의된 가능 언어와 불가능 언어세트에 대해 GPT-2모델을 훈련시켰고, 결과적으로 가능 언어에 비해 불가능 언어의 학습 효율이 낮은 것으로 나타났다.
-
세 가지 주요 실험을 통해 LLM은 가능 언어에 비해 불가능 언어를 학습하는 데 어려움을 겪었으며, 이는 Chomsky의 주장을 반박하는 결과로 해석된다.
-
연구는 불가능 언어의 수많은 예제를 제시하며, 이러한 언어들이 언어 모델의 학습에서 중요한 정보를 제공할 수 있음을 강조한다
1.1 Experiment
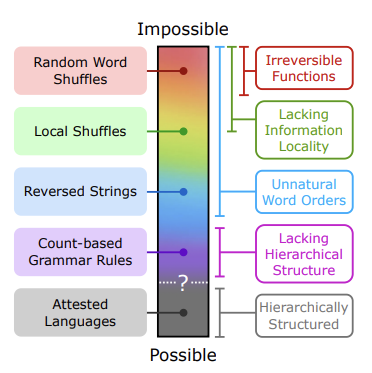
LLM에 대한 주요 비판
- 가능/불가능 언어 구분 불가능성: LLM은 본질적으로 가능 언어와 불가능 언어를 구분하지 못한다고 주장합니다.
- 실험적 증거 부족: Chomsky 등은 강력한 주장을 펼쳤지만, 이를 뒷받침하는 구체적이고 광범위한 실험적 증거는 부족합니다.
이 연구의 접근 방식
논문은 LLM이 불가능한 언어를 학습할 수 있는지를 검증하기 위해 다음과 같은 접근법을 사용했습니다:
- 불가능한 언어 설계: 영어 데이터를 기반으로 비자연적 문법과 단어 배열을 통해 다양한 불가능한 언어를 생성했습니다.
- 실험적 검증: GPT-2 모델을 사용해 각 불가능한 언어를 학습시키고, 학습 과정과 결과를 자연어(가능 언어)와 비교했습니다.
실험 개요
연구팀은 GPT-2 모델을 사용하여 다음과 같은 세 가지 주요 실험을 수행했습니다:
1. 불가능한 언어 학습 성능 비교:
- GPT-2를 다양한 불가능한 언어 데이터셋으로 훈련시키고 학습 효율성을 평가.
- 특정 문법 규칙에 대한 반응 분석:
- 단어 위치 기반 규칙을 포함한 언어에서 모델의 문법 감수성을 테스트.
- 내부 메커니즘 분석:
- 모델이 불가능한 문법 규칙을 학습하기 위해 개발하는 내부 구조를 파악.
연구의 주요 질문
- LLM은 불가능한 언어를 학습할 수 있을까?
- 학습 과정에서 자연어와 차별적인 성과를 보이는가?
기대 효과
이 연구는 LLM이 인간 언어 학습과 관련된 인지적, 언어학적 메커니즘을 이해하는 도구로 활용될 가능성을 제시하며, LLM 아키텍처와 학습 능력에 대한 더 깊은 논의로 이어지길 기대합니다.
2.0 Background and Related Work
2.1 인간 언어의 불가능성과 언어 보편성
- 불가능한 인간 언어란 정의하기 어려운 개념으로, 특정 언어적 특성이 보편적인지, 또는 불가능한지를 두고 논란이 존재합니다.
- 예: 재귀성(recursion)은 인간 언어의 보편적 특성으로 여겨지지만, 그 필요성에 대한 의문도 제기됩니다.
- 반례: 일부 언어는 내포 구조를 가지지 않는다는 주장(Everett, 2012).
- 불가능한 언어 규칙의 예:
- 단어 순서에 의존하거나, 단어 위치를 기반으로 하는 규칙(Moro et al., 2023).
- 예: 단어 위치를 세어 부정문이나 동사 일치를 표시하는 방식.
2.2 비자연적인 단어 순서를 사용하는 언어 모델 학습
- 이전 연구는 LLM이 비자연적 언어를 학습할 수 있음을 보여주었습니다.
- 예: Mitchell and Bowers (2020)의 연구에서는 RNN이 비자연적 언어에서도 높은 정확도를 달성.
- 최근 연구는 Transformer 기반 모델의 단어 순서 및 구문 구조 처리 능력을 다루며, 사전 학습(pretraining)이나 위치 인코딩(positional encoding)의 역할도 분석했습니다.
- BERT, GPT 등의 모델은 비정형적인 단어 순서에서도 구문 정보를 학습할 수 있다는 증거를 발견했습니다.
2.3 언어 모델과 형식 언어
- 언어 모델의 표현 가능성을 형식 언어 이론(Chomsky 계층구조) 관점에서 분석:
- 인간 언어는 문맥 자유(context-free) 언어보다 더 복잡한 구조를 가질 수 있음(Shieber, 1985).
- 연구 결과: RNN과 Transformer 모델은 단순한 문맥 자유 언어를 잘 학습하지만, 더 복잡한 언어 학습은 제한적(Hahn, 2020).
- Transformer의 구조적 변화(예: 스택 추가)나 데이터 중심 접근법(예: 구조적 사전 학습)을 통해 이러한 한계를 완화할 수 있음.
3.0. Impossible Languages
이 연구에서는 인간 언어의 불가능성을 탐구하기 위해 인위적으로 설계된 불가능한 언어들을 제시합니다. 이러한 언어들은 정보 이론적 속성과 언어학적 구조를 고려해 설계되었으며, 불가능성의 연속체(impossibility continuum)를 따라 배치됩니다.
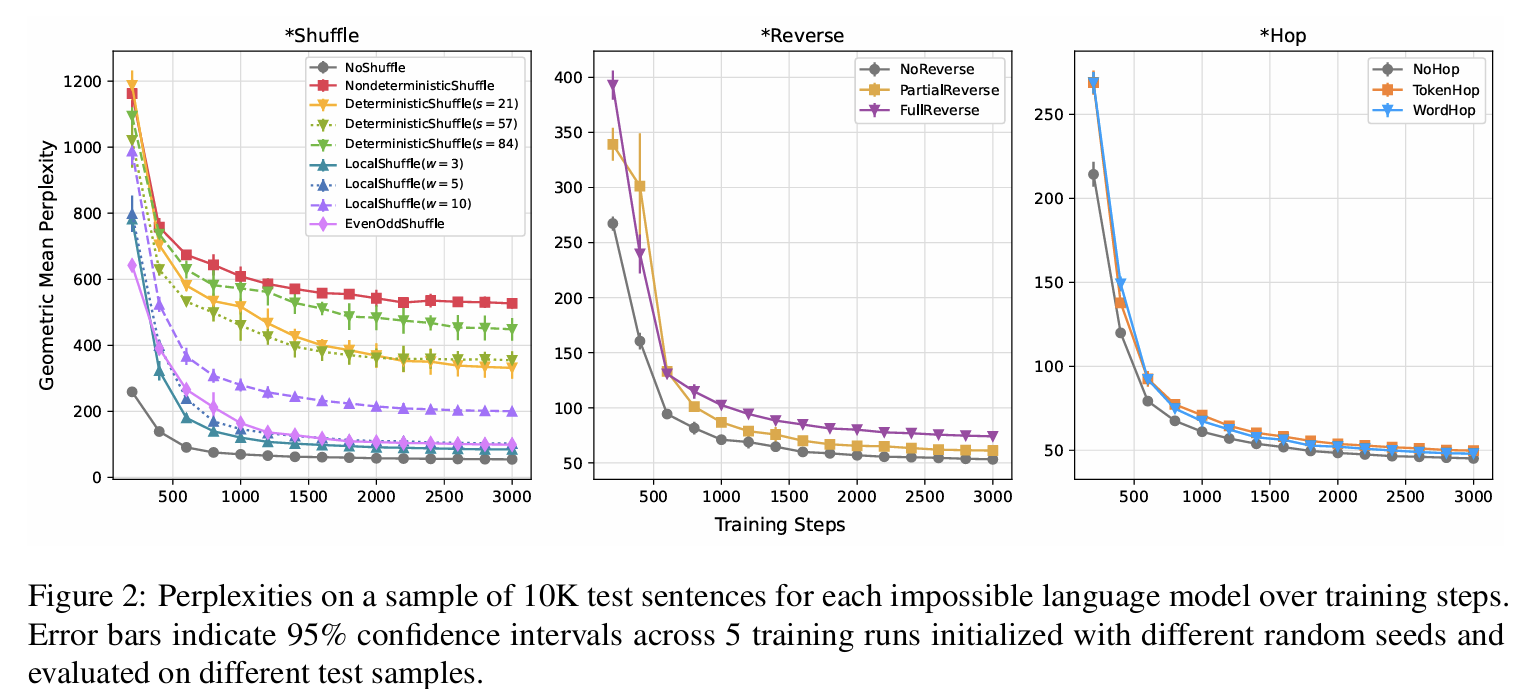
3.1 SHUFFLE 언어 (SHUFFLE Languages)
단어의 순서를 섞는 방식을 통해 설계된 언어들입니다.
1. NO SHUFFLE: 단어 순서를 변경하지 않은 원래의 영어(대조군).
2. NONDETERMINISTIC SHUFFLE: 단어를 무작위로 섞은 비결정적 방식.
3. DETERMINISTIC SHUFFLE(s): 특정 규칙(랜덤 시드 s)에 따라 결정적으로 단어를 섞은 방식.
4. LOCAL SHUFFLE(w): 고정된 크기의 window 안에서만 단어를 섞는 방식. 창 크기 w에 따라 다양한 변형 존재.
5. EVENODD SHUFFLE: 짝수 위치 단어와 홀수 위치 단어를 재배치.
- 특징:
- NONDETERMINISTIC SHUFFLE은 단어 간 구조적 정보를 완전히 제거하여 가장 학습하기 어려움.
- LOCAL SHUFFLE은 창 크기가 작을수록 정보 지역성(information locality)을 더 잘 유지.
3.2 REVERSE 언어 (REVERSE Languages)
문장을 뒤집는 방식을 통해 설계된 언어들입니다.
1. NO REVERSE: 원래 문장에 특별한 마커(marker)를 추가(대조군).
2. PARTIAL REVERSE: 문장의 일부를 뒤집고, 뒤집힌 부분에 마커를 추가.
3. FULL REVERSE: 문장을 완전히 뒤집고 마커를 추가.
- 특징:
- PARTIAL REVERSE는 FULL REVERSE보다 더 높은 정보 구조를 보존.
3.3 HOP 언어 (HOP Languages)
단어 위치 기반 규칙을 도입해 설계된 언어들입니다.
1. NO HOP: 동사를 원형으로 변환하고, 뒤에 수/시제를 나타내는 표지(S 또는 P)를 추가(대조군).
2. TOKEN HOP: 마커가 동사에서 4개의 토큰 뒤에 위치.
3. WORD HOP: 마커가 동사에서 4개의 단어 뒤에 위치(구두점 제외).
- 특징:
- TOKEN HOP과 WORD HOP은 위치 정보를 세어야 하므로 인간 언어로는 비현실적.
결론
이 섹션에서는 언어 모델의 학습 한계를 검증하기 위해 다양한 불가능한 언어를 설계했습니다. 각 언어는 구조적 정보, 정보 지역성, 그리고 학습 가능성에 따라 구분되며, 모델의 학습 성능을 비교 분석할 수 있는 테스트베드 역할을 합니다.
4. Experiments
이 연구는 GPT-2 모델을 사용하여 설계된 불가능한 언어들의 학습 가능성을 평가했습니다. 세 가지 주요 실험이 수행되었습니다.
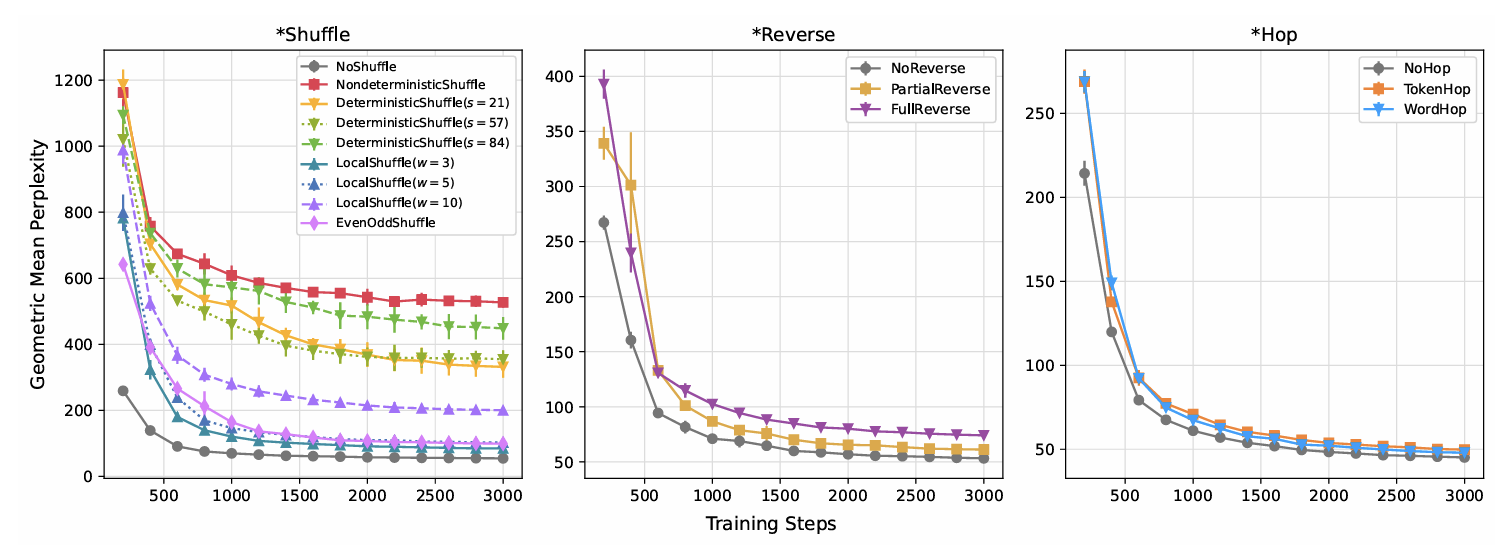
4.1 실험 1: 불가능 언어의 학습 성능 평가
- 목적: 불가능 언어와 가능한 언어를 학습하는 모델의 효율성을 비교.
- 방법:
- 각 언어 데이터셋으로 GPT-2를 훈련.
- 테스트 데이터셋에서 perplexity(언어 모델의 예측 불확실성 지표)를 측정.
- 결과:
- 가능한 언어는 불가능 언어보다 더 낮은 perplexity를 달성.
- LOCAL SHUFFLE(창 크기가 작은 경우)와 PARTIAL REVERSE 언어는 상대적으로 높은 학습 성능을 보임.
- NONDETERMINISTIC SHUFFLE은 가장 학습하기 어려운 언어로 나타남.
💡 Perplexity란?
Cross Entropy에 Log제거한 값임. 유도과정은 블로그 내에 GPT-1논문리뷰에 있습니다!
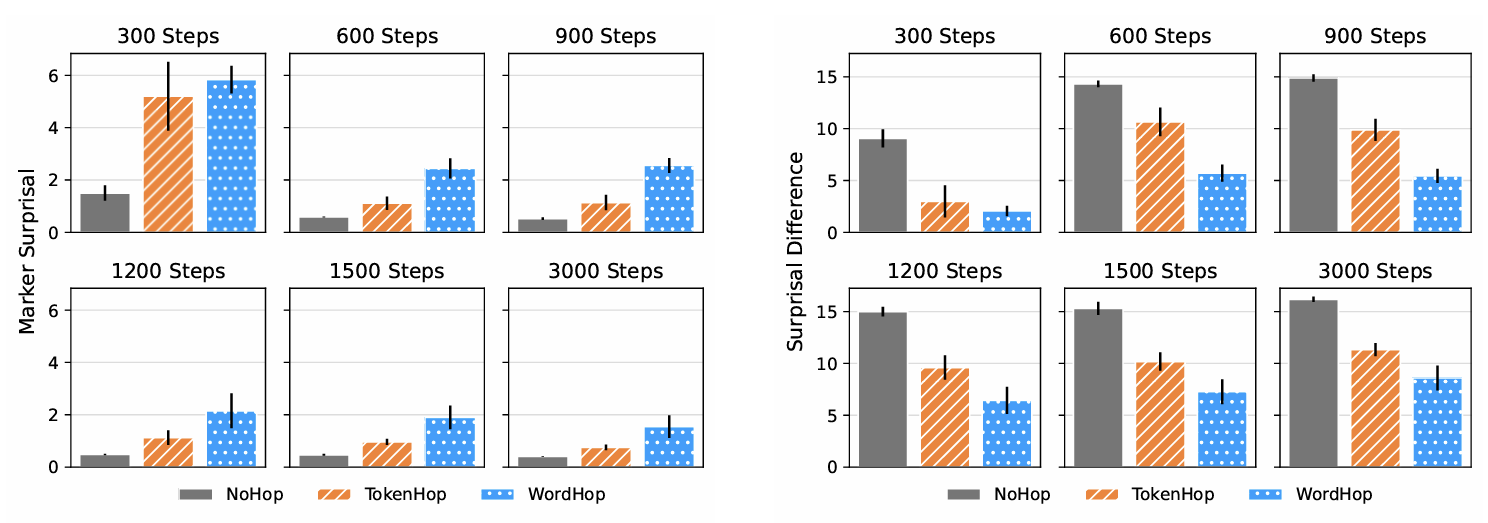
4.2 실험 2: 문법 규칙에 대한 모델의 반응 분석
- 목적: 모델이 불가능 언어의 동사 표지 규칙을 얼마나 잘 학습하는지 평가.
- 방법:
- 각 언어에서 동사 표지(S, P)에 대한 surprisal(예측의 어려움)을 계산.
- 표지가 있는 문장과 없는 문장의 surprisal 차이를 비교.
- 결과:
- NOHOP(대조군)의 동사 표지 surprisal이 가장 낮았으며, 규칙을 잘 학습함.
- TOKENHOP이 WORDHOP보다 더 나은 학습 성능을 보임.
- 위치 기반 규칙을 가진 언어에서는 모델의 학습 성능이 저하됨.
📲 논문에서 Surprisal 측정 방법
1. Marker Surprisal
Marker Surprisal은 동사 표지(S 또는 P)가 나타날 확률을 기반으로 측정됩니다. 이 값은 모델이 특정 위치에서 동사 표지가 나타날 것을 얼마나 기대했는지를 나타냅니다.공식:
여기서:
- : 동사 표시(S 또는 P).
- : 표지가 등장하기 전까지의 문맥
- : 주어진 문맥에서 모델이 마커를 예측할 확률
의미:
- 낮은 Marker Surprisal: 모델이 문맥에서 마커(S 또는 P)가 나타날 가능성(정답)을 높게 평가.
- 높은 Marker Surprisal: 모델이 해당 위치에 마커가 나올 것을 예상하지 못함.
예제:
문장: He cleans S his books.
- Surprisal 계산:
만약 모델이S를 예측했을 확률이 높다면 값은 낮음2. Surprisal Difference
Surprisal Difference는 동사 표지(S 또는 P)가 문장에서 예상 위치에 등장했을 때와 등장하지 않았을 때의 surprisal 값 차이를 나타냅니다.
- 공식:
_- 여기서:
- : 표지가 예상 위치에 있을 때의 Surprisal.
- _: 표지가 없는 경우, 바로 다음 단어의 Surprisal.
- 의미:
- 큰 Surprisal Difference(ΔS값이 크다): 모델이 문법 규칙에 따라 표지가 등장해야 한다고 강하게 기대하고 있음.
- 작은 Surprisal Difference(ΔS값이 작다): 모델이 해당 규칙을 학습하지 못했거나 규칙이 약함.
- 예제:
- 문장:
He cleans S his books.
- 정상적인 경우 (S가 있음): 값 계산.
- marker가 없을 경우(
He cleans _ his books): S(his)값 계산.- Surprisal Difference:
- 가 클수록 모델이 표지의 부재에 놀랐음을 의미
4.3 실험 3: 내부 메커니즘 분석
- 목적: 불가능한 언어의 문법 규칙을 학습할 때 모델이 개발하는 내부 구조를 분석.
- 방법:
- Causal abstraction analysis(Figure4)를 사용해 GPT-2의 내부 표현이 동사 표지 규칙에 미치는 영향을 평가.
- 단어 간 구문적 관계를 변경해 모델 출력에 미치는 영향을 측정.
- 결과:
- 모델은 가능한 언어에서 규칙을 더 효과적으로 학습하며, 불가능한 언어에서는 학습 과정에서 더 많은 어려움을 겪음.
- NO HOP 모델은 가장 일관된 내부 메커니즘을 보여줌.
4.4 결과 요약
- 가능한 언어는 불가능 언어보다 더 효율적으로 학습됨.
- 불가능 언어의 학습 성능은 정보 구조와 지역성(information locality)에 의해 크게 영향을 받음.
- 위치 기반 규칙(counting rules)을 가진 언어는 모델이 학습하기 어려운 것으로 나타남.
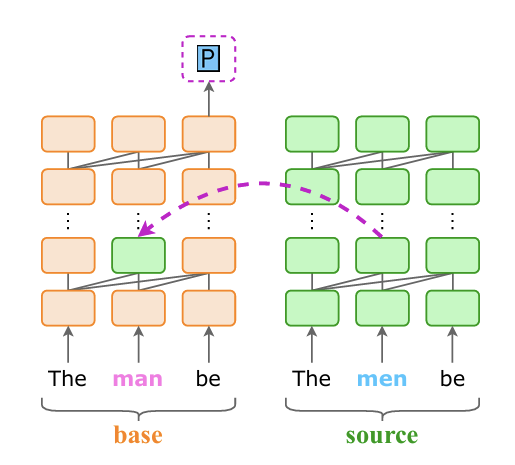
Figure 4
1. 입력 문장(Base Input):
- Singular subject: The man be
- 이 입력에서 모델은 S(singular 동사 표지)를 예측해야 합니다.
- 소스 문장(Source Input):
- Plural subject: The men be
- 이 입력에서는 모델이 P(plural 동사 표지)를 예측해야 합니다.
- Interchange Intervention:
- 두 입력의 특정 레이어와 토큰 위치의 내부 표현을 서로 교환(interchange)한 후, 모델의 예측이 어떻게 변하는지 분석.
- 예: The man be의 2번째 레이어에서 2번째 토큰 위치의 표현을 The men be에서 가져옴.
- 결과:
- 교환 후, base input이 S 대신 P를 예측 → 특정 레이어와 토큰 위치가 모델의 예측에 중요한 영향을 미친다는 것을 보여줌.
Figure 5의 구성
1. 축의 의미
- 수직축 (Layer): GPT-2 모델의 레이어(1~12)를 나타냅니다.
- 상위 레이어로 갈수록 더 추상적인 정보를 처리.
- 수평축 (Token Position):
td: Determiner (관사) 위치 (예:The).ts: Subject (주어) 위치 (예:man).tv: Verb (동사) 위치 (예:be).t1, t2, ..., t4: 동사와 동사 표지(S 또는 P) 사이의 간격(TOKEN HOP 및 WORD HOP에서만 해당).
2. Interchange Intervention Accuracy (IIA)
- 특정 레이어와 토큰 위치에서 주어 정보(단수/복수)를 교환했을 때, 모델의 동사 표지 예측 정확도를 측정.
- IIA 값:
- 0%: 모델이 정보를 제대로 활용하지 못함.
- 100%: 모델이 정보를 완벽히 활용하여 올바른 동사 표지를 예측.
- 색상:
- 밝은 색상: 낮은 IIA.
- 짙은 색상: 높은 IIA.
주요 결과
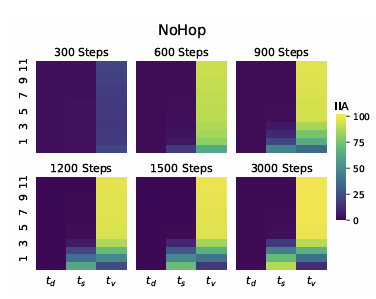
1. NO HOP 모델
- 초기 단계:
- 하위 레이어에서 주어 위치(
ts)가 높은 IIA를 보임 → 주어의 단수/복수 정보가 초기에 추출됨.- 후기 단계:
- 상위 레이어에서 정보가 동사 표지 위치로 전달(
t4에서 높은 IIA).- 결론:
- 자연스러운 규칙을 잘 학습하며, 정보가 적절히 처리되고 전달됨.
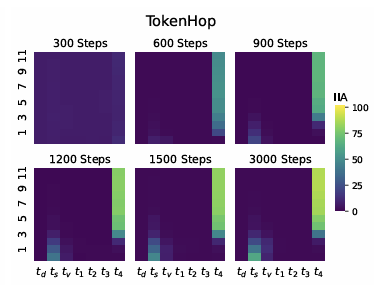
2. TOKEN HOP 모델
- 초기 단계:
- 주어 위치(
ts)에서 단수/복수 정보가 추출됨.- 중간 단계:
- 중간 레이어에서 정보가 동사와 표지 사이 간격(
t1~t4)으로 전달.- 후기 단계:
- 상위 레이어에서 동사 표지 위치로 정보가 결합되어 높은 IIA를 달성.
- 결론:
- TOKEN HOP 모델은 NO HOP보다 복잡한 규칙을 학습하지만, 간격 정보를 유지하며 규칙을 처리함.
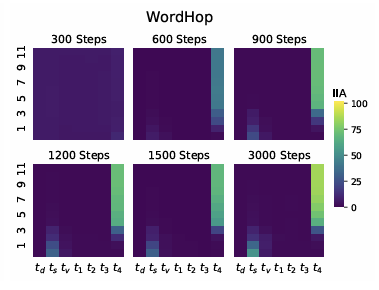
3. WORD HOP 모델
- 초기 단계:
- 주어 위치(
ts)에서 단수/복수 정보가 추출되지만, TOKEN HOP보다 낮은 IIA를 보임 → 정보 추출이 더 어려움.- 중간 및 상위 레이어:
- 간격(
t1~t4)과 동사 표지 위치로 정보가 전달되지만 높은 IIA를 달성하는 데 더 많은 레이어가 필요.- 결론:
- WORD HOP 모델은 규칙이 복잡해 학습 효율이 낮음.
5.0 Conclusion
이 실험들은 GPT-2 모델이 불가능한 언어를 학습하는 데 어려움을 겪는다는 점을 명확히 보여줍니다. 이는 LLM이 인간 언어와 더 유사한 학습 경향을 가지며, 모델 구조 및 학습 메커니즘에 대한 추가 연구의 필요성을 강조합니다.
