MuGI: Enhancing Information Retrieval through Multi-Text Generation Intergration with Large Language Models(2024)
자연어 논문리뷰

0.0 Abstract
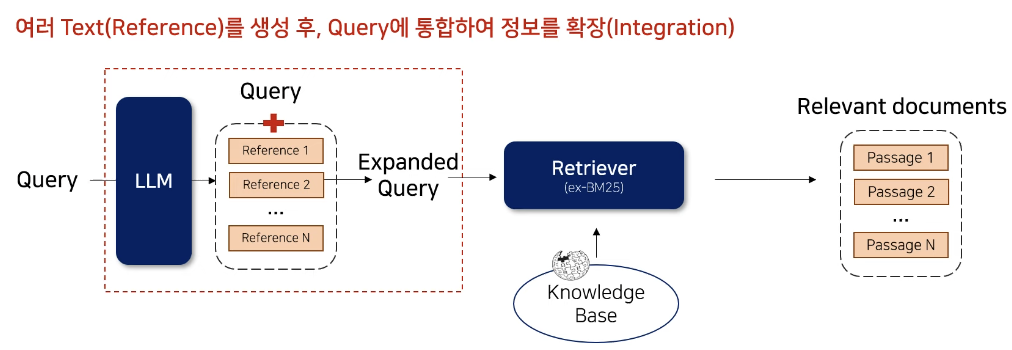
- Information Retrieval Task에서, LLM을 사용해 여러 text(reference)를 생성 후 Query Expansion하는 방법론 제안
- Query Expansion : 기존 연구들과 다르게 Zero-shot Prompt를 N번 생성시켜 다양성을 극대화
- 2-Step Retrieval : Sparse와 Dense Retriever를 모두 활용하여 검색 능력 향상
1.0 Background
1.1 Information Retrieval
- 정의
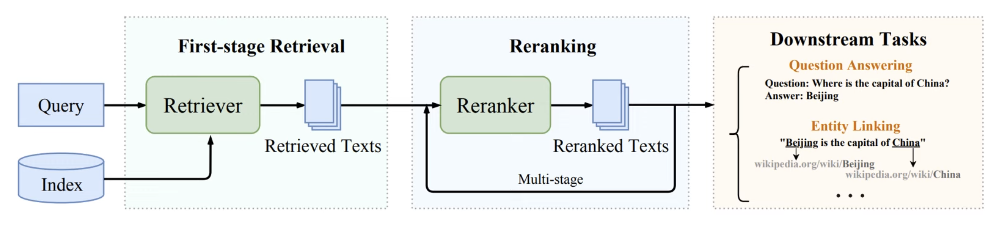
Query를 입력해 방대한 DB(knowledge Base)에서 관련 Document(Passage)를 출력하는 Task - 추가 파이프라인
- Retrieval: Query에 해당하는 Passage를 추출
- Reranking: Query와 Passage간 관련성을 기반으로 순서 재정렬
1.2 기존의 방법론
방법1: Sparse Retrieval-BM25
- lexical overlaps(어휘 중복)계산을 통해, Query와 연관성이 높은 Passage를 검색함
- 모델 학습이 필요하지 않아, 빠르고 일반화 성능이 좋음
- 하지만 lexical overlaps에 제한되어, 단어/문장의 의미(Semantic)는 반영이 불가능함
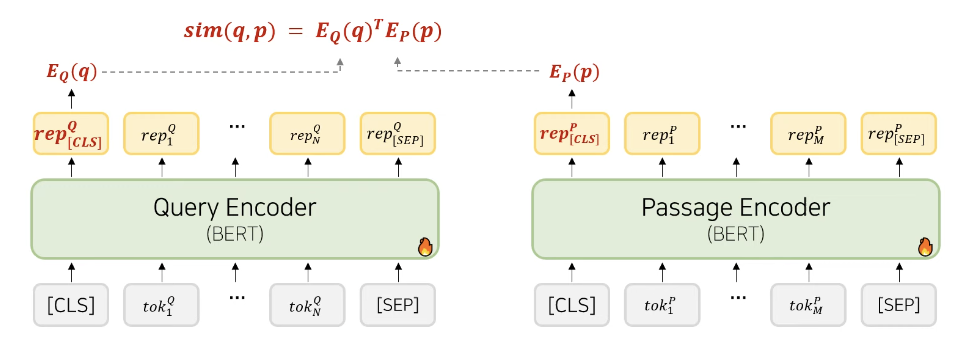
방법2: Dense Retrieval - DPR
-
단어/문장의 의미 정보도 반영하고자, Query와 Passage의 Dense Vector간 유사도로 연관성 평가
-
Query의 [CLS] embedding과, passage의 [CLS] Embedding간 Dot product를 Relevance Score로 사용함
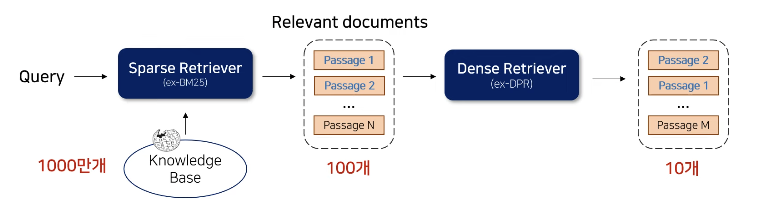
2-Step Retrieval
- Sparse Retrieval: 전체 Knowelge Base에서 일부 Passage를 추출
- Dense Retrieval: Re-ranking만 진행
효과: 속도 효율 + Retrieval 성능 향상 (Keyword기반 Retrieval + Semantic정보 모두 반영)
LLM in Information Retrieval
방법1: Direct Re-Ranking
- LLM의 사전 학습 지식과 추론능력을 활용해, Initial Retriecal Passage를 Re-Rank하는 벙법
- Instructional Permutation Generation
- LLM에게 Passage들을 주고 Reranking을 진행. Rank가 높은 Passage의 Number 생성
- Input: Query-Passage1-Passage2-...-PassageN
- Output: 2>3>1 (rank가 높은 Passage의 Index를 정렬한 값으로 내보냄)
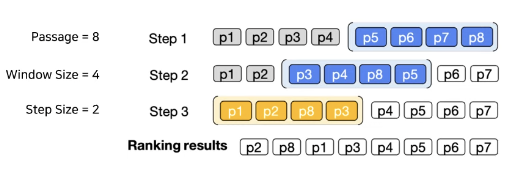
Sliding window strategy
LLM의 길이제한 문제로 인해 일부 Passage에만 Reranking이 가능함
-> Window size와 step size를 설정해 reranking을 진행하는 방법
방법2: Query Rewriting
- 관련 Passage를 더 잘 Retrieval 할 수 있도록, 사용자의 Original Query를 구체화 하는 것
- LLM에게 prompt를 주어, Query를 Augumentation하는 방법
-> Query의 모호성과 vocabulary mismatch 해결
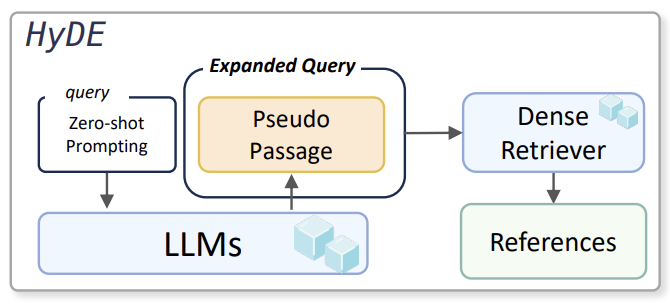
Query Rewriting 방법1 - HyDE
LLM이 생성한 Pseudo Passage를, Dense Retrieval의 Query로 사용해 Retrieval을 진행함
1. LLM에게 Zero-shot prompt를 주어서 Query와 관련된 Pseudo Passage를 생성함
2. Dense Retrieval로 Pseudo Passage를 Encoding한 후, Retrieval을 진행
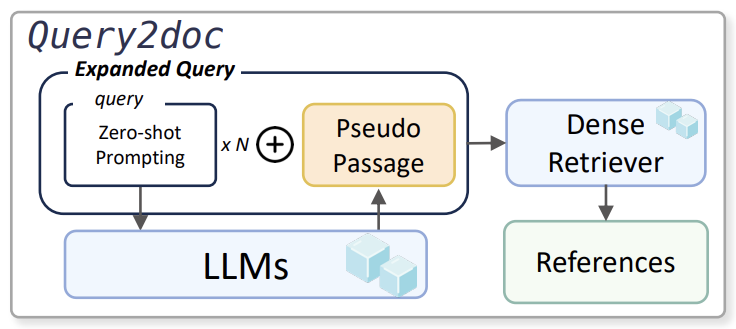
Query Rewriting 방법2 - query2doc
LLM이 생성한 Pseudo Passage를 Query와 Concat 후 Retrieval 진행
1. LLM에게 Zero-shot prompt를 주어서 Query와 관련된 Pseudo Passage를 생성함
2. 생성한 Pseudo Passage를 기존 Query와 Concat한 뒤 Retrieval을 진행
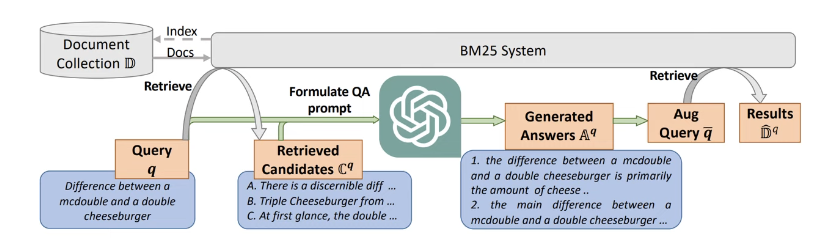
Query Rewriting 방법3 - LameR
Retrieve(BM25)-Generation(LLM)-Retrieve(BM25) 구조
1. Retrieve: BM25에서 Top-K(10개)의 Passage Retrieval을 수행함
2. Generation: 1단계에서 구한 Passage Retrieval과 Query를 LLM에 입력 후, 가상의 Answer를 생성함 (N번 반복)
3. Retrieve: 가상의 N개의 Answer를 Query와 Concat후, BM25로 Retrieval 진행(1000개 추출)
논문에서 말하고 있는 차별점
| 방법론 | LLM Query Expansion의 shot 개수 | Retriever Query에 사용되는 Pseudo Passage 개수 | 사용하는 Retriever 종류 | Query와 Passage Concat 방법 |
|---|---|---|---|---|
| HyDE | 0 (Zero-shot) | 1 | Dense | 단순 concat |
| Query2doc | 5 (Few-shot) | 1 | Sparse or Dense | Sparse (Query N번) Dense (단순 concat) |
| LameR | 10 (Few-shot) | 5 | Sparse | 단순 concat |
| MuGI | 0 (Zero-shot) * N번 | 5 (Sparse), 3 (Dense) | Sparse + Dense | Sparse (Adaptive Repetition Ratio) Dense (단순 concat) |
- Zero-shot * N번: zero-shot의 일반화 성능을 극대화함
- 2-Step Retrieval: Sparse + Dense Retrieval
- Adaptive Repetition Ratio: Query와 Passage간 길이 비율을 고려한 Concat방식
2.0 MuGI
- 2-Step Retrieval구조
Sparse Retriever로 Initial Retrieval -> Dense Retrieval로 Re-rank - LLM Query Expansion
각 단계의 Retriever의 Query로 LLM이 생성한 Pseudo Passage 활용
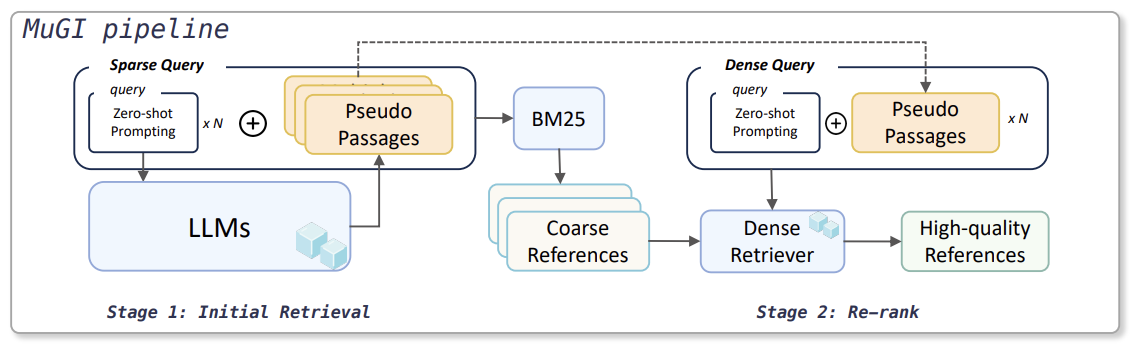
2.1 1단계- Initial Retrieval
Query Expension
- Query q -> Pseudo Passage R = 생성
- LLM Zero-shot prompt를 통해 다양성을 높인다는 장점
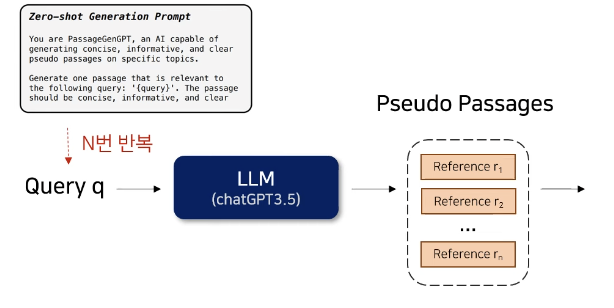
왜 Few-Shot이 아닌 Zero-shot으로 N번 반복해서 썼을까?
일반화된 단어 생성 task에서는 실험 데이터 셋이 Specific한 도메인의 데이터셋이라기 보다는 General 도메인 데이터셋이기에 Zero-Shot이 적합했을 것이라고 생각.도메인과 관련된 단어 생성의 경우는 Few-Shot이 적합하다고 생각.
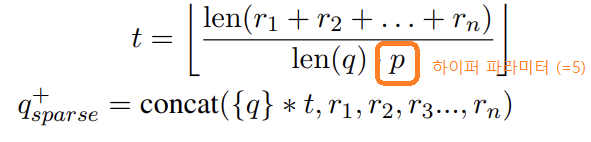
- Sparse Retrieval에서 Adaptive Repetition Ratio t를 적용하여 Query의 길이를 가변적으로 변경함.
- Query가 Reference보다 길이가 짧기 때문에 가중치가 줄어들 수 있음
-> Query를 t번 concat하고 넣어 Reference와 길이를 맞춰줌
2.2 2단계 - Re-rank
Query Expension
- Query q -> Pseudo Passages R = 생성
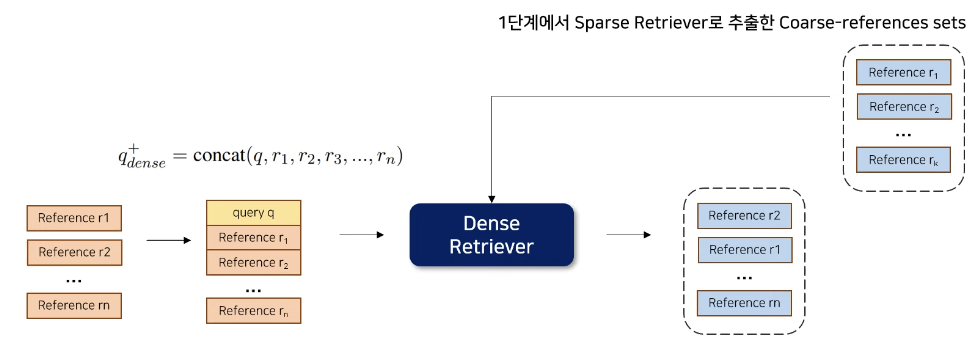
Dense Retrieval
- 1단계에서 Sparse Retriever로 추출한 Coarse-references sets과 Query q와 Reference를 Concat한 것을 Dense Retriever에 넣어서 Reranking을 해줌
(참고로 Adaptive Repetition Ratio t를 적용하지 않음 -> Semantic 정보로 검색하기 때문)
03 Set up
각 Retrival의 LLM model
- Sparse Retrieval Query: ChatGPT3.5-turbo 모델의 생성문 사용
- Dense Retrieval Query: ChatGPT4-turbo 모델의 생성문 사용
Query에 결합한 Passage 수
- Sparse Retriever(BM25): 5개 사용 (Adaptive Repetition Ratio의 하이퍼 파라미터로 p=5 사용)
- Dense Retriever: input length 제한 512로, 3개 사용함
3.1 Implementation Details
평가지표
- nDCG@10
Relevance Score가 높은 Passage가 상위에 있을수록 큰 값을 가지는 지표임
초기 Retrieval의 상위 100개의 결과에 대해 Re-ranking후 nDCG@10 측정
사용한 Dense Retriever 모델
- all-mpnet-base-b2 (AMB-v2)
빠르고 성능 좋은 파이프라인 개발이 목적이기에, 110M 파라미터를 가지는 작은 Dense Retrieval 모델 사용
3.2 In-domain Dataset
TREC DL19, DL20
- Query-Passage 형태로 되어 있는 데이터셋
- Out-Of-Distribution Dataset
BEIR의 9개 데이터셋 - 다양한 task, 다양한 domain이 반영된 Retrieval 분야 zero-shot 성능 측정용 - benchmark 데이터셋
- 다양한 task : News retrieval, Question answering, tweet retrieval 등 성격이 다른 9개 task
- 다양한 domain : 뉴스나 Wikipedia같은 광범위한 도메인, Scientific publications 같은 특정 도메인 등
4.0 Results
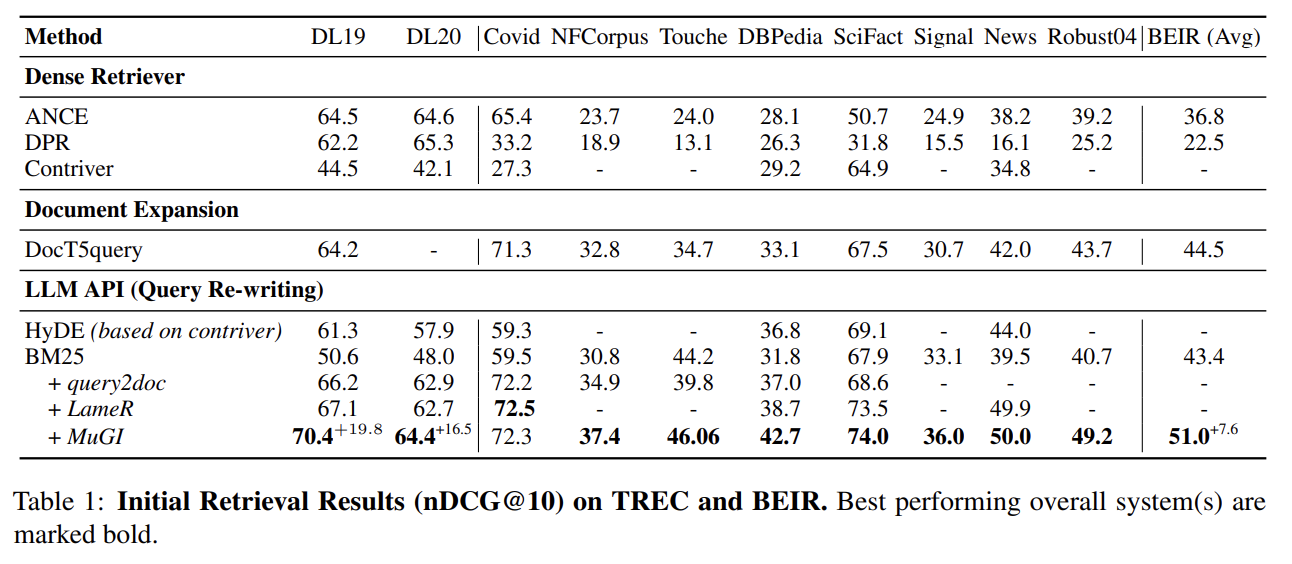
Initial Retrieval
In-domain, OOD 모두에서, 모든 Dense Retriever 모델의 성능 능가
Dense Retriever가 OOD(BEIR) Dataset에서 성능이 지나치게 낮은 이유는
BEIR 데이터셋으로 학습되지 않았기 때문으로 해석
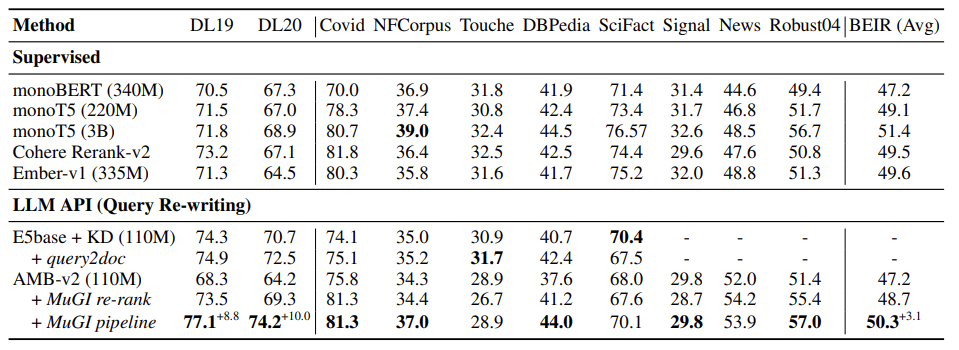
Re-Rank
대부분의 Supervised Model보다 성능 우수
monoT5(3B)라는 대규모 모델과 성능 격차 해소
5.0 Analysis
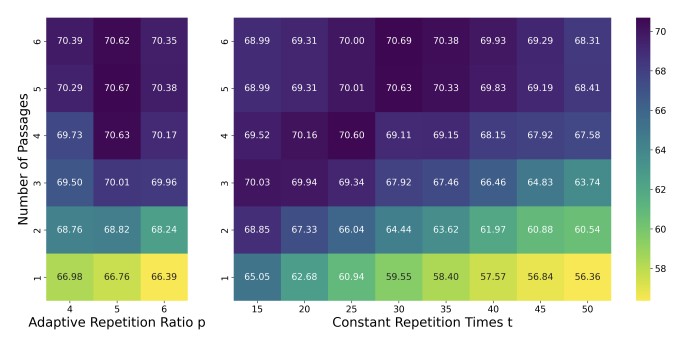
Hyper-parameters for Sparse Retrieval
Adaptive Repetition Ratio가 Robust한 성능 향상에 중요한 요인
일정 횟수만큼 반복하는 것보다, Query와 Passage 간 길이 비율에 따라 동적으로 변화하는 것이 중요
더 많은 Passage를 포함할수록 성능 향상
하지만, 최대치(5개) 이상부터는 성능이 더 오르지 않음
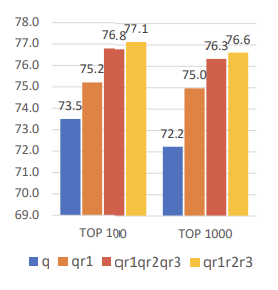
Integration Pattern for Dense Retrieval
Dense Retrieval Query와 Passage를 Concat하는 형태에 대한 분석
3개 Passage를 모두 Concat할 때 최적의 성능
특히 Query와 Passage를 번갈아 Concat하는 경우보다,
Query 하나 Passage 여러 개를 Concat하는 경우가 더 높은 성능
6.0 Conclusion
- LLM Rewriting 방법에 Sparse Retrieval과 Dense Retrieval를 모두 결합한 파이프라인 제안
- Adaptive Repetition Ratio로 Query와 여러 Passage 간 비율을 고려해 Concat하는 방법 제안
- Initial retrieval 및 Re-rank 모두에서 성능을 향상
- 간단한 BM25 모델에 제안 파이프라인을 결합하여 In-domain, OOD 모두에서 기존 방법론 성능보다 우수
한계: 속도 비교실험이 없다.
