
기존의 exhaustive search 방식의 비효율성으로 Object가 있을 법한 영역만 찾는 방법이 제안됨 이를 region proposal이라고 한다.
기존 알고리즘의 진행방식
1) detector는 Object가 있을법한 영역을 찾기 위해 exhaustive search(sliding window)을 진행한다. (region proposal)
2) 이 candidate object에 대해서 인식 알고리즘을 시행한다.
그러나 이 방식도 해결해야 될 단점이 존재한다.
-> object들이 각기 다른 shape를 가진다면 window로 scan이 되지 않는 object가 존재 할 수 있다. (고정된 size의 window는 각기 다른 size의 object를 포착하기 힘들기 때문)
만약 object recognition을 실행하기 전에 아래와 같이 이미지를 올바르게 segment하면 segmented result에 대해서 candidate object로 사용할 수 있지 않을까?
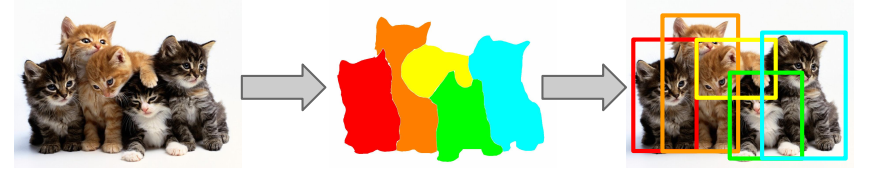
이 방법을 활용해서 제안한 것이 바로 Selective search이다.
Selective search가 나왔을때 기존의 방법들보다 좋은 성능을 보였다고 한다.
Selective Search의 목표: Object 인식이나 검출을 위해 가능한 후보영역을 잘 알아내는 것이 목표이다.

Selective search 진행과정
- 초기에는 원본 이미지로부터 각각의 object들이 1개의 개별 영역에 담길 수 있도록 수많은 영역들을 생성합니다.
💡 초기 영역을 나누는데 어떤 방법을 사용했을까?
Felzenszwalb's graph-based segmentation을 사용했다고 합니다.
이 기법은 픽셀간의 유사도를 측정하여 두 영역을 분리시킬 것인지 혹은 통합할 것이지 판단하는 수식을 사용한다고 합니다.
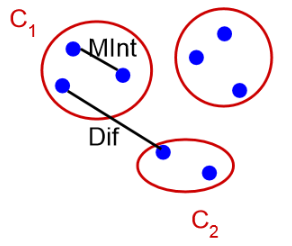
- 이후 아래 그림의 알고리즘에 따라서 유사도가 높은 것들을 하나의 Segmentation으로 합쳐주는데 그 자세한 과정은 다음과 같습니다.

최초 Segmentation을 통해서 나온 초기 n개의 후보 영역들
- 영역들 사이의 유사도 집합
- 색상, 무늬 ,크기, 형태를 고려하여 각 영역들 사이의 유사도를 계산
- 유사도가 가장 높은 와 영역을 합쳐 새로운 의 영역을 생성함
- 와 영역과 관련된 유사도는 에서 삭제
- 새로운 영역과 나머지 영역의 유사도를 계산하여 의 유사도 집합 생성
- 새로운 영역의 유사도 집합 와 영역 를 기존의 집합에 추가
- 2번 과정을 여러 번 반복하여 최종 후보 영역을 도출한다.
아래 그림과 같이 엄청나게 많았던 초기 영역들이 2번 과정의 횟수가 많하질수록 유사도가 높은 영역들이 합쳐져 후보 영역들이 줄어드는 것을 확인할 수 있다.
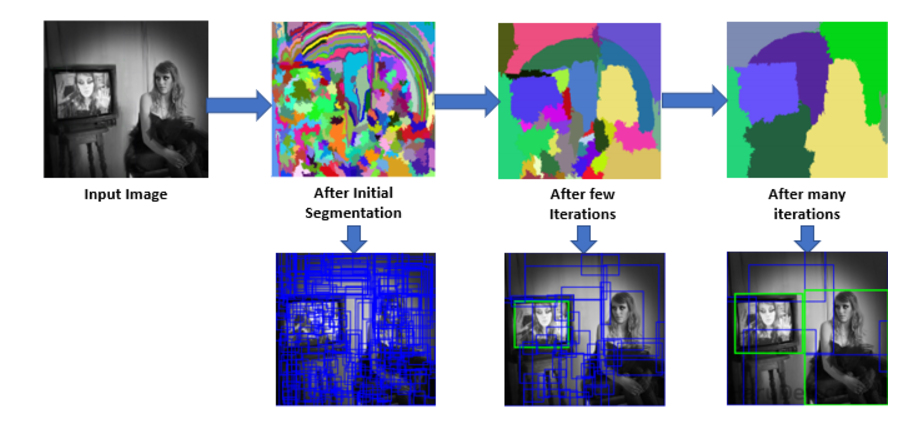
이제 최종 후보 영역들에 대해서 CNN을 통한 Classification과 Bounding box regression을 해주면 Object Detection이 수행되는 것이다.
그리고 이것이 최초의 딥러닝 기반 Object Detection 알고리즘인 R-CNN의 전반적인 과정이다.
