
Introduction
WRN은 residual net의 width를 증가시키고 depth를 감소시킨 모델이다.
너비가 증가한다는 것은 filter 수를 증가시킨다는 것을 의미한다. 즉, WRN은 residual block을 구성하는 convolution filter수를 증가시켜서 신경망의 너비를 증가시킨 것이다.
왜 이러한 연구가 나왔을까?
지금까지, CNN은 깊이를 증가시키는 방향으로 발전해왔다. (ex.VGG, Inception, ResNet) 하지만 모델의 깊이가 깊어지는 만큼 vanishing gredient, exploding gradient문제가 발생했다. 이 문제를 해결하기 위해 ResNet은 residual block개념을 제안했고 이는 뛰어난 성능을 보여줬다. 그리고 Pre-Activation ResNet을 제안하여 성능을 더 개선할 수 있었다.
Pre-Activation ResNet?
Pre-Activation ResNet리뷰를 참고해주세요
이전까지 너비에 따른 연구는 없었기 때문에 저자는 길피와 활성화 함수의 순서를 제외하고, ResNet의 넓이에 따른 정확도 양상을 실험한다. 그렇게 만들어진 것이 WRN(Wide Residual Network)이다.
ResNet의 문제점
1. Circuit Complexity theory
circuit complxity theory literature는 얇은 circuit은 깊은 circuit보다 더 많은 요소를 필요로 한다는 이론. 이를 신경망에 접목한다면 깊은 신경망이 가지는 표현력을 얇은 신경망이 가지기 위해서는 엄청나게 넓은 신경망을 구성해야 한다고 생각해볼 수 있다. (그만큼 parameter수가 늘어남)
ResNet저자는 이 이론을 ResNet에 접목시켜 bottleneck구조를 제안한다. 이 구조는 모델의 너비를 얇게 하여 파라미터의 수를 감소시켜 깊이를 증가시킨다. residual block을 최대한 얇게 구성하여 모델의 표현력을 증가시킨 것이다.
2. Diminishing feature reuse
Diminishing feature reuse는 순전파 연산시, 입력과 가까운 layer에서 학습한 특징이 최종 layer까지 도달하지 못하고 중간에 사라지는 문제이다. (많은 수의 가중치가 곱해져서 발생)
Diminishing feature reuse문제를 해결하기 위해 Stochastic Depth ResNet논문에서는 무작위로 특정 residual block을 제거한다. 이것은 dropout의 일종으로 생각해볼 수 있다. 그래서 WRN은 diminishing feature reuse문제를 다루기 위해 residual block에 dropout을 적용한다.
즉, WRN은 1의 문제는 모델의 넓이를 증가시켜 해결하려고 하고 2의 문제는 residual block내의 conv layer사이에 dropout을 끼워넣어 해결하려고 한 것이다.
WRN(Wide Residual Network)
Residual Block
-
basic: 3x3 conv - bn - ReLu - 3x3 conv - bn - ReLu로 이루어져 있음
-
bottle neck: 1x1 conv(차원축소) - bn - ReLU - 3x3 conv - bn - ReLu - conv 1x1(차원 다시 늘림) - bn - ReLU
-> 모델의 구조를 얇게 만들기 위해 사용하므로 WRN에서는 사용안함.
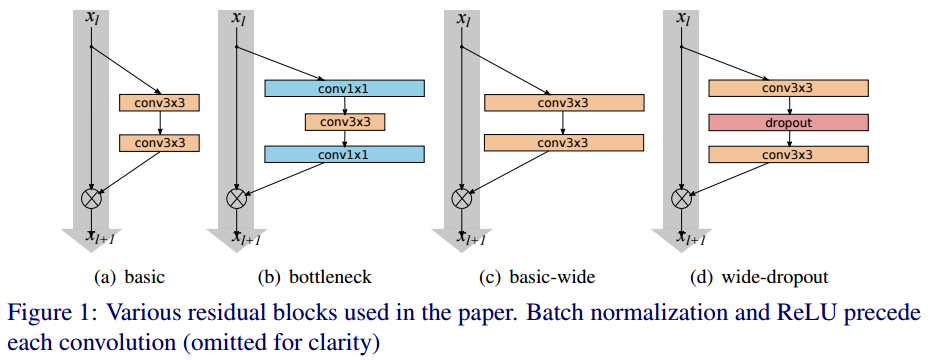
(c), (d)는 WRN의 residual block이다. pre-activation resnet에서 제안된 활성화 함수의 순서를 따른다. 그리고 각 conv layer가 가지고 있는 filter의 수를 k배한다.
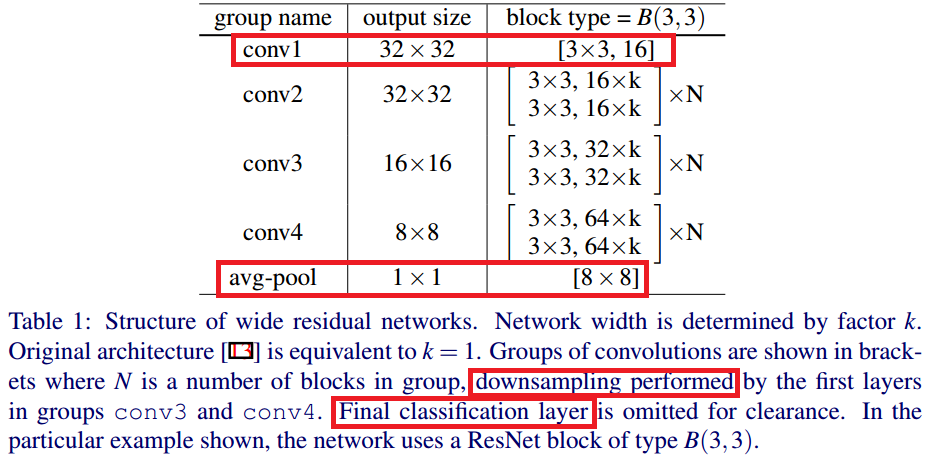
WRN-40-8?
N(layer의 수) = 6, k = 8이라는 뜻이다.WRN이 40개의 layer를 가질 경우 conv1, avg-pool, down sampling, Final classification layer를 제외한 36개의 residual block을 가진다. 이때 Figure1에서 하나의 block안에 각각의 3x3 필터가 두 개 있다는 것을 확인했다.
따라서 우리는 36/2 = 18개의 residual block을 가짐을 알 수 있고 18/3 = N 이므로 N이 6이라는 것을 알 수 있다.
필터 수에 K배를 해줌으로써, width를 증가시킨 것을 확인할 수 있다.
참고로 B(3, 3)은 filter의 kernel size를 의미한다.
Experimental Results
Type of convolution in a block
residual block을 구성하는 conv layer 개수와 kernel size에 따른 성능 실험이다. 예를 들어 B(1, 3, 1) = B(1x1 conv, 3x3 conv, 1x1 conv)로 이루어진 residual block이다.
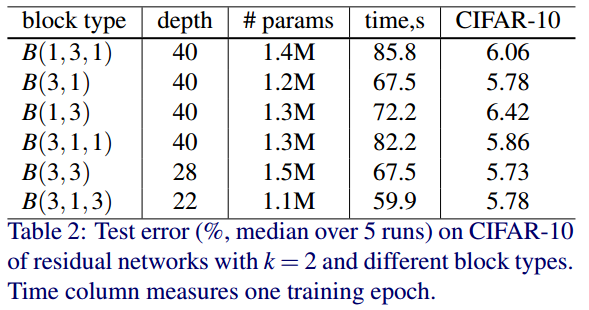
파라미터의 수는 최대한 비슷하게 맞춘 것을 확인할 수 있다. 이때 B(3, 3)의 성능이 CIFAR-10 데이터셋에서 가장 좋은 성능을 보여준다.
Number of convolution layer per residual block

2에서 가장 낮음을 알 수 있다.
실험결과를 종합했을때 B(3, 3)이 가장 좋다는 소리이다.
Width of residual block
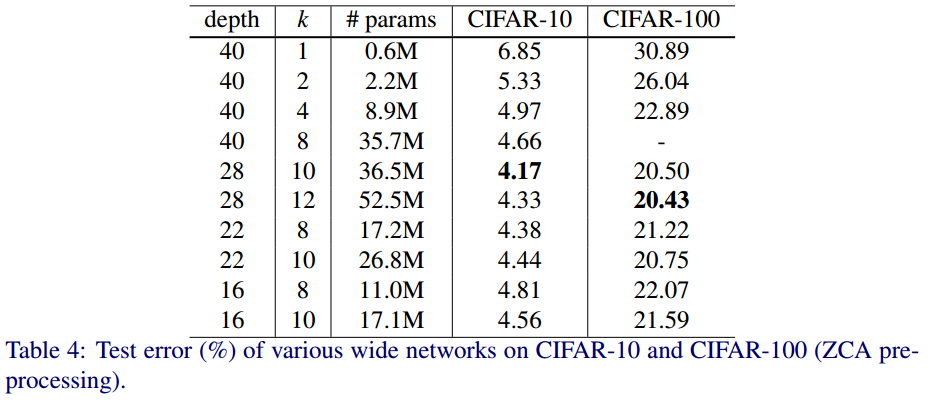
깊이와 너비에 따른 성능비교이다. K가 너비를 결정하는 파라미터이다.
너비가 어느정도 넓은 것이 얇고 깊은 모델보다 좋은 성능을 보였다.
Dropout in residual block
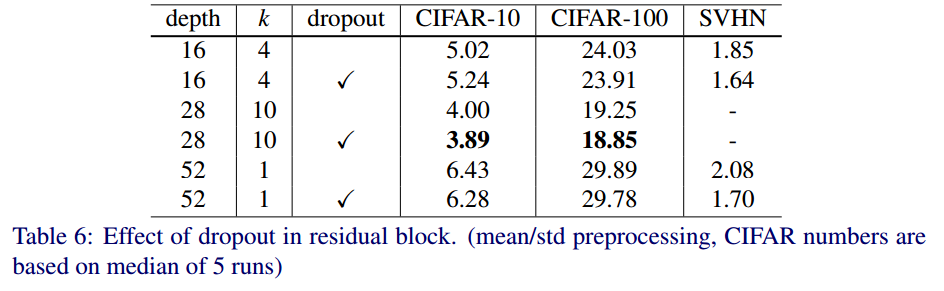
residual block사이에 dropout을 적용했는지 안했는지에 따른 성능 비교이다.
dropout을 한 것이 성능이 더 좋다는 것을 알 수 있다.
-> Diminishing feature reuse문제를 어느정도 해결했다고 볼 수 있음.
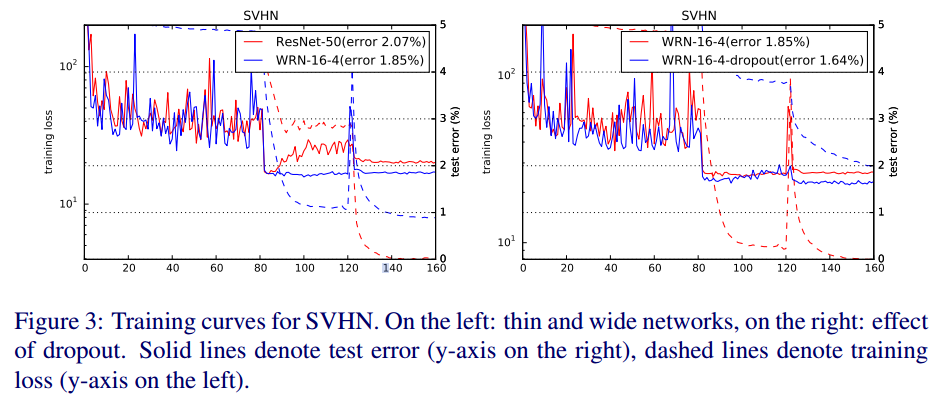
dropout을 적용하면 수렴속도도 더 향상시킬 수 있다.
Result
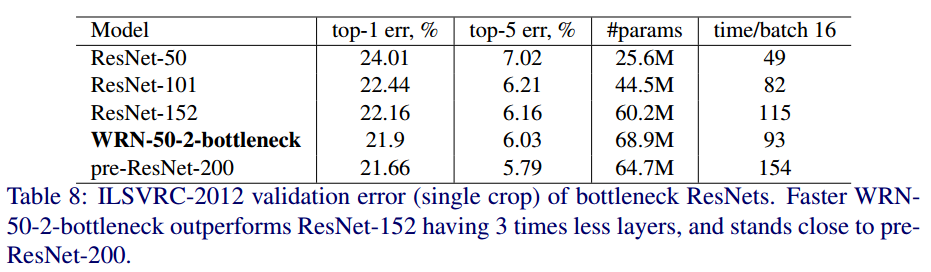
ImageNet 데이터 셋으로 ResNet과 WRN의 정확도를 비교한 것이다.
나는 개인적으로 이 부분을 보면서 두 가지 의문이 들었다.
-
너비를 이용하여 깊이를 줄이는 모델인데 사용한 데이터셋이 CIFAR10이었다.
CIFAR10은 사이즈가 매우 작은 이미지이기 때문에 receptive field를 생각했을때 성능측면에서는 당연히 depth가 작은 모델이 유리하다. -
마지막 비교에서는 ImageNet이 나오는데 depth 28을 쓰다 50이 나오고 파라미터 수도 pre-ResNet보다 많다는 점이 뭔가 애매하다고 생각했다.
depth대신 width를 늘려 ResNet의 두가지 문제점을 해결했다는 점에서 의의를 두어야 겠다.
CIFAR-10에서 depth가 작은 모델이 유리한 이유
CIFAR-10 이미지는 작기 때문에, 몇 층만 거쳐도 충분히 전체 이미지를 커버하는 receptive field를 얻을 수 있습니다.깊은 모델(예: ResNet-50 이상)은 지나치게 많은 층을 통해 너무 큰 receptive field를 형성하게 되어, 작은 이미지에서 불필요한 계산과 정보 손실이 발생함.
코드 구현
import torch
from torch import nn
class WiderBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride=1, projection=None, drop_p=0.3):
super().__init__()
self.residual = nn.Sequential(nn.BatchNorm2d(in_channels),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels, out_channels, 3, padding=1, stride=stride, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Dropout(drop_p),
nn.Conv2d(out_channels, out_channels, 3, padding=1, bias=False))
self.projection = projection
def forward(self, x):
residual = self.residual(x)
if self.projection is not None:
projection = self.projection(x)
else:
projection = x
out = residual + projection
return out
class WRN(nn.Module):
def __init__(self, depth, k, num_classes=1000, init_weights=True):
super().__init__()
N = int((depth-4)/3/2) # conv1, avg pool, down sampling, Final classification layer를 제외한 나머지 layer의 수
self.in_channels=16
self.conv1 = nn.Conv2d(3, 16, 3, padding=1, bias=False)
self.stage1 = self.make_stage(16*k, N, stride=1)
self.stage2 = self.make_stage(32*k, N, stride=2)
self.stage3 = self.make_stage(64*k, N, stride=2)
self.bn = nn.BatchNorm2d(64*k)
self.relu = nn.ReLU(inplace=True)
self.avg_pool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(64*k, num_classes)
if init_weights: # bias = 0, conv weight는 kaming initial기법 사용
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
def forward(self, x):
x = self.conv1(x)
x = self.stage1(x)
x = self.stage2(x)
x = self.stage3(x)
x = self.bn(x)
x = self.relu(x)
x = self.avg_pool(x) # down sampling
x = torch.flatten(x, start_dim=1)
x = self.fc(x) # classsification
return x
def make_stage(self, out_channels, num_blocks, stride):
if stride != 1 or self.in_channels != out_channels:
projection = nn.Conv2d(self.in_channels, out_channels, 1, stride=stride, bias=False)
else:
projection = None
layers = []
layers += [WiderBlock(self.in_channels, out_channels, stride, projection)]
self.in_channels = out_channels # skip-connection의 차원 수 맞춰주기
for _ in range(1, num_blocks):
layers += [WiderBlock(self.in_channels, out_channels)]
return nn.Sequential(*layers)