
0. Atomic units of NLP
우선 자연어 처리가 기존의 이미지나 숫자 데이터와 어떤 점에서 다른지 살펴보도록 하자. 자연어 처리는 인간의 언어인 자연어를 컴퓨터가 처리하는 방법을 연구하는 분야이다.
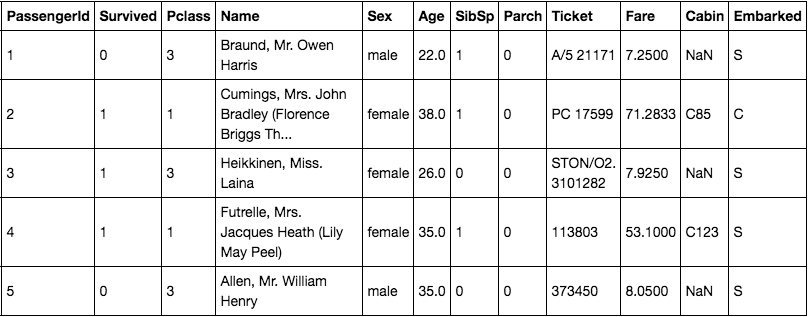
당연한 이야기지만, 숫자 데이터는 Titanic 데이터의 pclass, fare와 같이 숫자로 되어 있다. fare는 금액에 해당하는 데이터이기 때문에 연속형, pclass는 등급에 해당하는 데이터이기 때문에 이산형 데이터다. 두 데이터 종류가 조금은 차이가 있지만 컴퓨터가 처리하는데 있어서 데이터 그대로 처리가 가능하다는 점에서는 큰 차이가 없다. 즉, 3등급 좌석보다 1등급 좌석이 좋고, 7달러보다 1달러가 작은 금액이므로 그대로 모델이 처리할 수 있다.
하지만 자연어의 경우엔 그렇지 못하다. 자연어는 더하기, 빼기, 곱하기, 나누기와 같은 기본적인 연산이 불가능하기 때문에 일정한 처리를 통해 모델링에 사용하게 된다. 이때 가장 작은 요소인 자연어를 분리하여 사용한다. 즉, 코퍼스 -> 문단 -> 문장 -> 단어 -> 토큰 단위로 점점 데이터를 쪼개고, 가장 작은 토큰 단위로 데이터를 처리하게 된다.
1. Distributed Representation of Words
토큰 단위로 데이터를 처리할 때 가장 단순한 방법은 One Hot Encoding이다. 즉, 학습 데이터에 존재하는 각 토큰을 모두 모아서 vocab을 구성하고, 이 vocab에서 각각의 토큰마다 개별적은 인덱스를 부여하여 사용할 수 있다. 만약 전체 vocab의 크기가 5라면 [1 0 0 0 0][0 1 0 0 0]과 같이 토큰을 one hot vector로 변환해 컴퓨터가 인식하도록 만들 수 있다. 실제로 대부분의 트리 기반 모델은 이러한 전처리를 거쳐 자연어(정확하게는 범주형 변수)를 다룬다.
하지만 one hot vector는 다음과 같은 여러가지 문제점을 가지고 있다.
저장해야 할 데이터가 너무 크다.
우리는 5개의 토큰을 예시로 들었기 때문에 이게 무슨소리인가 할 수 있다. 하지만 현재 표준적인 vocab의 크기는 3만개 내외이다. 즉, 한 단어를 표현하기 위해서 해당 토큰의 인덱스만 1인 크기가 3만인 벡터를 사용해야 한다. 한 문장이 10개의 토큰으로 구성되어 있다면 30000×10의 행렬로 표현하게 된다.
지난 투빅스 프로젝트 때 330만개 코퍼스로 학습을 진행했는데, 각 코퍼스 당 대략 30문장으로 구성되어 있다고 하면, 3300000×30×30000 크기의 텐서가 필요해지는 것이다. 상당히 큰 텐서가 되고, 모델링하는데 무척 오래 걸릴 것이다.
정보가 거의 없다.
모델링하는데 오래 걸리는 것은 사실 큰 문제가 아니다. 그냥 좋은 gpu를 사용하면 된다. 하지만 이때 이용할 수 있는 단어의 정보가 매우 적다면 문제가 된다. 모델링이란 input의 정보를 가공하여 output에 매칭시키는 작업인데, 사용할 수 있는 정보가 적으니 제대로 매칭될 리가 없다.
one hot vector가 표현하는 유일한 정보는 a 단어와 b 단어가 다른 단어이다 라는 정보가 유일하다. 하지만 실제로 인간은 언어를 사용함에 있어 정말 다양한 정보를 다루게 된다. 각 단어가 가진 의미도 있을 것이고, 문장에 맞는 문법을 구사하기 위해 동일한 단어를 변형시키기도 한다. 하지만 이러한 정보는 one hot vector에는 전혀 담기지 않는다.
위 두가지 문제로 인해 단어를 다른 방식으로 벡터화하려는 노력들이 있었다. 가장 대표적으로는 각 문서별 단어의 표현 빈도를 나타내거나, tf-idf를 이용해 보다 정교화해서 사용할 수도 있다. 하지만 이러한 방법들은 오늘 소개할 word2vec에 비하면 여전히 정보를 온전히 담고 있지 못하다.
word2vec은 무엇보다 분산표상(distributed representation)이라는 개념을 이용해 단어를 벡터화한다. 분산표상이란 한 단어의 의미는 함께 사용되는 단어를 통해 유추할 수 있다는 것이다. 즉, 단어의 의미는 그 단어 자체에 있지 않고 그 단어와 함께 사용되는 다른 단어들에 있다. 이에 대해선 언어학이나 비교문학 등에서 자세히 다룬다고 하는데, 이 정도만 하고 넘어가자.
2. Word2Vec
어쨋든 word2vec이 분산표상을 이용하는 방식은 거칠게 표현하면 다음과 같다.
모든 토큰에 일정 크기의 랜덤한 값을 가지는 벡터를 할당한다.
d = 512라 하면 학습 데이터의 모든 토큰에 512 차원의 임의의 벡터를 할당한다.
일련의 학습과정을 거친다.
학습을 마친 벡터는 각 토큰들이 사용되는 문법적, 의미적 정보를 가지게 된다.
간단하다. 그냥 두 단계를 통해 완성된다. 이때 word2vec은 크게 skip-gram과 cbow로 방식이 나눠지는데 이는 2번에서 학습 방식을 달리하여 나눠진다.
2번의 자세한 내용을 정리하면 다음과 같다.
동시에 등장하는 단어의 정의
학습 과정의 정의
이 두가지를 중점적으로 다루면서 하나씩 살펴보도록 하자.
word2vec은 크게 두가지 모델로 구분되지만, 두 모델이 학습하는 원리엔 공통적으로 위에서 언급한 단어의 의미는 함께 사용되는 단어에 있다는 철학을 공유합니다. 이를 다음 문장을 통해 좀 더 자세히 알아봅시다.
I want ___ food tonight
위 문장에서 빈칸에 들어갈 알맞은 단어는 다음 중 무엇일까요?
itailian
mexican
chair
coffee
당연히 1번이나 2번일 것입니다. 그 이유는 빈칸의 주변을 살펴보면 "밤에 먹음직스러운 음식"에 해당하는 단어가 빈칸에 적합하기 때문입니다. 즉, 빈칸에 들어갈 italian이나 mexican은 "밤에 먹음직스러운 음식"이라는 정보를 가지고 있는 단어일 것입니다. 한 단어의 의미는 독립적으로 존재하지 않고, 함께 사용되는 단어를 통해 파악할 수 있습니다!
2-1. 중심단어/주변단어
word2vec은 동시에 등장하는 단어를 중심단어와 주변단어라는 용어로 표현합니다. 아래와 같은 문장이 있다고 합시다.
Colorless green ideas sleep furiously
총 6개의 토큰(Colorless, green, ideas, sleep, furiously)으로 이루어진 문장입니다. 이때 기준이 되는 단어를 중심단어, 중심단어와 동시에 등장하는 단어를 주변단어라고 정의합니다.
즉, 한 문장에 같이 등장하는 단어라고 해도 항상 동시에 등장하는 단어라고 여기지 않습니다. 그럼 어디까지가 동시에 등장하는 단어일까요? 윈도우 사이즈를 통해 이를 정의합니다. 윈도우 사이즈란 하이퍼 파라미터로 중심단어로부터 윈도우 사이즈만큼 떨어진 토큰만 동시에 등장하는 단어라 간주하고 주변단어로 여깁니다. 예를 들어 윈도우 사이즈가 1이고, 중심단어가 green이라면 아래와 같이 green 양 옆으로 1 토큰 이내에 위치한 colorless, ideas만 green의 주변단어가 됩니다. 이를 정리해보면 다음과 같습니다.
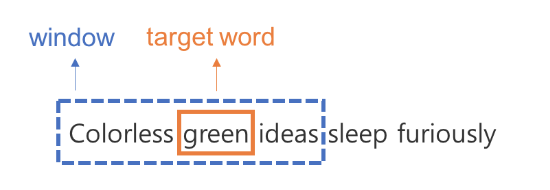
이러한 과정을 각 토큰을 중심 단어로 보고 주변단어를 매번 정리할 수 있습니다. 그 결과는 다음과 같습니다.
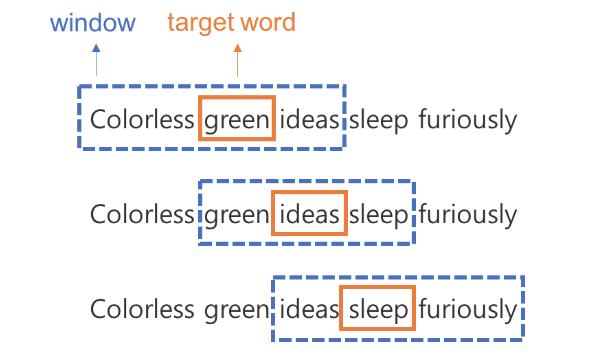
즉, 하나의 문장에서 학습 데이터가 위와 같이 여러 개 나오게 됩니다. 중심단어 하나에 윈도우 사이즈 X 2 만큼의 주변단어가 존재한다는 점을 기억해주세요.
2-2. CBOW
위에서 동시에 등장한 토큰을 정의했는데, 어떤 방식으로 학습하면 벡터에 토큰들의 문법적, 의미적 정보를 담을 수 있을까요? CBOW는 주변단어들의 정보로 중심단어를 맞추는 과정을 통해 이러한 정보를 벡터에 녹일 수 있다고 간주합니다.
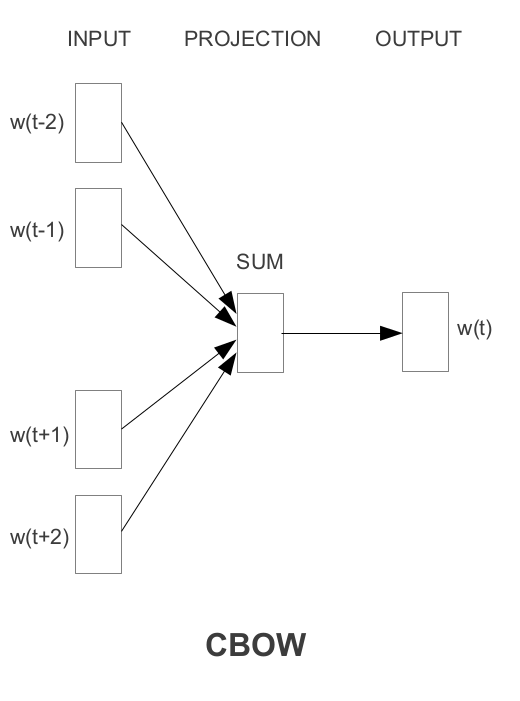
2-2-1. 모델 구조
- input(1×V) : input은 토큰의 인덱스에 해당하는 원소만 1인 one hot vector입니다.
- input과 hidden layer 사이의 가중치 W V×M : 이 가중치는 모든 토큰의 임베딩 벡터를 행으로 가지는 행렬입니다.
- hidden layer와 output 사이의 가중치 W M×V: 이 가중치는 반대로 모든 토큰의 임베딩 벡터를 열로 가지는 행렬입니다.
- output : output은 입력 토큰의 벡터와 각 토큰의 유사도를 계산한 값입니다.
- 최종 출력 : 위 그림엔 나와있지 않지만 output은 softmax 함수를 통과하여 최종적인 출력을 가지게 됩니다.
모델 구조를 입력부터 살펴보면 다음과 같은 흐름을 가집니다.
- 우선 주변 단어 각각이 one hot vector로 입력됩니다.
- 입력된 one hot vector 들은 W V×M 와 행렬곱을 수행합니다. 이 과정을 통해 각 단어의 인덱스에 해당하는 W V×M 의 행만 나오게 됩니다((1×V)(V×M) = (1×M)). 즉 각 단어의 임베딩 벡터를 가져옵니다.
- 각 주변단어의 임베딩 벡터를 합 혹은 평균합니다. 이를 통해 주변 단어의 정보를 하나의 벡터로 표현합니다.
- 이렇게 주변단어의 정보를 가지고 있는 벡터((1×M))를 다시 W M×V 와 곱하여 다음 레이어로 통과시킵니다((1×M)(M×V)=(1×V). 이 과정에서 두번째 가중치 행렬 W'는 각 열에 모든 임베딩 벡터를 가지고 있다는 점을 생각합시다. 즉, 4번 과정은 주변단어의 정보를 각 임베딩 벡터와 내적하는 과정이라 할 수 있습니다. -> 1xM의 행렬과 MxV행렬의 열벡터가 각각 내적을 하기 때문에 어떤 embedding 해당 주변단어와 관련성이 가장 높은지 알 수 있습니다. 유사한 벡터일 수록 값이 커지기 때문에 유사한 단어 임베딩값과의 내적은 다른 내적값보다 더욱 커질 것 입니다.
- 그 결과 만들어진 output vector (1×V)는 주변단어의 정보와 각 토큰의 normalize되지 않은 코사인 유사도를 나타냅니다(코사인 유사도에 대한 정보는 여기). 개념이 어렵다면 그냥 output vector는 주변단어의 정보가 모든 토큰들과 어느정도로 유사한지를 담고 있는 벡터라고 생각합시다.
- 이러한 벡터를 softmax 함수에 통과시키면 중심단어로 올 단어의 확률분포가 만들어집니다. 즉, 주변단어로 중심단어를 예측했습니다.
- 이를 실제 중심 단어 one hot vector를 이용해 cross entropy를 구하여 역전파 시킵니다.
2-2-2. 임베딩 벡터
모델 구조에서 이야기했듯이, cbow는 두가지 임베딩 벡터를 가지고 있습니다.
W와 W'인데, W는 주변단어일때의 임베딩 벡터이고, W'는 중심단어일 때의 임베딩 벡터로 간주합니다. 실제로 임베딩 벡터를 사용할 때는 W만 단독으로 사용하거나, W + W'를 사용하게 됩니다.
W'이 중심단어의 임베딩이 될 수 있는 이유는 주변 단어에 대해서 가장 어울릴만한 단어들의 값들을 W와의 내적으로 구할 수 있기 때문입니다.
2-3. Skip-Gram
하지만 이런 식으로 학습이 진행되면 조금 아쉬운 점이 있습니다. CBOW는 입력값으로 다수의 단어 벡터를 사용하는 과정에서 아래와 같은 복잡도를 가지게 됩니다.
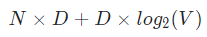
여기서 N = 윈도우 사이즈, D = 임베딩 벡터 크기, V = 보캡 크기 입니다. 그래서 Skip Gram은 이를 개선하여 연산속도를 빠르게 하면서 비슷한 학습 과정을 거치도록 설계했습니다.
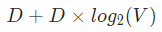
2-3-1. 모델구조
Skip-Gram은 CBOW의 모델 구조를 뒤집었습니다. 즉, 중심단어를 입력으로 하여 주변단어를 예측하는 과정을 수행합니다.
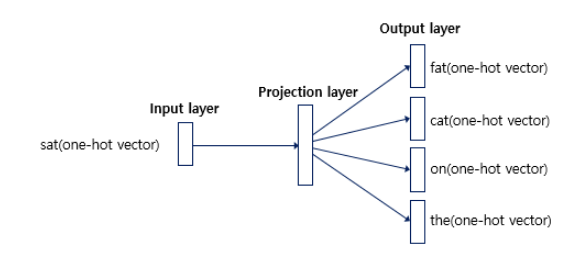
여기서 가중치 벡터나 모델의 순전파 방식은 거의 동일합니다. 다른 점만 이야기해보면 다음과 같습니다.
-
input으로 중심단어를 사용하기 때문에 hidden layer의 벡터는 중심단어의 임베딩 벡터가 됩니다.
-
CBOW와 다르게 input으로 하나의 단어만 사용되기 때문에 더하거나 평균을 구하는 과정이 없습니다.
-
CBOW와 다르게 주변단어를 예측하기 때문에 softmax를 통과한 확률분포는 모든 주변단어와 손실값을 계산하여 역전파가 이루어지게 됩니다.
2-3-2. 장점
이를 통해 중심단어와 주변단어의 관계를 통해 학습이 이루어지는 CBOW의 학습 과정은 거의 모사하되, input으로 사용되는 one hot vector를 N개에서 1개로 줄여 연산량을 줄일 수 있었습니다. 또한, 모델 성능에서도 CBOW보다 Skip-Gram이 훨씬 잘 잡아내는 모습입니다.
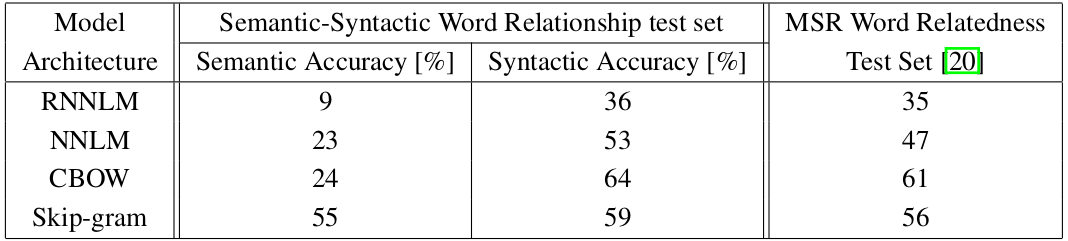
의미적 정보에서 Skip-Gram이 월등히 앞서면서 문법적 정보에선 아주 조금 밀리는 모습을 보입니다.
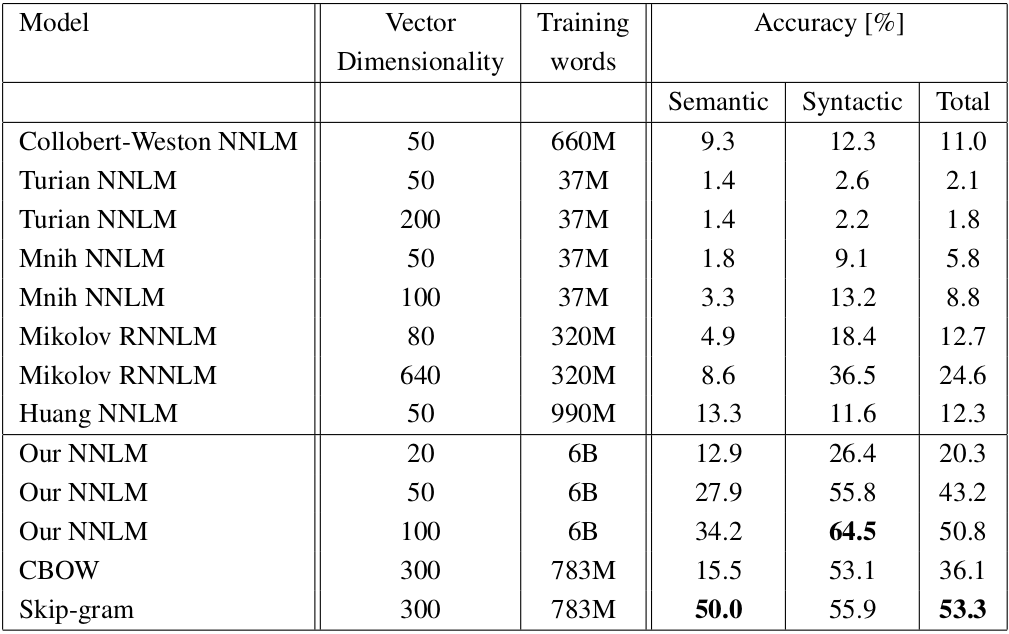
여기서는 Skip-gram이 Cbow보다 좋은 성능을 보입니다.
참고자료
https://arxiv.org/abs/1301.3781 word2vec 1
https://arxiv.org/abs/1310.4546 word2vec 2
https://arxiv.org/abs/1402.3722
https://wikidocs.net/22660
https://dreamgonfly.github.io/blog/word2vec-explained/
https://ratsgo.github.io/deep%20learning/2017/10/02/softmax/
