
Attention is All you need는 Transformer 모델을 처음 제안한 논문이다. 자연어와 비전영역 모두 중요하게 다뤄지는 모델이기 때문에 논문리뷰도 꼼꼼하게 할 생각이다.
Attention사용 이전 모델의 구조
transformer와 다른 모델간의 차이점을 비교하기 위해 RNN기반 Seq2seq모델 먼저 소개하겠다.
RNN
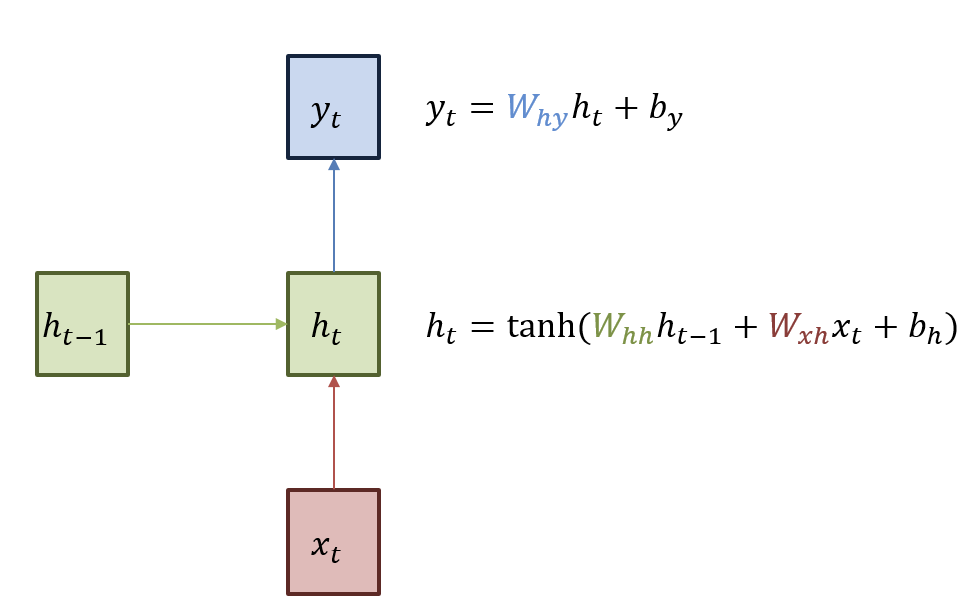
RNN은 Recurrent neural Network로 반복되는 neural network를 사용한다는 의미를 가지고 있다.
실제로 RNN은 동일한 weight를 사용한다.
- 동일한 weight를 사용함으로써 얻는 이점이 무엇일까?
-> 동일한 weight를 사용해서 입력을 받고 이전 정보를 다음 ht에 전달하면서 ht-1시점에서 받은 단어의 정보를 획득할 수 있다는 장점이 있다.
그렇다면 RNN은 어떤 단점이 있을까?
- 현재시점에서 멀어질수록 해당 단어의 의미가 왜곡될 가능성이 높아진다.
-> 예를들어 나는 밥을 먹고 산책을 나갔다. 이 문장을 번역하는 RNN기반 Seq2seq모델을 생각해보자,
모델의 구조는 다음과 같을 것이다.
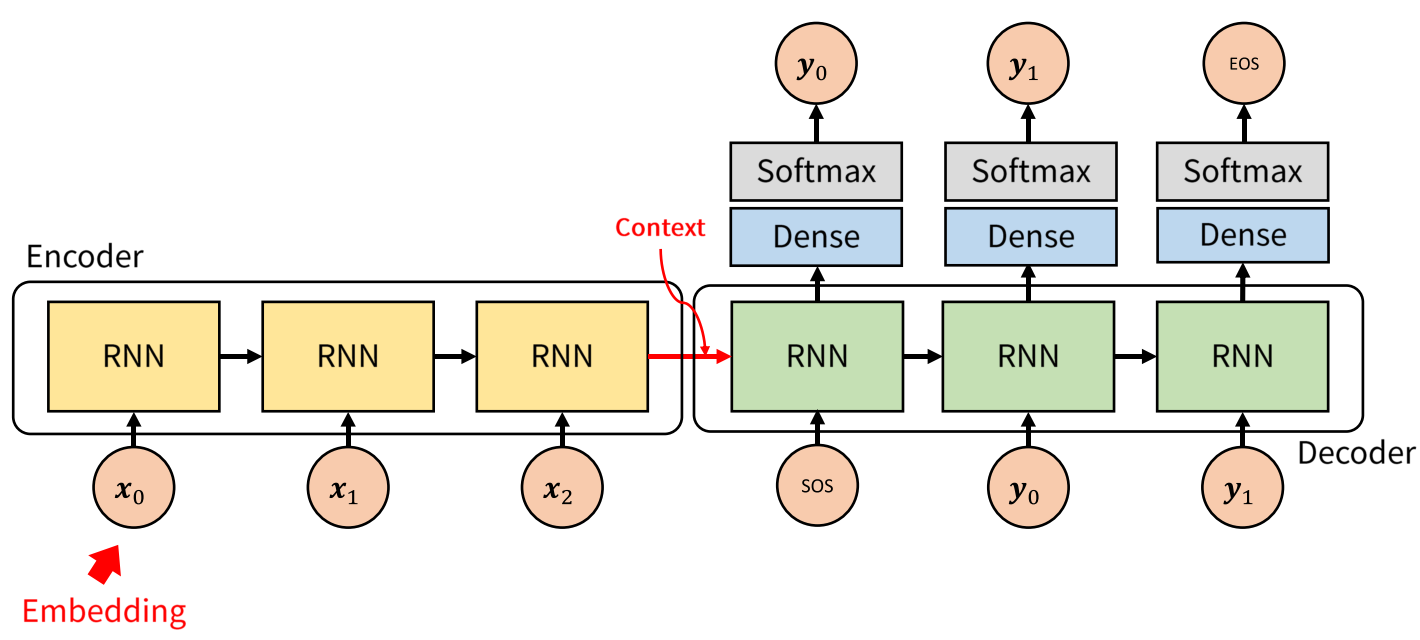
여기서 번역된 문장이 I went for a walk after eating 이라고 해보자.
현재 walk까지 주어져있다면 모델은 이전에 주어진 단어들의 정보를 최대한 사용해서 after를 예측해야 될 것이다.
하지만 input의 첫번째 값인 나는의 정보는 과연 올바르게 유지가 될까?
현재 시점에서 멀어질수록 단어에 곱해지는 weight와 activation의 개수가 많아진다.
-> 왜곡될 가능성이 높아짐.
- 멀수록 update가 잘 되지않음
-> activation으로 tanh를 쓴다.
tanh함수는 다음과 같다.
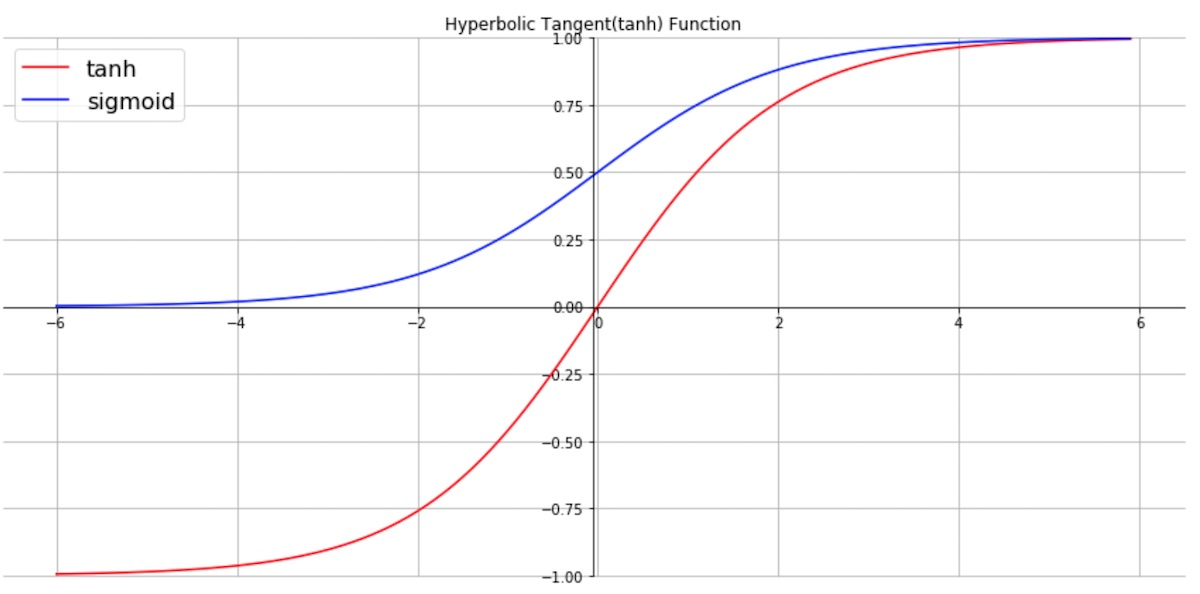
tanh함수는 sigmoid보다 기울기가 크기 때문에 vanishing gradient문제가 조금 해결된다는 장점이 있지만 최대기울기가 1이기 때문에 vanishing gradient문제가 완벽하게 해결되지는 않는다.
기울기가 최대 1이기 때문에 현재 시점에서 멀이질수록 training과정에서 backpropagation을 사용한 weight update값이 0에 수렴하게 되는 것이다.
이 문제를 해결하기 위해 Attention이라는 방법론이 등장했다.
Attention
그렇다면 Attention은 어떻게 이 문제를 해결했을까?
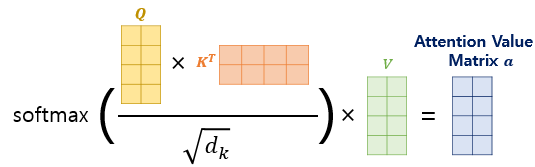
이것이 바로 Attention이다. (생각보다 간단하쥬?)
나는 이 수식이 왜 이렇게 만들어졌을지 생각해봤다.
일단 Attention은 RNN의 두가지 문제점을 잘 해결해냈다.
-> 편미분을 많이 안해도 목표하는 미분지점에 도달이 가능함
편미분을 많이 하지 않아서 vanishing gradient문제가 어느정도 해결되었다.
Q, K, V는 각 단어의 의미를 담고 있는 word embedding이다.
-> 단어의 embedding weight와 tokenizer의 one-hot값을 곱한 값임 (learnable parameter)
이를 통해 embedding값도 model이 알아서 학습하는 것을 알수 있음.
dk는 key의 embedding dimention이다. (왜 나눠줬을까..?)
root dk로 key와 query의 내적값을 나눠줬기 때문에 내적의 분산이 작아졌다. -> softmax의 미분이 작아지는 것 방지 -> vanishing gredient문제 방지
transformer는 Attention을 어떻게 사용했을까?
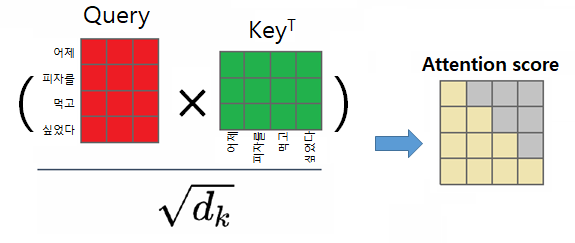
transformer는 자신에 대한 Attention을 해서 단어간의 관계성을 학습시킨다.
근데 어떻게 관계성을 학습시킨다는 것인지 감이 오지 않아서 고민을 하기 시작.
수식을 다시 살펴보기 시작했다.
self-Attention
나는 softmax함수를 통해 출력된 스칼라 값(attention-score)을 weight라고 생각했다.
-> 그렇다면 한 단어에 대한 self-attention의 수식은 각 word-embedding에 대한 weighted sum이 된다.
new_word_embed = w1embed1 + w2embed2 + ....
하지만 그냥 weight로만 인식하면 식의 입장에서는 어떤 단어에 의해 weight가 커지고 작아지는지 구분이 안되기 때문에 weight의 값에 인식하고자 하는 word-embedding값을 넣어놓은 것이라고 생각한다.
-> 관련있는 단어의 weight가 커짐 해당 단어의 embedding-vector값이 커지기 때문에 그 단어와 연관성이 커짐
transformer는 next-token-prediction방식으로 traning, test가 진행되기 때문에 현재시점보다 앞에 있는 word에 mask를 씌워야한다.

-> softmax함수를 적용하기 전 mask에 해당하는 값에 매우 작은 값을 넣어서 mask값들이 출력에 영향을 미치지 못하도록 만들었다.
왜 softmax적용이후에 사용하지 않았을까? -> 이후에 사용하면 각 행의 합이 1이 아니므로 확률분포가 아니게 된다. 그리고 각 행의 합이 모두 달라지기 때문에 기준이 없어짐
Positional Encoding(Embedding)
Data에 Seq(순서)정보를 추가하는 것
트랜스포머는 단어의 위치 정보를 얻기 위해서
각 단어의 임베딩 벡터에 위치 정보들을 더하여
모델의 입력으로 사용
RNN이 자연어 처리에서 유용했던 이유는
단어의 위치에 따라 단어를순차적으로 입력받아서
처리하는 RNN의 특성으로 인해 각 단어의 위치 정보
(position information)를 가질 수 있다
트랜스포머는 단어 입력을 순차적으로 받는 방식이 아니다
따라서, 단어의 위치 정보를 다른 방식으로 알려주어야 한다
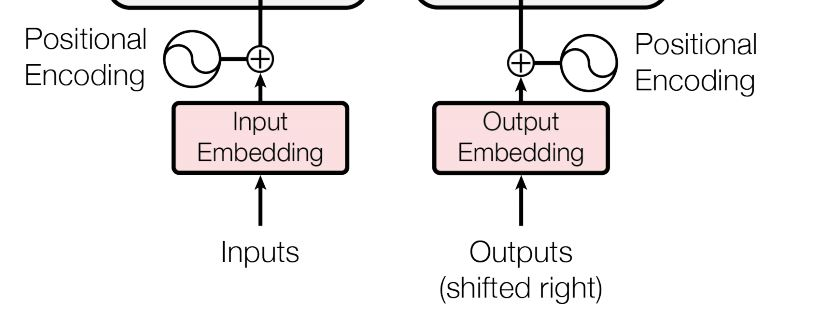
입력으로 사용되는 임베딩 벡터들이 트랜스포머의 입력으로 사용되기 전에 포지셔널 인코딩의 값이 더해진다
위치(Position)에 대한 절대적 위치를 표현하는 것이 아니라 대변 할 수 있는 encoding
포지셔널 인코딩을 학습시킬 수 있지만, 고정된 벡터여도
학습의 질에는 큰 차이가 없다는 것을 논문 저자가 밝힘
위치(Position)에 대한 unique한 벡터가 생성됨
-> 동일 위치는 같은 벡터가 생성된다
실제 코드구현은 embedding matrix를 만들어서 모델이 스스로 학습함!
Multi-Head Attention

-
왜 그냥 어텐션말고 Multi-head를 사용했을까?
-> 앙상블이 생각난다. (다양성을 높히기 위해 사용한 것이 아닐까?)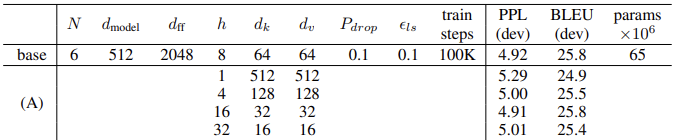
논문에서는 단순히 많은 parameter를 사용한 것이 아니라 parameter의 개수는 유지한 채로 실험을 진행했다. (embedding차원 * head = embedding 차원 = 8 x 64 = 512)
그 결과 실제로 성능이 증가한 것을 확인할 수 있었다.
Multi-Head Attention 구현코드
class MHA(nn.Module):
def __init__(self, d_model, n_heads):
self.d_model = d_model
self.n_heads = n_heads
self.fc_q = nn.Linear(d_model)
self.fc_k = nn.Linear(d_model)
self.fc_v = nn.Linear(d_model)
self.fc_o = nn.Linear(d_model)
self.scale = torch.sqrt(d_model/n_heads)
def forward(self, Q, K, V, mask=None):
Q = rearrange(Q, 'batch word (head dim) -> batch head word dim', head=self.n_heads)
K = rearrange(K, 'batch word (head dim) -> batch head word dim', head=self.n_heads)
V = rearrange(V, 'batch word (head dim) -> batch head word dim', head=self.n_heads)
attention_score = Q@K.transpose(-2, -1) # batch head word word
if mask is not None:
attention_score[mask] = -1e10
attention_weight = nn.softmax(attention_score, dim=-1)
attention = attention_weight@V
x = rearrange(attention, 'batch head word dim -> batch word (head dim)')
x = self.fc_o(x)
return x, attention_weight
einops 라이브러리를 사용해 차원을 바꿨다.
Encoder 구현코드
class EncoderLayer(nn.Module):
def __init__(self, d_model, d_ff, n_heads, drop_p):
super().__init__()
self.self_atten = MHA(d_model, n_heads)
self.self_atten_LN = nn.LayerNorm(d_model)
self.FF = FeedFoward(d_model, d_ff, drop_p)
self.FF_LN = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(drop_p)
def forward(self, x, enc_mask):
residual, atten_enc = self.self_atten(x, x, x, enc_mask)
x = self.dropout(x)
x = self.self_atten_LN(residual + x)
residual = self.FF(x)
residual = self.dropout(residual)
x = self.FF_LN(residual + x)
return x, atten_enc
class Encoder(nn.Module):
def __init__(self, input_embedding, max_len, n_layers, d_model, d_ff, n_heads, drop_p):
super().__init__()
self.scale = torch.sqrt(d_model/n_heads)
self.input_embedding = input_embedding
self.pos_embedding = nn.Embedding(max_len, d_model)
self.dropout = nn.Dropout(drop_p)
self.layers = nn.ModuleList([EncoderLayer(d_model, d_ff, n_heads, drop_p) for _ in range(n_layers)])
def forward(self, src, enc_mask, atten_map_save=False):
pos = torch.arrange(src.shape[1]).expand_as(src)
x = self.scale * self.input_embedding(src) + self.pos_embedding(pos)
x = self.dropout(x)
atten_encs = torch.tensor([]).to(DEVICE)
for layer in self.layers:
x, atten_enc = layer(x, enc_mask)
if atten_map_save is True:
atten_encs = torch.cat([atten_encs, atten_enc[0]], dim=0) # layer head word word
return x, atten_encsDecoder 구현코드
class DecoderLayer(nn.Module):
def __init__(self, d_model, d_ff, n_heads, drop_p):
super().__init__()
self.self_atten = MHA(d_model, n_heads)
self.self_atten_LN = nn.LayerNorm(d_model)
self.enc_dec_atten = MHA(d_model, n_heads)
self.enc_dec_atten_LN = nn.LayerNorm(d_model)
self.FF = FeedForward(d_model, d_ff, drop_p)
self.FF_LN = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(drop_p)
def forward(self, x, enc_out, dec_mask, enc_dec_mask):
residual, atten_dec = self.self_atten(x, x, x, dec_mask)
residual = self.dropout(residual)
x = self.self_atten_LN(x + residual)
residual, atten_enc_dec = self.enc_dec_atten(x, enc_out, enc_out, enc_dec_mask) # Q는 디코더로부터 K,V는 인코더로부터!!
residual = self.dropout(residual)
x = self.enc_dec_atten_LN(x + residual)
residual = self.FF(x)
residual = self.dropout(residual)
x = self.FF_LN(x + residual)
return x, atten_dec, atten_enc_dec
class Decoder(nn.Module):
def __init__(self, input_embedding, max_len, n_layers, d_model, d_ff, n_heads, drop_p):
super().__init__()
self.scale = torch.sqrt(torch.tensor(d_model))
self.input_embedding = input_embedding
self.pos_embedding = nn.Embedding(max_len, d_model)
self.dropout = nn.Dropout(drop_p)
self.layers = nn.ModuleList([DecoderLayer(d_model, d_ff, n_heads, drop_p) for _ in range(n_layers)])
self.fc_out = nn.Linear(d_model, vocab_size)
def forward(self, trg, enc_out, dec_mask, enc_dec_mask, atten_map_save = False): # trg.shape = 개단, enc_out.shape = 개단차, dec_mask.shape = 개헤단단
pos = torch.arange(trg.shape[1]).expand_as(trg).to(DEVICE) # 개단
x = self.scale*self.input_embedding(trg) + self.pos_embedding(pos) # 개단차
# self.scale 을 곱해주면 position 보다 token 정보를 더 보게 된다 (gradient에 self.scale 만큼이 더 곱해짐)
x = self.dropout(x)
atten_decs = torch.tensor([]).to(DEVICE)
atten_enc_decs = torch.tensor([]).to(DEVICE)
for layer in self.layers:
x, atten_dec, atten_enc_dec = layer(x, enc_out, dec_mask, enc_dec_mask)
if atten_map_save is True:
atten_decs = torch.cat([atten_decs , atten_dec[0].unsqueeze(0)], dim=0) # 층헤단단 ㅋ
atten_enc_decs = torch.cat([atten_enc_decs , atten_enc_dec[0].unsqueeze(0)], dim=0) # 층헤단단 ㅋ
x = self.fc_out(x)
return x, atten_decs, atten_enc_decsTraining 정보
epochs 12
Adam (
Parameter Group 0
amsgrad: False
betas: (0.9, 0.98)
capturable: False
differentiable: False
eps: 1e-09
foreach: None
fused: None
lr: 0.00022260183745731945
maximize: False
weight_decay: 0
)Training, Validation Loss
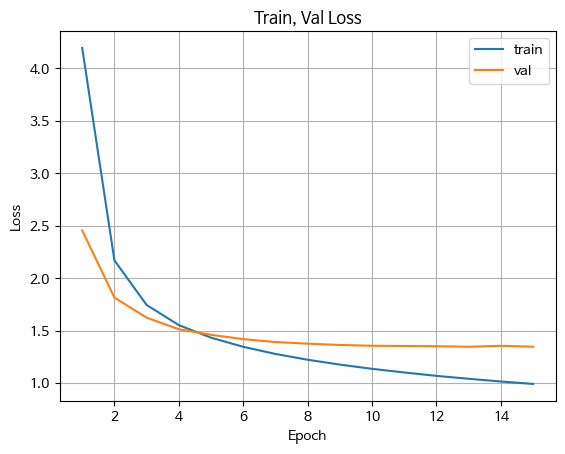
잘 줄어드는 것을 확인했다.
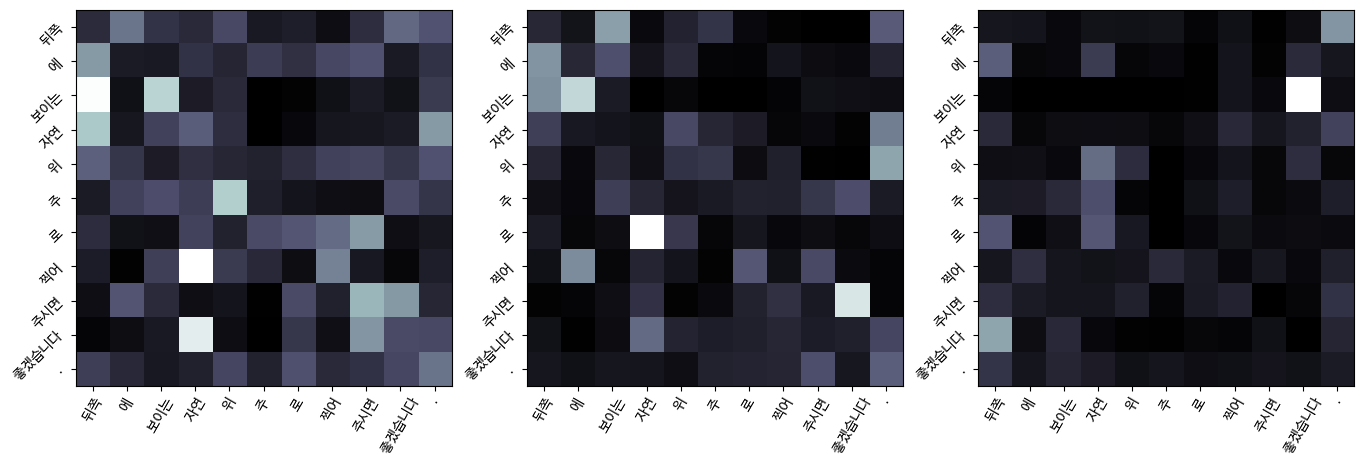
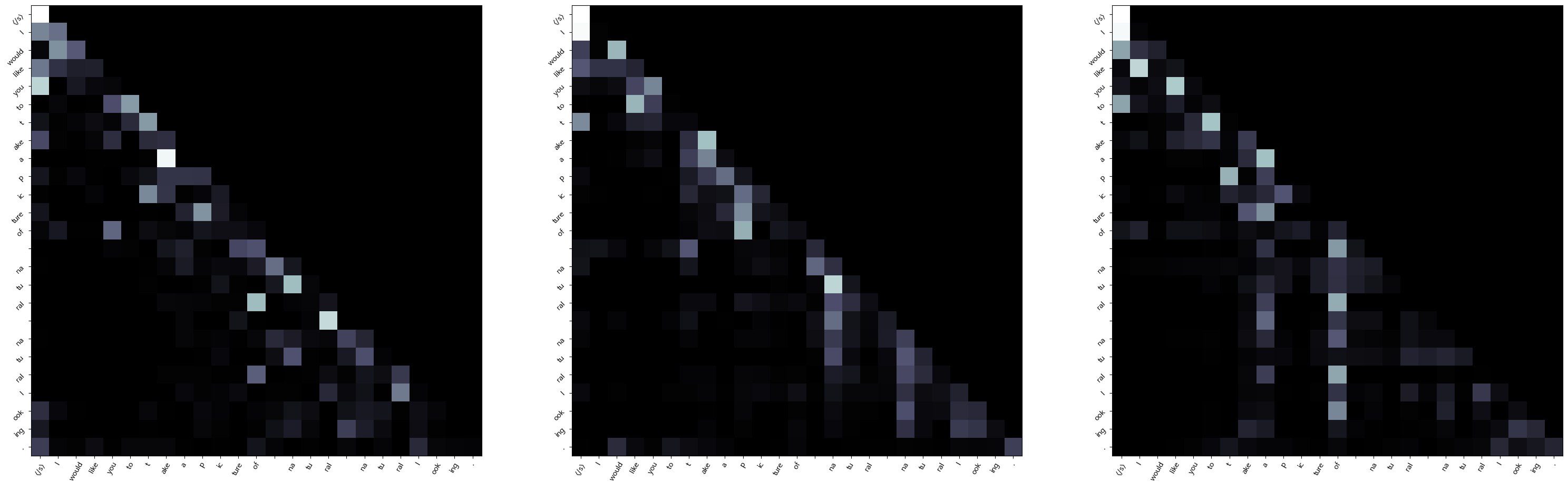
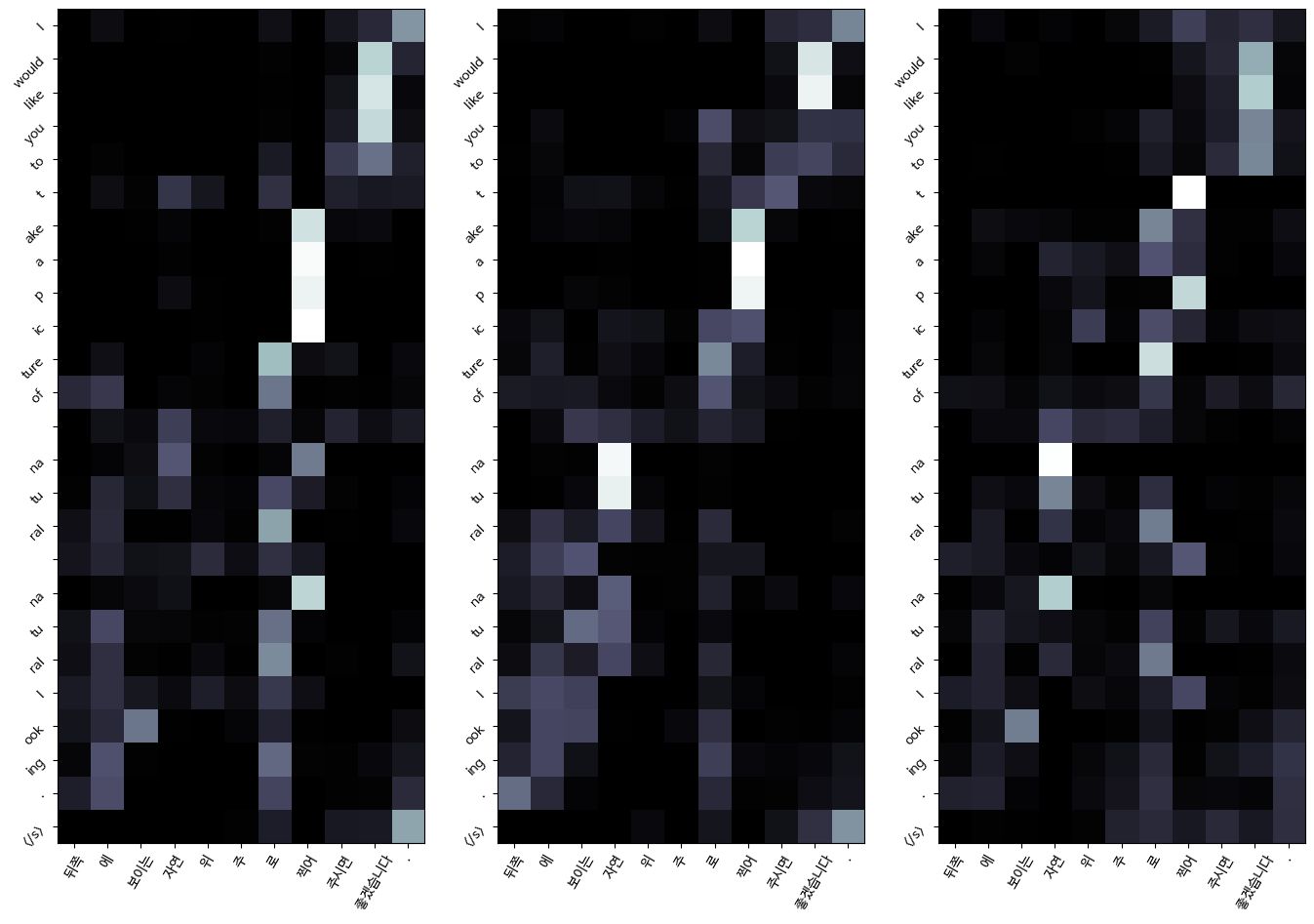
Attention 성능확인
왼쪽부터 오른쪽으로 layer 증가 (1, 2, 3번째 layer임)
흰색일수록 값이 큼
Encoder self-attention
Decoder self-attention
Encoder-Decoder self_attention
한국어와 영어의 어순이 반대가 되다보니 오른쪽 대각선 모양이 아니라 위쪽 대각선 모양인 것을 확인할 수 있다.
트랜스포머의 문제점 - 어텐션만으로는 충분하지 않을 수도 있음
트랜스포머는 모든 토큰이 이전 토큰을 참조할 수 있어, 컨텍스트가 커질수록 모델이 느려짐
기존의 트랜스포머의 병목 현상을 완화하는 기술들이 있지만, 근본적인 해결을 위해서는 다른 접근 방식이 필요함
