
1.✅ Introduction
VGGNet은 CNN 모델로 네트워크의 깊이가 모델이 좋은 성능을 보이는 데 중요한 역할을 한다는 것을 보여줬다. VGGNet의 필터 크기는 3x3, stride 1, 제로 패딩 1의 Conv 레이어로 이루어져 있으며, 필터 크기 2x2 (패딩 없음)의 Max-pool을 Pooling 레이어로 사용한다. ILSVRC 대회에서는 GoogLeNet 보다 이미지 분류 성능은 낮았지만, 다른 연구에서는 좋은 성능을 보인다. (논문의 Appendix에서 확인 가능) 최근에는 이미지 특징(feature)을 추출하는 데 이용되는 등 기본 네트워크 모델로 활용되고 있으며, 매우 많은 메모리를 이용하여 연산한다는 단점이 있다.
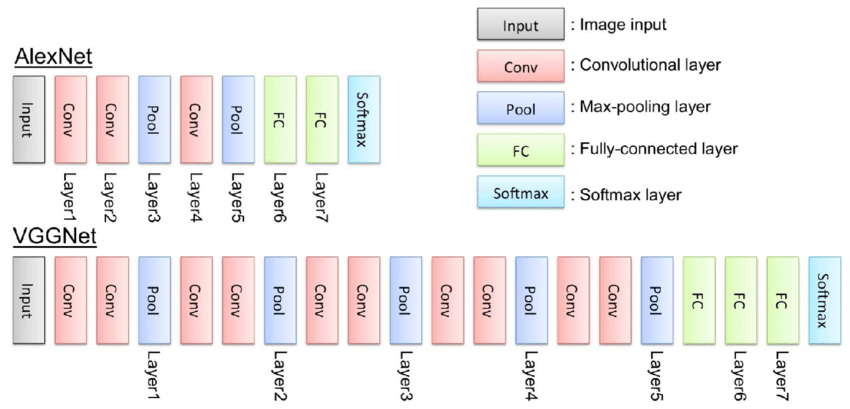
VGG 모델은 딥러닝기반 컴퓨터 비전 모델의 시대를 열었던 AlexNet의 8-layer보다 두배 이상 깊은 모델이다. 논문에서 VGG 모델이 16~19-layer의 깊은 신경망을 학습할 수 있었던 것은 모든 합성곱 레이어에서 3x3의 필터를 사용했기 때문이라고 말하고 있다.
2.✅ VGG-16 Architecture
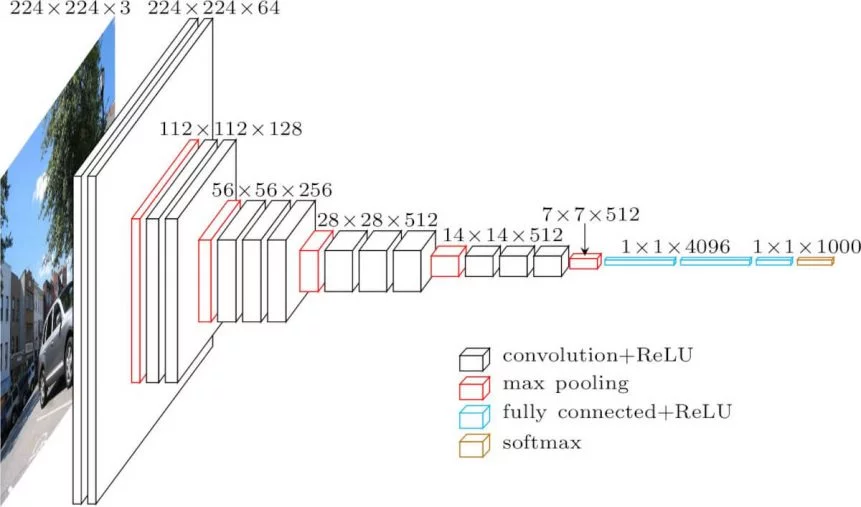
224x224의 컬러이미지가 들어와서 총 13개의 conv layer를 지나고 3개의 Fully connected Layer를 지난다.
놀라운 점은 Convolution layer가 훨씬 많음에도 불구하고 2000만개의 파라미터를 쓰는 것에 반해 FCN layer는 3개의 layer만 사용했음에도 불구하고 1억 2000만개의 파라미터를 사용했다는 것이다.
이를 통해 Convolution Neural Network가 정말 효율적으로 파라미터를 사용한다는 것을 알 수 있다.
이 논문에서는 각 CNN에 Padding=1, Stride=1을 사용하고 있고 2x2의 max pooling을 사용하고 있다.
✳ VGG-16 Architecture의 구성
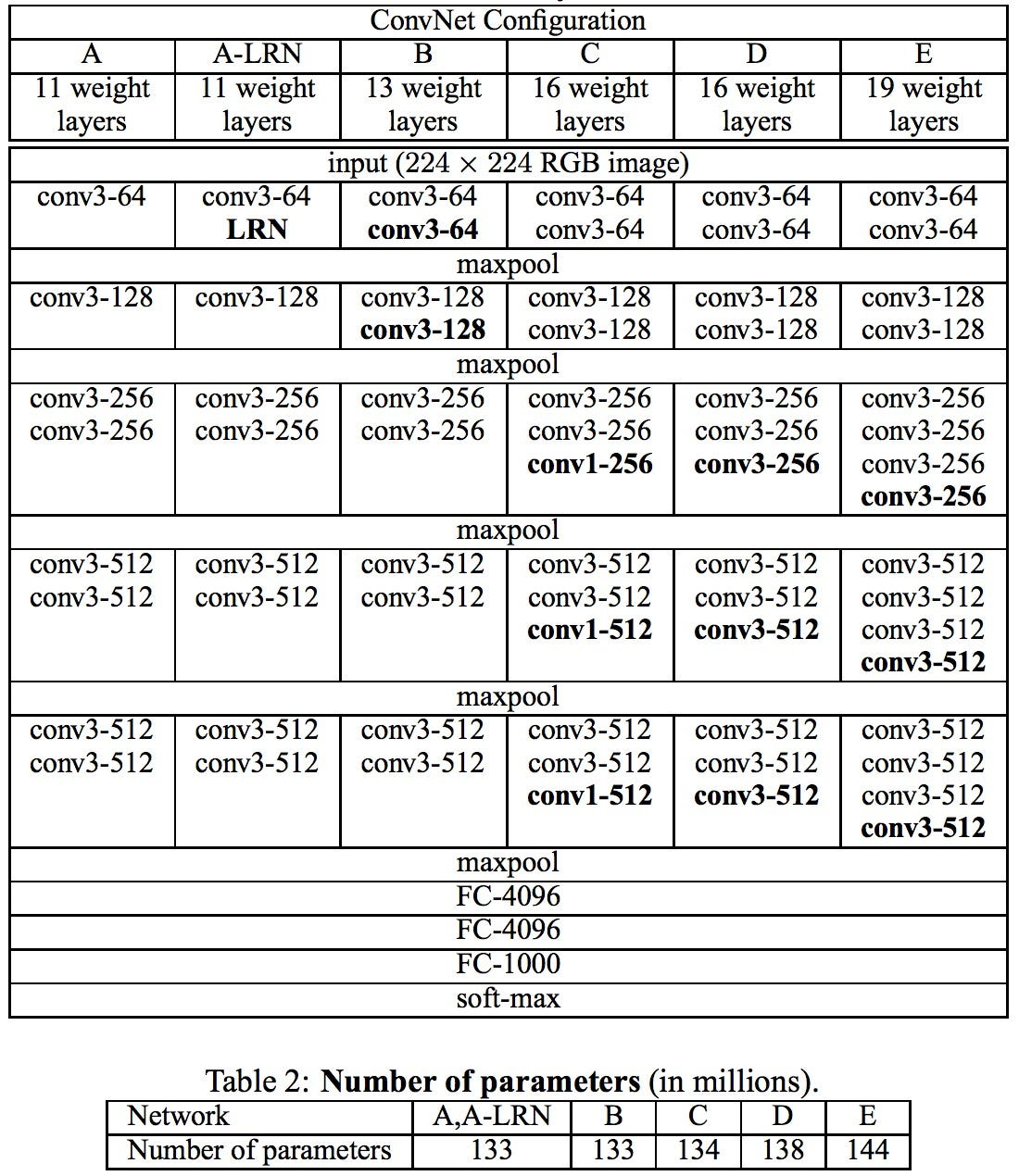
- 13 Convolution Layers + 3 Fully-connected Layers
- 3x3 convolution filters
- stride: 1 & padding: 1
- 2x2 max pooling (stride : 2)
- ReLU
Note
- 3x3 필터 사용
VGGNet 이전에 CNN을 사용해서 좋은 성과를 보였던 모델을 비교적 큰 Receptive Field를 갖는 11x11이나 7x7을 포함하지만 VGGNet은 3x3의 작은 필터만 사용했음에도 정확도를 비약적으로 개선시켰다.
Receptive Field?
Receptive Field란 이미지의 특정 영역이 모델의 특정 뉴런에 영향을 미치는 범위를 의미한다. 쉽게 말해 모델이 이미지의 어떤 부분을 보고 있는지를 나타냄.
CNN의 각 레이어는 이전 레이어의 특징 맵에서 일정 영역을 보고 새로운 특징을 추출하는데, 이때 입력 이미지에서 해당 영역까지 거슬러 올라가 봤을 때 어느 범위까지 관여하는지를 말하는 것을 Receptive Field 라고 한다.Receptive Field는 레이어가 깊어질수록 점차 넓어진다. 초기 레이어에서는 국소적인 저수준 특징(모서리, 색상 등)을 인식하지만, 레이어가 깊어질수록 더 넓은 영역에 걸친 고수준 특징(물체의 부분, 전체 모양 등)을 인식하게 된다. 이를 통해 CNN은 이미지의 계층적 특징 표현을 학습할 수 있다는 것이다.
- 3x3 필터를 왜 사용했을까?
영상에서 특정위치에 있는 픽셀들은 그 픽셀 주변에 있는 픽셀하고만 상관관계가 존재한다. 해당 픽셀에서 거리가 멀수록 관계가 낮아지는 특성이 있음.
-> 전체 영역에 동일한 중요도를 부여하는 것보다 관계가 있을만한 주변 픽셀에 중요도를 더 부여하는 것이 효과적이라고 생각하지 않았을까?
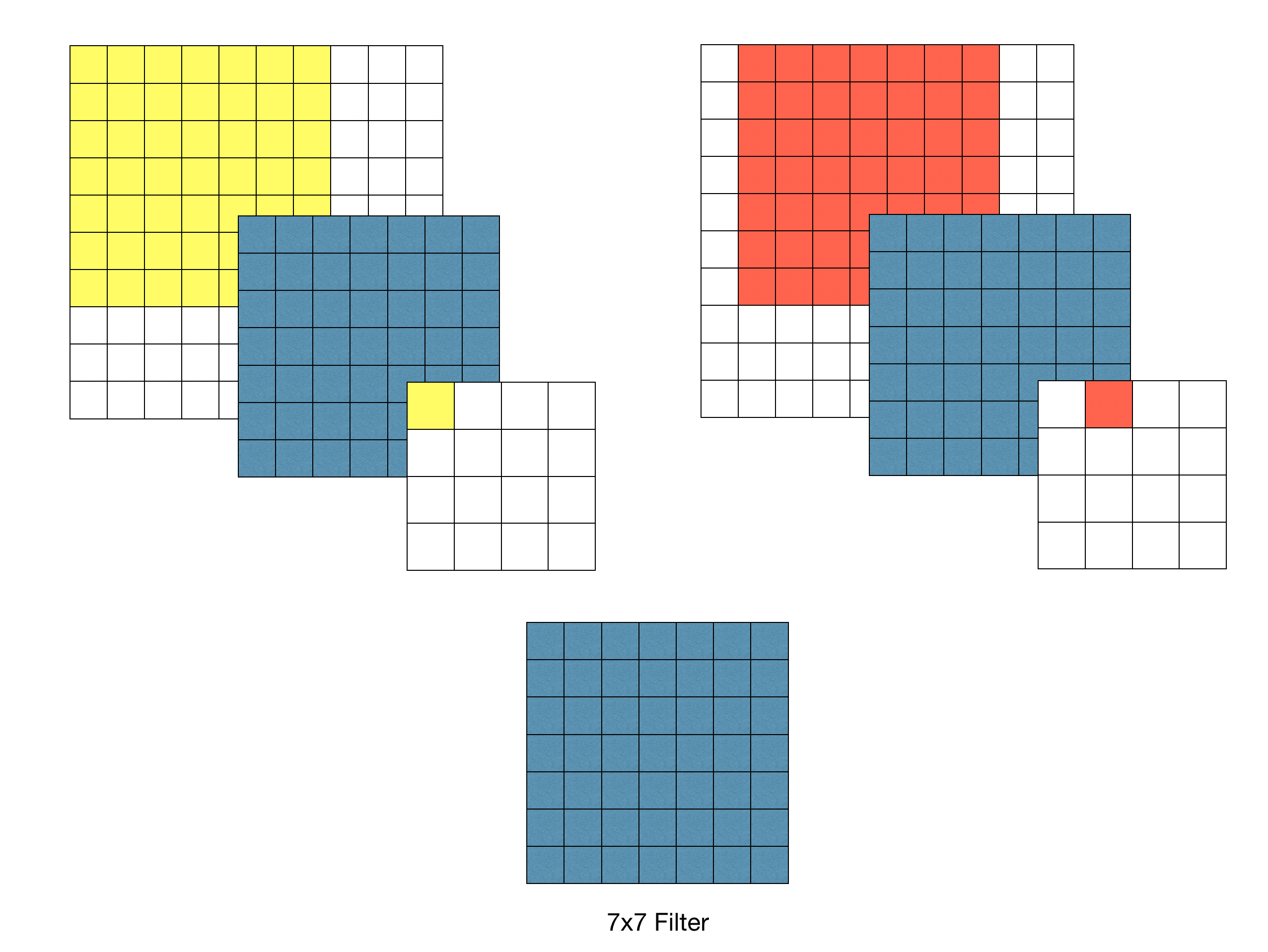
7x7 필터를 이용하여 Convolution 했을 경우 출력 특징 맵의 각 픽셀 당 Receptive Field는 7x7이다.
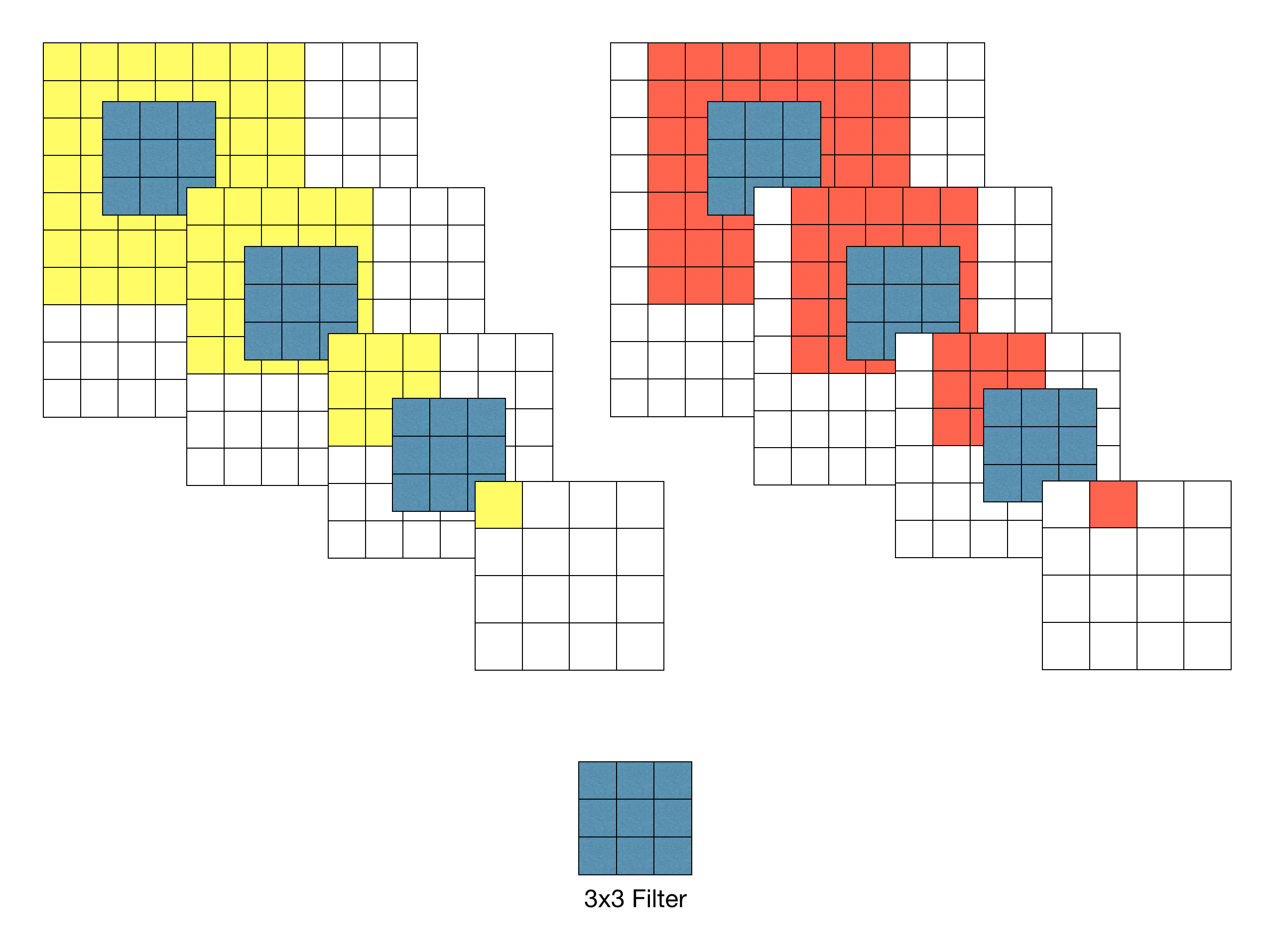
3x3필터를 이용할 경우 3-레이어 Convolution을 반복했을 때 원본 이미지의 7x7 영역을 수용할 수 있다.
- 3x3 필터를 사용해 얻는 효과
- 결정함수의 비선형성 증가
각 Convolution연산은 ReLU함수를 포함한다. -> 3x3은 7x7보다 ReLU함수를 2번 더 통과함 - Receptive Field 효율성
Stride가 1일 때, 3차례의 3x3 Conv 필터링을 반복한 특징맵은 한 픽셀이 원본 이미지의 7x7 Receptive field의 효과를 볼 수 있다. -> 학습 파라미터 수 감소(49 vs 9 x 3)
- 결정함수의 비선형성 증가
✅ Traing
AlexNet보다 더 깊고, 파라미터 수도 더 많지많 더 적은 epoch을 했다는 언급이 있다

❔why❔
-
implicit regularization
3x3 필터을 여러층 겹쳐서 사용하면 동일한 크기의 Reception Field를 가지는 필터보다 더 적은 파라미터로 학습이 가능하다. 더 적은 파라미터를 사용함으로써 불필요한 학습을 줄임 -> 과적합 방지
(설계방식 자체가 규제효과를 만들어냄.) -
pre-initialisation of certain layers
VGG A모델의 처음 4개의 Conv Layers 와 마지막 3개의 Fully connected layer의 가중치 값들로 다음 B,C,D,E 모델들을 구성할 때 사용함.
-> 가중치 초기값 설정은 모델 학습을 용이하게 도와줌.
가중치 초기화
딥러닝에서 신경망 가중치의 초기화는 학습 속도 및 안정성에 큰 영향을 줄 수 있기 때문에 어떤 방식으로 초기화할 것인지는 중요한 문제 중 하나이다. VGG 연구팀은 이러한 문제를 보완하고자 다음과 같은 전략을 세웠다.
- 상대적으로 얕은 11-Layer 네트워크를 우선적으로 학습한다. 이 때, 가중치는 정규분포를 따르도록 임의의 값으로 초기화한다.
- 어느 정도 학습이 완료되면 입력층 부분의 4개 층과 마지막 3개의 fully-connected layer의 weight를 학습할 네트워크의 초기값으로 사용한다.
🔰 원문에서는 학습 시 다음과 같은 최적화 알고리즘을 사용하였다
Optimizing multinomial logistic regression
mini-batch gradient descent
Momentum(0.9)
Weight Decay(L2 Norm)
Dropout(0.5)
Learning rate 0.01로 초기화 후 서서히 줄임
학습 이미지 크기
모델 학습(Training) 시 입력 이미지의 크기는 모두 224x224로 고정하였다.
학습 이미지는 각 이미지에 대해 256x256~512x512 내에서 임의의 크기로 변환하고, 크기가 변환된 이미지에서 개체(Object)의 일부가 포함된 224x224 이미지를 Crop하여 사용하였다.

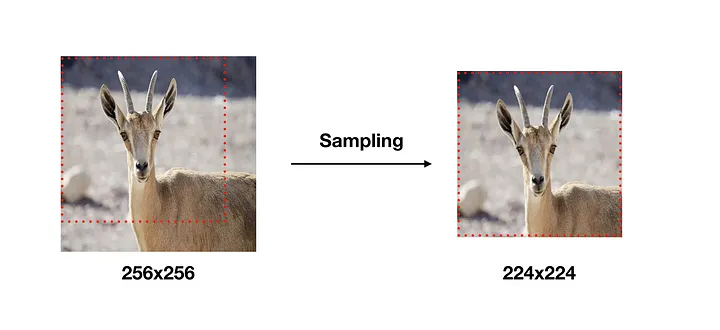


이미지를 256x256 크기로 변환 후 224x224 크기를 샘플링한 경우
이미지를 512x512 크기로 변환후 224x224 크기를 샘플링한 경우
이처럼 학습 데이터를 다양한 크기로 변환하고 그 중 일부분을 샘플링해 사용함으로써 몇 가지 효과를 얻을 수 있다.
한정적인 데이터의 수를 늘릴 수 있다. — Data augmentation
하나의 오브젝트에 대한 다양한 측면을 학습 시 반영시킬 수 있다. 변환된 이미지가 작을수록 개체의 전체적인 측면을 학습할 수 있고, 변환된 이미지가 클수록 개체의 특정한 부분을 학습에 반영할 수 있다.
두 가지 모두 Overfitting을 방지하는 데 도움이 된다.
실제로 VGG 연구팀의 실험 결과에 따르면 다양한 스케일로 변환한 이미지에서 샘플링하여 학습 데이터로 사용한 경우가 단일 스케일 이미지에서 샘플링한 경우보다 분류 정확도가 좋았다.
Fully-convolutional Nets
Training 완료된 모델을 테스팅할 때는 신경망의 마지막 3 Fully-Connected layers를 Convolutional layers로 변환하여 사용하였다.
첫 번째 Fully-Connected layer는 7x7 Conv로, 마지막 두 Fully-Connected layer는 1x1 Conv로 변환하였다. 이런식으로 변환된 신경망을 Fully-Convolutional Networks라 부른다.
신경망이 Convolution 레이어로만 구성될 경우 입력 이미지의 크기 제약이 없어진다. 이에 따라 하나의 입력 이미지를 다양한 스케일로 사용한 결과들을 앙상블하여 이미지 분류 정확도를 개선하는 것도 가능해진다.
