1. BS4를 이용해 HTML에서 데이터 뽑기
- BeautifulSoup : 웹 스크래핑 및 페이지 파싱을 수행하는 데 사용되는 도구이다.
from bs4 import BeautifulSoup- BeautifulSoup() : 객체를 생성하는 함수이다. 첫 번째 매개변수로 파싱하려는 HTML, XML 문서의 문자열 또는 경로를 넣고, 두 번째 매개변수는 파서를 지정한다.
아래 코드에서 두 번째 매개변수인 html-parser 는 가장 빠르고 안정적인 HTML 파서이다.
f = open("file_path", encoding = 'UTF-8')
text = BeautifulSoup(f.read(), 'html-parser')- find() : 결과가 한 개인 경우 (여러 개가 존재해도 결과는 1개만 반환한다.)
h1 = text.find('h1')
h2 = text.find('h2')- find_all() : 결과가 여러 개인 경우 (리스트 형태로 결과를 반환한다.)
#ul > li 에 해당하는 모든 li를 출력한다.
ul = text.find('ul')
lis = ul.find_all('li')
for l in lis:
print(l.text)- 만약, find('ul')을 거치지 않고 곧바로 find_all('li')를 실행한다면, HTML 코드 내에 있는 모든 li가 출력이 된다.
lis = text.find_all('li')
for l in lis:
print(l.text)2. 네이버 금융 크롤링
1) 주가
div_today = bs.find("div", {"class" : "today"})
em = div_today.find("em")
today_price = em.find("span", {"class":"blind"}).text
2) 회사 이름
h_company = bs.find("div", {"class":"h_company"})
name = h_company.find("a").text
3) 회사 코드
div_description = h_company.find("div", {"class":"description"})
code = div_description.find("span").text
4) 거래량
table_no_info = bs.find("table", {"class":"no_info"})
tds = table_no_info.find("tr").find_all("td")
volume = tds[2].find("span", {"class":"blind"}).text5) 함수화
def crawl(code):
url = f"https://finance.naver.com/item/main.naver?code={code}"
res = requests.get(url)
bs = BeautifulSoup(res.text, 'html.parser')
div_today = bs.find("div", {"class" : "today"})
em = div_today.find("em")
today_price = em.find("span", {"class":"blind"}).text
h_company = bs.find("div", {"class":"h_company"})
name = h_company.find("a").text
div_description = h_company.find("div", {"class":"description"})
code = div_description.span
table_no_info = bs.find("table", {"class":"no_info"})
tds = table_no_info.find("tr").find_all("td")
volume = tds[2].find("span", {"class":"blind"}).text
dic = {"price": today_price, "name": name, "code":code, "volume":volume}
return dic
6) 예시
- 삼성전자의 code "005930"를 crawl()함수에 넣어보면 다음과 같이 결과가 나온다.
samsung = crawl('005930')
print(samsung)
{'price': '69,700', 'name': '삼성전자', 'code': <span class="code">005930</span>, 'volume': '7,003,670'}3. 크롤링 데이터 엑셀 저장
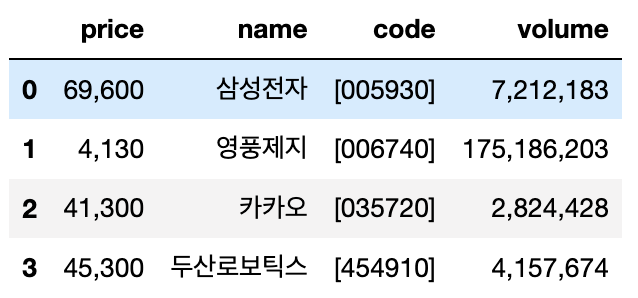
for문을 사용하여 여러 종목에 대한 결과값을 dataframe으로 저장 후 엑셀로 저장한다.
import pandas as pd
import openpyxl
codes = ["005930", "006740", "035720", "454910"]
result = [crawl(code) for code in codes]
df = pd.DataFrame(result)
df.to_excel("prices.xlsx")위 코드를 실행하면 다음과 같이 데이터프레임 result가 엑셀(맥북의 경우 numbers)에 저장된다.