웹 크롤링
1.[웹 크롤링] 크롤링 개요
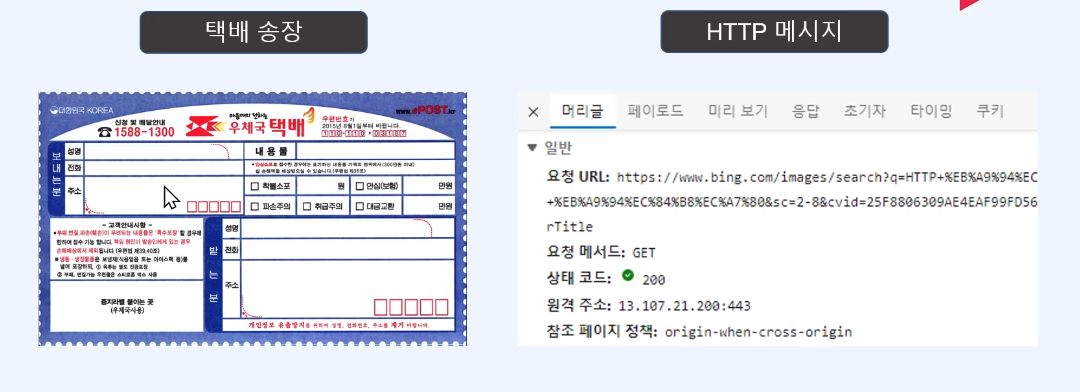
1) 크롤링이란 데이터를 불러 오는 것 2) 파싱이란 불러온 데이터에서 필요한 정보를 뽑아내는 것3) 스크래핑이란 데이터를 수집하는 모든 작업이며 크롤링보다 큰 범위의 용어이다. 1) 직접 데이터를 뽑는 방법 장점: 원하는 대로 데이터 가공 가능 단점: 데이터를 직접
2.[웹 크롤링] 네이버 금융 크롤링
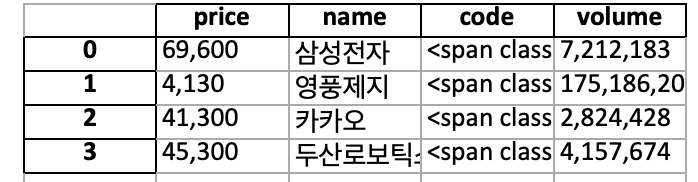
BeautifulSoup : 웹 스크래핑 및 페이지 파싱을 수행하는 데 사용되는 도구이다. BeautifulSoup() : 객체를 생성하는 함수이다. 첫 번째 매개변수로 파싱하려는 HTML, XML 문서의 문자열 또는 경로를 넣고, 두 번째 매개변수는 파서를 지정한다
3.[웹 크롤링] 인스타그램 좋아요, 댓글 달기
1. Selenium 이란 Selenium은 웹 어플리케이션 테스트를 위한 포터블 프레임 워크이다. Requests는 비교적 호출이 쉽지만, 안되는 경우가 많다. 반면, Selenium은 사람이 화면에서 작동하듯이 쓸 수 있으며 비교적 어렵지만 Requests가 못
4.[웹 크롤링] Pixabay 이미지 수집하기

이미지를 다운로드하는 과정은 다음과 같다. 이미지 검색 -> 이미지 URL 수집 -> URL에 이미지 요청 -> 이미지 다운로드
5.[웹 크롤링] 네이버 API 활용 (1) 검색
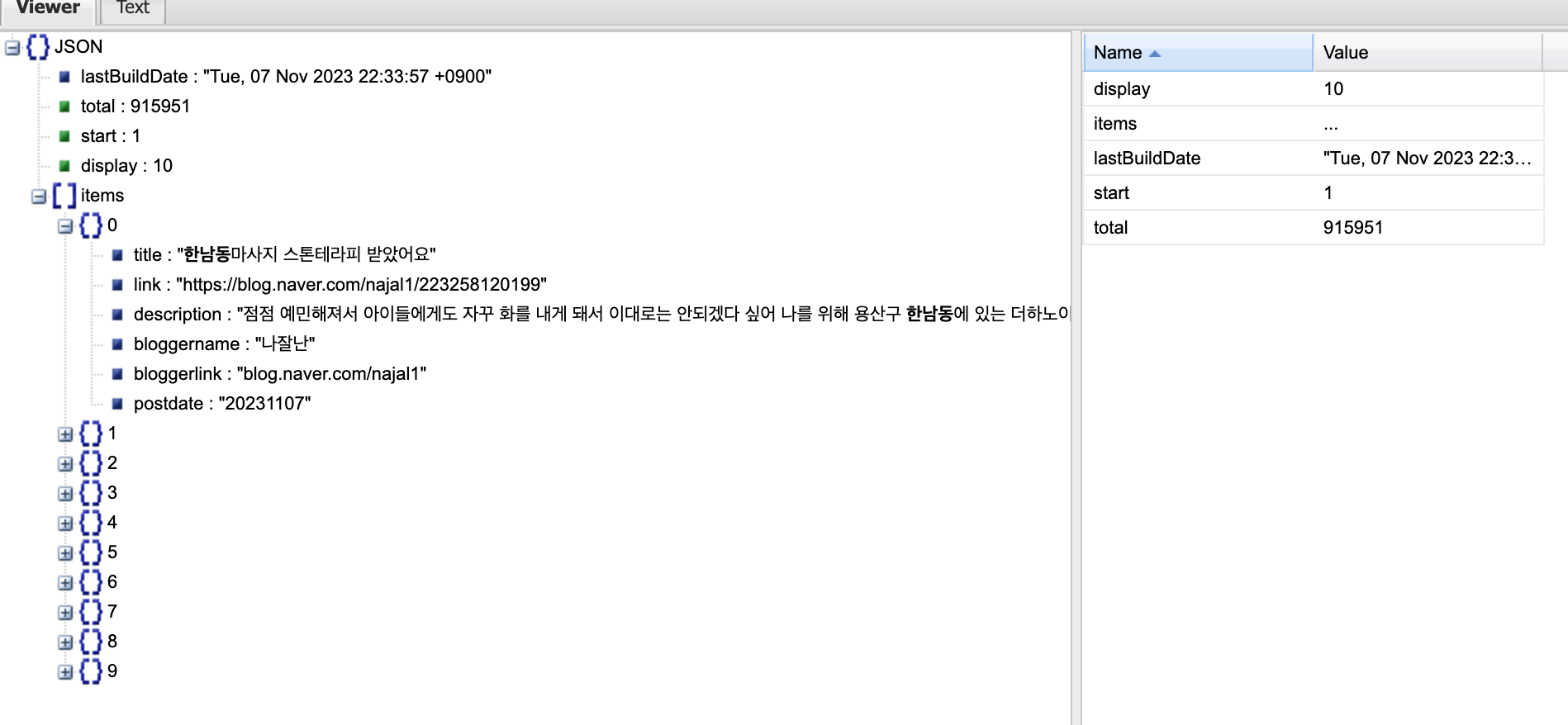
1. API란 API(Application Programming Interface)란 기업에서 데이터를 제공하거나 변경할 수 있도록 열어놓은 창구라고 생각하면 된다. API를 이용하기 위해 사용 신청을 받고, key를 발급받아야 한다. 대체로는 자동으로 발급해주지만
6.[웹 크롤링] 네이버 API 활용 (2) 데이터랩(쇼핑인사이트)
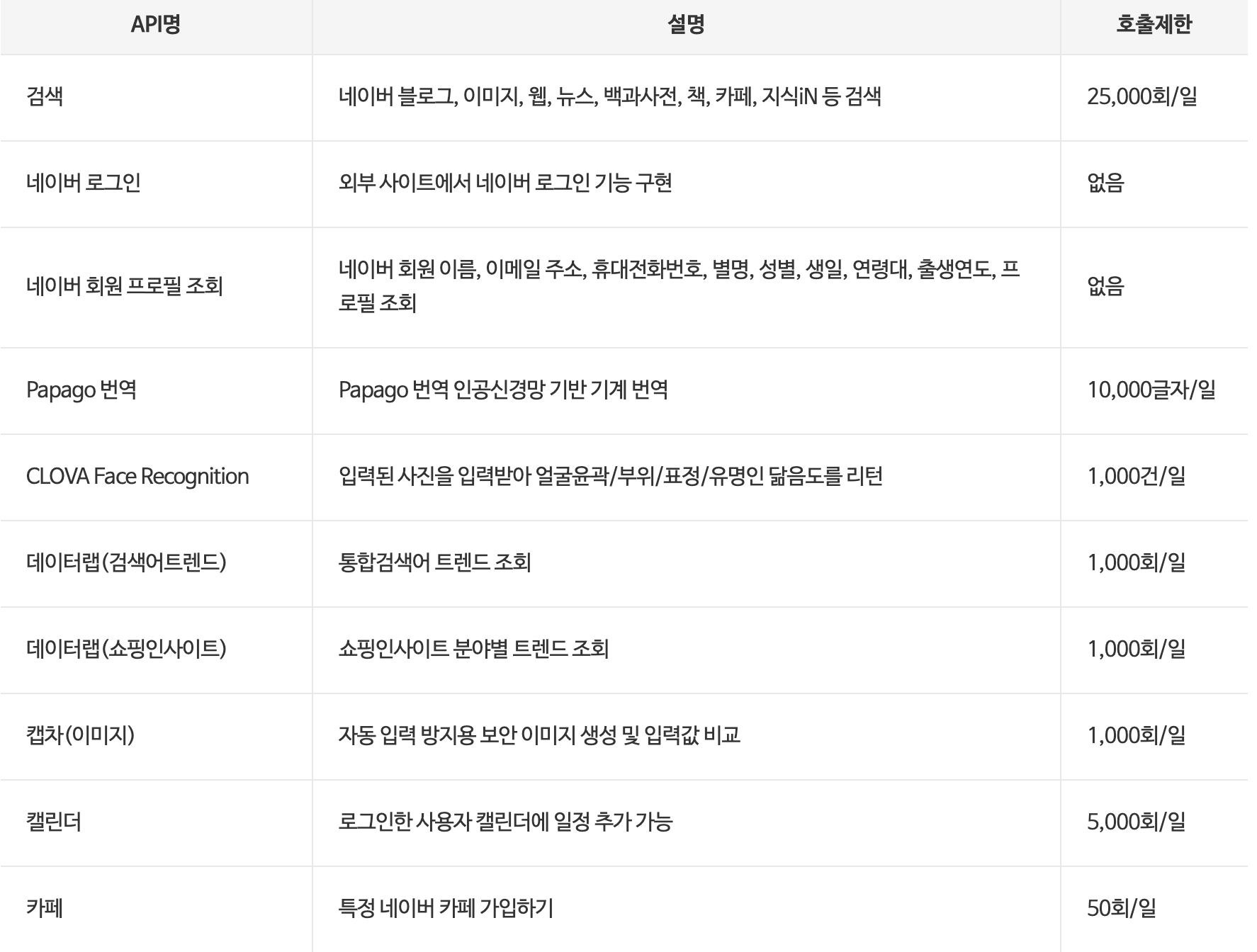
네이버 오픈 API는 파파고, 검색 등 다양한 기능을 제공한다. 이번에는 네이버 쇼핑 데이터를 수집하기 위해 데이터랩(쇼핑인사이트) API를 사용해보려고 한다. (API 신청은 링크 참조)신청을 마치면 "내 애플리케이션" 에서 위 사진과 같이 client_id, sec