1. API란
API(Application Programming Interface)란 기업에서 데이터를 제공하거나 변경할 수 있도록 열어놓은 창구라고 생각하면 된다.
API를 이용하기 위해 사용 신청을 받고, key를 발급받아야 한다. 대체로는 자동으로 발급해주지만, 간혹 수동 발급인 API도 있다.
API key 없이 요청을 하게 되면 not authouralized error가 뜨기 때문에 key를 받아야 한다.
2. 네이버 API 사용 신청하기
네이버 API key를 받기 위해 다음과 같은 과정을 거쳐야 한다.
네이버 개발자 센터에 들어가서, APPlication - 내 Application 등록을 누르면 로그인 후 Application 등록을 할 수 있다.
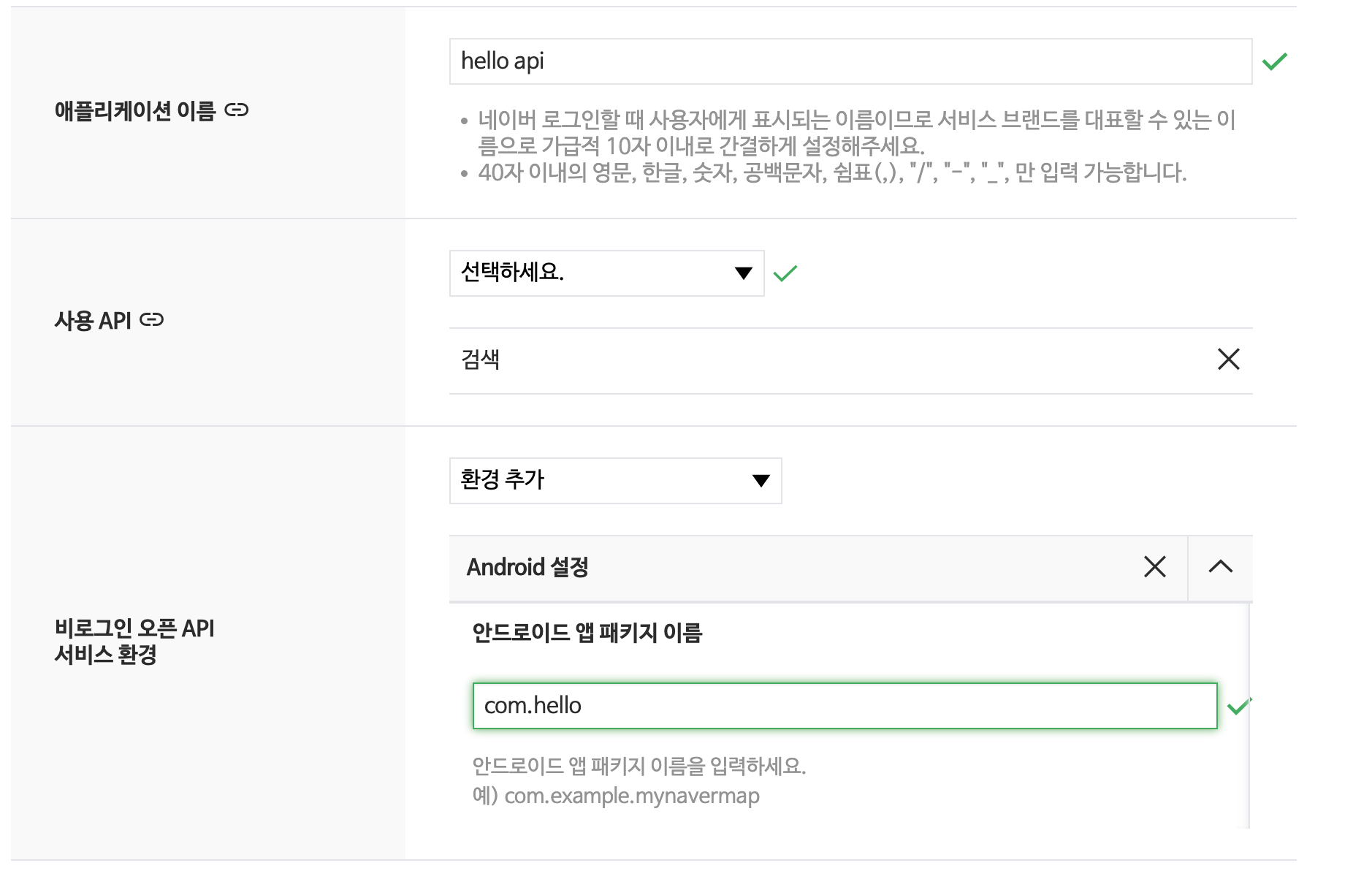
아래와 같이 나는 hello api라는 이름으로 애플리케이션을 등록했다.
API 사용 범위는 꽤나 다양했는데 일단 검색 기능만 추가했다.
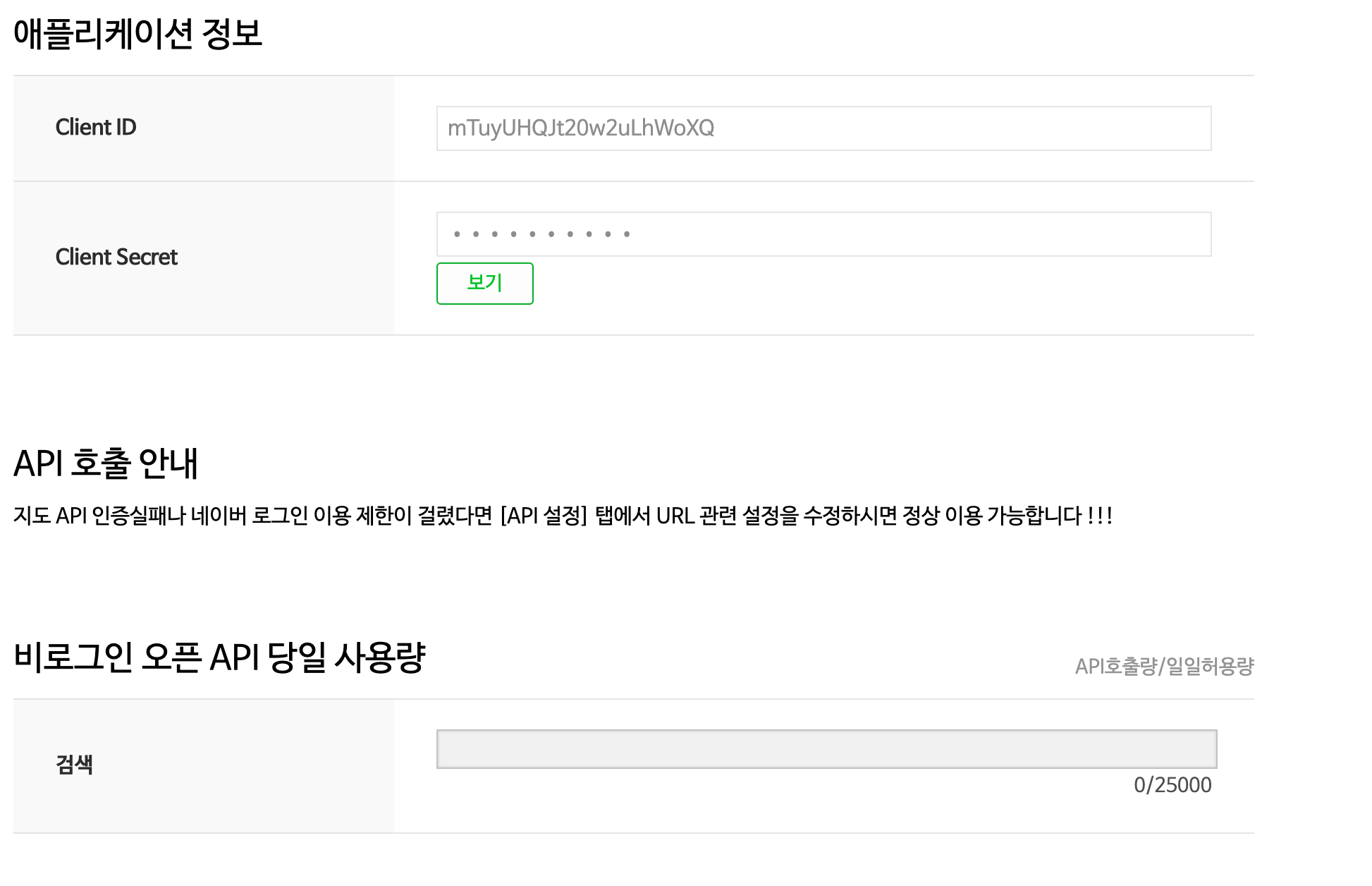
애플리케이션 등록 후 client id, secret이 주어진다.
주의해야 할 점은 네이버 API의 무료 일일 사용량은 25000인 것이다.
3. API 문서 살펴보기
- 검색 API 구현 예제
import os
import sys
import urllib.request
client_id = "YOUR_CLIENT_ID"
client_secret = "YOUR_CLIENT_SECRET"
encText = urllib.parse.quote("검색할 단어")
url = "https://openapi.naver.com/v1/search/blog?query=" + encText # JSON 결과
# url = "https://openapi.naver.com/v1/search/blog.xml?query=" + encText # XML 결과
request = urllib.request.Request(url)
request.add_header("X-Naver-Client-Id",client_id)
request.add_header("X-Naver-Client-Secret",client_secret)
response = urllib.request.urlopen(request)
rescode = response.getcode()
if(rescode==200):
response_body = response.read()
print(response_body.decode('utf-8'))
else:
print("Error Code:" + rescode)- 요청 URL

- 요청 변수
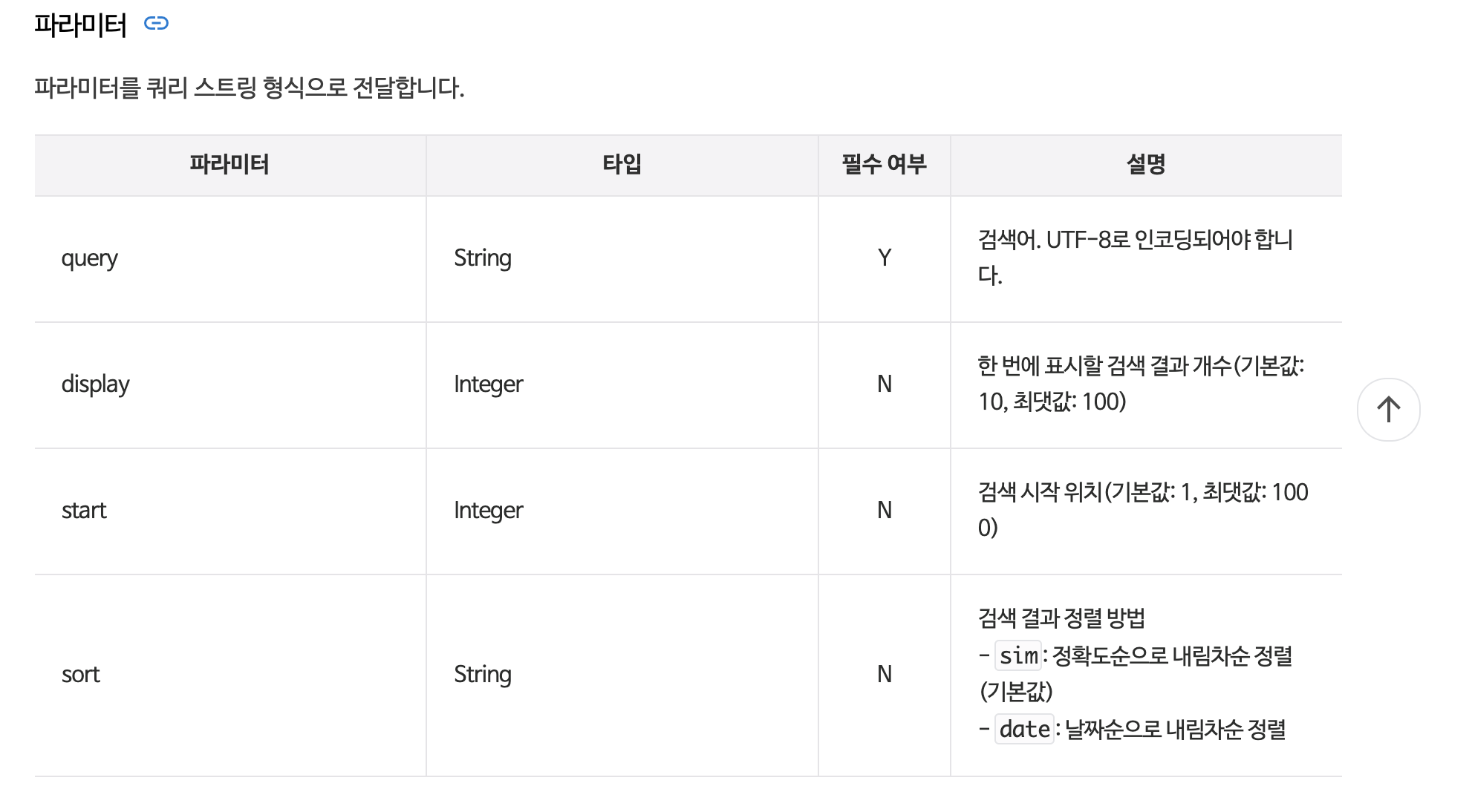
4. API 호출하기
1) requests.get() : requests 라이브러리를 사용하여 지정된 url에 GET 요청을 보낸다. 따라서 네이버 검색 API에 요청을 보내고, 요청 시에 headers를 함께 전송하여 인증된 클라이언트 정봉니 cliend_id, client_secret을 제공한다.
client_id = ""
client_secret = ""
import os
import sys
import urllib.request
import requests
url = "https://openapi.naver.com/v1/search/blog?query=한남동"
res = requests.get(url, headers = {
"X-Naver-Client-Id" : client_id,
"X-Naver-Client-Secret" : client_secret
} )
5. 응답 결과 확인하기
json() 함수를 통해 요청에 대한 응답인 res를 JSON 형식으로 파싱한다.
JSON 형식으로 저장된 result 변수에는 블로그 검색 결과에 관한 정보가 딕셔너리 형태로 담겨있다.
result를 확인해보면 다음과 같이 구성되어있다.
result = res.json()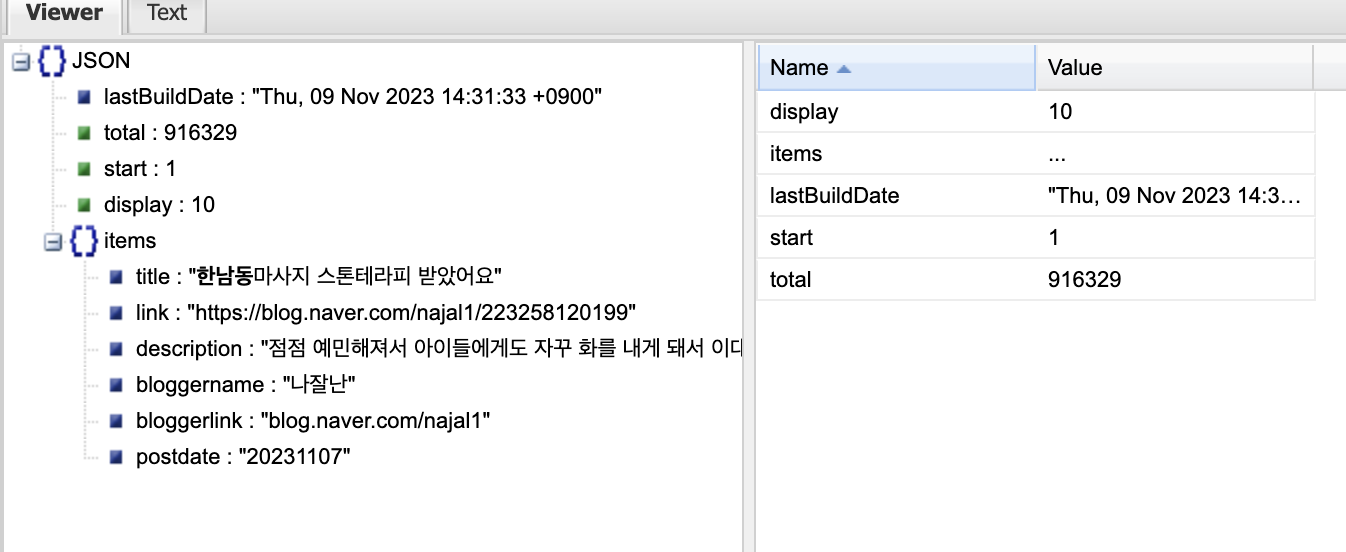
응답에 성공하면 결괏값을 JSON 형식의 결괏값이 반환되고 형태는 다음과 같아야 한다.
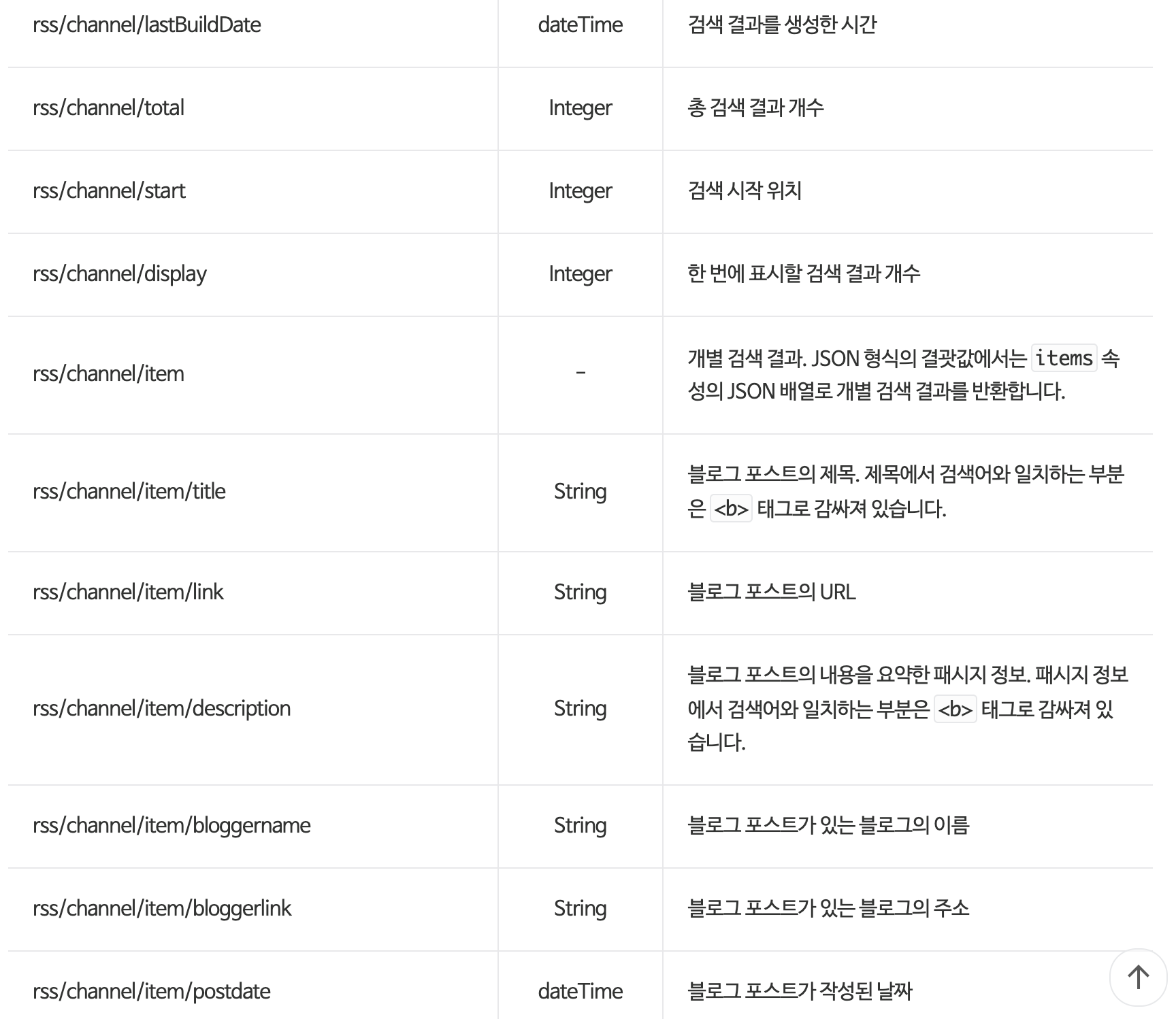
따라서 result가 잘 반환되었음을 확인할 수 있다.
또한 JSON 객체의 특정 필드(키 값)를 사용하여 원하는 정보를 추출할 수 있다 .
아래 코드는 각각 'total'와 'items' 필드의 값에 접근한다. 코드를 실행하면 각 해당 값을 반환받을 수 있다.
docs에 따르면 'total' 필드 값은 "총 검색 결과 개수" 이고, 'items'는 개별 검색 결과이다.
아래 코드 실행 결과는 "916329"이므로 "한남동"을 검색한 결과의 수가 916329라는 것을 알 수 있다.
result['total']
아래 코드 실행 결과는 10개의 개별 검색 결과를 dict 형태로 반환한다.
result['items']
[{'title': '<b>한남동</b>마사지 스톤테라피 받았어요',
'link': 'https://blog.naver.com/najal1/223258120199',
'description': '점점 예민해져서 아이들에게도 자꾸 화를 내게 돼서 이대로는 안되겠다 싶어 나를 위해 용산구 <b>한남동</b>에 있는 더하노이풋앤바디에 스톤테라피 받으러 다녀왔어요. 제가 다녀온 <b>한남동</b>마사지 숍... ',
'bloggername': '나잘난',
'bloggerlink': 'blog.naver.com/najal1',
'postdate': '20231107'},
{'title': "<b>한남동</b> 호주 브런치 아침 일찍 오픈하는 ' 써머레인 '",
'link': 'https://blog.naver.com/kikiao12/223253279049',
'description': '검색, <b>한남동</b> 브런치 써머레인은 오픈시간이 다른곳보다 조금 이른 오전 7시 30분이였기에 아침을 먹으러 가보았어요, <b>한남동</b> 브런치 써머레인은 한강진역 1번 출구에서 도보로 약 7~8분 거리에 위치해있어요... ',
'bloggername': '츠리의 맛집여행♪',
'bloggerlink': 'blog.naver.com/kikiao12',
'postdate': '20231102'},
{'title': '<b>한남동</b> 고기집 현주엽 방문 찐 맛집 녹다 리뷰',
'link': 'https://blog.naver.com/sia855/223234799971',
'description': '== 친구들이랑 약속이 있어서 간만에 <b>한남동</b>에서 모였어요! <b>한남동</b>에 맛집이 굉장히 많지만 얼마전에 봤던 유튜브가 생각나서 찾아보니까 현주엽님이 다녀간 고기집이 바로 근처에 있더라구요. 그래서 가게된... ',
'bloggername': '행복한 시야의 블로그',
'bloggerlink': 'blog.naver.com/sia855',
'postdate': '20231012'},
{'title': '서울 와인바 <b>한남동</b> 핫플 데이트 빠니에 리슈 러시안잭... ',
'link': 'https://blog.naver.com/fromrei8/223258274233',
'description': "서울 와인바 데이트 <b>한남동</b> 핫플 빠니에 리슈 지난 8월 오픈한 서울 <b>한남동</b> 와인바 '빠니에 리슈(Panier Lichoux)'에 다녀왔다. 가기로 해놓고 자꾸 그 이름을 헷갈렸는데.. 불어로 '맛있는 것들로 가득한 바구니... ",
'bloggername': '프롬레이의 여행잡화점',
'bloggerlink': 'blog.naver.com/fromrei8',
'postdate': '20231107'},
{'title': '<b>한남동</b> 와인바 빠니에 리슈 러시안 잭 소비뇽 블랑 즐겨볼 수... ',
'link': 'https://blog.naver.com/nowwegom/223257915939',
'description': '퇴근 후에 친구와 만나기로 한 날, 이왕이면 분위기 좋은 <b>한남동</b> 와인바에 가고 싶어서 추천 받았었던... 빠니에 리슈 2층으로 올라가보면 <b>한남동</b> 와인바가 있는데 센스 있게 꾸며놔서 입장할 때부터 기분이... ',
'bloggername': '먹기 위해 사는 위장 환자',
'bloggerlink': 'blog.naver.com/nowwegom',
'postdate': '20231107'},
{'title': '[<b>한남동</b> 맛집] 깔끔한 점심식사는 <b>한남동</b> 한정식 코스요리... ',
'link': 'https://blog.naver.com/khyrt/223253882885',
'description': '오랜만에 시간내서 같이 <b>한남동</b> 맛집에 가보기로 했어요! 어머니 모시고 가야하니까 깔끔한 비주얼에 <b>한남동</b> 맛집이 어디 있나 폭풍서치를 했는데요. <b>한남동</b> 한정식 코스요리가 나오는 알아차림으로 예약을... ',
'bloggername': 'Love your life♥',
'bloggerlink': 'blog.naver.com/khyrt',
'postdate': '20231102'},
{'title': '<b>한남동</b>단발 미용실 도영 디자이너 쌤',
'link': 'https://blog.naver.com/todays_lora/223249763905',
'description': '좀 길어진 머리 정돈하러 <b>한남동</b>단발 미용실 리느 한남이라는 곳에 다녀왔어요 예전에 차*에서 만났던 쌤이 <b>한남동</b> 미용실로 가셨다고 해서 오랜만에 만나서 머리 단발 커트(손질) 하고 부스스해진 머리카락을... ',
'bloggername': '여행 좋아하는 한량 주부',
'bloggerlink': 'blog.naver.com/todays_lora',
'postdate': '20231029'},
{'title': '<b>한남동</b> 월세 소형 고급주택 입주 안내',
'link': 'https://blog.naver.com/l88my/223239920621',
'description': '<b>한남동</b> 월세 소형 고급주택 입주 안내 <b>한남동</b> 월세 기록 제조기, 최고가 아파트 등의 다채로운 명품 수식어를 갖추고 상위 0.1%분을 모시는 이곳 <b>한남동</b> 월세 더힐 소식인데요, 해당 단지는 부촌 내 희소한... ',
'bloggername': 'RODENHOUSE_Dosan-daero',
'bloggerlink': 'blog.naver.com/l88my',
'postdate': '20231018'},
{'title': '[용산] <b>한남동</b> 고기집 네모집 한남점에서 숙성 돈마호크... ',
'link': 'https://blog.naver.com/kkl430/223255752359',
'description': '제로페이 <b>한남동</b>에 있는 숙성한우 전문점 네모집에 방문해봤어요 https://app.catchtable.co.kr/ct/shop/Hannam... 부른데 <b>한남동</b> 고기집 네모집의 식사류도 궁금해서 주문해봤어요 한우차돌된장찌개 맛없을수가 없는... ',
'bloggername': 'Leemy',
'bloggerlink': 'blog.naver.com/kkl430',
'postdate': '20231106'},
{'title': '<b>한남동</b> 더힐 65평 전세',
'link': 'https://blog.naver.com/dntjq8977/223242046855',
'description': '<b>한남동</b> 더힐 65평 전세 안녕하세요. 뒤로는 매봉산과 남산이 버티고 있으며 앞으로 한강이 흐르고 있는... 소재지 : 서울시 용산구 <b>한남동</b> 810 면적 : 공급면적 215.25㎡ 전용면적 173.82㎡ 가격 : 전세 50억... ',
'bloggername': 'hampton korea',
'bloggerlink': 'blog.naver.com/dntjq8977',
'postdate': '20231020'}]참고) Json Tree
Json tree 에 넣으면 가독성을 높힐 수 있다.
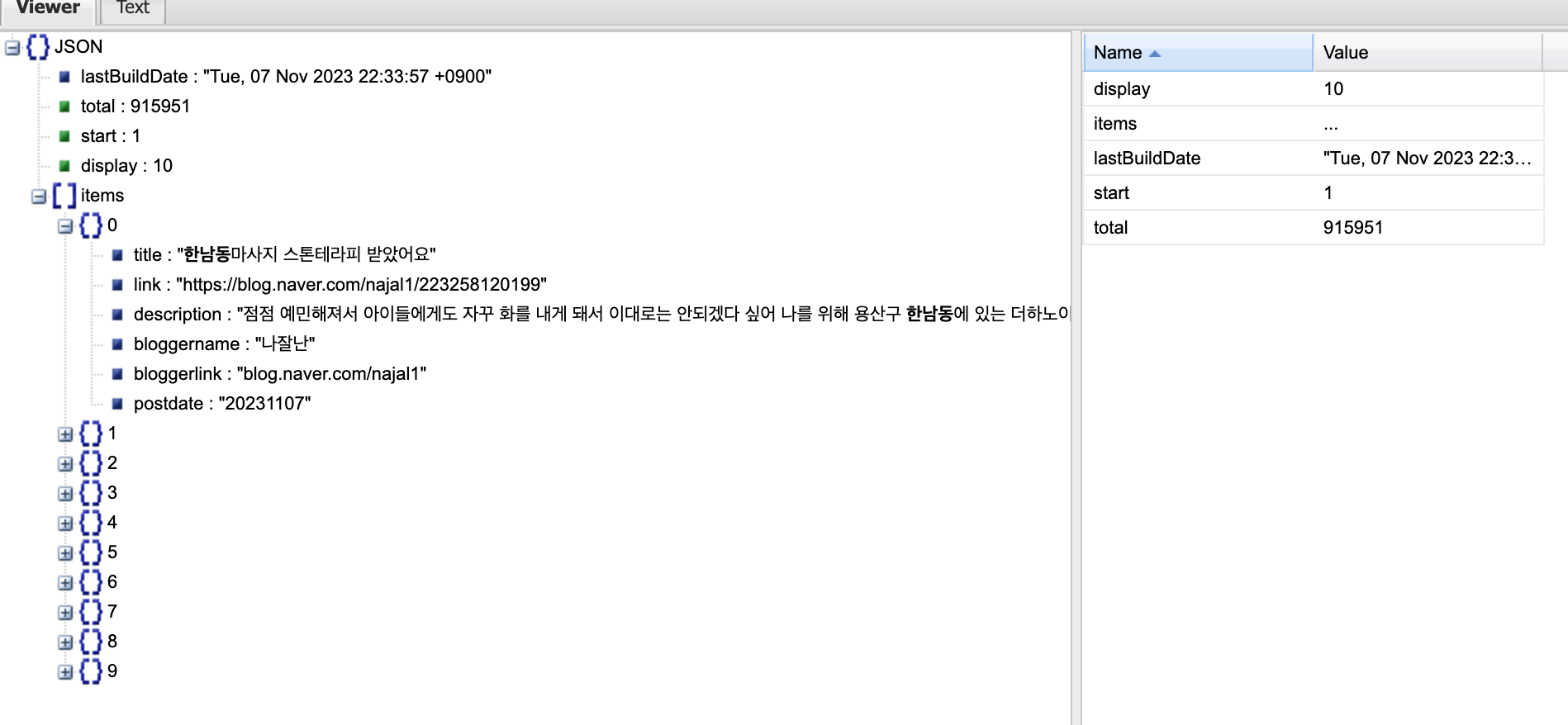
6. parameter
1) display

아래 코드의 결과 값은 10이다. 네이버 API의 파라미터로 n을 따로 설정해주지 않으면 default 값이 10으로 지정되어있기 때문이다.
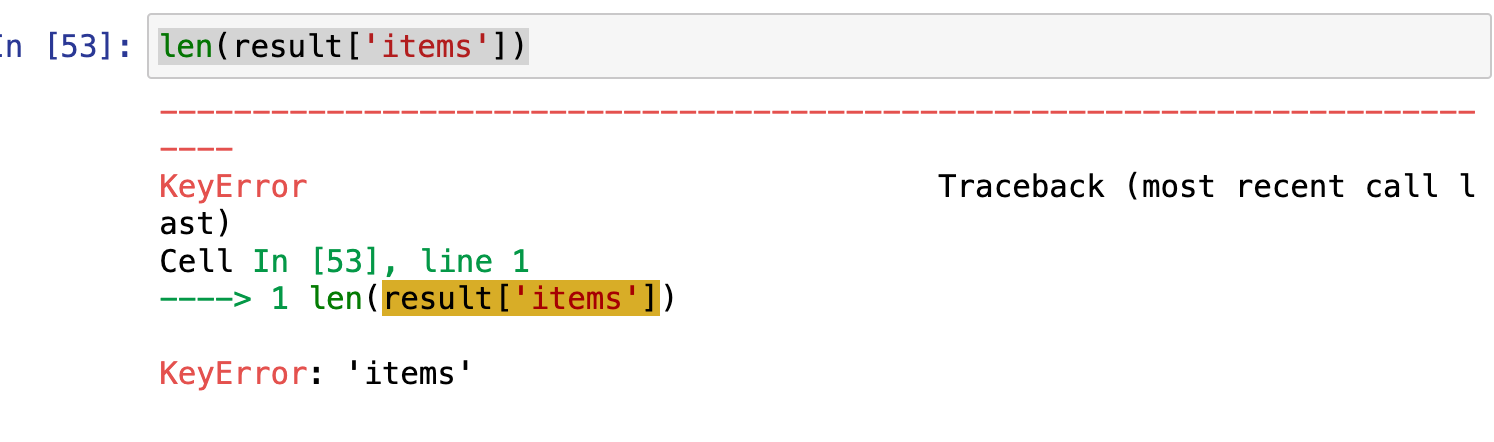
len(result['items'])최대 100건을 호출할 수 있으며 한 번에 최댓값들을 반환받기 위해 url에 display 인자를 추가할 것이다.
아래 코드의 결과 값은 100으로 나오게 된다.
url = "https://openapi.naver.com/v1/search/blog.json?query=한남동&display=100"
res = requests.get(url, headers = {
"X-Naver-Client-Id" : client_id,
"X-Naver-Client-Secret" : client_secret
} )
result = res.json()
len(result['items'])만약 100이 넘는 수를 인자로 넣는다면, keyerror가 뜨게 된다.
2)start

start 인자를 101으로 설정해주면, 101부터 201까지의 게시글이 나오게 된다.
url = "https://openapi.naver.com/v1/search/blog.json?query=한남동&start=101&display=101"
res = requests.get(url, headers = {
"X-Naver-Client-Id" : client_id,
"X-Naver-Client-Secret" : client_secret
} )마찬가지로, start 인자의 범위를 벗어난 값을 인자로 넣어준다면 keyerror가 뜨게 된다.
7. 함수화
def call_api(query, start,display):
url = f"https://openapi.naver.com/v1/search/blog.json?query={query}&start={start}&display={display}"
res = requests.get(url, headers = {
"X-Naver-Client-Id" : client_id,
"X-Naver-Client-Secret" : client_secret
} )
r = res.json()
return r
r = call_api("병원", 1 ,10)
r['items']8. 원하는 건수 만큼 자동 반복하는 기능 만들기
1-1000번까지 페이징하기 위해 parameter를 10번 바꿔야한다.
같은 코드를 여러번 쓰지않고, 건수를 인자로 받아 원하는 만큼 자동 반복을 할 수 있는 함수로 만들어 효율성을 높일 수 있다.
함수화하기 전 코드인 1번 코드를 함수화하면 2번 코드와 같이 작성할 수 있다.
repeat 변수는 "quantity // display" 이므로 100을 나눈 값으로 설정한다.
1부터 100, 101부터 200,... 최대 요청 건수는 1100이므로 (quantity의 최댓값이 1100이므로) repeat 값이 11번 이상이면 종료한다.
또한 r['items']를 result 변수에 append 하여 반환한다.
1)
r = call_api("병원", 1 ,100)
r = call_api("병원", 101 ,200)
r = call_api("병원", 201 ,300)
r = call_api("병원", 301 ,400)
r = call_api("병원", 401 ,500)
...
2)
def get_page_call(query, quantity):
if quantity > 1100:
print(f"최대 요청할 수 있는 건수는 1100건 입니다")
exit("")
repeat = quantity // 100
result = []
for i in range(repeat):
start = i * 100 + 1
if start > 1000:
start = 1000
r = call_api(query, start= start, display=100 )
result += r['items']
return result
t = get_page_call("병원", 900)
len(t)9. 한 장의 이미지 저장하기
def save_image(self, r, quantity):
image_url = r[0]['link']
image_byte = Request(image_url, headers = {"User-Agent":"Mozilla/5.0"})
f = open('0.jpg', 'wb')
f.write(urlopen(image_byte).read())
f.close()
if __name__ == '__main__':
naver_search_api = NaversearchAPI()
r = naver_search_api.image("이케아 의자", 100)
naver_search_api.save_image(r, 100)10. 여러 장의 이미지 저장하기 + 경로 지정하기
def save_images(self, path, r):
if not os.path.exists(path):
os.mkdir(path)
cnt = 0
for img in r:
#이미지 저장 시 에러가 발생할 수도 있기에 try except문으로 예외처리
try:
image_url = img['link']
image_byte = Request(image_url, headers = {"User-Agent":"Mozilla/5.0"})
f = open(f'{path}/{cnt}.jpg', 'wb')
f.write(urlopen(image_byte).read())
f.close()
except Exception as e:
print(e)
cnt += 1
if __name__ == '__main__':
keyword = "이케아 의자"
naver_search_api = NaversearchAPI()
r = naver_search_api.image(keyword, 100)
#path는 keyword로 넘겨주어서 keyword에 따라 디렉토리를 만든다
naver_search_api.save_images(keyword, r)11. class로 만들기
블로그 뿐만 아니라 뉴스, 책, 백과사전 등 다양한 검색 API를 사용할 수 있도록 class화를 해볼 것이다.
class NaversearchAPI():
def call_api(self, query, start = 1,display = 10):
url = f"{self.api_url}?query={query}&start={start}&display={display}"
res = requests.get(url, headers = {
"X-Naver-Client-Id" : client_id,
"X-Naver-Client-Secret" : client_secret
} )
r = res.json()
return r
#블로그
def blog(self, query, quantity= 100):
self.api_url = "https://openapi.naver.com/v1/search/blog.json"
return self.get_page_call(query, quantity)
#뉴스
def news(self, query, quantity= 100):
self.api_url = "https://openapi.naver.com/v1/search/news.json"
return self.get_page_call(query, quantity)
#웹문서
def webkr(self, query, quantity= 100):
self.api_url = "https://openapi.naver.com/v1/search/webkr.json"
return self.get_page_call(query, quantity)
def get_page_call(self, query, quantity):
if quantity > 1100:
print(f"최대 요청할 수 있는 건수는 1100건 입니다")
exit("")
repeat = quantity // 100
result = []
for i in range(repeat):
start = i * 100 + 1
if start > 1000:
start = 1000
r = self.call_api(query, start= start, display=100 )
result += r['items']
return result
def save_image(self, r, quantity):
image_url = r[0]['link']
image_byte = Request(image_url, headers = {"User-Agent":"Mozilla/5.0"})
f = open('0.jpg', 'wb')
f.write(urlopen(image_byte).read())
f.close()
def save_images(self, path, r):
if not os.path.exists(path):
os.mkdir(path)
cnt = 0
for img in r:
#이미지 저장 시 에러가 발생할 수도 있기에 try except문으로 예외처리
try:
image_url = img['link']
image_byte = Request(image_url, headers = {"User-Agent":"Mozilla/5.0"})
f = open(f'{path}/{cnt}.jpg', 'wb')
f.write(urlopen(image_byte).read())
f.close()
except Exception as e:
print(e)
cnt += 1
if __name__ == '__main__':
naver_search_api = NaversearchAPI()
r = naver_search_api.blog("교대역")
#r = naver_search_api.news("교대역 맛집")
print(r[0])
