1. Seaborn 이란
Seaborn 은 matplotlib을 기반으로 하는 python 데이터 시각화 라이브러리이다.
다양한 색상 테마와 통계용 차트 등의 기능으로 시각화를 간편하게 할 수 있도록 한다.
주요 파라미터는 다음과 같다.
- x, y : x,y축의 위치를 지정하는 변수
- hue : 다른 색상의 선을 생성하는 그룹화 변수
- size : 너비가 다른 선을 생성하는 그룹화 변수
- style : 다른 스타일의 마커 또는 선을 생성하는 그룹화 변수
- data : 데이터 구조 입력
- palette : hue 매핑 시 사용할 색상 선택 변수
2. 사전 준비
(1) import
seaborn 라이브러리는 통상적으로 sns 라는 별칭으로 import 하며, 이 때 matplotlib 패키지를 기반으로 하기 때문에 matplotlib.pyplot도 함께 import 해준다.
import matplotlib.pyplot as plt
import seaborn as sns(2) load data
seaborn 라이브러리에도 샘플 데이터셋이 있다. load_dataset() 함수를 사용하여 라이브러리 상에 저장되어있는 샘플 데이터셋을 로드한다.
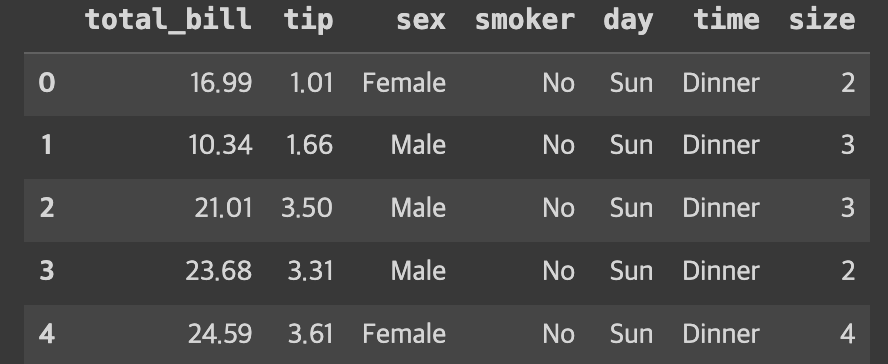
tips = sns.load_dataset("tips")
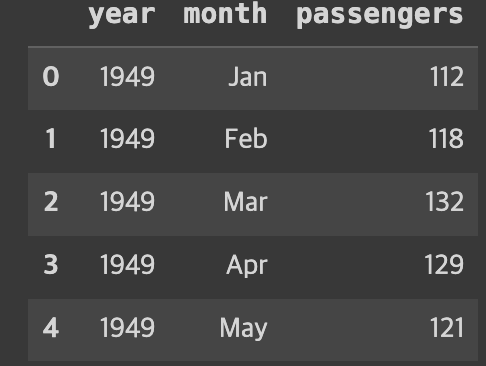
flights = sns.load_dataset("flights")
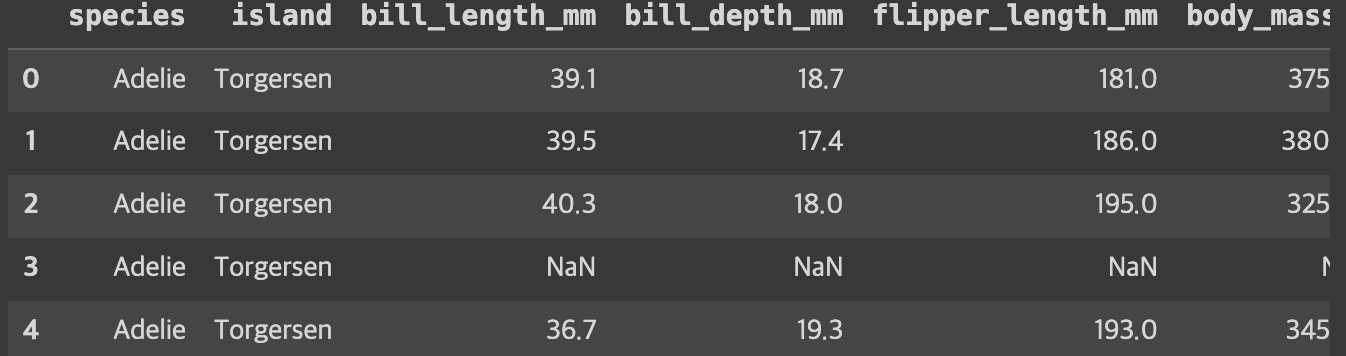
penguins = sns.load_dataset("penguins")
print(tips)
print(flights)
print(penguins)
3. relational plots
relational plot이란 x, y값의 관계를 그려주는 관계형 그래프이다.
(1) line plot
lineplot()은 선 그래프를 그리는 함수로 데이터가 시간 또는 순서에 따라 어떻게 변화하는지 보여주기 위해 사용한다.
참고) query() 함수: pandas 에서 데이터프레임을 쿼리하고 원하는 조건에 맞는 데이터를 선택하는 데 사용되는 메서드이다. 이 함수를 통해 SQL 스타일의 쿼리를 편리하게 작성할 수 있다.
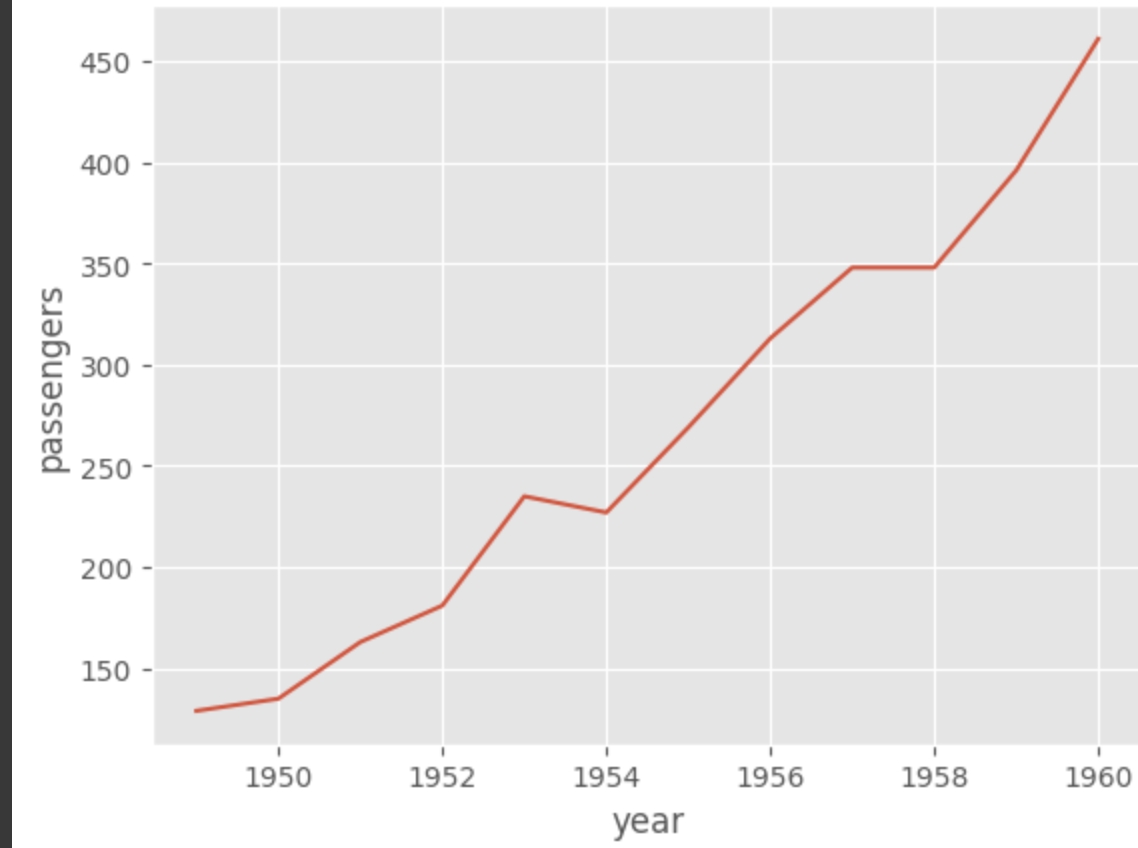
아래 코드는 flights 데이터에서 month 열 중 "Apr"인 데이터만 april_flights 변수에 저장한 후 이를 선 그래프로 나타냈다.
x축은 year, y축은 passengers(승객의 수)이다.
그래프를 보면 시간이 흐를 수록 4월 달에 탑승한 승객의 수가 높아지고 있음을 알 수 있다.
+) seaborn 패키지의 함수들은 plt.show()를 사용하지 않아도 그래프가 플롯팅된다.
april_flights = flights.query("month == 'Apr'")
sns.lineplot(data = april_flights, x = 'year', y ='passengers')
plt.show()
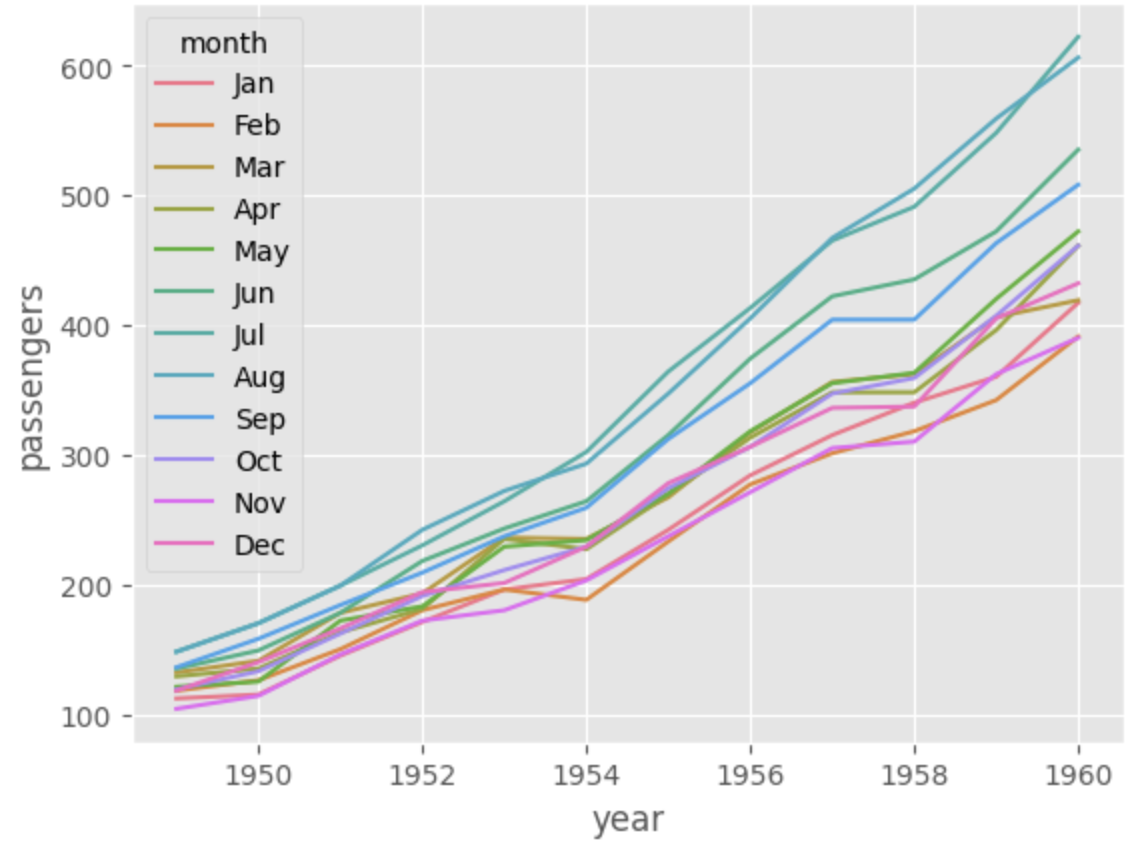
위 코드에서 hue 인자를 추가하여 월별 탑승 승객의 년도별 추이를 살펴볼 수 있다.
결과는 다음과 같이 나온다.
april_flights = flights.query("month == 'Apr'")
sns.lineplot(data = april_flights, x = 'year', y ='passengers', hue = 'month)
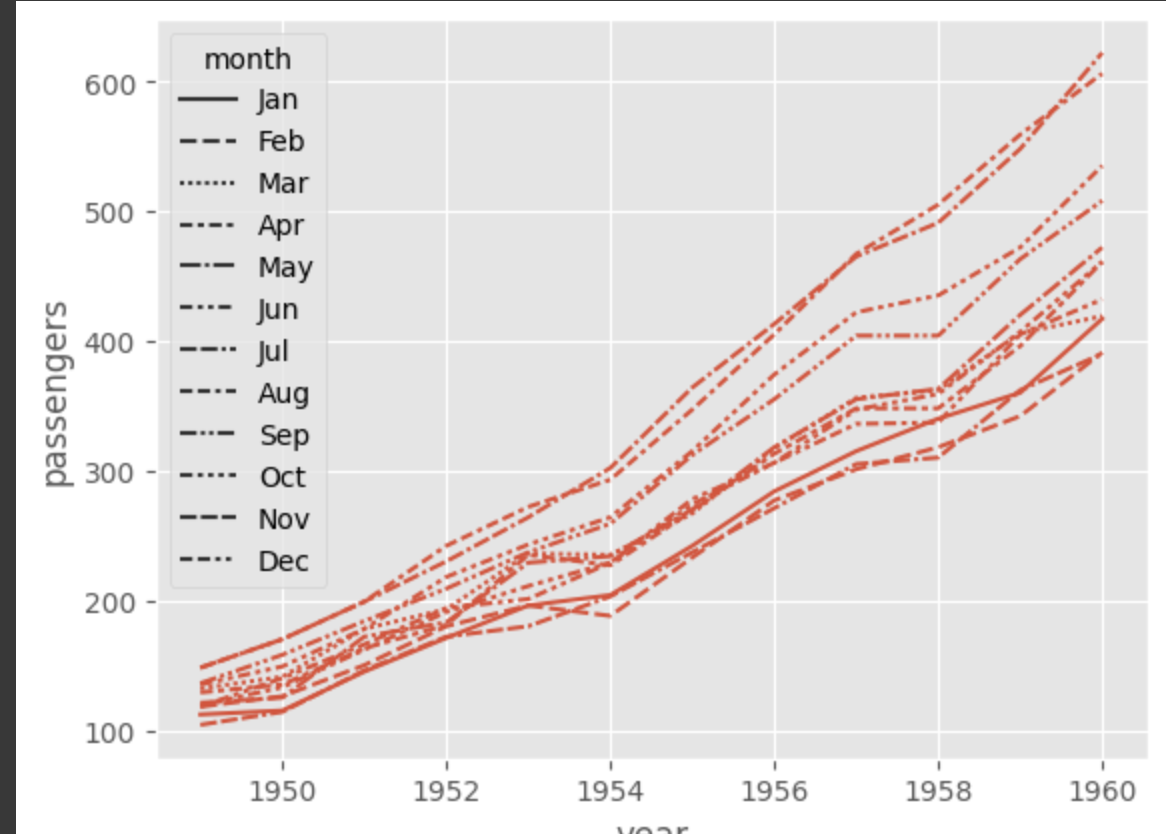
hue 인자 대신 style 인자를 추가하여 월별 탑승 승객을 다른 스타일의 그래프로 나타내어 년도별 추이를 살펴볼 수 있다.
그러나 이 데이터로 그린 그래프의 style 차이를 육안으로 식별하기 어려웠다.
(2) scatter plot
참고) 이산적인 데이터: 일정한 간격으로 나뉘어져 있지 않으며 연속적이지 않고 분리된 값을 가지는 데이터를 의미한다.
앞서 사용한 flights 데이터셋은 이산적인 값들을 가지지만 lineplot을 통한 분석에 적합하다.
이는 시간("year")의 흐름에 따라 변화하는 "passengers" 변수가 있기 때문이다.
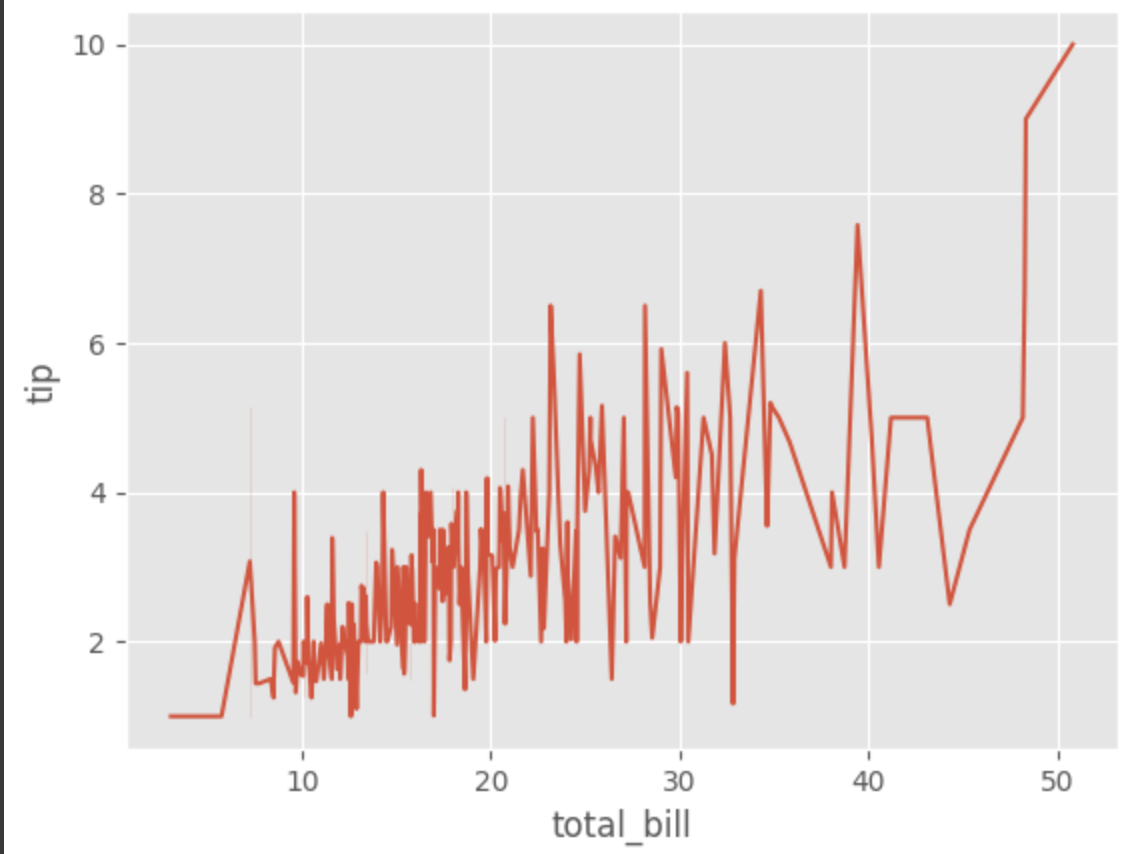
시간의 흐름에 따라 변화하는 변수가 없는, 이산적인 데이터셋을 가지고 lineplot을 그린다면 어떻게 될까?
이를 알아보기 위해 seaborn의 tips 데이터셋의 total_bills, tip 변수에 대해 lineplot을 그려보았다.
결과로 나온 그래프는 다음과 같다.
tips = sns.load_dataset("tips")
sns.lineplot(data = tips, x= 'total_bill', y = 'tip')
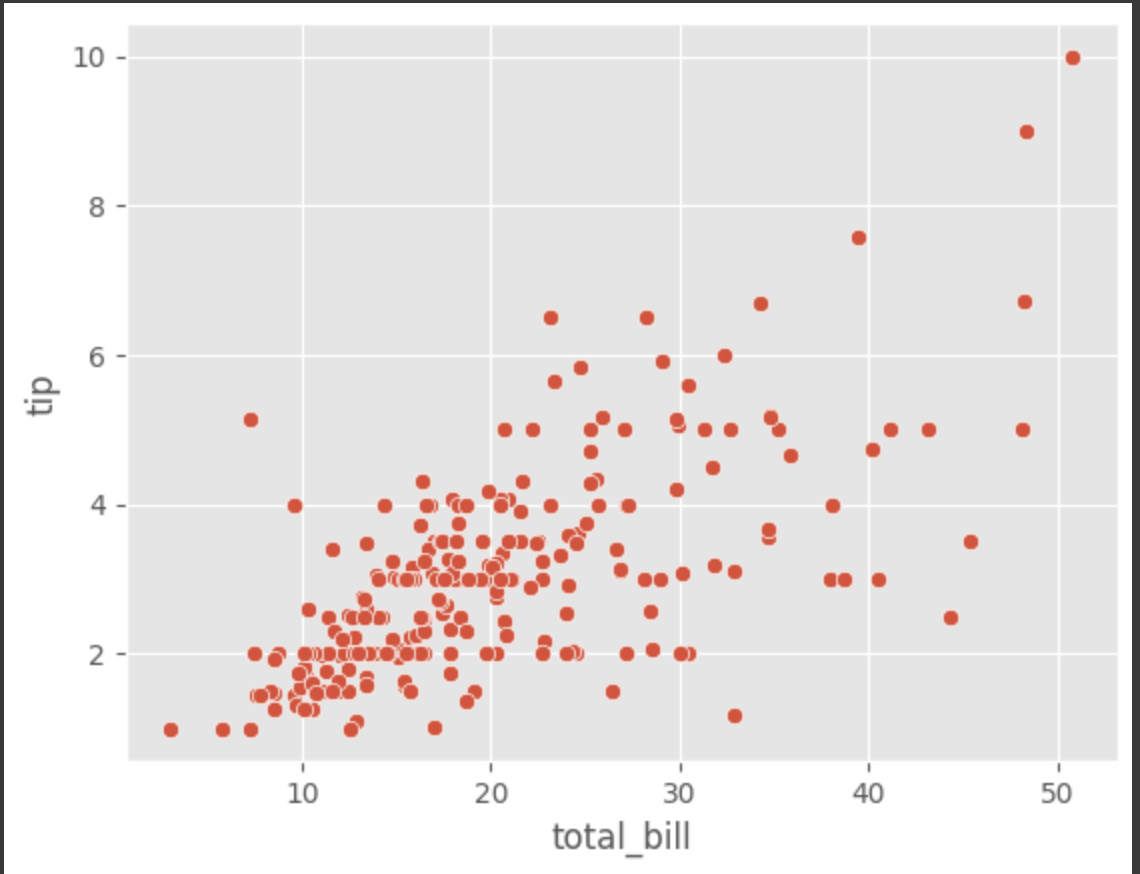
tips 데이터셋과 같이 시간의 흐름에 따른 변화가 없으며, 이산적인 값들을 갖는 데이터셋에 대해서는 scatter plot이 더 적절하다.
scatterplot()은 두 개의 실수 데이터 집합의 상관관계를 파악하기 위해 산점도를 그릴 때 사용한다.
tips = sns.load_dataset("tips")
sns.scatterplot(data = tips, x= 'total_bill', y = 'tip')
scatterplot의 hue 인자에 time을 추가했다. time 변수는 lunch 또는 dinner로 나뉘어져 있으며 이에 따라 색 분류를 다르게 그렸음을 볼 수 있다.
tips = sns.load_dataset("tips")
sns.scatterplot(data = tips, x= 'total_bill', y = 'tip', hue = 'time')
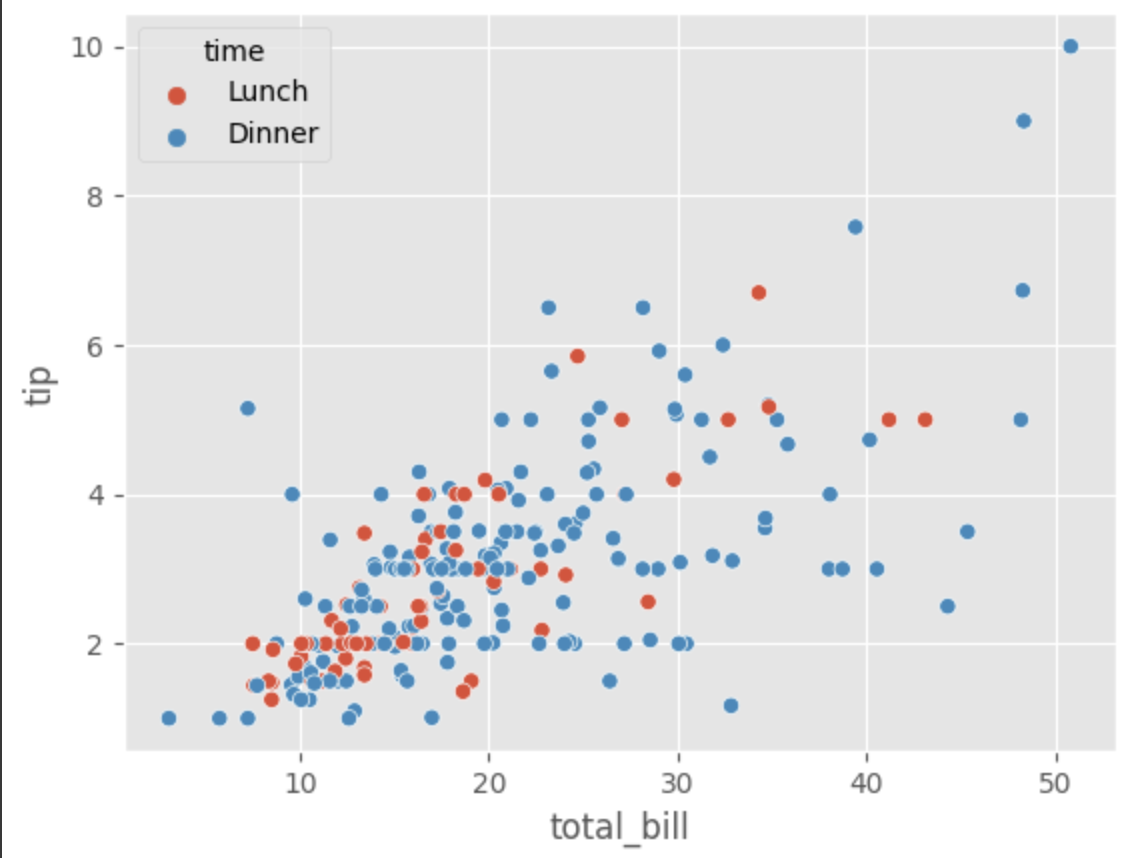
tips 데이터셋 중 'size' 열은 "식사에 참여한 인원 수"를 나타낸다. 팁의 금액과 size의 상관관계를 알아보기 위해 size 인자를 추가했다.
tips = sns.load_dataset("tips")
sns.scatterplot(data = tips, x= 'total_bill', y = 'tip', hue = 'time', size = 'size')
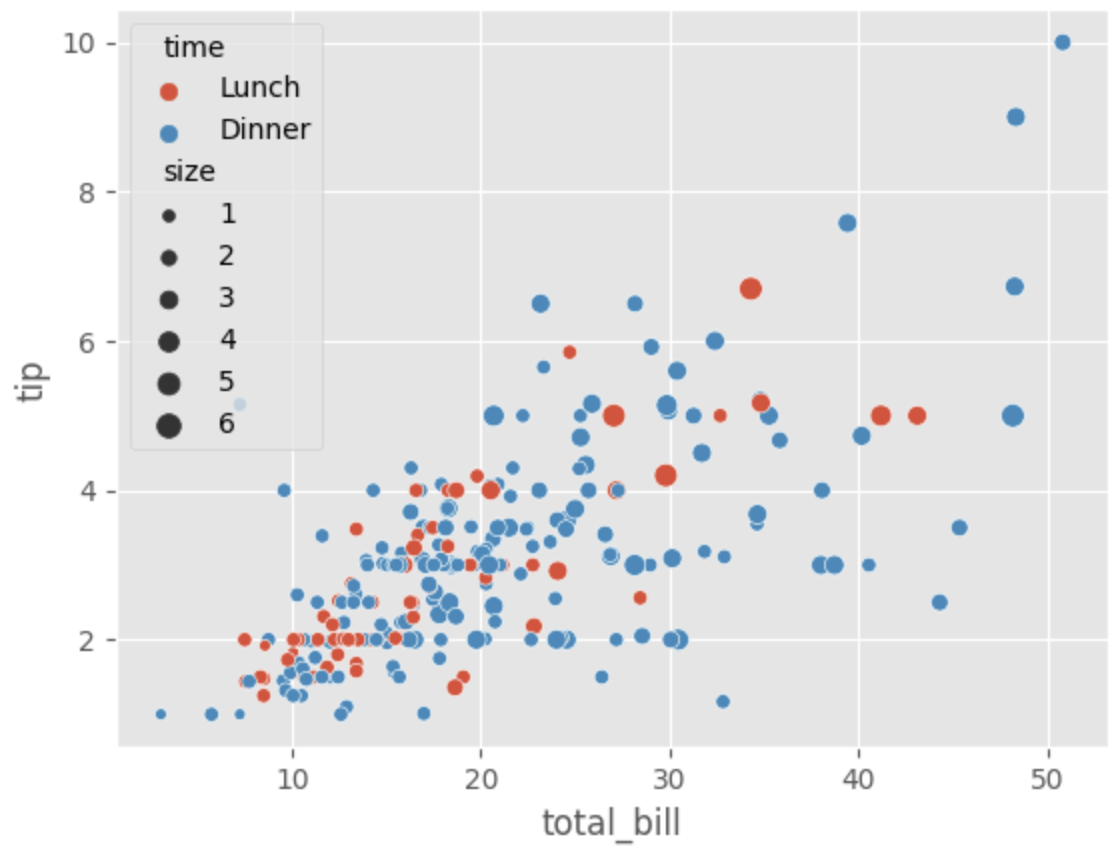
hue 인자에 대해 'size'로 설정하면, 'size' 값이 커질수록 색상이 점점 어두워지고, scatter의 크기가 점점 커지는 것을 확인할 수 있다.
tips = sns.load_dataset("tips")
sns.scatterplot(data = tips, x= 'total_bill', y = 'tip', hue = 'size', size = 'size')
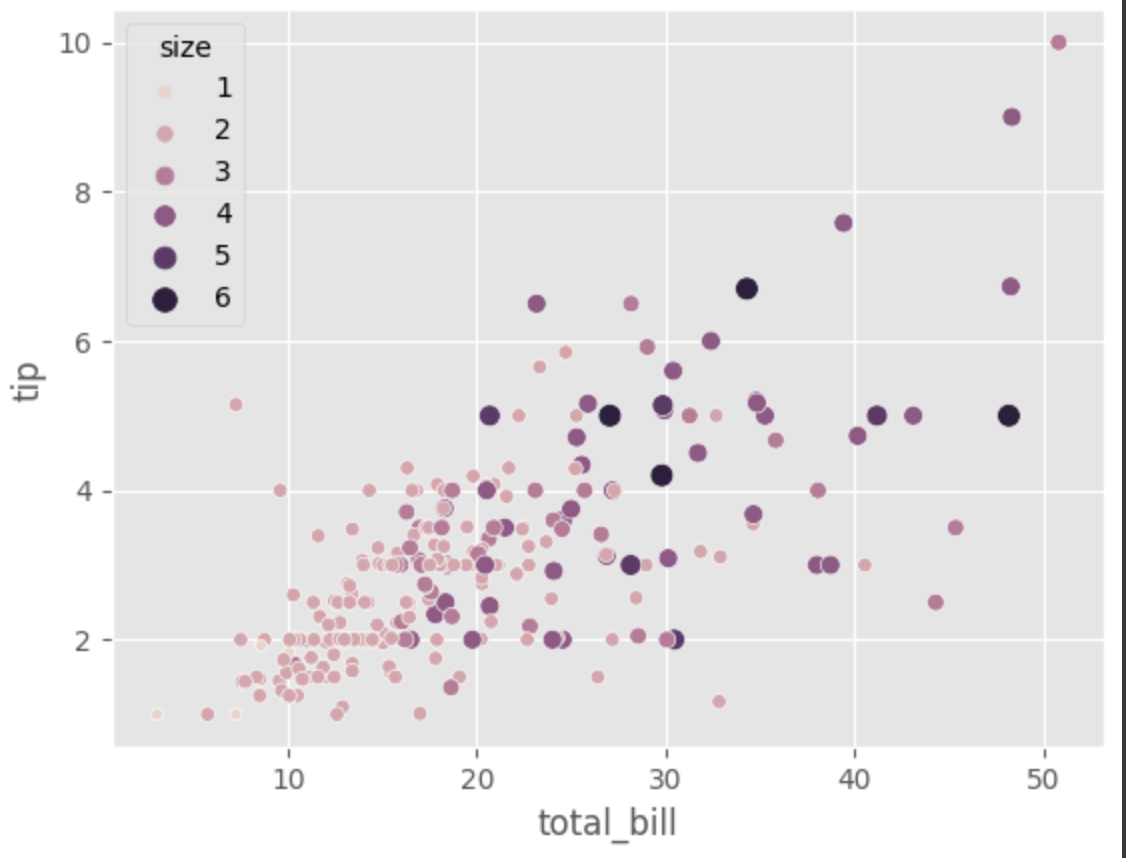
4. distribution plots
distribution plot이란 변수 값의 분포를 나타내기 위한 그래프이다.
분포를 나타내는 대표적인 그래프는 히스토그램으로, 이를 그리는 두 가지 함수가 있다.
- displot(): 여러 축의 히스토그램, 커널 밀도 추정 그래프 (kde) 등을 그릴 때 사용한다. kind 파라미터를 통해 히스토그램(hist), 커널 밀도 추정 그래프(kde), ecdf 등을 선택한다.
- histplot(): 하나의 축에 대한 히스토그램을 그릴 때 사용한다. 단일 변수의 분포를 시각화한다.
⭐️갑자기 이미지 업로드 오류가 떠서 추후에 이미지 추가 예정⭐️
(1) displot()
displot()은 여러 개의 서브 플롯을 그릴 수 있으며 kind 파라미터를 통해 다양한 그래프를 선택할 수 있다.
penguins = sns.load_dataset("penguins")
sns.displot(data=penguins, x = "flipper_length_mm")kind 인자에 "kde" 를 대입하면 커널 밀도 추정을 사용하여 일변량, 이변량 분포를 그린다.
penguins = sns.load_dataset("penguins")
sns.displot(data=penguins, x = "flipper_length_mm", kind="kde")kind 인자에 "ecdf"를 대입하면 경험적 누적 분포 함수를 그린다.
penguins = sns.load_dataset("penguins")
sns.displot(data=penguins, x = "flipper_length_mm", kind="ecdf")kde 인자에 True를 대입하면 kde 곡선이 추가된 히스토그램을 그린다.
penguins = sns.load_dataset("penguins")
sns.displot(data = penguins, x = "flipper_length_mm", kde = True)hue 인자에 "species"를 대입하여 펭귄의 종에 따라 kde 그래프의 색을 다르게 그린다.
penguins = sns.load_dataset("penguins")
sns.displot(data = penguins, x = "flipper_length_mm", hue = "species", kind = "kde")hue 인자에 "species" 를 대입하여 각 species 히스토그램을 다른 색상으로 하며, multiple 인자에 "stack"을 대입하여 하나의 막대에 여러 개의 막대를 쌓는 형식으로 그린다.
penguins = sns.load_dataset("penguins")
sns.displot(data = penguins, x = "flipper_length_mm", multiple = "stack", hue = "species")(2) histplot()
histplot()은 특정 축(단일 축)에만 히스토그램을 그릴 때 사용한다. displot()과 달리 여러 축을 가진 전체 그림을 만들지 않고, 단일 축에만 그래프를 그린다.
x값이 flipper_length_mm인 히스토그램을 그린다. (displot과 동일)
penguins = sns.load_dataset("penguins")
sns.histplot(data = penguins, x = "flipper_length_mm")
flipper_length_mm을 y축에 할당하여, 수평 방향의 히스토그램을 그린다.
penguins = sns.load_dataset("penguins")
sns.histplot(data = penguins, y = "flipper_length_mm")
kde 인자에 True를 대입하여 kde 곡선을 히스토그램 위에 추가한다.
penguins = sns.load_dataset("penguins")
sns.histplot(data = penguins, x = "flipper_length_mm", kde = True)
hue인자에 "species"를 대입하여 각 종마다 다른 색상의 히스토그램을 그리며, multiple 인자에 "stack"을 대입하여 하나의 막대에 여러 개의 막대를 쌓는 형식으로 그린다.
penguins = sns.load_dataset("penguins")
sns.histplot(data = penguins, x = "flipper_length_mm", hue = "species", multiple = "stack")
위 코드에서는 막대들이 겹치기 때문에 육안으로 식별하기 힘든 문제를 갖는다.
이를 해결하기 위해 element 인자에 "step"을 대입하여 히스토그램을 그린다.
penguins = sns.load_dataset("penguins")
sns.histplot(data = penguins, x = "flipper_length_mm", hue = "species", element = "step")
element 인자에 "poly"를 대입하여 히스토그램을 그리면 각 막대의 중앙에 꼭짓점이 있는 다각형의 형태인 히스토그램을 그릴 수 있다
이 그래프는 분포의 모양을 쉽게 파악할 수 있으나, 히스토그램이라고 보기 어렵다는 단점이 있다.
penguins = sns.load_dataset("penguins")
sns.histplot(data = penguins, x = "flipper_length_mm", hue = "species", element = "poly")
5. categorical plots
categorical plot이란 범주형 변수와 연속형 변수간의 관계를 나타내기 위한 그래프이다.
범주형 데이터는 명목형, 순서형 데이터로 나뉜다.
- 명목형: 순서나 계층이 없는 데이터
- 순서형: 상대적 순서, 등급, 계층이 있는 데이터 (간격이나 비율이 명확하지 않은 경우에도 사용)
categorical plot()함수 사용 시 set_theme()은 plot에 대한 시각적 테마를 설정한다.
#기본 테마
sns.set_theme()
#whitegrid 스타일에 pastel 테마
sns.set_theme(style='whilegrid', paletter='pastel')
(1) barplot()
barplot()은 막대 그래프를 그리는 함수로, 직사각형 막대로 카테고리 별 평균값을 나타낸다.
막대 상단의 검은 선은 해당 추정치 주변의 불확실성을 나타내는 오차 막대이다.
tips 데이터셋의 "day"를 x축으로, "total_bill"을 y축으로 수직 막대 그래프를 그린다.
tips = sns.load_dataset("tips")
sns.barplot(data = tips, x = "day", y = "total_bill")
x와 y를 반대로 할당하여 수평 막대 그래프를 그린다.
tips = sns.load_dataset("tips")
sns.barplot(data = tips, x = "day", y = "total_bill")
hue 인자에 "sex"를 대입하여 성별에 따라 막대의 색상이 다르게 그린다.
tips = sns.load_dataset("tips")
sns.barplot(data = tips, x = "day", y = "total_bill", hue = "sex")
(2) boxplot()
boxplot()은 데이터의 분포와 중앙값, 이상치 등을 시각적으로 보여준다.
아래 코드는 tips 데이터셋의 "total_bill" 열의 분포에 대한 boxplot을 그린다.
상자는 데이터의 중간 50%에 해당하는 사분위수를 나타낸다 상자의 아랫부분은 25-50%, 윗부분은 50-75%까지의 데이터를 나타내며, 상자 내부의 가로선은 데이터의 중앙값을 나타낸다.
수염은 데이터의 전체 범위를 나타내며, 일반적으로 사분위수의 1.5배를 벗어나는 값은 이상치로 표시된다.
이상치는 수염 바깥에 있는 점으로 나타난다.
tips = sns.load_dataset("tips")
sns.boxplot(x = tips["total_bill"])
x값에는 범주형 변수 "day"를, y값에는 범주형 변수 "total_bill"을 대입하여 day로 그룹화된 수직 boxplot을 그린다.
tips = sns.load_dataset("tips")
sns.boxplot(data = tips, x = "day", y = "total_bill")
hue 인자에 "smoker"를 대입하여 day와 smoker로 중첩 그룹화된 boxplot을 그린다.
또한, palette 인자에 "Set3"를 대입하여 그림의 색상을 Set3로 설정한다.
tips = sns.load_dataset("tips")
sns.boxplot(data = tips, x = "day", y = "total_bill")
(3) countplot()
countplot()은 각 카테고리에 속하는 데이터의 개수를 막대 그래프로 나타낸다.
tips = sns.load_dataset("tips")
sns.countplot(data = tips, x = "day", hue = "time")tips = sns.load_dataset("tips")
sns.countplot(data = tips, y = "day", hue = "time")(4) stripplot()
stripplot()은 주어진 카테고리의 각 데이터 포인트를 점 형태로 표시하여 데이터의 분산을 쉽게 파악할 수 있다.
x값에 "total_bill"를 대입하여 단일 수평 stripplot을 그려 total_bill의 값의 범위에 따라 각각의 데이터를 점 형태로 표시했다.
tips = sns.load_dataset("tips")
sns.stripplot(data = tips, x = "total_bill")x값에 범주형 변수 "day"를 y값에 숫자형 변수 "total_bill"을 대입하여 범주형 변수 "day"로 스트립을 그룹화한 그래프를 그렸다.
tips = sns.load_dataset("tips")
sns.stripplot(data = tips, x = "day", y = "total_bill")x에 "total_bill", y에 "day"를 각각 대입하여 스트립을 반대로 그렸다.
tips = sns.load_dataset("tips")
sns.stripplot(data = tips, x = "total_bill", y = "day")hue인자에 "day"를 대입하여 요일에 따라 색 분류를 하였고, x에 "sex", y에 "total_bill"을 대입하여 성별로 스트립을 그룹화한 그래프를 그렸다.
tips = sns.load_dataset("tips")
sns.stripplot(data = tips, x = "sex", y = "total_bill", hue = "day")(5) swarmplot()
swarmplot은 stripplot과 유사하지만 데이터 포인트를 겹치지 않게 배치하여 더 나은 가시성을 제공한다.
x값에 "total_bill"를 대입하여 단일 수평 swarmplot을 그려 total_bill의 값의 범위에 따라 각각의 데이터를 점 형태로 표시했다.
tips = sns.load_dataset("tips")
sns.swarmplot(data = tips, x = "total_bill")
x값에 범주형 변수 "day"를 y값에 숫자형 변수 "total_bill"을 대입하여 범주형 변수 "day"로 스트립을 그룹화한 그래프를 그렸다.
tips = sns.load_dataset("tips")
sns.swarmplot(data = tips, x = "day", y = "total_bill")
x에 "total_bill", y에 "day"를 각각 대입하여 그래프를 반대로 그렸다.
tips = sns.load_dataset("tips")
sns.swarmplot(data = tips, x = "total_bill", y = "day")
hue인자에 "day"를 대입하여 요일에 따라 색 분류를 하였고, x에 "sex", y에 "total_bill"을 대입하여 성별로 그룹화한 그래프를 그렸다.
tips = sns.load_dataset("tips")
sns.swarmplot(data = tips, x = "day", y = "total_bill", hue = "sex")
이외에도 다양한 그래프를 제공한다. 그러나 본질적으로 들어가는 인자들이 비슷하기 때문에 하나의 사용법을 잘 익혀두면 나머지 그래프들도 잘 그려볼 수 있을 것 같다.
