1. Scikit-learn이란
파이썬 머신러닝 라이브러리 중 가장 많이 사용되는 라이브러리이다.
특징으로는 다음과 같다.
- 데이터 분석 시 사용되는 ML 라이브러리
- 분류, 회귀, 군집화 문제 해결 가능
- 직관적인 API, 다양한 모듈, 머신러닝 기능 제공
2. Scikit-learn의 주요 모듈
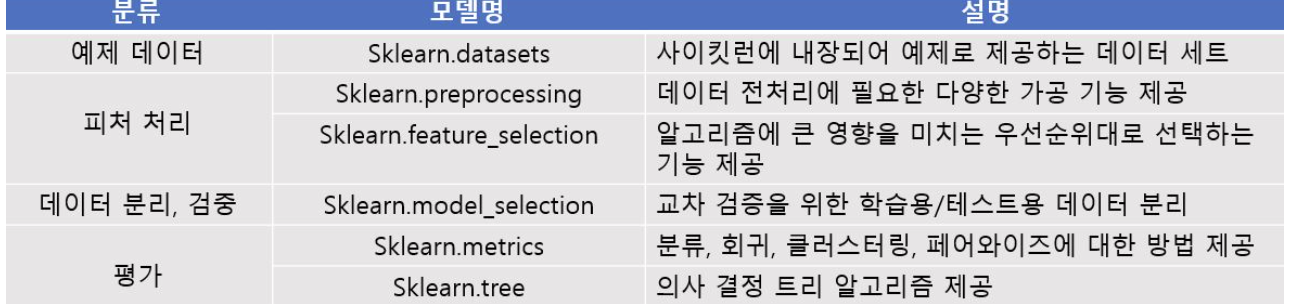
1. 예제 데이터셋
dataset 모듈은 scikit-learn이 제공하는 다양한 데이터 샘플을 모아둔 모듈이다.
데이터 샘플은 다음과 같다.
- Load_ : 패키지 안에 내장된 데이터 세트
- Fetch_ : 데이터의 크기가 커 인터넷에서 받아 사용하는 데이터
대표적인 Load 데이터셋으로 iris 데이터셋이 있다. 이 데이터셋은 다음과 같이 불러올 수 있다.
from sklearn.datasets import load_iris
iris = load_iris()
2. sklearn.preprocessing
1. 데이터 클렌징
(1) 불필요한 열 제거
drop함수를 이용하여 피쳐로 사용하기 부적절한 열을 제거한다.
해당 데이터에서는 PassengerId 열이 피쳐로 사용하기 부적합하므로 제거한다.
axis인자의 값이 0이면 행 단위 수정, 1이면 열 단위 수정이다. 데이터프레임에서 특정 열을 제거해주기 위해서 axis = 1을 꼭 써주어야 하는데 이는 디폴트가 axis = 0이기 때문이다.
titanic_df.drop(['PassengerId'], axis = 1)
(2) 결측값 처리
scikit-learn 알고리즘은 null 값을 허용하지 않기 때문에 데이터 클렌징 과정에서 null 값을 반드시 처리해야 한다.
Age 열의 결측치는 평균값으로 대체한다.
mean_of_age = round(titanic_df['Age'].mean(),0)
titanic_df['Age'].fillna(mean_of_age, inplace = True)2. preprocessing
scikit-learn의 preprocessing 모듈을 사용하여 인코딩 을 한다.
- 레이블 인코딩 : 문자열 값을 숫자로 변환하는 인코딩 방식
LabelEncoder(): 레이블 인코딩을 구현
Fit(): 인코딩 학습 -> Fit() 실행 후 문자열을 숫자값으로 학습
transform(): 학습한 숫자값을 실제로 변환
import numpy as np
from sklearn import preprocessing
# 샘플 데이터 입력
input_labels = ['red','black','red','green']
#레이블 인코더 생성후 앞에서 정의한 레이블로 학습시키기.
encoder = preprocessing.LabelEncoder()
encoder.fit(input_labels)
labels = encoder.transform(input_labels)
- 원핫 인코딩 : 레이블 인코딩은 숫자 값의 크고 작음에 대한 특성이 작용하여 단순히 숫자를 표시로 인식하는 것이 아니라 숫자나 중요도로 인식할 수 있다는 한계가 있다. 따라서 원핫 인코딩은 2차원 구현으로 레이블 인코딩을 거쳐 고윳값에 해당하는 컬럼에만 1을 표시하고 나머지는 0으로 표시한다.
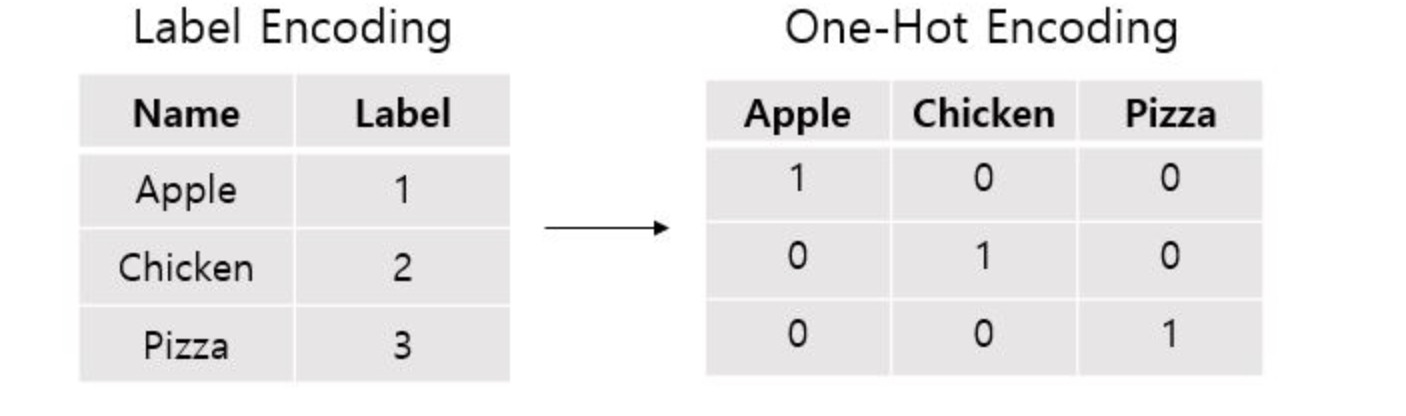
#(4,) -> (4,1) 이차원 변환
labels = labels.reshape(-1,1)
encoder2 = preprocessing.OneHotEncoder()
encoder2.fit(labels)
labels2 = encoder2.transform(labels)
print(labels2)out[]:
<4x3 sparse matrix of type '<class 'numpy.float64'>'
with 4 stored elements in Compressed Sparse Row format>
3. 데이터 분할
train_test_split()은 훈련용, 시험용 데이터를 분리하는 함수이며 주요 파라미터는 다음과 같다.
- test_size: 전체 데이터에서 테스트 데이터 세트 크기를 얼마로 샘플링할 것인가 (디폴트 0.25)
- train_size: 전체 데이터에서 학습용 데이터 세트 크기를 얼마로 샘플링할 것인가 (잘 사용x)
- random_state: 호출할 때마다 동일한 학습, 테스트용 데이터 세트를 생성하기 위해 주어지는 난수 값이며 이 값을 지정하지 않으면 실행 시마다 다른 데이터 세트를 만들어낸다.
- shuffle: 데이터를 분리하기 전 데이터를 미리 섞을 것인지 여부 결정 (디폴트 True)
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
iris = load_iris()
iris_data = iris.data
iris_label = iris.target
X_train, X_test, y_train, y_test = train_test_split(iris_data, iris_label, test_size = 0.2, random_state=11)
