
📕 머신러닝이란?
과거 특정 분야의 인공지능을 개발하기 위해 해당 분야의 전문가들이 만든 수 많은 샘플들을 데이터화시켜 기계에게 수작업으로 학습시키는 방식을 사용했다. 인간의 손을 거쳐 학습시키는 작업은 당시 기술력을 본다면 반강제적으로 사용 할 수 밖에 없던 방법이였으나 기술의 발전에 따라 굳이 많은 돈과 시간이 소요되는 해당 작업 사용할 필요성을 느끼지 못했으며 인간이 명확히 구분하기 난해한 구분할 수 없는 지식(no explicit knowledge)을 구현해야하는 상황이 오자 이를 대체할 방식이 개발되었으니 이것이 머신러닝(Machine Learing)이다.

많은 사람들이 아직 인공지능과 머신러닝을 햇갈리거나 머신러닝이 무엇을 말하는지 모르는 사람이 많은데 이는 머신러닝(ML)이 인공지능(AI)의 부분집합에 해당한다고 생각하면 이해하는데 수월하다. 머신러닝과 인공지능에 대해 함께 논의되는 경우가 많고 서로 바꿔서 사용되기 때문에 비슷하다라고 볼 수도 있지만 동일한 것을 의미하지는 않는다.

📕 머신러닝으로 무엇을 하는가?
인공지능 개발자들이 빅데이터 속에 존재하는 데이터에 대한 전문가급 지식이 아니더라도 인간 수준의 간단한 지능을 구현할 방법을 고민하다. 정답(label)을 매겨 계산하고 인간의 생각과 차이가 나는 오류를 줄이는 방법으로 수정하는 과정을 반복하여 인간의 생각과 유사하게 만드는 방법을 만들었고 이같은 학습을 통해 얻은 인간과 유사한 지능, 인공지능을 응용하는 기술을 머신러닝이라 부른다.
일반적으로 머신러닝은 알고리즘을 이용하여 데이터를 분석하고 나온 결과를 스스로 학습한 뒤 이를 기반으로 판단이나 예측을 한다. 그러므로 데이터 분석 과정 중 데이터 정제 과정을 거쳐 양질의 데이터를 통해 더욱 정확성 높은 판단과 예측을 할 수 있다.
인공지능이 정확성 높은 판단과 예측을 하기 위한 머신러닝의 학습 방법은 지도 학습, 비지도 학습, 강화 학습 3가지 광범위한 범주로 나뉜다.
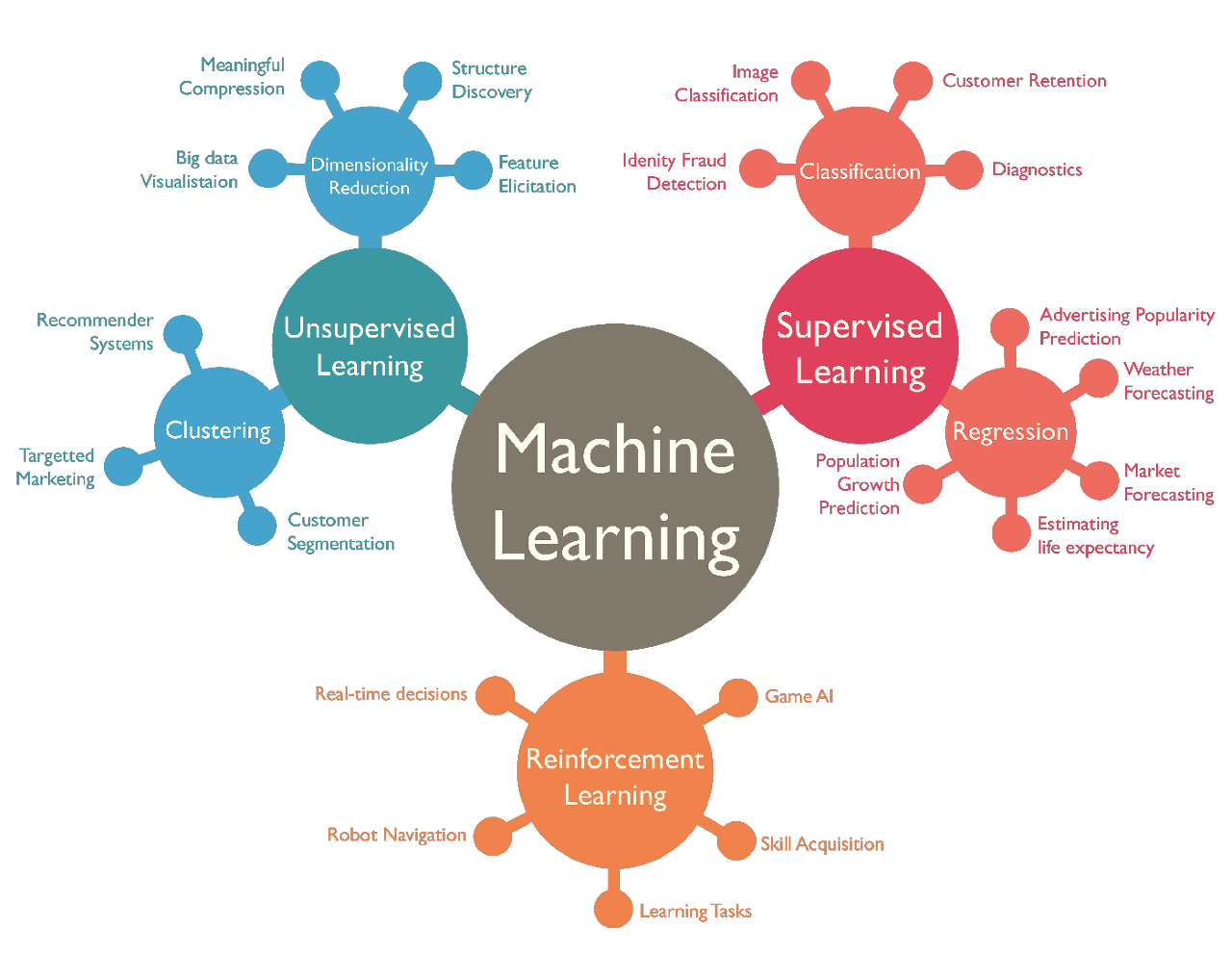
📙 지도 학습(Supervised learning)
지도 학습(Supervised learning)은 예시를 통해 훈련하는 방식이다. 지도학습은 모델을 사용하여 사진 속 사람은 몇 명이 존재하는가?, 사진의 배경 색상은 무엇인가?, 사진 속 공의 갯수는 몇 개인가? 등과 같은 정답이 정해져있는 예시를 학습하여 예측한 값을 낸다. 마치 교사가 학생들에게 문제지를 배포하고 체점을 동해 더욱 높은 점수를 받을 수 있게 지도하는 것과 비슷한 머신러닝 학습 방법이다. 지도 학습은 분류 기법(Classification techniques)과 선형 회귀(Linear regression)으로 크게 두 가지 유형이 있다.
📗 분류(Classification)
레이블이 달린 학습 데이터로 학습한 후 새로 입력된 데이터가 학습했던 어느 그룹에 속하는 지를 찾아내는 그룹의 구성원으로 식별하기 위해 알고리즘에 이산 값을 예측하도록 요청하는 방법이다. 분류 모델의 결과값은 언제나 학습했던 데이터의 레이블 중 하나가 된다. 레이블y가 이산적(Discrete)인 경우, y가 가질 수 있는 값이 [0, 1, 2, ..]와 같이 유한한 경우 분류가 되며 이와 다르면 인식 문제라고 부른다. 일상에서 가장 접하기 쉬우며 연구가 많이 되어있고 기업들이 가장 관심을 가지는 문제 중 하나이다. 이러한 문제들을 해결하기 위한 대표적인 기법들로는 로지스틱 회귀(Logistic Regression), 의사 결정 트리 분류(Decision Tree Classifier), K-NN 분류 (K-Nearest Neighbor Classifier), 랜덤 포레스트 분류(Random Forest Classifier), 신경망(Neural Networks;NN) 등이 있다.

📗 회귀(Regression)
회귀는 알고리즘이 데이터에서 학습하여 판매, 급여, 체중 또는 온도와 같은 연속 값을 예측하는 지도 기계 학습의 한 유형이다. 예시로 부지 크기, 침실 수, 욕실 수, 이웃 등과 같은 집의 특징을 포함하는 데이터 세트라고 할 수 있다. 또한 주택 가격, 회귀 알고리즘은 주택의 특징과 가격 사이의 관계를 학습하도록 훈련 될 수 있다. 회귀 작업에 사용할 수 있는 머신러닝 알고리즘으로는 선형 회귀(Linear Regression), 의사 결정 트리 회귀(Decision Tree Regressor), K-NN 회귀(K-Nearest Neighbor Regressor; KNN ), 랜덤 포리스트 회귀(Random Forest Regressor), 신경망(Neural Networks;NN) 등이 있다.

📗 알고리즘(Algorithm)
-
의사 결정 트리(Decision Tree)
결과 모델이 트리(Tree) 구조를 가지고 있기 때문에 의사 결정 트리라는 이름을 가진다. 특정 질문에 따라 데이터를 구분하느 모델을 의사 결정 트리 모델이라고 하며 한번의 분기 때마다 변수 영역을 두 개로 구분한다. 주어진 입력값들의 조합에 대한 의사결정규칙(Rule)에 따라 출력값을 예측하는 모형이다.

-
랜덤 포레스트(Random Forest)
정확성, 단순성 및 유연성으로 인해 가장 많이 사용되는 알고리즘 중 하나이다. 의사 결정 트리는 하나의 결과와 좁은 범위의 그룹을 갖지만, 포레스트는 더 많은 수의 그룹 및 결정으로 보다 정확한 결과를 보장한다. 분류와 회귀 작업에 사용할 수 있다는 사실과 비선형 특성을 결합하면 다양한 데이터 및 상황에 매우 적합하다.
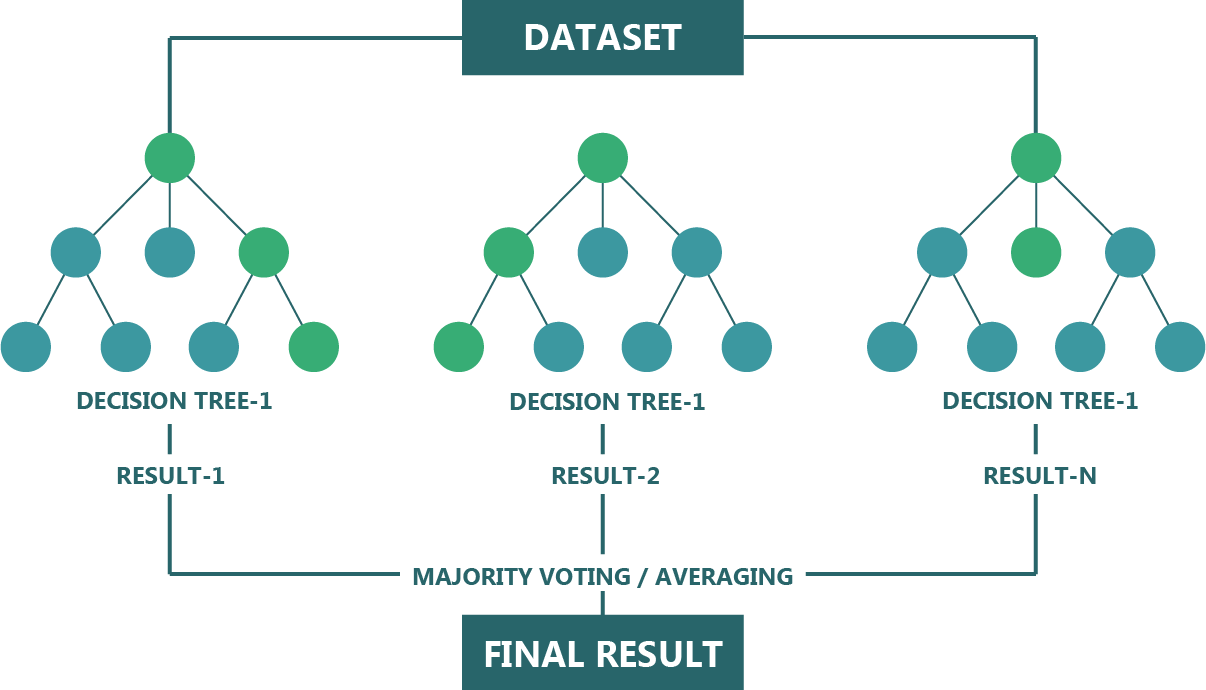
-
그레디언트 부스팅 머신(GBM; Gradient Boosting Machine)
경사 하강법(Gradient descent)을 결합한 새로운 부스팅(Boosting) 알고리즘이다. Adaboost는 이전 약한 모델(Weak Model)의 오답에 가중치를 부여하여 새로운 모델을 학습하는 방법이었다면 그래디언트 부스팅 머신은 잔차(Residual)에 집중한다. 이 잔차를 최소화하는 과정에서 경사 하강법을 사용하기 때문에 이런 이름이 붙었다. 그래디언트 부스팅 머신이 작동하는 방식은 약한 모델 을 만든 후 정답과 예측값의 차이, 잔차 을 계산한다.
다음으로 잔차 을 예측하는 두 번째 약한 모델 을 만든 후 과 의 잔차 를 구한다.
이렇게 번째 약한 모델 는 번째의 잔차를 근사하는 함수이다. 이를 번 반복한 뒤 정리하면 다음과 같은 식이 된다. 처음 은 크겠지만 반복해서 근사한 모델을 더해나가면 마지막 는 매우 작아진다.
📙 비지도 학습(Unsupervised Learning)
비지도 학습(Unsupervised Learning)은 자전거 타는 법을 배우는 아이(머신러닝)이 있을 때 자전거 뒤에서 균형을 잡아주는 부모가 있다면 지도 학습이고 그렇지 않고 자전거를 넘겨준 뒤 지켜보고 있다면 비지도 학습이라고 할 수 있다. 머신이 데이터 사이언티스트의 도움이나 안내가 없이 학습하도록 하는 것이다. 그 과정에서 더 적합한 결과가 있을 때 결과와 그룹화를 조정하는 방법도 학습해야 하며 이를 통해 머신이 데이터를 이해하고 적합하다고 판단되는 방식으로 처리할 수 있다. 해당 학습 방법은 알려지지 않은 데이터를 탐색하는 데 사용 또는 놓쳤을 수 있는 패턴을 밝히거나 사람이 처리하기에 너무 큰 대규모 데이터 세트를 검사할 떄 사용된다. 비지도 학습은 군집화(Clustering), 시각화(Visualization)와 차원 축소(Dimensionality Redution), 연관 규칙 학습(Assoction Rule Learing)을 사용하여 작동한다.
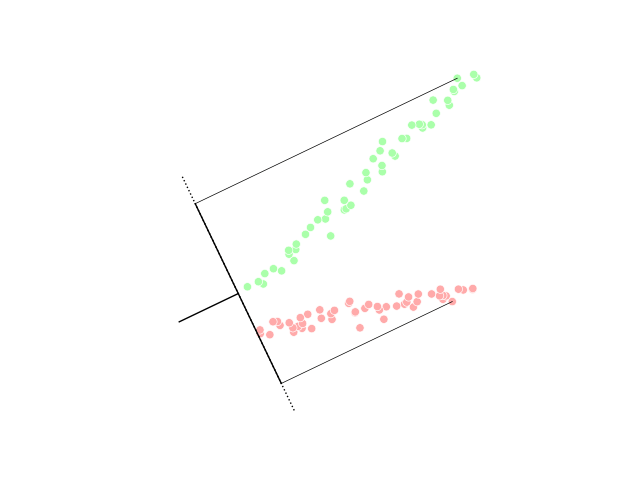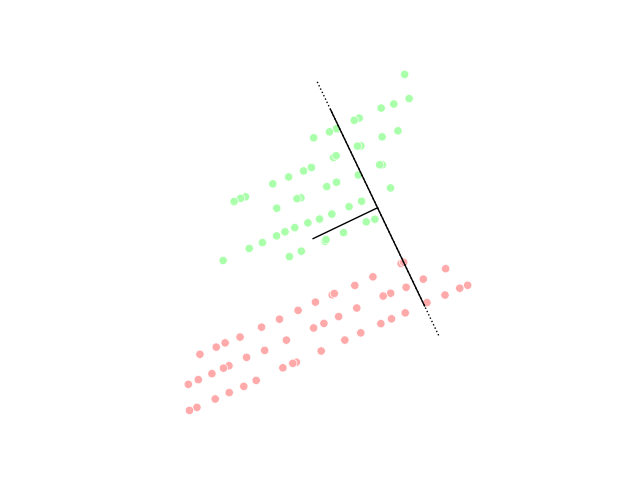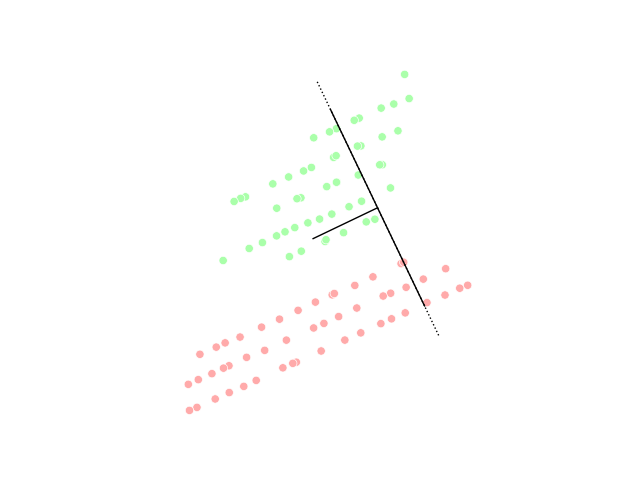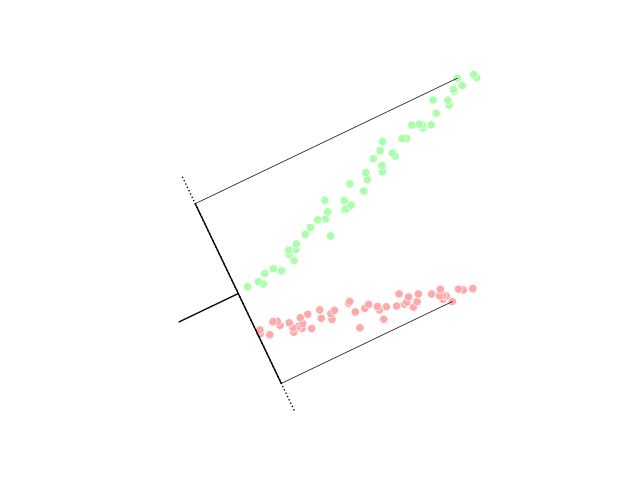
📗 군집화(Clustering)
집단 또는 데이터 요소를 여러 그룹으로 나누어 그룹의 데이터 요소가 다른 그룹의 데이터 요소와 비유사성을 띄도록 하는 작업이며 기본적으로 객체 간의 유사성과 비유사성에 기초한 객체 모음이다.
아래 그래프의 데이터 포인트는 클러스터링되어 각 그룹으로 분류되어 클러스터를 구별 할 수 있다.
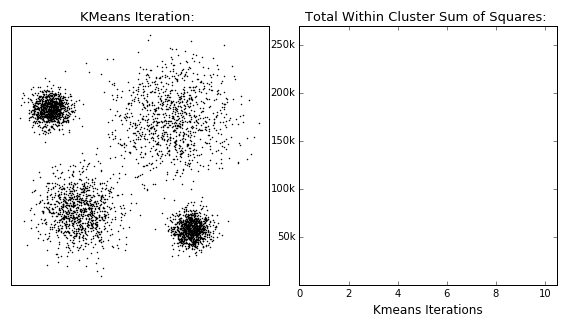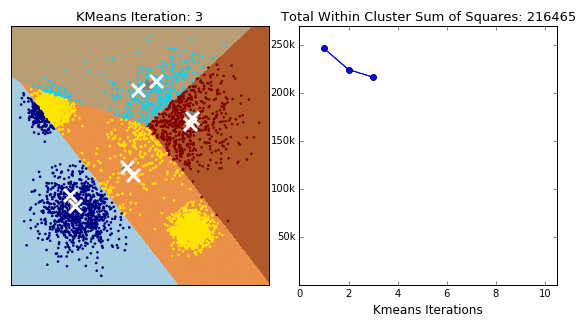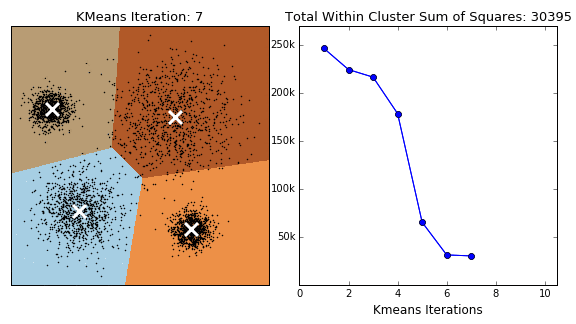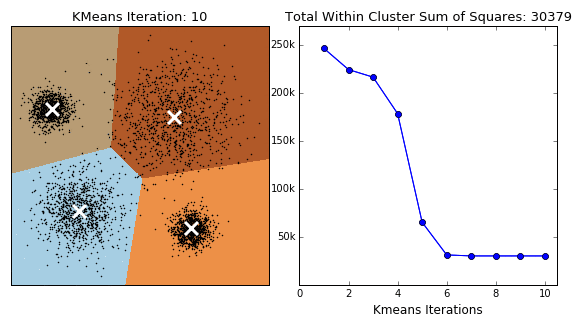
📗 밀도 추정(Density Estimation)
부류(Class)별 데이터를 만들어 냈을 것으로 추정되는 확률 분포를 찾는 것이며 밀도 추정은 각 부류 별로 주어진 데이터를 발생시키는 확률 계산, 가장 확률이 높은 부류로 분류하는 것에 사용된다.
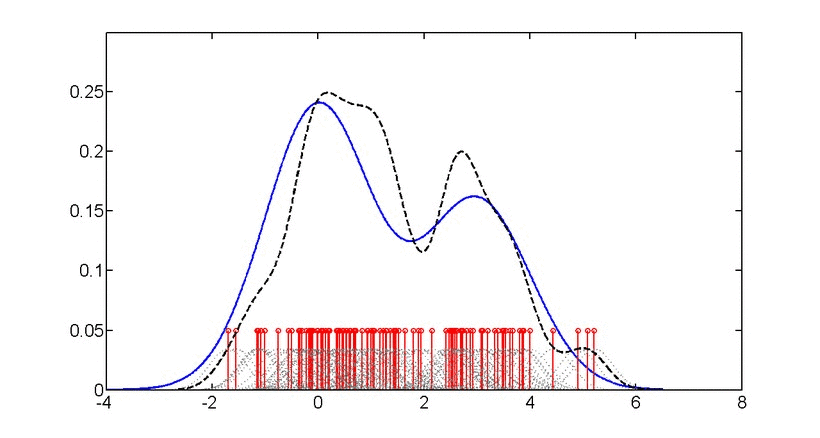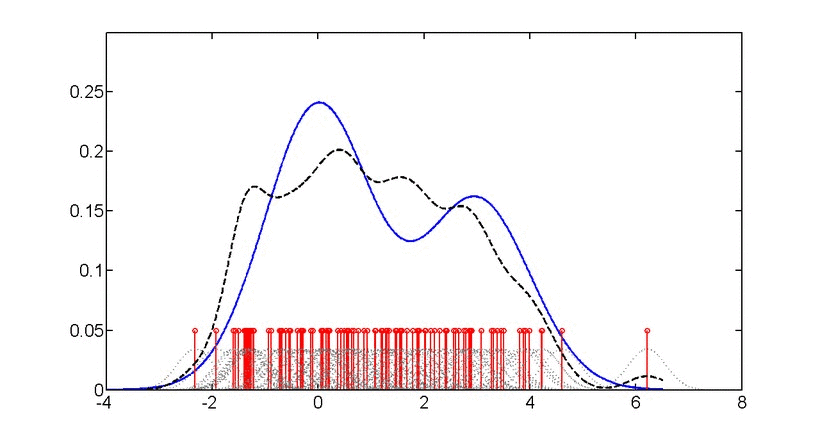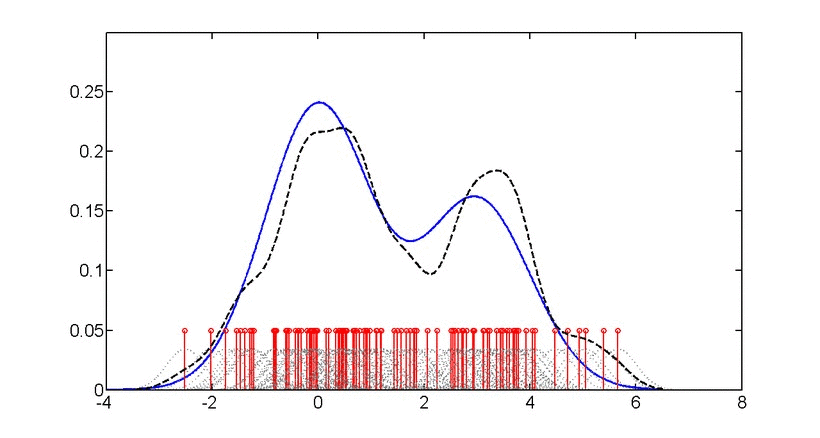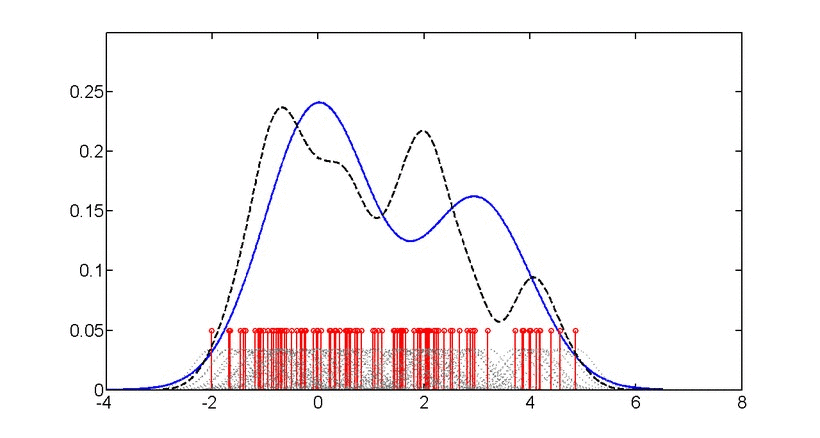
📗 차원 축소(Dimensionality Reduction)
차원이 데이터의 변수의 수를 의미하며 차원이 크면 시각화, 분석이 어렵다. 그래서 이 차원을 줄이는 다향한 기법들을 차원 축소하고 한다. 주성분 부석(Principal Component Analysis;PCA) 대표적인 차원 축소 알고리즘으로 시각화를 위해 사용되며 다차원의 시각화가 가능하다. 몇 개의 포인트가 겹치는 문제점이 발생하는데 이때 정보의 유실이 발생할 수 있다.
📗 연관 규칙 학습(Association Rule Learning)
서로 종속된 항목에서 패턴을 찾고 항목 간의 연결을 매핑하는 규칙 기반의 머신러닝 접근 방식이다. 일반적으로 큰 데이터베이스에서 두 항목이 연결되는 방법과 이유에 대한 관계를 찾는데 사용한다.
아래 사진과 같이 소비자의 행동을 이해한 뒤 다른 관련 있는 제품을 고객에게 맞춤형으로 제공한다,

📙 강화 학습(Unsupervised Learning)
강화 학습(Unsupervised Learning)은 현재의 상태(State)에서 어떤 행동(Action)을 취하는 것이 최적인지를 학습하는 것이다. 행동을 취할 때마다 외부 환경에서 보상(Reward)이 주어지는데, 이러한 보상을 최대화 하는 방향으로 학습이 진행된다. 그리고 이러한 보상은 행동을 취한 즉시 주어지지 않을 수도 있다(지연된 보상). 이 때문에 문제의 난이도가 앞의 두개에 비해 대폭 상승한다.
📗 Agent(행위자)
강화학습의 분류 기준이 되기에 가장 먼저 Agent의 구성 요소에 대해 알아보려 한다. 강화학습의 Agent는 Policy, Value function, Model 세가지의 요소를 갖습니다.
-
Policy
Agent의 행동 패턴으로 상태(state)에서 어떤 행동(action)을 취할지 말해준다.즉 상태를 행동에 연결 짓는 함수인것 이다. 이 함수는 상태에 대해 하나의 행동을 주는 (결정적)과 주어진 상태에 대해 행동들의 분포를 주는 (확률적) 두가지로 나눈다.
:
: -
Value function
상태(State)와 행동(Action)이 나중에 어느 정도의 보상(reward)를 돌려줄지에 대한 함수이다. 해당 상태와 행동을 취했을 때 이후에 받을 모든 보상들의 가중합이라고 하며 뒤에 받을 보상보다 먼저 받을 보상에 대한 선호를 나타내기 위해 를 사용합니다.
-
Model
환경(environment)의 다음 상태(state)와 보상(reward)이 어떨지에 대한 agent의 예상이다. State model과 Reward model로 나눌 수 있다.
📗 Model-Free와 Model-Based
강화학습 알고리즘을 구분짓는 첫번째는 환경(environment)에 대한 model의 존재 여부이다.
model을 갖는 것의 장점은 계획(Planning)을 가능하게 한다는 것이다. 자신의 행동(action)에 따라서 환경이 어쩧게 바뀔지 안다면 실제로 행동학 전에 미리 변화를 예측해보고 최적의 행동을 계획 후 실행할 수 있다.
model을 갖는 것의 단점은 환경의 정확한 model은 보통 알아내기가 어렵거나 불가능하다는 점이다. 혹시라도 model이 환경을 제대로 반영하지 않는다면 이 오류는 그대로 agent의 오류로 이어지게된다. 정확한 model을 만드는 것은 좋은 agent를 만드는 것만큼 또는 더 어려울 수 있습니다.
model을 사용하는 agent를 Model-based라고 부르고 그렇지 않다면 Model-free라고 부른다.
📗 Value-Based와 Policy-Based
강화학습 알고리즘을 구분짓는번째 구분은 value function 또는 policy의 사용 여부이다.
만약 value function이 완벽하다면 최적의 policy는 자연스럽게 얻을 수 있다. 각 상태(state)에서 가장 높은 value를 주는 행동(action)만을 선택하면 된다. 이를 implicit (암묵적인) policy라고 하고 Value function만을 학습하고 policy는 암묵적으로만 갖고 있는 알고리즘들을 value-based agent라고 부른다. DQN 등이 여기에 해당합니다.
반대로 Policy가 완벽하다면 value function은 굳이 필요하지 않다. 결국 value function은 policy를 만들기 위해 사용되는 중간 계산과정일 뿐이며 이처럼 value function이 없이 policy만을 학습하는 agent를 policy-based라고 부릅니다. Policy Gradient 등이 여기에 해당합니다.
Value-based agent : 데이터를 더 효율적으로 활용할 수 있다.
policy-based agent : 원하는 것에 직접적으로 최적화하여 더욱 안정적으로 학습된다.
Actor-Critic agent : Value function과 Policy를 모두 갖고 있는 agent
