
결정트리
1. 데이터 불러오기
import pandas as pd
wine = pd.read_csv('https://bit.ly/wine_csv_data')2. 데이터 확인 및 전처리
- 데이터셋에 대한 정보를 출력하고, 누락된 값이 있는지 확인합니다. 누락된 값이 있을 경우, 처리 방법에 대해 언급하고, 데이터를 넘파이 배열로 변환합니다.
판다스 데이터프레임의 유용한 메서드 2개
info()
- 이 메서드는 데이터프레임의 각 열의 데이터 타입과 누락된 데이터가 있는지 확인하는데 유용합니다.
describe()
- 이 메서드는 열에 대한 간략한 통계를 출력해 줍니다. 최소, 최대, 평균값 등을 볼 수 있습니다
data = wine[['alcohol', 'sugar', 'pH' ]].to_numpy()
target = wine['class'].to_numpy()훈련 세트와 테스트 세트로 나눕니다
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = train_test_split(data, target, test_size=0.2, random_state=42)3. 데이터 표준화
- 데이터를 표준화하기 위해 StandardScaler를 사용하여 특성을 변환합니다. 이 작업은 훈련 세트와 테스트 세트에 모두 적용되어야 합니다.
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
ss.fit(train_input)
train_scaled = ss.transform(train_input)
test_scaled = ss.transform(test_input)4. 로지스틱 회귀 모델 훈련
- 표준화된 데이터를 사용하여 로지스틱 회귀 모델을 훈련합니다.
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()
lr.fit(train_scaled, train_target)훈련된 모델의 성능을 훈련 세트와 테스트 세트에서 평가합니다.
결정 트리 모델은 데이터를 스무고개처럼 질문을 통해 분류하며, 데이터를 잘 나눌 수 있는 질문을 찾아가며 정확도를 높입니다.
사이킷런의 DecisionTreeClassifier 클래스를 사용하여 결정 트리 모델을 훈련합니다.
- 이때, random_state 매개변수를 지정하는 이유는 결정 트리 알고리즘에서 노드에서 최적 분할을 찾기 전에 특성 순서를 무작위로 섞는데, 이로 인해 실행할 때마다 결과가 조금씩 다를 수 있기 때문입니다. 노드의 순서를 일정하게 유지하기 위해 random_state를 설정합니다.
5. 결정 트리 모델 훈련
- 결정 트리 모델을 훈련하기 위해 DecisionTreeClassifier를 사용합니다.
from sklearn.tree import DecisionTreeClassifier
dt = DecisionTreeClassifier(random_state=42)
dt.fit(train_scaled, train_target)결정 트리 모델의 훈련 세트와 테스트 세트에서의 성능을 평가합니다.
6. 결정 트리 시각화
결정 트리를 시각화하기 위해 plot_tree() 함수를 사용합니다
import matplotlib.pyplot as plt
from sklearn.tree import plot_tree
plt.figure(figsize=(10,7))
plot_tree(dt, max_depth=1, filled=True, feature_names=['alcohol', 'sugar', 'pH'])
plt.show()밑 결과를 통해 트리의 구조 및 각 노드에서 수행되는 분류 기준을 시각적으로 파악할 수 있습니다.
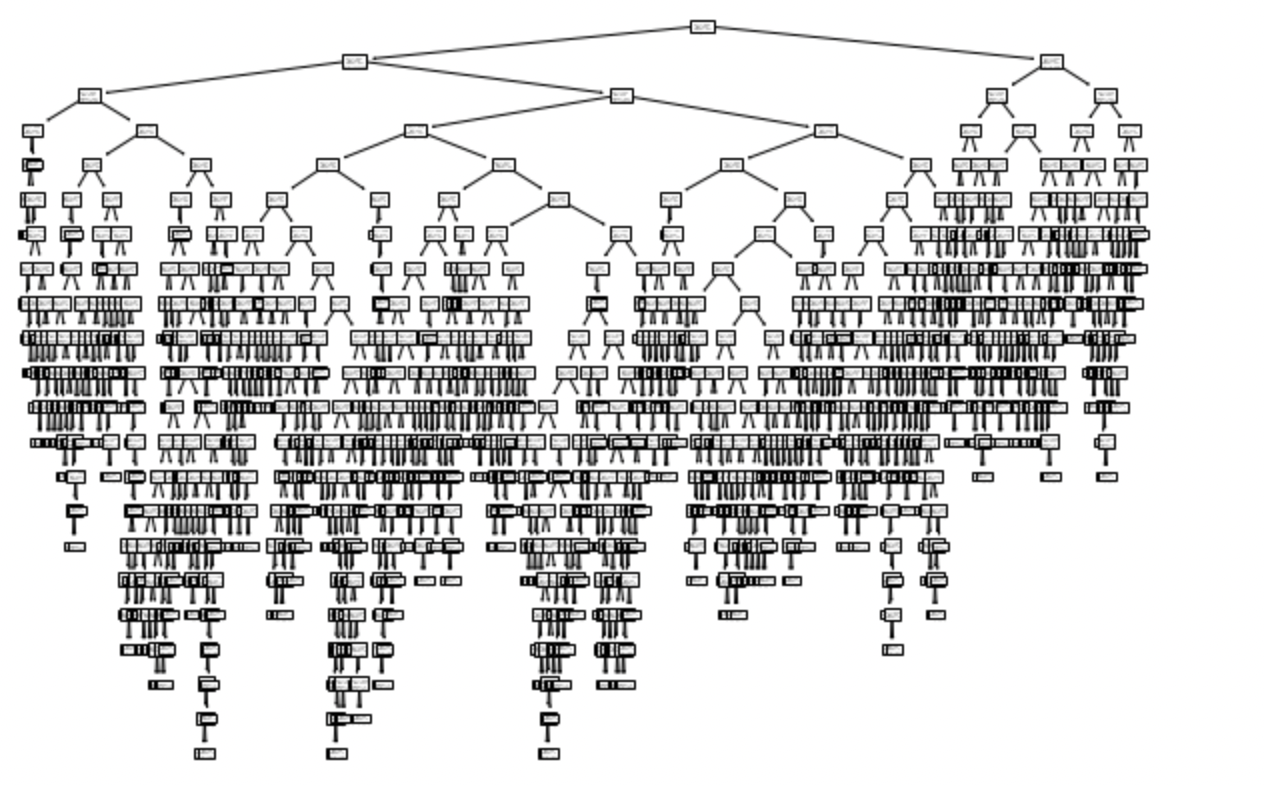
결정 트리 모델은 노드와 가지로 구성되며, 노드에서 특정 조건을 검사하고 그 결과에 따라 가지를 따라 이동합니다. 일반적으로 하나의 노드는 2개의 가지를 가지게 됨
노드(node) - 특성에 대한 테스트를 수행
- 루트 노드(root node)는 맨 위에 위치하며, 리프 노드(leaf node)는 트리의 맨 아래에 위치합니다
가지(branch) - 테스트 결과를 나타냄
트리의 시각화
결정 트리를 시각화하려면 plot_tree() 함수를 사용할 수 있습니다. 이 함수를 통해 트리의 깊이를 제한하고, 노드의 색을 클래스에 따라 칠할 수 있습니다. 또한 feature_names 매개변수를 사용하여 특성의 이름을 표시할 수 있습니다.
plt.figure(figsize=(10, 7))
plot_tree(dt, max_depth=1, filled=True, feature_names=['alcohol', 'sugar', 'pH'])
plt.show()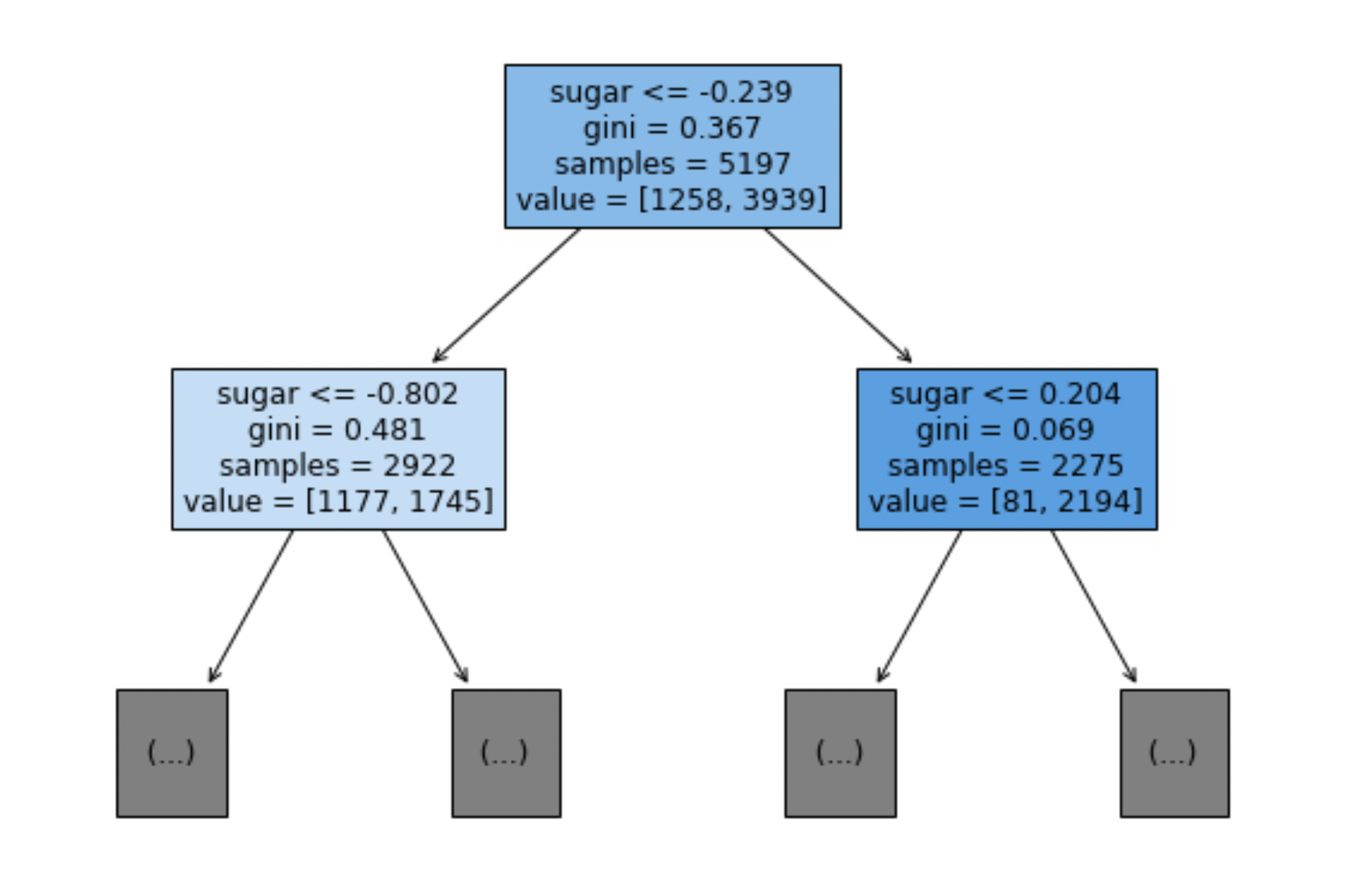
불순도
결정 트리에서 노드를 나누는 기준은 불순도입니다. 불순도는 노드의 클래스 분포의 혼잡도를 나타내며, 주요한 기준으로는 지니 불순도(Gini impurity)와 엔트로피 불순도(Entropy impurity)가 있습니다.
-
지니 불순도(Gini impurity): 클래스 비율의 제곱을 더한 다음 1에서 뺀 값으로 계산됩니다. 결정 트리의 기본 불순도 지표입니다.
-
엔트로피 불순도(Entropy impurity): 클래스 비율을 밑이 2인 로그로 곱하여 계산합니다.
불순도의 차이를 계산하여 정보 이득(Information Gain)을 최대화하기 위해 데이터를 분할합니다. 정보 이득은 부모 노드와 자식 노드 간의 불순도 차이로 정의됩니다.
결정 트리는 데이터를 분할하기 위해 불순도를 기준으로 사용하며, 정보 이득을 최대화하도록 노드를 분할합니다. 이를 시각화하여 노드의 특성과 클래스 분포를 살펴볼 수 있습니다.
가지치기
가지치기는 결정 트리에서 모델의 일반화 성능을 향상시키기 위한 중요한 기술입니다. 결정 트리의 가지치기는 트리의 최대 깊이를 제한하여 모델을 더 간결하게 만드는 방법 중 하나입니다. 이를 통해 훈련 세트에 과적합되는 것을 방지할 수 있습니다.
dt = DecisionTreeClassifier(max_depth=3, random_state=42)
dt.fit(train_scaled, train_target)
- 가지치기 후 모델의 성능은 훈련 세트에서는 낮아질 수 있지만 테스트 세트에서는 더 좋은 성능을 얻을 수 있습니다. 이것을 일반화라고 합니다.
import matplotlib.pyplot as plt
from sklearn.tree import plot_tree
plt.figure(figsize=(20,15))
plot_tree(dt, filled=True, feature_names=['alcohol', 'sugar', 'pH'])
plt.show()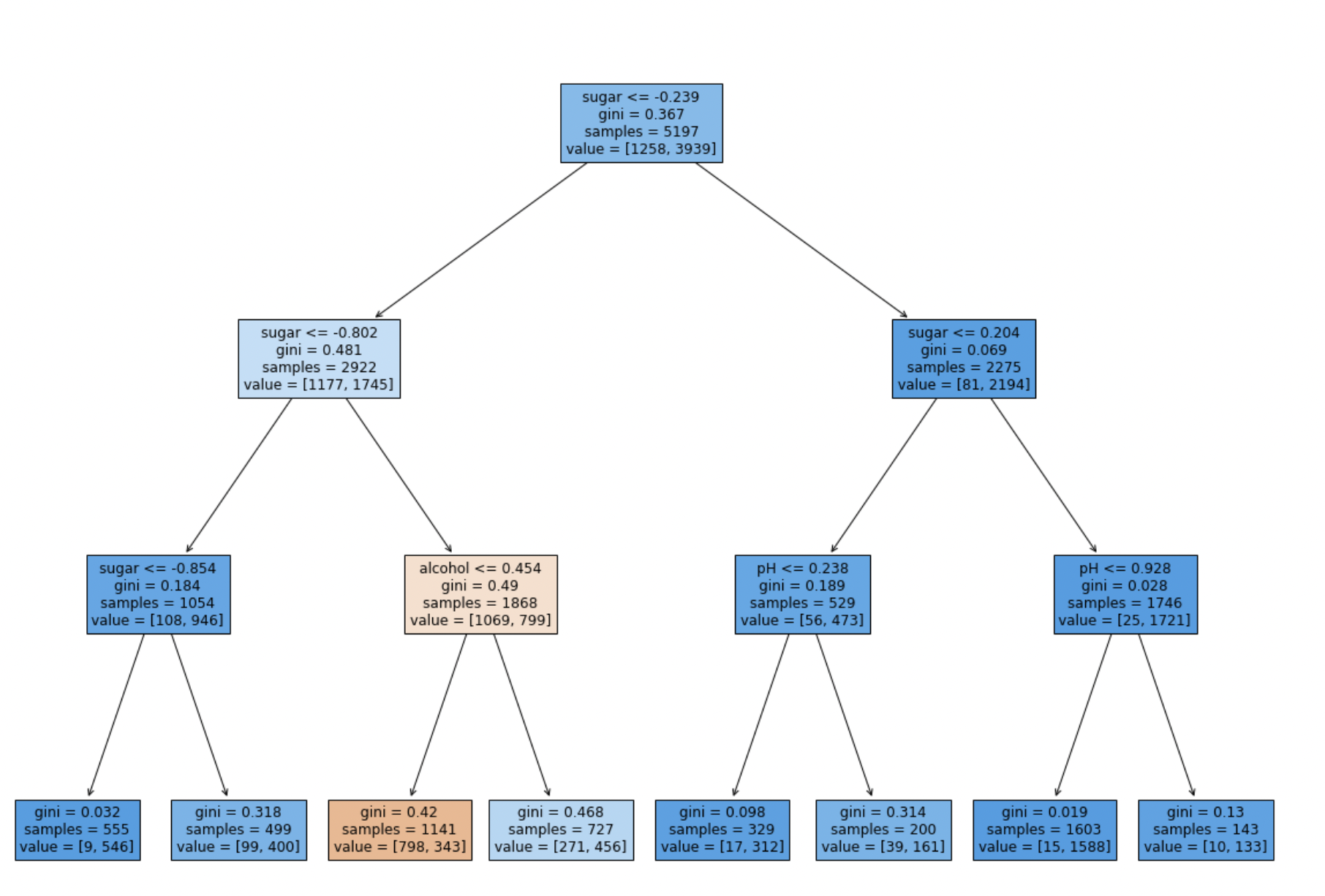
이를 통해 루트 노드부터 리프 노드까지의 경로를 시각적으로 확인할 수 있습니다.
특성 중요도
결정 트리 모델은 각 특성의 중요도를 계산해줍니다. 특성 중요도는 각 노드의 정보 이득과 전체 샘플에 대한 비율을 곱한 후 특성별로 더하여 계산합니다. 중요도는 트리 노드에서 분기하는 결정에 특성이 얼마나 기여하는지를 나타냅니다.
print(dt.feature_importances_)특성 중요도를 통해 어떤 특성이 모델에서 가장 유용한 역할을 하는지 확인할 수 있으며, 이를 통해 특성 선택에 활용할 수 있습니다.
교차 검증과 그리드 서치
검증 세트(Validation Set)
- 데이터 세트를 학습 세트와 검증 세트, 테스트 세트로 나누어 테스트 세트에 과적합한 모델이될 가능성을 낮출 수 있습니다
훈련 세트의 입력 데이터와 타깃 데이터를 train_input과 train_target배열에 저장하고
그 다음 train_input과 train_target을 다시 train_test_split() 함수에 넣어 훈련 세트 sub_input, sub_target과 검증 세트 val_input, val_target을 만듭니다.
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = train_test_split(data, target, test_size=0.2, random_state=42)
sub_input, val_input, sub_target, val_target = train_test_split(train_input, train_target, test_size=0.2, random_state=42)dt = DecisionTreeClassifier(random_state=42)
dt.fit(sub_input, sub_target)
print(dt.score(sub_input, sub_target))
print(dt.score(val_input, val_target))검증 세트의 성능을 평가하고 모델이 과대적합되었다면, 매개변수를 조정하여 더 나은 모델을 찾을 수 있습니다.
반복적으로 모델을 훈련하고 검증 세트를 사용하여 성능을 평가하며 매개변수를 조정합니다.
교차 검증(Cross Validation)
- 모델의 성능을 안정적으로 평가하고 최적의 매개변수를 찾는 데 도움이 되는 기술
역할
- 검증 세트를 나누는 과정에서 훈련 세트의 크기가 감소하는 문제를 극복하고 모델의 안정적인 성능 평가를 가능하게 합니다.
- 모델의 성능을 여러 번 측정하여 평균을 계산해 최종 성능을 얻습니다.
종류
- 3-폴드, 5-폴드, 10-폴드 교차 검증 등 여러 종류가 있으며, 보통 5-폴드나 10-폴드 교차 검증을 많이 사용합니다.
사이킷런의 교차 검증 함수
- cross_validate() 함수를 사용하여 교차 검증을 수행할 수 있습니다.
- cross_val_score() 함수는 cross_validate() 함수의 결과 중 test_score 값만 반환합니다.
from sklearn.model_selection import cross_validate
from sklearn.model_selection import StratifiedKFold
from sklearn.tree import DecisionTreeClassifier
dt = DecisionTreeClassifier(random_state=42)
scores = cross_validate(dt, train_input, train_target, cv=StratifiedKFold())
print(np.mean(scores['test_score']))교차 검증에서 훈련 세트를 섞지 않고 사용하려면 기본적으로 StratifiedKFold(분류 모델) 또는 KFold(회귀 모델)를 사용합니다.
k-폴드 교차 검증 (k-fold cross validation)
- 훈련 세트를 k 부분으로 나눠서 교차 검증을 수행하는 것.
훈련 세트를 섞어서 사용하려면 분할기(splitter)를 지정해야 합니다.
from sklearn.model_selection import KFold
scores = cross_validate(dt, train_input, train_target, cv=StratifiedKFold())
splitter = StratifiedKFold(n_splits=10, shuffle=True, random_state=42)
scores = cross_validate(dt, train_input, train_target, cv=splitter)
print(np.mean(scores['test_score']))하이퍼파라미터 튜닝
모델 파라미터: 머신러닝 모델이 학습하는 파라미터
파라미터(parameter, 매개변수): 학습 과정에서 생성되는 변수
하이퍼파라미터: 머신러닝 모델이 학습할 수 없어서 사용자가 지정해야만 하는 파라미터 (사람의 개입 없이 하이퍼파라미터를 자동으로 튜닝하는 기술을 'AutoML' 이라고 합니다)
그리드 서치 (Grid Search)
- 하이퍼파라미터 탐색을 자동화해 주는 도구
- 탐색과 교차 검증을 한 번에 수행
- 탐색할 매개변수를 지정합니다.
- 그리드 서치를 수행하여 최상의 평균 검증 점수가 나오는 매개변수 조합을 찾습니다.
- 그리드 서치는 최상의 매개변수에서 전체 훈련 세트를 사용해 최종 모델을 훈련합니다.
- 사이킷런의 GridSearchCV 클래스를 사용하면 그리드 서치를 간단히 수행할 수 있습니다.
from sklearn.model_selection import GridSearchCV
params = {'min_impurity_decrease': [0.0001, 0.0002, 0.0003, 0.0004, 0.0005]}
gs = GridSearchCV(DecisionTreeClassifier(random_state=42), params, n_jobs=-1)
gs.fit(train_input, train_target)
dt = gs.best_estimator_
best_index = np.argmax(gs.cv_results_['mean_test_score'])
print(gs.cv_results_['params'][best_index])GridSearchCV 클래스를 사용하여 최적의 매개변수를 탐색하고, 최상의 매개변수, 모델, 및 교차 검증 점수를 얻을 수 있습니다.
랜덤 서치 (Random Search)
- 연속적인 매개별수 값을 탐색할 때 유용
- 랜덤 서치에는 매개변수 값의 목록을 전달하는 것이 아니라 매개변수를 샘플링할 수 있는 확률 분포 객체를 전달
가능한 모든 조합을 시도하는 대신 각 반복마다 하이퍼파라미터에 랜덤으로 대입하여 지정한 횟수만큼 평가.
먼저, SciPy 라이브러리에서 uniform과 randint 클래스를 임포트합니다. 이 두 클래스는 주어진 범위에서 값들을 균등하게 샘플링할 수 있습니다.
싸이파이(scipy)는 어떤 라이브러리인가
- 싸이파이는 파이썬의 핵심 과학 라이브러리 중 하나이다. 적분, 보간, 선형대수, 확률 등을 포함한 수치 계산 전용 라이브러리이다. 사이킷런은 넘파이와 싸이파이 기능을 많이 사용한다.
from scipy.stats import uniform, randintuniform 클래스는 주어진 범위 내에서 실수 값을 샘플링하고, randint 클래스는 정수 값을 샘플링합니다. 예를 들어, 0에서 10 사이의 정수를 랜덤하게 샘플링해보겠습니다.
rgen = randint(0, 10)
samples = rgen.rvs(10)여기서 rvs 메서드는 지정한 횟수만큼 샘플링하여 배열로 반환합니다. 샘플링 결과는 무작위성에 따라 다를 수 있습니다.
uniform 클래스의 사용법도 동일하며, 0에서 1 사이의 실수를 샘플링해보겠습니다.
ugen = uniform(0, 1)
samples = ugen.rvs(10)샘플링 결과는 0과 1 사이의 임의의 실수입니다. 랜덤 서치는 이러한 확률 분포 객체를 활용하여 매개변수 값을 샘플링하고 교차 검증을 수행하여 최적의 매개변수 조합을 찾는 방식으로 동작합니다.
랜덤 서치의 사용
params = {
'min_impurity_decrease': uniform(0.0001, 0.001),
'max_depth': randint(20, 50),
'min_samples_split': randint(2, 25),
'min_samples_leaf': randint(1, 25),
}랜덤 서치를 설정한 매개변수와 샘플링 횟수를 이용하여 수행합니다.
from sklearn.model_selection import RandomizedSearchCV
rs = RandomizedSearchCV(DecisionTreeClassifier(random_state=42), params, n_iter=100, n_jobs=-1, random_state=42)
rs.fit(train_input, train_target)랜덤 서치는 총 100번(n_iter 매개변수) 샘플링하여 교차 검증을 수행하고 최적의 매개변수 조합을 찾습니다. 결과를 확인하기 위해 최적의 매개변수와 교차 검증 점수를 출력합니다.
best_params = rs.best_params_
best_score = np.max(rs.cv_results_['mean_test_score'])랜덤 서치는 랜덤하게 샘플링하기 때문에 실행할 때마다 결과가 조금씩 다를 수 있습니다.
트리의 앙상블
정형 데이터(structure data)
- csv파일처럼 가지런히 정리되어 있는 데이터
비정형 데이터(unstructured data)
- 텍스트, 이미지, 영상, 음악 등 DB로 표현하기 어려운 데이터
앙상블 학습(ensemble learning)
- 정형데이터에서 가장 뛰어난 알고리즘
- 결정트리를 기반
랜덤 포레스트 (random forest)
- 각 트리를 훈련하기 위해 부트스트랩 방식으로 데이터를 생성하며, 이는 입력된 훈련 데이터에서 중복된 샘플을 허용하여 추출하는 방식
- 랜덤하게 선택한 샘플과 특성을 사용하기 때문에 훈련 세트에 과대적합되는 것을 막아주고 검증 세트와 테스트 세트에서 안정적인 성능을 얻을 수 있습니다
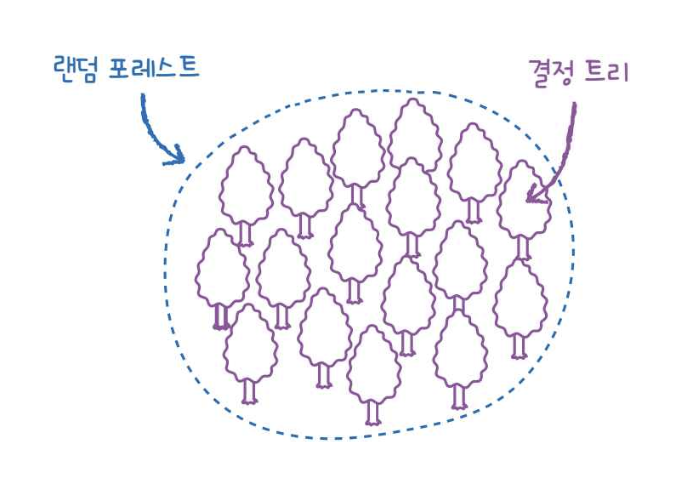
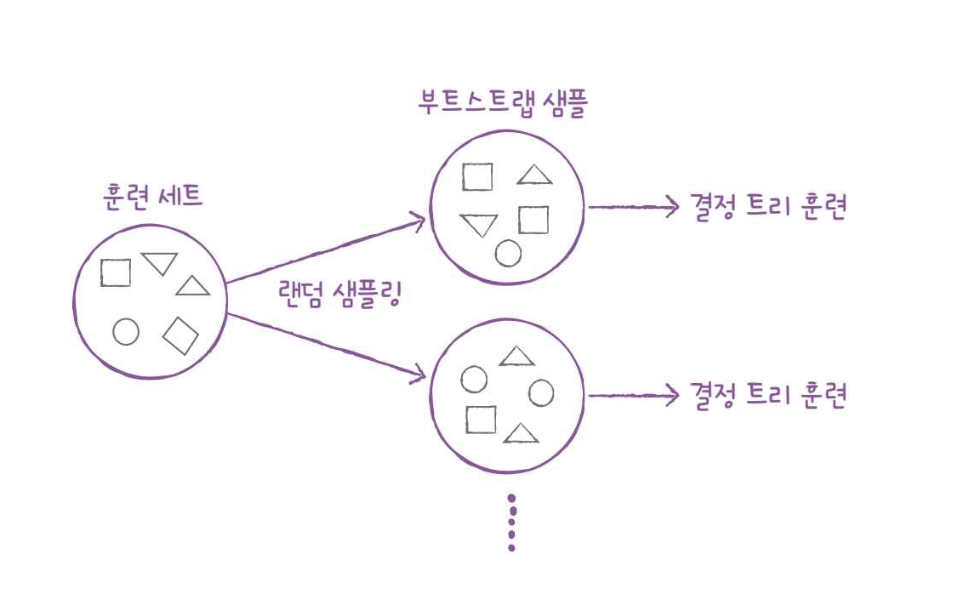
부트스트랩(bootstrap)
- 데이터 세트에서 중복을 허용하여 데이터를 샘플링하는 방식을 의미
- 1,000개의 샘플이 있을 때 먼저 1개를 뽑고, 다시 가방에 넣어 그다음 샘플을 뽑는 방식. 부트스트랩 샘플이란 결국 부트스트랩 방식으로 샘플링하여 분류한 데이터라는 의미!
- OOB(Out Of Bag) 샘플
-부트스트랩 샘플에 포함되지 않고 남는 샘플
-이 샘플을 이용하여 부트스트랩 샘플로 훈련한 결정 트리 평가 가능.(검증 세트의 역할)
rf = RandomForestClassifier(n_jobs=-1, random_state=42)
scores = cross_validate( rf, train_input, train_target,return_train_score=True, n_jobs=-1)객체를 생성하고 cross_validate()함수를 사용하여 교차 검증을 수행하였습니다.
훈련 세트와 검증 세트의 점수를 비교하면 과대적합을 파악하는데 용이합니다
rf = RandomForestClassifier(oob_score=True, n_jobs= -1, random_state=42)
rf.fit(train_input, train_target)RandomForestClassifier의 oob_score 매개변수를 활용하여 OOB (out of bag) 점수를 계산하였습니다.
OOB 점수를 사용하면 교차 검증을 대신할 수 있어서 결과적으로 훈련 세트에 더 많은 샘플을 사용할 수 있습니다.
엑스트라 트리 (Extra Tree)
- 랜덤 포레스트와 동일한 점.
- 결정 트리가 제공하는 대부분의 매개변수를 지원함.
- 전체 특성 중 일부 특성을 랜덤하게 선택하여 노드를 분할하는데 사용함.- 랜덤하게 노드 분할하기 때문에 계산속도가 빠름.
- 랜덤하게 노드 분할하기 때문에 계산속도가 빠름.
- 랜덤 포레스트와 차이점.
- 랜덤포레스트는 부트스트랩 샘플을 사용하는 반면, 엑스트라 트리는 부트스트랩 샘플을 사용하지 않음.
- 즉, 각 결정 트리를 만들 때 전체 훈련 세트를 사용함.
- 보통 엑스트라 트리가 무작위성이 좀 더 크기 때문에 랜덤 포레스트보다 더 많은 결정 트리를 훈련해야 함.
랜덤 포레스트
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(n_jobs=-1, random_state=42)
scores = cross_validate(rf, train_input, train_target,
return_train_score=True, n_jobs=-1)
print(np.mean(scores['train_score']), np.mean(scores['test_score']))훈련 세트: 0.9973541965122431, 검증 세트: 0.8905151032797809
엑스트라 트리
from sklearn.ensemble import ExtraTreesClassifier
et = ExtraTreesClassifier(n_jobs=-1, random_state=42)
scores = cross_validate(et, train_input, train_target,
return_train_score=True, n_jobs=-1)
print(np.mean(scores['train_score']), np.mean(scores['test_score']))훈련 세트: 0.9974503966084433, 검증 세트: 0.8887848893166506
랜덤 포레스트와 엑스트라 트리의 결과는 비슷하며, 데이터셋이 간단한 경우 큰 차이를 보이지 않습니다. 엑스트라 트리가 조금 더 무작위성이 크기 때문에 더 많은 결정 트리를 훈련해야 할 수 있습니다.
그레이디언트 부스팅(Gradient Boosting)
- 깊이가 얕은 결정 트리를 사용하여 이전 트리의 오차를 보완하는 방식으로 앙상블하는 방법
- 길이가 얕은 결정 트리를 사용하기에 과대적합에 강하고 일반적으로 높은 일반화 성능을 기대할 수 있음. - default depth = 3 이며 결정트리 100개를 사용
- 경사하강법을 사용하여 분류에서는 로지스틱 손실 함수를 사용하고 회귀에서는 평균제곱오차함수를 사용
subsample 매개변수
- 그레이디언트 부스팅의 트리 훈련에 사용할 훈련 세트의 비율을 조절
- 이 매개변수의 기본값은 1.0으로 전체 훈련 세트를 사용
- 하지만 subsampled 1보다 작으면 훈련 세트의 일부를 사용. 마치 경사 하강법 단계마다 일부 샘플을 랜덤하게 선택하여 진행하는 확률적 경사 하강법이나 미니배치 경사 하강법과 비슷
히스토그램 기반 그레이디언트 부스팅 (Histogram based Gradient Boosting)
- 정형 데이터를 다루는 머신러닝 알고리즘 중에서 가장 인기가 높은 알고리즘 중 하나
- 입력 특성을 256개의 구간으로 나누어 먼저 전처리를 진행함으로써 노드를 분할할 때 최적의 분할을 빠르게 찾을 수 있습니다
- 트리의 개수를 지정하는데 n_estimators 대신에 부스팅 반복 횟수를 지정하는 max_iter를 사용
