
04-1 로지스틱 회귀
문제 배경 설명과 k-최근접 이웃 분류 알고리즘으로 접근
생선의 (길이, 높이, 두께 ...등) 7가지 특성으로 이 생선이 어느 생선일지 확률을 구하는 문제를 가정해보자.
이전에 배웠던 k-최근접 이웃 분류 알고리즘에서, 이웃의 클래스를 알 수 있었다. 그렇기에 이웃의 클래스 비율을 확률이라고 가정하면? 문제가 매우 쉬워진다.
csv파일은 판다스의 pd.read_csv('https...')로 받고 이것은 데이터프레임이다.
데이터프레임은 to_numpy() 함수로 넘파일 배열로 변경하여 sklearn에서 활용해야 한다.
다음은 표준점수로 전처리하는 방법인데, 핵심은 # 훈련 세트의 통계 값으로 테스트 세트를 변환해야 한다. 기껏 훈련한 모델이 쓸모 없게 되므로! 전에 배웠던 건데 까먹어서 적으면서 기억하기!
from sklearn.preprocessing import StandardScaler
std = StandardScaler()
std.fit(X_train)
X_train_scaled = std.transform(X_train)
X_test_scaled = std.transform(X_test)
dtc.fit(X_train_scaled, y_train)
print('모델의 정확도 :', round(dtc.score(X_test_scaled, y_test), 4))그리고 주변 이웃의 비율에 따라 확률 구하는 함수는 다음과 같다.
kn.predict_proba(test_data)
그러나, K-최근접 이웃 분류 알고리즘은 이웃의 개수가 3개, 4개, 등등 정해져있기에 1/3, 2/3, 3/3 확률 밖에 안나온다. 즉, 확률이라고 말하기 애~매하다.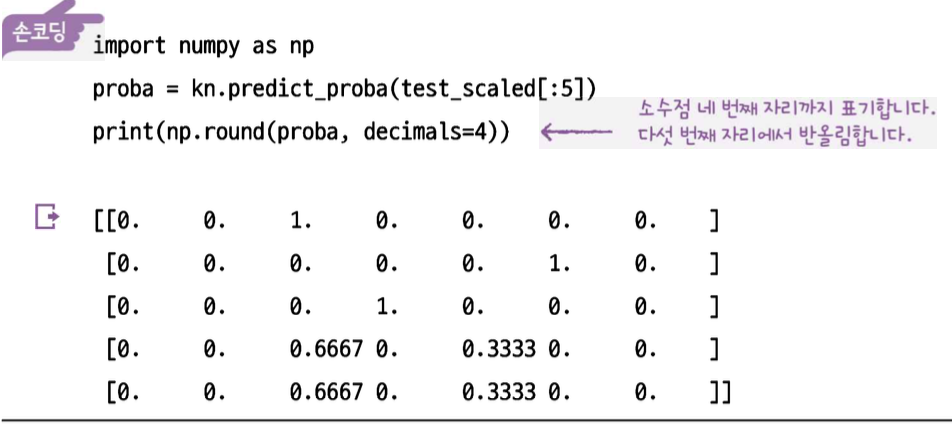
로지스틱 회귀 알고리즘으로의 접근
그래서 로지스틱 회귀 알고리즘으로 갈아탔다.
로지스틱 회귀: 선형 방정식을 사용한 분류 알고리즘. 선형 회귀랑 똑같이 선형 방정식을 활용하지만 분류 모델이다. 선형 회귀와 달리 시그모이드 함수나 소프트맥스 함수를 사용하여 클래스 확률을 출력할 수 있다.
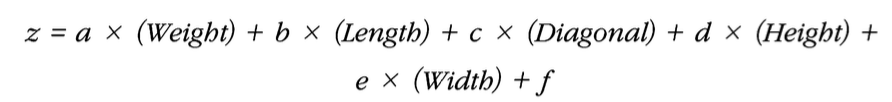
이진 분류부터 시작
시그모이드 함수란(또는 로지스틱 함수) 선형 방정식의 출력을 0과 1 사이 범위의 값으로 압축하며 이진(또는 더 많은) 분류를 위해 사용하는 함수이다. spipy라이브러리의 expit(lr.decision_function(test_data)) 명령어를 통해 z값을 넣고 시그모이드 함숫값을 알 수 있다.
이진 분류라면 0.5 이상이면 1, 이하면 0으로 표현하여 확률을 0%에서 100%까지 나타낼 수 있는 것이다!
lr.predict_proba(test_data) 훈련까지는 똑같고 확률 보기는 똑같은 메서드 써서 나타내면 이번에는 매우 잘 나온 확률을 확인해볼 수 있다! 이건 이진 분류의 예시.
다중 분류로 마무리
다중분류로 바꾸려면?
로지스틱 회귀 모델은 데이터를 보고 예측을 잘 할 수 있도록 '학습'을 하는데, 이 학습 과정에서 여러 번 반복을 거칩니다. 이 반복을 통해 모델이 예측을 잘하기 위한 '최적의 값'을 찾게 됩니다.
그런데 이 반복 횟수가 너무 적으면, 모델이 충분히 학습하지 못해서 예측이 정확하지 않게 됩니다. 지금 책에서 언급한 기본 반복 횟수는 100번인데, 이게 데이터의 복잡성에 비해 부족할 수 있어요. 그래서 100번만 반복했을 때 모델이 아직 최적의 상태에 도달하지 못했다는 '경고'가 뜨는 거예요.
라는 chatgpt의 말처럼 max_iter를 1000으로 늘리고,
규제를 해주는 이유: 과적합 방지
규제를 완화해주는 이유: 과소적합 방지
이므로 규제를 완화 해준다.
해결 방법으로 반복 횟수를 더 늘려서(예를 들어 1000번으로) 모델이 충분히 학습할 시간을 주는 거죠.
소프트 맥스 함수는? 다중 분류에서의 시그모이드 함수(로지스틱 함수). 사용법은 scipy 라이브러리의 softmax(lr.decision_function(test_data), axis=1)이고 axis가 1이므로 각 행, 즉 각 샘플에 대한 소프트맥스를 계산하는 셈이다.

04-2 확률적 경사 하강법 Stochastic Gradient Descent
확률적 경사 하강법: 대표적인 점진적 학습이다. 샘플이 계속 추가될 때마다 최적의 모델을 위해 매번 새로운 학습을 하면 비효율적이므로 점진적 학습을 활용.
방법은 이렇다. 훈련 세트에서 샘플을 하나씩 꺼내 손실 함수의 경사를 따라 내려오며 최적의 모델을 찾는 것이다.
샘플을 하나씩 사용하지 않고 여러개를 사용하면 미니배치 경사 하강법이 됨. <- 실전 활용
한번에 전체 샘플을 사용하면 배치경사 하강법이 됨.
손실 함수: 확률적 경사 하강법이 최적화할 대상. 문제 별로 다른 손실함수가 정해져 있음. 미분가능해야한다. 왜냐면 확률적 경사 하강법에서는 기울기(변화량)을 통해 경사를 내려오기 때문이다.
- 이진 분류 -> 로지스틱 손실함수 = 이진 크로스엔트로피 손실 함수
- 다중 분류 -> 크로스엔트로피 손실 함수
- 회귀 -> 평균 제곱 오차
에포크 : 확률적 경사 하강법에서 전체 샘플을 모두 사용하는 한 번 반복을 의미
잊지 말자!!!
확률적경사하강법을꼭사용하는알고리즘이있습니다. 바로신경망알고리즘입니다. 신경망은일반적으로많은데이터 를사용하기때문에한번에모든데이터를사용하기어렵습니다. 또모델이매우복잡하기때문에수학적인방법으로해 답을얻기어렵습니다. 신경망모델이확률적경사하강법이나미니배치경사하강법을사용한다는점을꼭기억하세요.
SGDClassifier로 점진적 학습을 위한 확률적 경사하강법 활용해보기
sc = SGDClassifier(loss='log', max_iter=100, tol=None)에서 tol은 tolerance의 약자이며 오차범위를 뜻한다. SGDClassifier는 에포크 반복 동안 성능 개선이 없으면, 즉 현재loss > 최저loss - tol인 경우 학습을 멈추는 경향이 있는데 지멋대로 멈추지 마라고 할 때 tol=None을 해준다.
