01. Compiler Construction

1. Why Compilers?
- Compiler
- 한 언어에서 다른 언어로 번역하는 프로그램
- 소스의 의미를 보존해야한다.
- 타겟 언어의 효율적인 버전을 생성해야한다.
- 컴퓨팅의 초기에는 machine language가 있었다.
- Ugly - writing code, debuging
- 그 다음으로, 텍스트 기반 어셈블리가 등장 했고, DSPs에 여전히 사용된다.
- High-level languages - Fortran, Pascal, C, C++
- 기계 구조가 너무 복잡해지고 소프트웨어 관리가 저수준 언어로는 너무 어려워져서 고수준 언어로 이동하게 되었다.
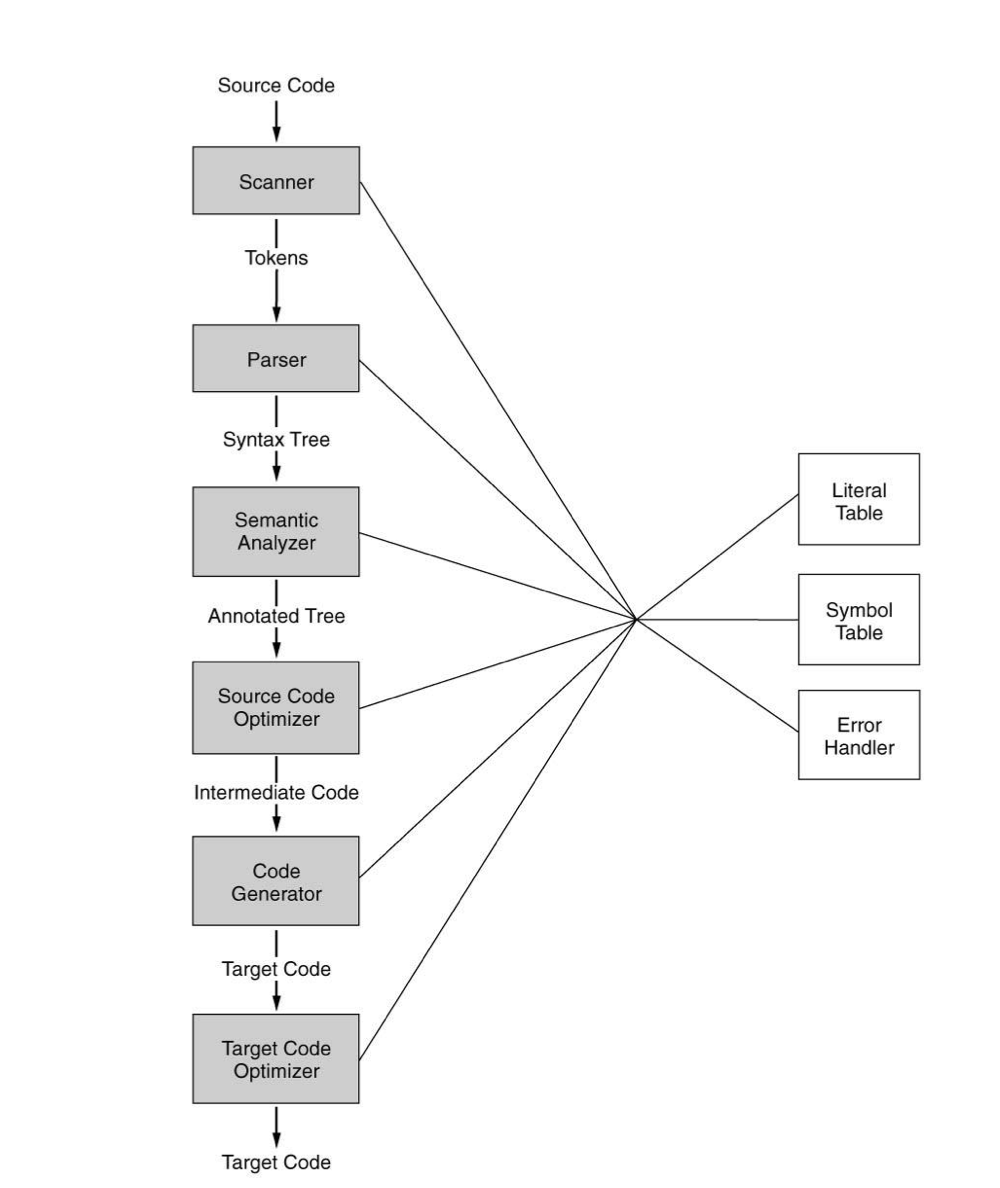
1) Compiler Structure
- Source language
- Fortran, Pascal, C, C++
- Verilog, VHDL, Tex, Html
- Target language
- Machine code, assembly
- High-level languages, simply actions
- Compile time vs run time
- Compile time or statically - Positioning of variables
- Run time or dynamically - stack values, heap allocation
2) Why compilers? A brief history
- Machine language
- Ex> C7 06 0000 0002
- 읽고 쓰는 것이 어렵다.
- 한 컴퓨터에서 쓰인 코드가 다른 컴퓨터에서 다시 쓰여야만 한다.
- Assembly language
- Ex> MOV X, 2
- machine language보다 더 쉽다.
- 여전히 읽고 쓰는 것이 어렵다.
- 특정한 machine에 극도로 의존적이다.
- 한 컴퓨터에서 쓰인 코드가 다른 컴퓨터에서 반드시 다시 쓰여야만 한다.
- High-level language
- X = 2
- 거의 수학적 표기법 또는 자연 언어와 유사하다.
- 기계에 독립적이다.
- 우려 사항들이 있었는데,
- 구현이 불가 할 수도 있다.
- 그리고, obj code가 너무 비효율적이기에 사용할 수 없을 것이라는 것이다.
- 그래서 컴파일러 이론이 필요하다.
- Chomsky hierarchy
- grammar들의 복잡성에 따라 분류한다.
- type 0 ~ type 3
- type 2, or context-free, grammars
- 꽤 parsing problem의 완벽한 해결책으로 찾아졌다.
- finite automata and regular expressions
2. General Structure of a Modern Compiler
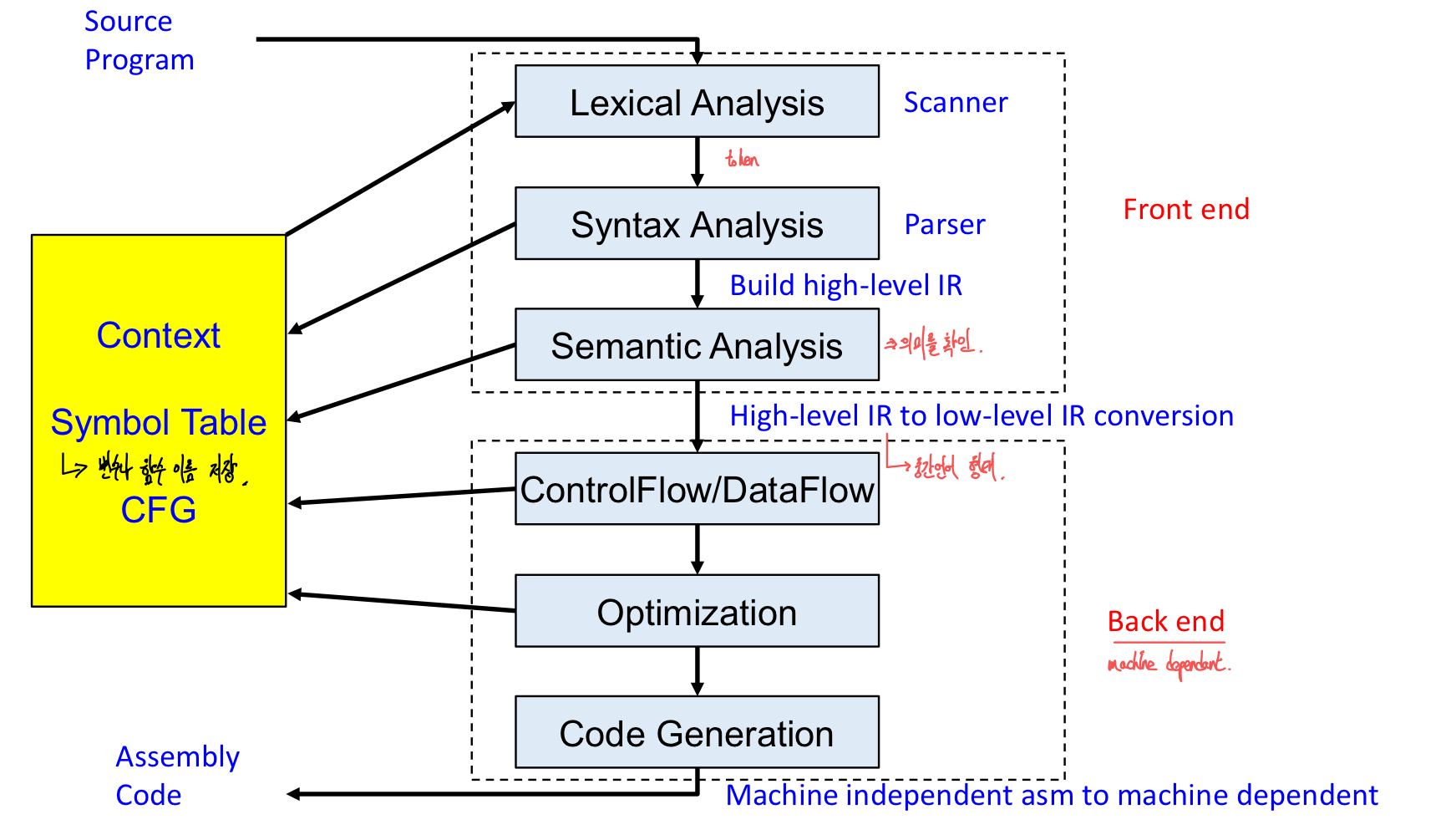
1) Lexical Analysis (Scanner)
- Source stream으로 부터 가장 낮은 수준의 lexical elements를 추출하고 식별한다.
- Reserved words: for, if, switch
- Identifiers: “i”, “j”, “table”
- Constants: 3.14159, 17, “%d\n”
- Punctuation symbols: “(”, “)”, “,”, “+”
- Stream에서 문법 요소가 아닌 것을 제거한다 - i.e. spaces, comment
- Finite state Automata (FSA)로 구현이 된다.
- state의 집합 - 부분 입력들
- state들을 이동하기 위한 Transition functions
a) Examples

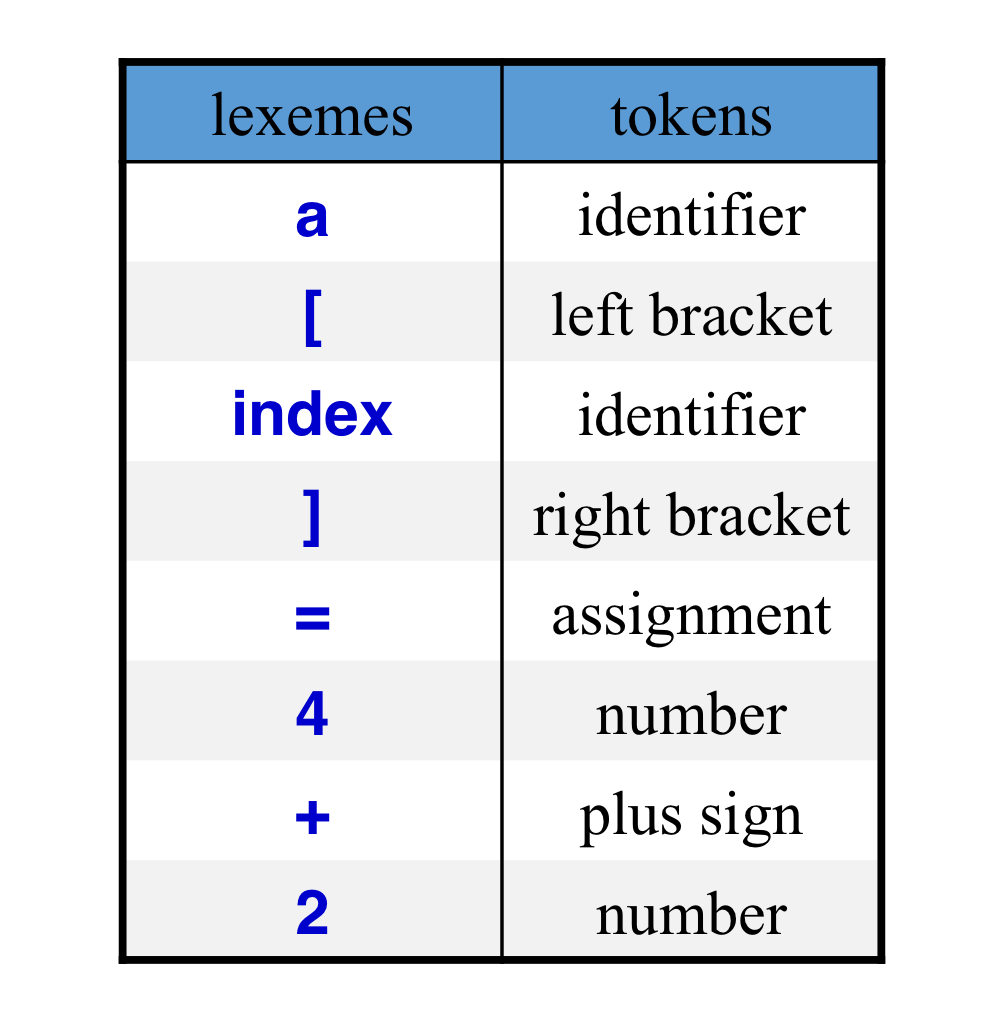
b) Lexical Analysis (Scanning)
- Source program → lexemes → tokens
- Lexemes: 의미 있는 unit들의 최소 단위
- a[index] = 4 + 2 → a / [ / index / ] / = / 4 / + / 2
- 자연어의 단어들과 비슷하다.
- I am a boy → I / am / a / boy
- Tokens: lexeme들의 categories a[index] = 4 + 2
c) Lex/Flex
- scanner의 자동 생성
- 수동으로 작성된 것들이 더 빠르다.
- 그러나 작성하기가 지루하고, 오류가 발생하기 쉽다!
- Lex/Flex
- 정규 표현식의 명세가 주어짐
- 테이블 기반의 FSA를 생성한다.
- 출력은 scanner를 생성하기 위해 compile하는 C program이다.
2) Syntax Analysis (Parsing)
- 문장에서 grammatical analysis를 수행하는 것과 비슷하다.
- tokens → parse tree or (abstract) syntax tree
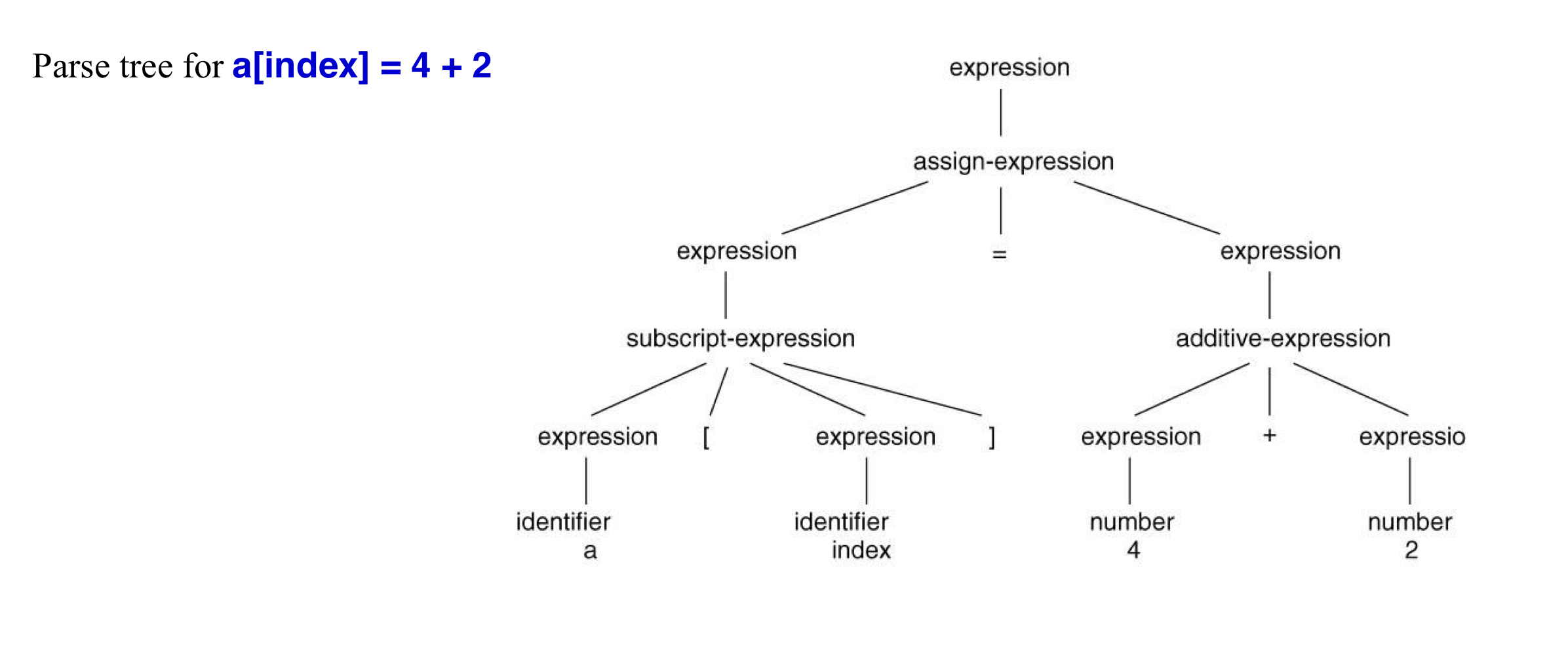
a) Syntax trees
- Syntax trees (or abstract syntax trees) 는 parse tree보다 더 간단하다.
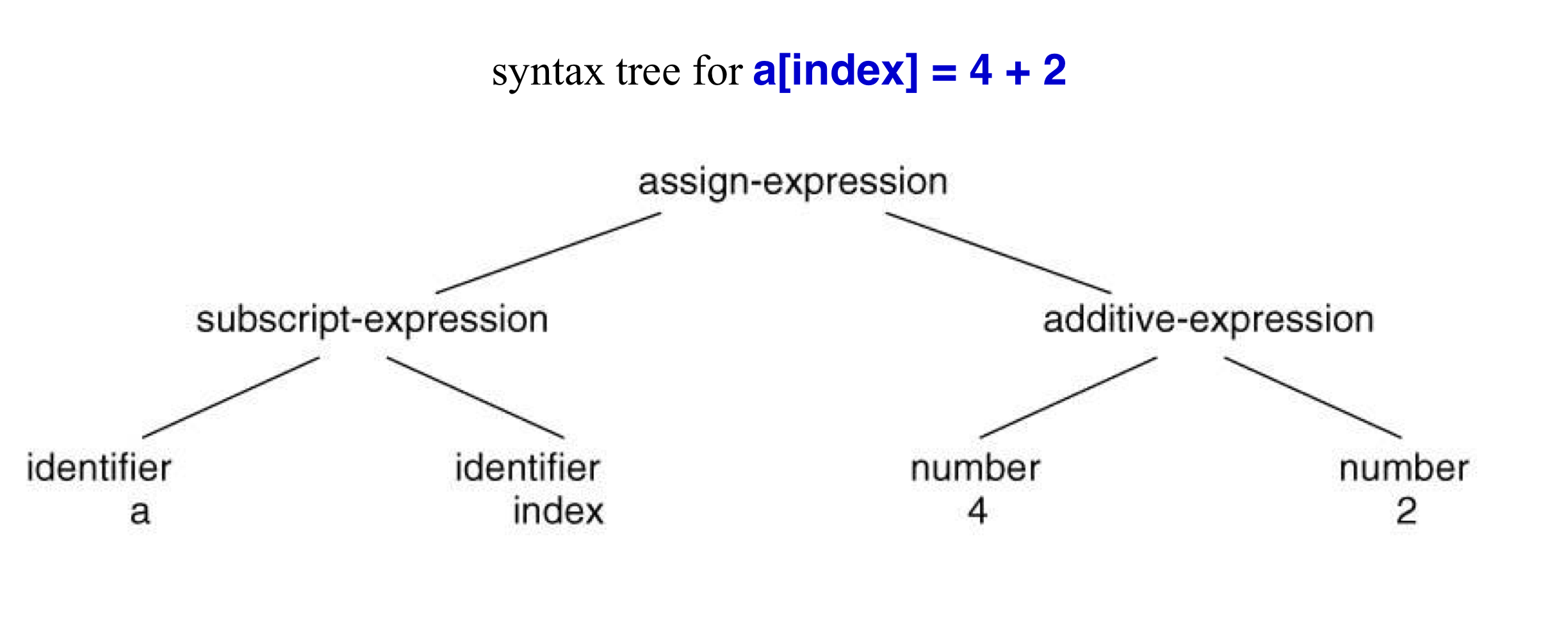
b) Parser
- input stream의 syntactic correctness를 확인
- subsequent semantic processing(후속 의미 처리)을 위한 framework
- Push down automaton (PDA)로 구현된다.
- 수많은 변형이 있다.
- 수동 코드 또는 재귀적 하강?
- table 기반 (top-down or bottom-up)
- 시도 된적 없는 언어에 대해서, writing a correct parser는 도전이다.
- Yacc (yet another compiler compiler) / bison
- Context free grammar가 주어진다.
- 해당 언어에 대한 parser를 생성 (또다시 C program)
3) Semantic Analysis
- parse tree or syntax tree → annotated tee
- 선언과 type checking
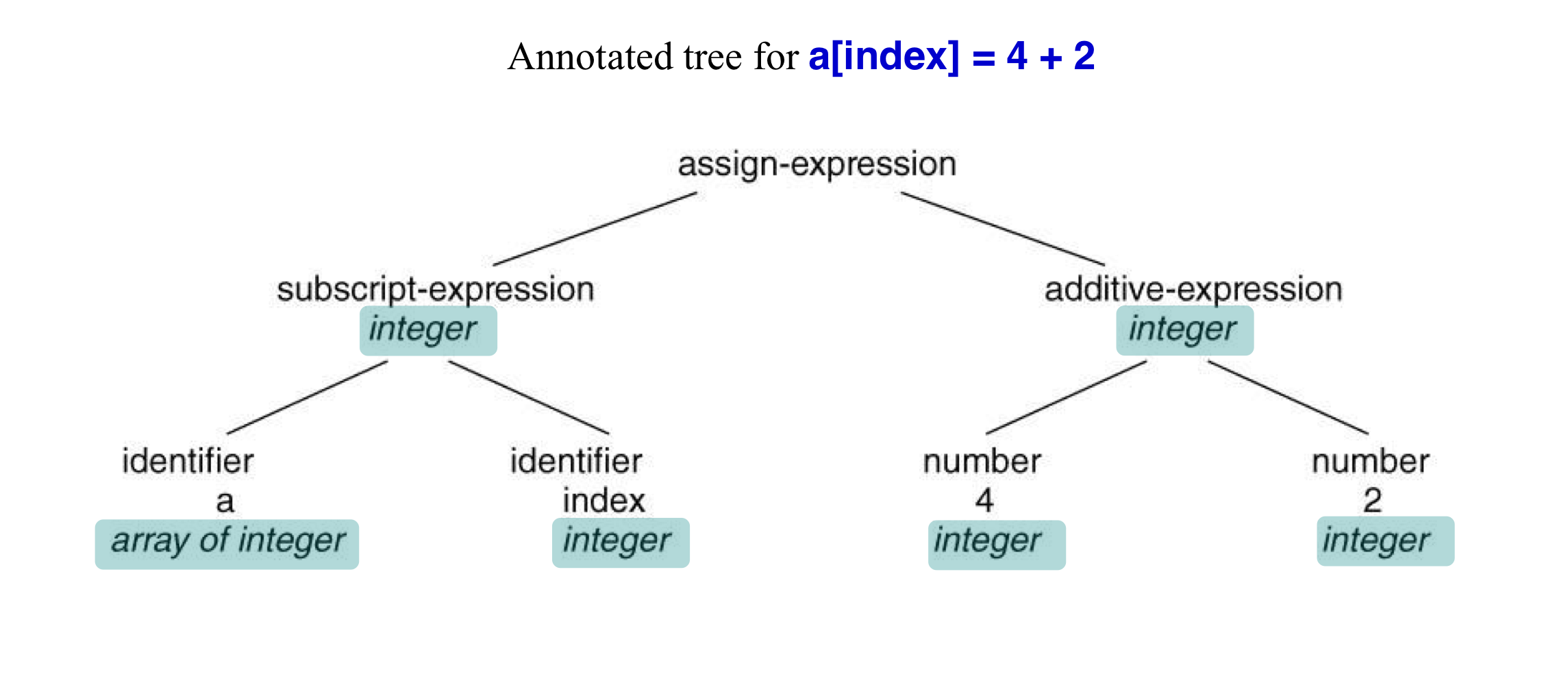
- 수행할 여러 distinct action들이 있다.
- identifier의 정의를 확인하고, 사용법이 올바른지 확인한다.
- 중복된 연산자를 분명하게 한다.
- source에서 IR로 변환한다. (intermediate representation 중간 표현)
- Type checking
- operator and operands
- e.g. an array index should be an integer
- Type conversion (타입 변환)
- semantic rules를 적용하는데 사용되는 표준 형식은 Attribute Grammar (AG)이다.
- parse tree 주위의 정보 이동으로 위한 Graph
- 트리에 각 노드에 적용할 함수들이 있다.
- compiler는 아마 한개 혹은 더많은 IR들을 생성한다.
- syntax and semantic 분석 후에
- 명시적인 low-level or machine-like IR을 생성하낟.
- abstract machine을 위한 program이다.
- IR
- 생성하기 쉬워야한다.
- target machine으로 변역하기 쉬워야 한다.
- e.g. three-address code t1 = inttofloat(60 t2 = id3 * t1 t3 = id2 + t2 id1 = t3
- annoatated tree → intermediate code
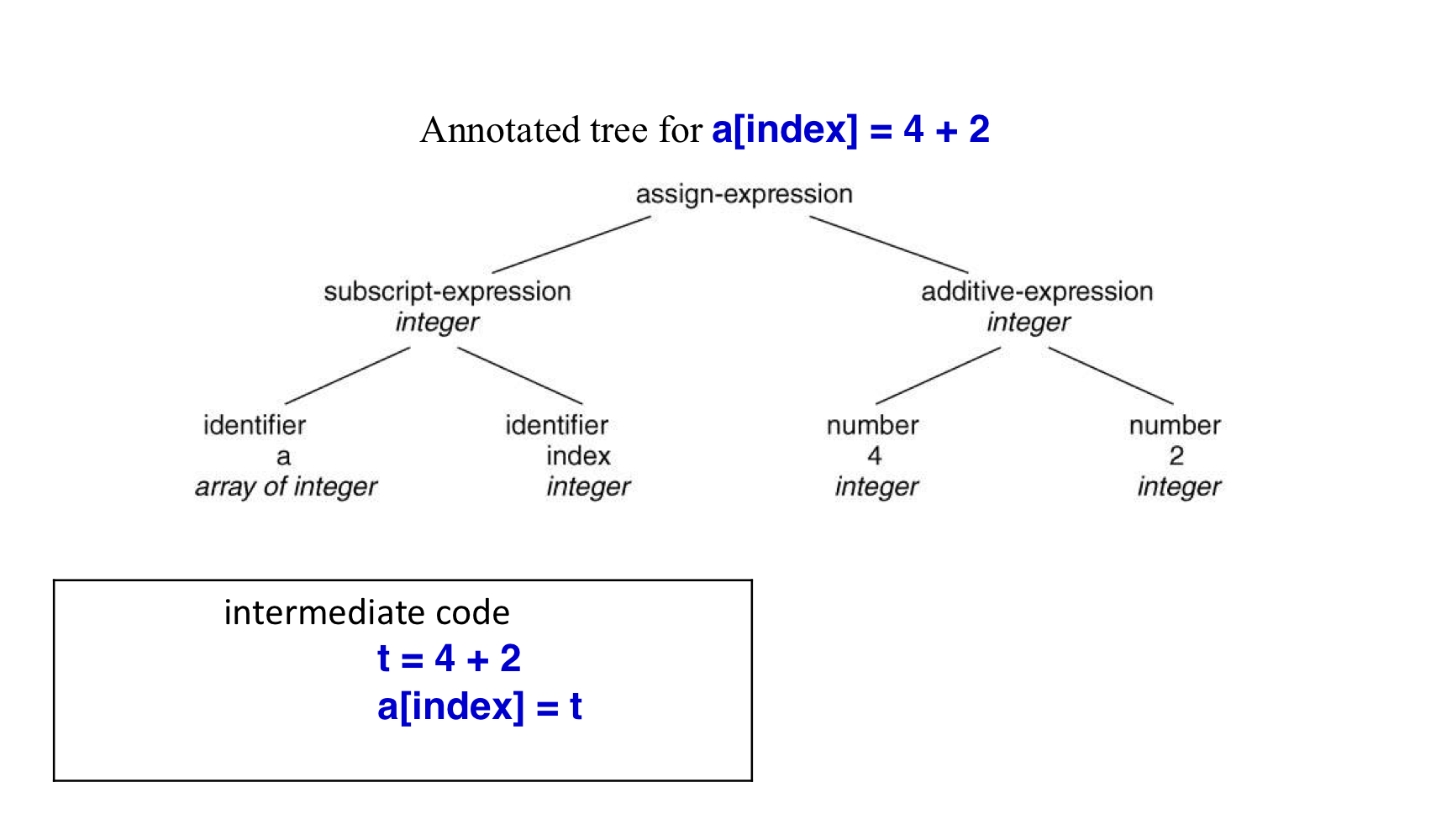
3. Backend
- Frontend -
- Statements, loops, etc.
- 이들은 여러가지 assembly statement들로 분해된다.
- Machine 독립적인 assembly code
- 3-address code, RTL (레지스터 전송 언어)
- 무한한 가상 레지스터, 무한한 자원
- “Standard” opcode repertoire
- Goals
- code의 품질을 최적화 하는 것.
- application을 실제 hardware에 매핑하는 것.
1) Dataflow and Control Flow Analysis
- transformation이 legal한지 illegal한지를 결정하기 위해 variable 사용과, execution behavior에 관한 필요한 정보를 제공한다.
- Dataflow analysis
- variable들이 “interesting” values를 포함하고 있을 때를 식별한다.
- 어떤 명령어가 값을 생성하거나 사용하는지
- DEF, USE, GEN, KILL
- Control flow analysis
- 제어문에 의한 execution behaviors
- If문, for/while roop, goto’s
- Control flow graph
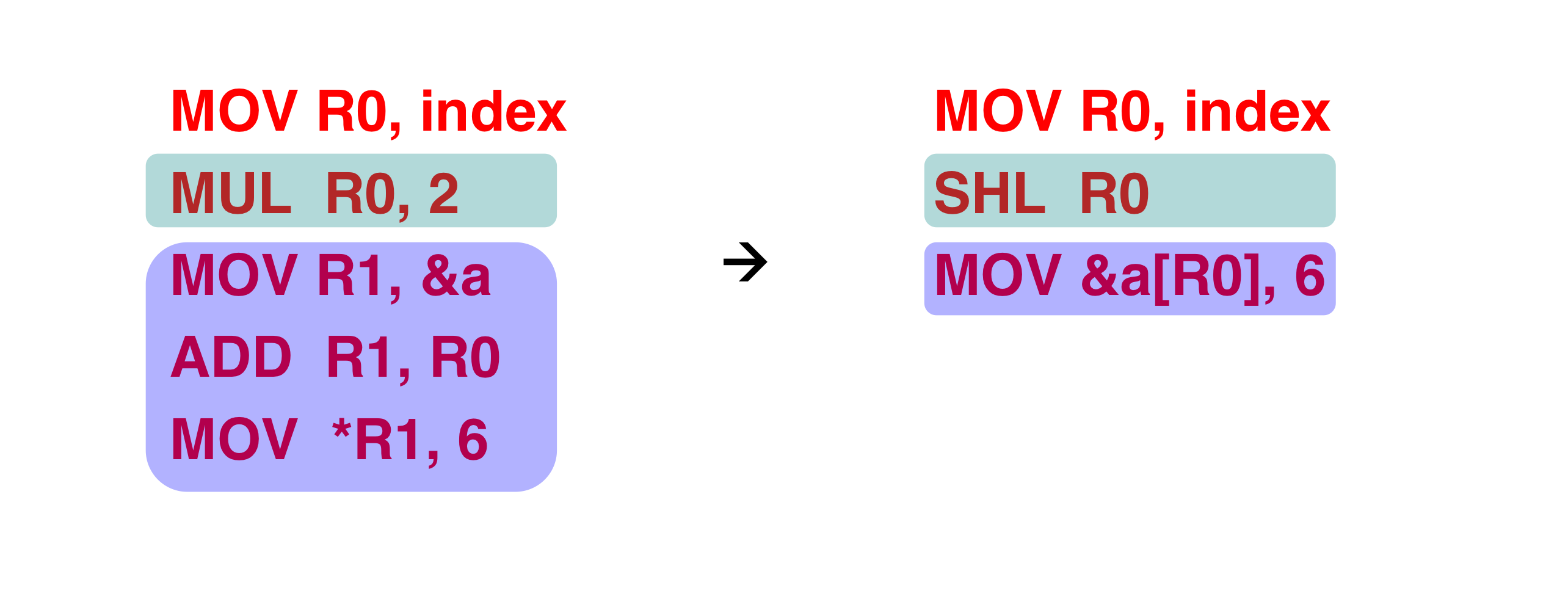
2) Optimization
- 코드를 더 빠르게 만드는 방법
- Classical optimizations
- Dead code elimination - useless code를 제거한다.
- Common subexpression elimination - 동일한 것을 여러번 다시 계산하는 것을 제거
- Machine independent (classical)
- 이번 강의에서 목표로 한다.
- 거의 모든 architecture에 유용하다.
- Machine dependent
- processor architecture에 의존적이다.
- Memory system, branches, dependences
- intermediate code → optimized intermediate code
- constant folding (값 자체는 변하지 않기에)

4) Code Generation
- machine에 독립적인 assembly code를 target architecture에 매핑
- 가상에서 물리적으로 binding
- Instruction selection - 일반적인 opcode를 구현하기 위한 최적의 machine opcode를 선택
- Register allocation - 무한한 가상 레지스터를 N개의 물리적 레지스터로 할당
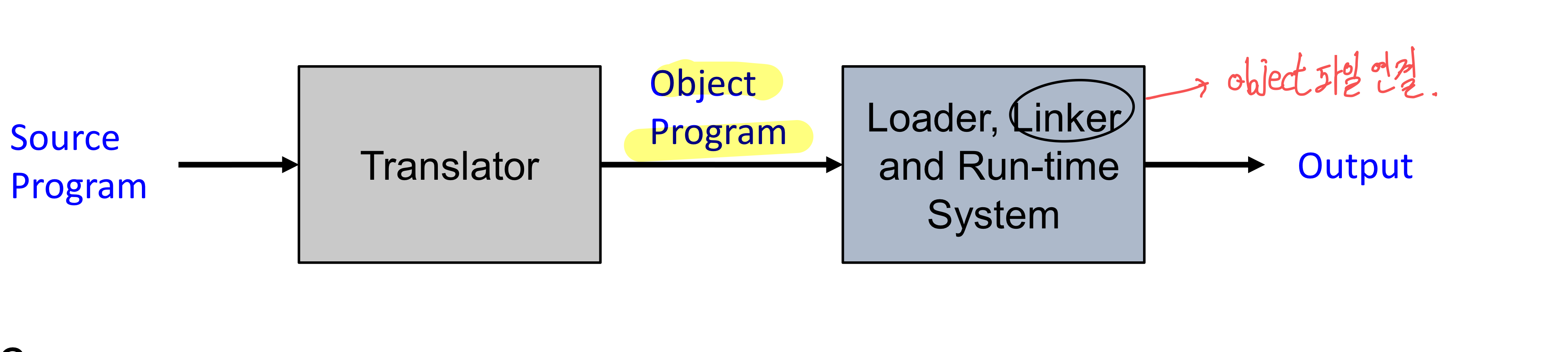
- Machine assembly가 우리의 output이며, assembler and linker는 이를 통해 binary를 생성
- optimized intermediate code → target code

5) Target code optimization
- target code → optimized target code
4. The translation process
- Lexical analysis (Scanning)
- Syntax analysis (Parsing)
- Semantic analysis
- Intermediate code generation
- Intermediate code optimization
- Code generation
- Target code optimization