
드디어 말로만 듣던 스탠포드 대학교의 교육용 os인 pintos를 구현하는 주차에 접어들었다.
Project1의 과제 목표는 다음과 같다.
과제 목표
- Alarm : 호출한 프로세스를 정해진 시간 후에 다시 시작하는 커널 내부 함수
- 핀토스에서 Busy-wating으로 구현되어있는 알람 기능을 sleep/wake up 방식으로 개선한다.
Busy-wating이란? 스레드가 CPU를 점유하면서 대기하고 있는 상태를 의미한다. 이러한 상태일 경우 CPU 자원이 낭비 되고, 소모 전력이 불필요하게 낭비될 수 있다.
Pintos의 Thread lifecycle
핀토스의 스레드 생명주기는 아래 사진과 같다.
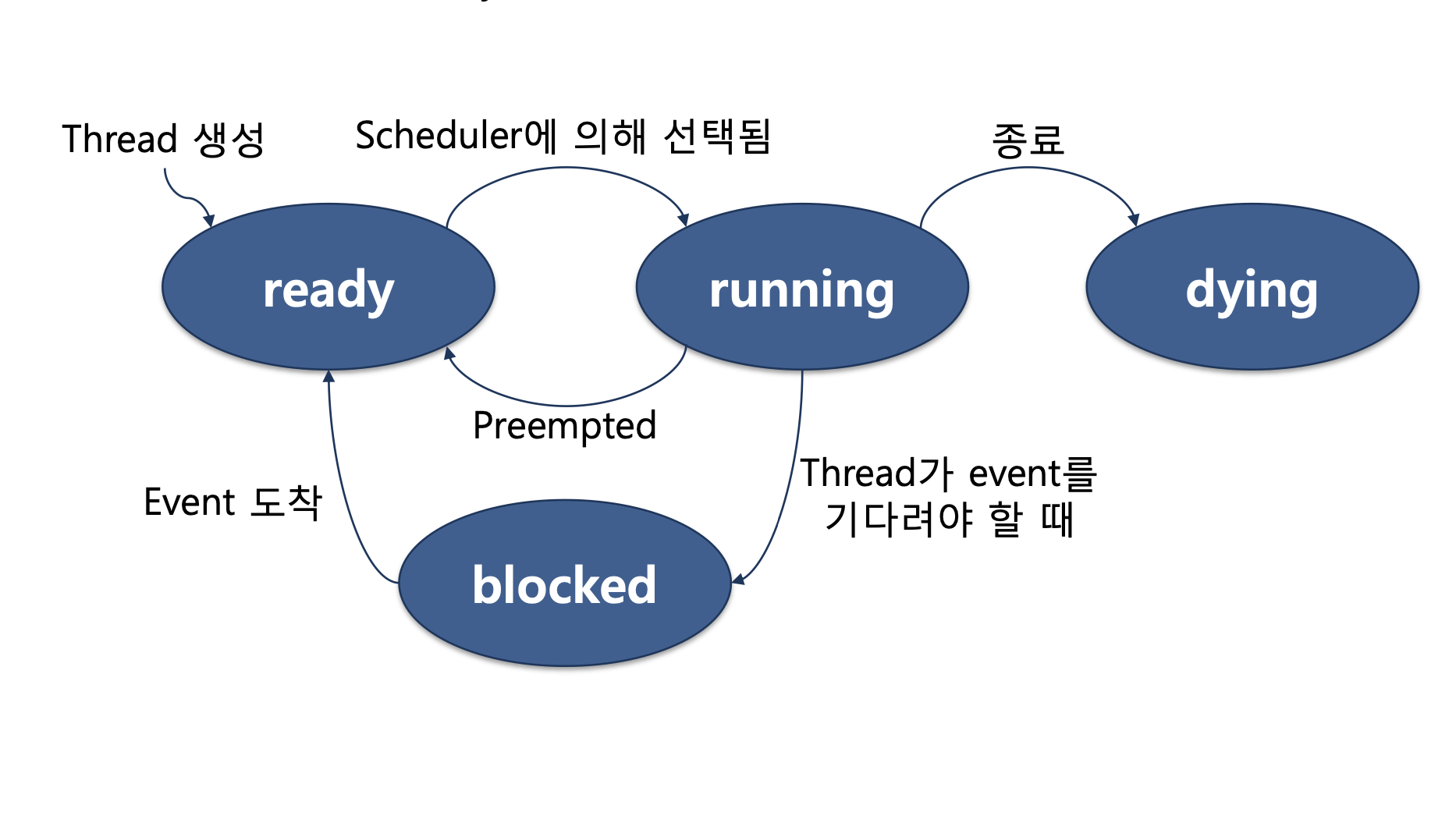
처음 스레드가 생성되면 ready 상태로 ready list에 추가되며, 실행시에는 상태가 running으로 바뀌게 된다. ready list에 위치한 스레드는 cpu가 언제든 실행할 수 있는 상태가 된다.
만약 1000초 뒤에 running 상태가 되어야할 스레드가 있는데, 이 스레드가 ready list에 포함되어 있다면 아직 실행되지도 못함에도 불구하고 cpu가 계속해서 1000초가 되었는지 검사해야하는 상태가 되는 것이다. 이러한 Busy-wating 방식은 cpu는 불필요한 조건 연산을 수행하는데 cpu 자원을 낭비하게 만든다.
Busy waiting vs Sleeping?
따라서 언제 스레드가 일어날지 알 수 있는 현재 Alarm과 같은 상황에서는 해당 시간이 되기 전까지 blocked 상태에 재워두었다가, 깨어날 시간이 되면 ready 상태로 바꾸어 실행 가능한 상태로 만들어주는 sleeping 방식이 효율적이다.
그렇다면 Busy-waiting 방식은 항상 나쁠까? 그렇지만은 않다. 자원의 권한을 얻는데 많은 시간이 소요되지 않는 상황이나 Context Switching 비용보다 성능적으로 더 우수한 상황에는 Busy-waiting이 오히려 더 좋은 선택이 될 수도 있다.
sleeping 방식은 기다리는 시간동안 ready list가 아닌 blocked된 상태로 sleep list에 재워 놓기 때문에, cpu가 일어날 시간이 되기 전까지는 해당 스레드를 실행시키지 않기 때문에 효율적이다.
그러나 sleep list에 넣는 비용과 Context switch 비용이 소모 된다는 단점이 있기 때문에, 각각의 장/단점을 잘 인지하고 사용하는것이 중요할 것 같다.
Pintos에서 스레드를 관리하는 방법?
struct thread {
...
struct list_elem elem; /* List element. */
...
pintos에서 스레드 구조체는 list_elem 이라고 하는 구조체의 필드를 이중 연결 리스트로 연결하여 각 스레드를 리스트 형태로 관리하고 있다. 이를 그림으로 그려보면 아래와 같다.
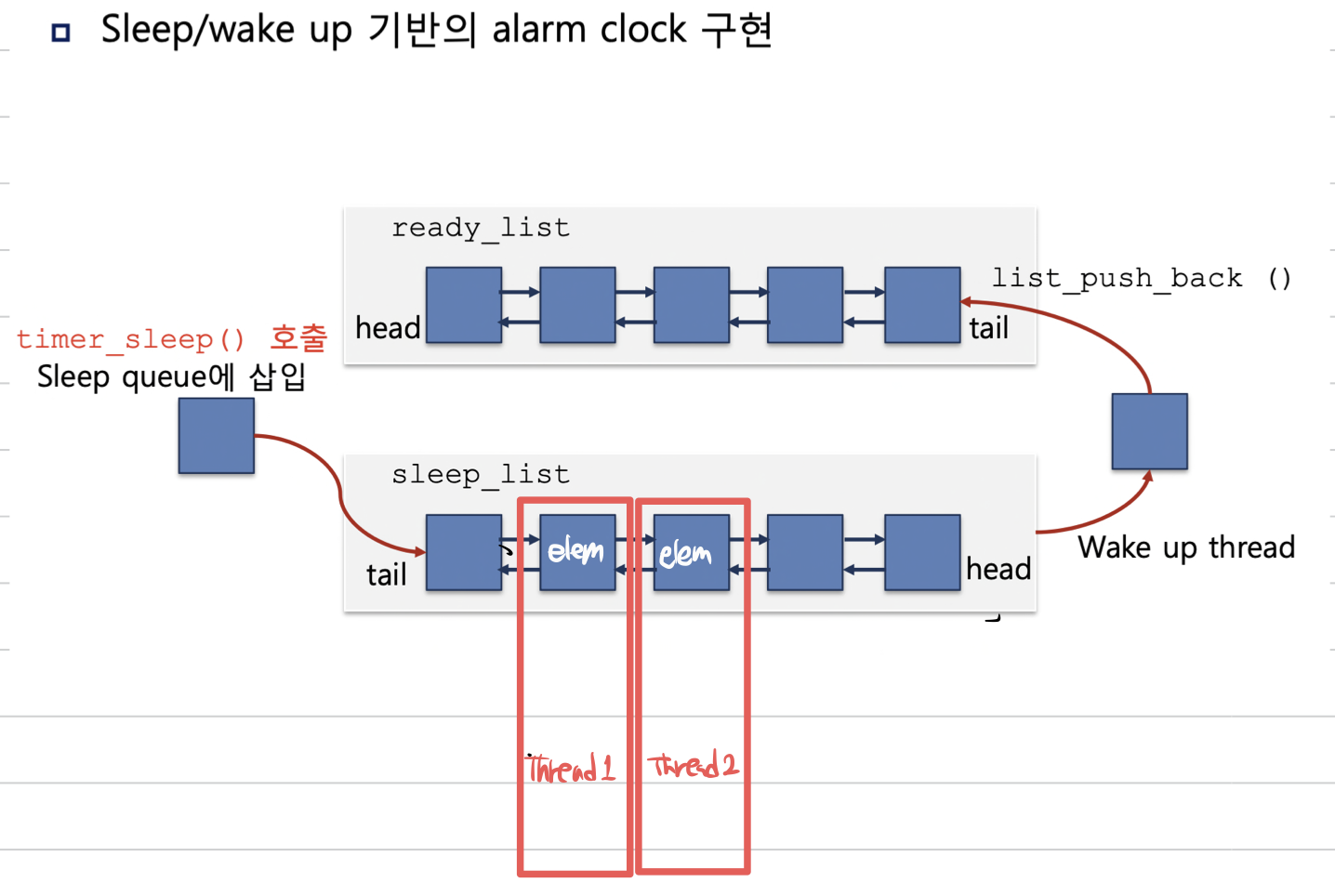
그렇다면 왜 pintos는 스레드를 다른 자료 구조가 아닌 리스트 형태로 구현하고 있을까?
예를 들어 binary heap, red-black tree, hash table 같은 자료구조를 사용하면 이중 연결 리스트보다 효율적인 검색, 삽입, 삭제가 가능하지 않을까?
내가 생각한 이유는 다음과 같다.
- hash table 같은 경우에는 같은 주솟값을 가지게 될 경우 해쉬 충돌이 발생할 가능성이 생긴다.
- binary heap과 red-black tree의 경우에는 효율적이지만, 구현에 있어서 복잡성이 늘어난다.
따라서 운영체제를 학습하는데 의의가 있는 pintos에서 약간의 비효율성을 감수하면서, 구현이 간단한 양방향 연결 리스트를 채택했다고 생각했다.
timer_interrupt()는 왜 interrupt가 disable 되어 있을까?
/* Timer interrupt handler. */
static void
timer_interrupt(struct intr_frame *args UNUSED)
{
ticks++;
thread_tick();
if (get_next_tick_to_awake() <= ticks) // 가장 빨리 깨워야하는 스레드 기상 시간보다 현재 시간이 더 경과 되었다면
thread_awake(ticks); // 시간 지난 스레드 깨우러 감
}timer_interrupt()에서 intr_get_level()을 호출해서 디버깅을 해보면, 다른 부분처럼 intr_disable()과 같이 인터럽트 서비스를 금지하는 명시적인 선언이 없는데도 불구하고, 이미 인터럽트가 disable 되어 있음을 확인할 수 있다. 이 때문에 thread_awake() 내에서 임계 영역에 해당하는 부분을 intr_disable(), intr_enable()을 이용해 조작해주려다가, 이미 다른 곳에서 인터럽트가 조작되고 있어서 오류가 발생했었다.
그렇다면 코드에서는 명시되어 있지 않는데, 어디서 interrupt를 자동으로 disable 해주는것일까? 이는 해결하지 못해서 조교님들께 질문을 드려 궁금증을 해소할 수 있었다.
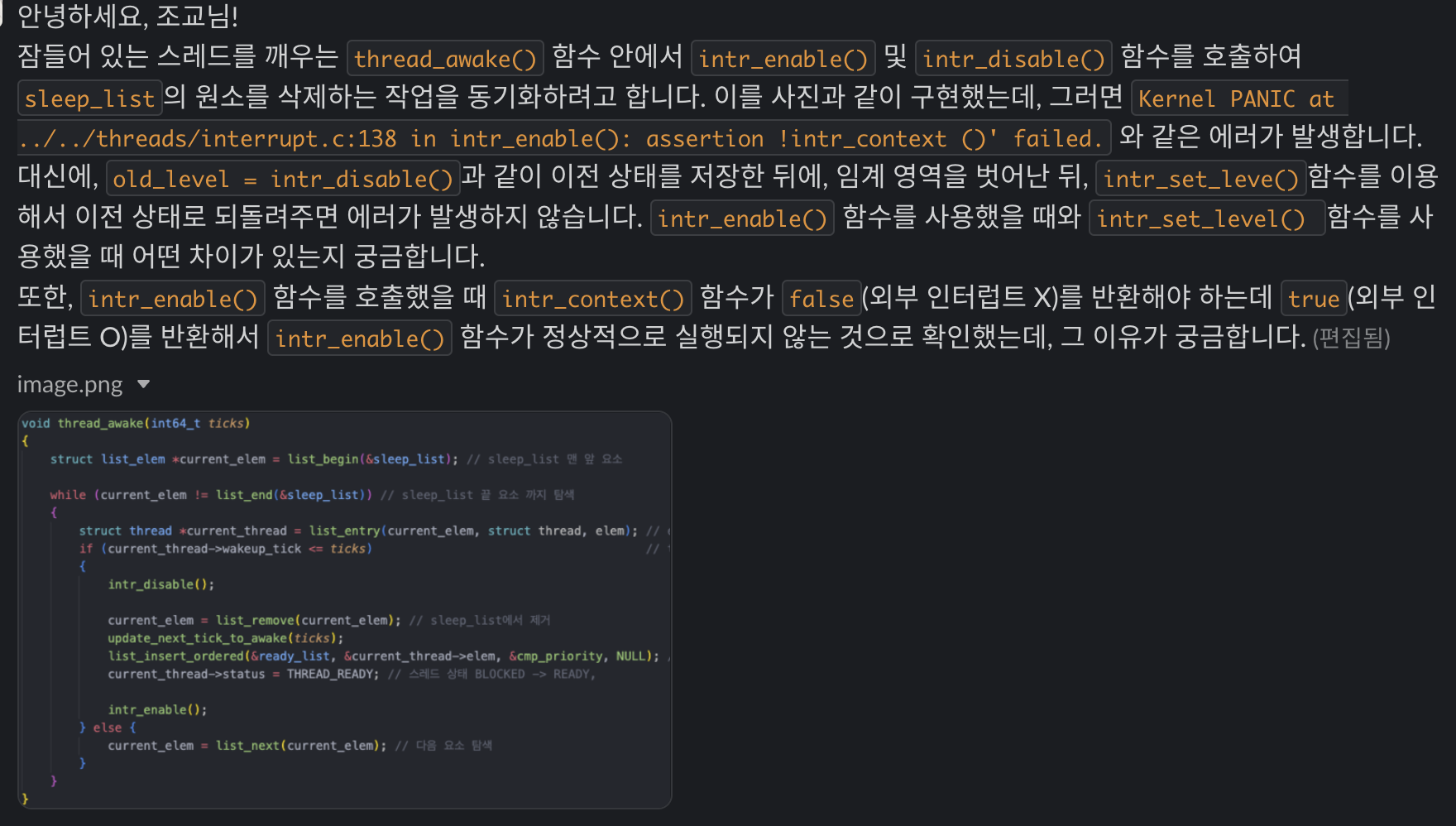


이는 코드에 구현되어있는것이 아니라 하드웨어가 담당하게 된다고 한다. 인터럽트가 발생할 경우 CPU에서 자동으로 interrupt flag를 clear하게 된다.
timer_interrupt()에서 tick을 증가시켜 os의 시간을 측정하고 있는데, 다른 부분에서 interrupt가 발생한다면 시간을 세는 요청 또한 멈추게 되어 시간에 오차가 생기는것이 아닌지?
이 또한 조교님께 질문을 드려보았다.


pintos 에서는 다른 부분에서 interrupt가 발생하게 되면 tick을 증가시키는 인터럽트 요청 또한 요청이 막히는 경우가 생기게 되어서 실제 os가 실행된 tick 수와 계산된 tick 수가 다를 수 있다고 한다. 이를 실제 os에서는 kernel에서 interrupt가 막히게 되어도 HPET(High Precision Event Timer)라는 하드웨어 타이머가 계속 tick을 카운팅하고 있어서, 정확한 tick 수를 체크할 수 있다고 한다.
HPET 관련 참고 자료
