
두 번째 해결 과제는 기존에 FIFO 방식으로 비선점으로 스레드가 스케쥴링 되던 구조를 Priority를 추가하여 선점이 가능하도록 변경하는 것이었다.
예를 들면 다음과 같다.
기존에는 무조건 처음 들어온 스레드가 가장 먼저 작업을 수행하고, 이후에 새로운 스레드가 생성되면 먼저 생성된 스레드가 작업을 완료한 이후에 다음 스레드가 작업을 수행할 수 있었다. 전형적인 FIFO 구조이다.
개선하게 될 구조에서는 각 스레드는 우선순위(priority)를 갖는다. 만약 현재 실행되고 있는 스레드가 31의 우선순위를 가지고, 실행 중에 32의 우선순위(더 높은 우선 순위)를 갖는 스레드가 생성되었다고 해보자. 이 경우에는 실행되고 있던 스레드는 CPU를 더 높은 우선 순위를 갖는 스레드에 양보하게 된다. 새로 생성된 스레드 입장에서는 CPU를 중간에 선점하게 되는 것이기 때문에, 선점(preemption)이라고 한다.
비선점이 아닌 선점으로 구현해야하는 이유?
각 스레드에 우선 순위를 부여함으로써, 중요한 작업을 먼저 빠르게 실행 시킬 수 있다는 점에서 리소스를 효율적으로 사용할 수 있게 된다.
그러나 비선점 스케쥴링보다 각 스레드의 작업을 계속해서 추적하고 전환하는 과정이 필요하므로 CPU 오버헤드가 증가할 수 있다는 단점이 있다. 또한 자원이 올바르게 할당되지 않을 경우 Deadlock(교착상태)이 발생할 수 있으므로 이에 대한 추가적인 처리가 필요하다.
Pintos 구조체 구조
thread.h
struct thread {
...
int priority; /* Priority. */
...
struct list_elem elem; /* List element. */
...
int init_priority;
struct lock *wait_on_lock;
struct list donations;
struct list_elem donation_elem;
...synch.h
/* A counting semaphore. */
struct semaphore {
unsigned value; /* Current value. */
struct list waiters; /* List of waiting threads. */
};
/* One semaphore in a list. */
struct semaphore_elem
{
struct list_elem elem; /* List element. */
struct semaphore semaphore; /* This semaphore. */
};
/* Lock. */
struct lock {
struct thread *holder; /* Thread holding lock (for debugging). */
struct semaphore semaphore; /* Binary semaphore controlling access. */
};
/* Condition variable. */
struct condition {
struct list waiters; /* List of waiting threads. */
};위 구조체의 연관관계를 그림으로 그려보면 아래와 같다. (팀원이 잘 그려 주었다)
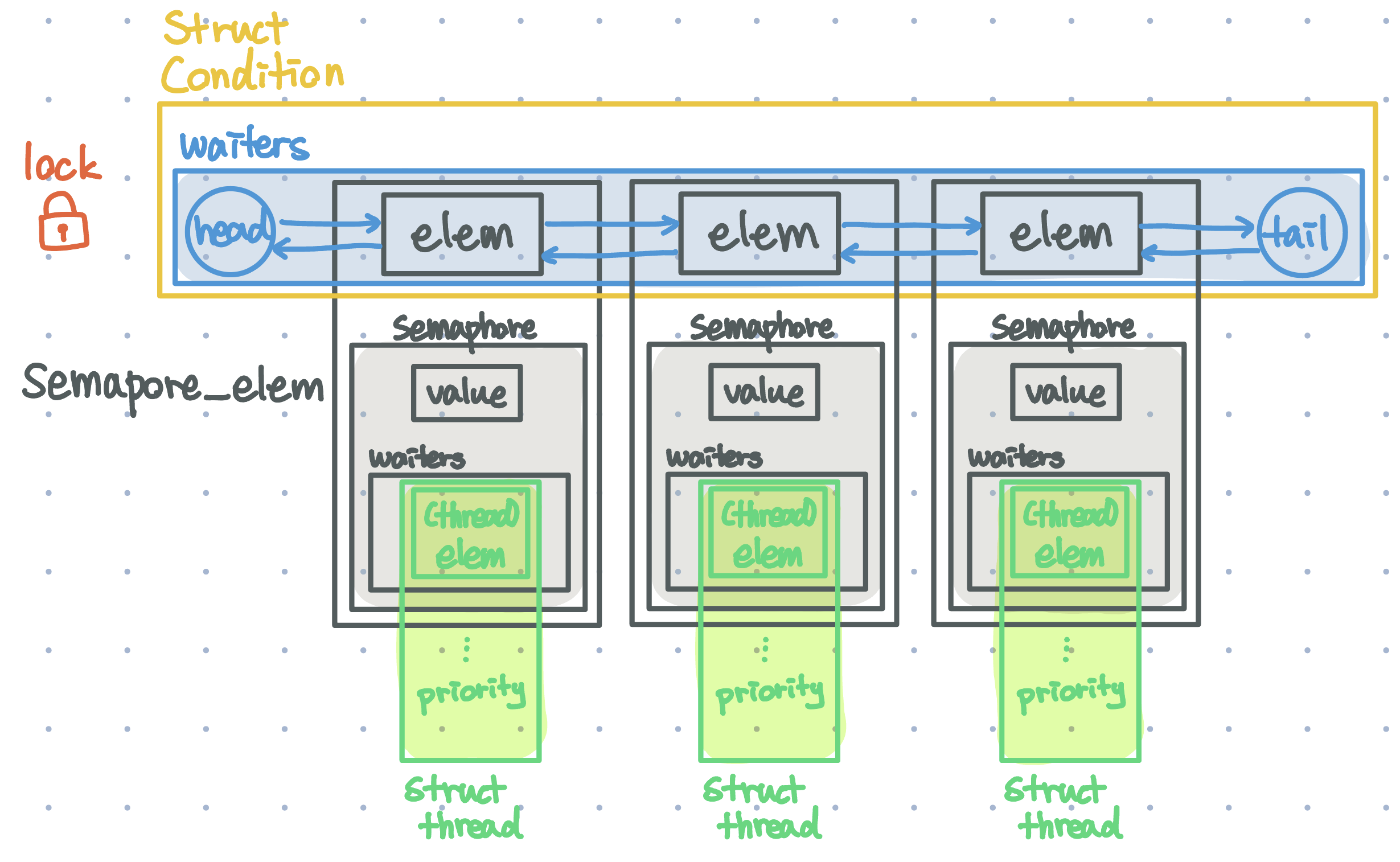
어떤 조건이 참이 되기를 기다리는 cond_waiter라는 대기자 목록에 semaphore_elem 이라는 요소로 대기를 시킨다. 이 그림을 보고 이해하기 어려웠던 부분은 다음과 같다.
결국 어떤 조건이 참이 되기를 기다리는 대상은 스레드일텐데, 어째서 스레드 구조체를 직접적으로 대기 리스트에 넣는것이 아니라 semaphore_elem을 리스트에 넣어 대기 리스트를 관리할까?
semaphore로 대기 리스트를 관리하는 이유
그 이유는 사실 이미 언급했었다. 조건이 참이 되기 전에는 대기 리스트에 있는 목록들은 block된 상태로 대기해야하기 때문이다. 따라서 조건이 참이 되기 전까지는 cond_wait() 함수를 호출하여 semaphore_elem 내의 semaphore 구조체의 value를 0인 상태로 스레드를 block한다. 이후 조건이 참이 되었다면 해당 해당 조건을 다 수행한 스레드는 cond_signal()을 호출해서, semaphore의 value를 1로 증가시킬 것이고, 다음 순서에 해당하는 대기자가 작업을 시작할 수 있게 된다.
이렇게 말하니 장황하고 복잡하지만, 결론만 말하자면 어떤 조건이 참이되기 전까지 대기 시킬 스레드들 또한 block 상태로 유지할 필요가 있기 때문이라고 이해해볼 수 있겠다.
조건 대기 로직에서 semaphore 구조체 내의 waiters 리스트 안에는 리스트지만 한 개의 스레드만 포함된다.
이 구조를 학습하며 생겼던 의문점은 semaphore_elem 구조체 내의 semaphore 구조체의 waiters 필드는 리스트 형태의 자료구조인데, 구현을 하다보면 실질적으로 semaphore_elem 또한 cond_waiter의 각각의 스레드 하나 하나를 구분 짓기 때문에 semaphore 내의 waiters 필드는 이름과는 맞지 않게 여러개의 스레드가 저장되는 것이 아닌, cond_waiter 스레드 하나하나를 구분하기 위해 스레드 하나만 리스트에 포함될 수 있다는 것이다.
이렇게 구조체가 구성된 이유에 대해서 고민해 보았는데, 아마 이전에 구현했던 세마포어 기능의 구조체를 재사용하기 때문에 이렇게 구현된 것으로 보인다.
Priority Scheduling이 필요한 이유?
기존에는 FIFO 방식의 비선점형 스케쥴링 방식을 사용했다. 이 말의 의미는 100초가 걸리는 작업이 먼저 들어오고, 이후에 1초짜리 작업이 들어왔다면 1초 짜리 작업은 금방 끝날 수 있는 작업임에도 불구하고 100초짜리 작업이 끝나기 전에는 대기할 수 밖에 없음을 의미한다. 이 경우는 많은 경우 중 하나의 예시가 될 수 있다.
따라서 cpu는 효율적으로 일을 처리하지 못할 가능성이 높기 때문에, 각 작업에 우선순위를 부여하여 현재 실행중인 작업보다 우선순위가 높은 작업이 요청될 경우, 즉시 현재 스레드 작업을 중지하고 더 높은 우선순위의 스레드를 실행시킨다. 이는 곧 선점형 방식의 구현을 의미한다.
이처럼 선점형 방식으로 구현하게 되면, cpu가 보다 효율적인 작업을 처리하는것이 가능해진다.
Priority Syncronization이 필요한 이유?
여러 스레드가 lock, semaphore, condition variable을 얻기 위해 기다릴 경우 우선 순위가 가장 높은 스레드가 CPU를 점유할 수 있도록 구현하기 위함이다. 이전 구조에서는 동기화를 위해서 semaphore를 대기하고 있는 대기자 목록 또한 FIFO 형식으로 구현되어 있었기 때문에, 이 부분 또한 우선순위가 적용되어지도록 구현하는것이다.
Priority Donation이 필요한 이유?
만약 우선순위가 H > M > L과 같이 정해져있고, CPU는 Priority Scheduling을 따른다고 했을때 H가 가장 먼저 실행되는것이 올바른 실행 동작일 것이다. 그러나 만약 L이 lock을 쥐고 있고, H는 L의 lock을 기다리고 M은 lock을 기다리지 않는 상태라면 H는 우선순위가 높더라도 L이 lock을 놓아주지 않는다면, 우선순위가 상대적으로 낮은 M이 H보다 더 먼저 실행되는 문제가 생길수도 있다.
이러한 경우에 우선 순위가 적절하게 지켜질 수 있도록 하기 위해, 일시적으로 lock을 가진 낮은 우선 순위의 스레드의 우선 순위를 현재 실행시키고자 하는 높은 우선 순위로 증가시키는 과정이 필요하다.
그렇다면 기존에 lock을 가지고 있는 낮은 우선 순위의 작업이 먼저 처리되고, 이후에 H가 처리하게 됨으로써 적절하게 작업의 우선순위를 보장할 수 있게 된다.
