
서버의 성능이 나빠지는 이유로는 웹 서버의 부하도 그 원인이 될 수 있지만, DB의 부하가 원인일 가능성도 있다. 웹 서버에 걸리는 부하를 분산하는 기술로 로드 밸런싱이 있듯이, DB 서버를 이중화하여 부하를 분산하도록 하는 기술에는 클러스터링(Clustering)과 리플리케이션(Reflication)이 있다.
Clustering이란?

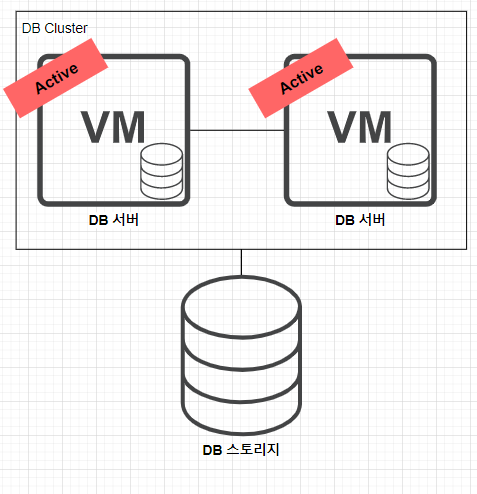
위 사진은 일반적인 DB 서버 구조이다. 이러한 구조일 경우 DB 서버가 죽게되면 어떻게 될까?
당연히 서비스 전체가 중단되게 될 것이다.
이에 대한 가장 간편한 해결책이 바로 클러스터링이다.
클러스터링에는 Active-Active와 Active-StandBy 클러스터링이 있다.
Active-Active 클러스터링
장점
동일한 DB 서버 두 대를 묶고 Active-Active 상태로 운영하면, 하나의 DB 서버가 죽더라도 나머지 DB 서버가 살아있기 때문에 서비스 전체가 중단되는 사태를 방지할 수 있다. 그렇다면 마냥 장점만 있는 방법일까?
단점
Active-Active 클러스터링의 단점은 하나의 DB 스토리지를 두 개의 DB 서버가 공유하기 때문에, 병목 현상이 있을 수 있다는 점과 두 개의 DB 서버가 동시에 활성화 되어있는만큼 이전보다 많은 비용이 발생할 수 있다는 단점이 있다.
Active-Stand By 클러스터링

장점
위의 Active-Active 클러스터링의 단점을 보완한 것이 Active-StandBy 클러스터링이다. 두 개의 DB 서버를 모두 활성 시켜놓는 Active-Active 클러스터링과는 달리, 하나의 Active 서버만을 사용하다가 DB 서버에 문제가 생겼을 때 Fail Over를 통해 Stand By 서버가 Active가 되고, 기존 Active는 Stand By 상태로 전환함으로써 장애에 대응할 수 있다.
Fail Over : a method of protecting computer systems from failure, in which standby equipment automatically takes over when the main system fails.
단점
Active-StandBy 또한 단점이 없는 것은 아니다. 두 대의 서버가 존재하지만, 동작하는 서버는 한 대이기 때문에 Active-Active에 있었던 서버 비용적인 문제는 해결이 되었다.
그러나 Fail Over가 바로 일어나는 것이 아니고, 상태가 전환이 되는데 수 초~수 분의 시간이 걸리기 때문에 이 시간 동안 영업 손실이 반드시 생기게 된다는 단점이 있다.
지금 까지 DB 서버를 분산시키는 클러스터링에 대해 알아보았다. 그렇다면 DB 스토리지는 분산시키지 않아도 괜찮은걸까? 데이터를 저장하는 DB 스토리지에 문제가 생기면 큰 문제가 발생하므로, 당연히 괜찮지 않을 것이다.
이로부터 파생된 개념이 리플리케이션(Replication)이다.
Replication이란?
리플리케이션(Replication)은 복제를 뜻한다. 2대 이상의 DBMS를 나누어서 데이터를 저장하는 방식을 말하며, 최소 구성은 Master/Slave 구성이다.
리플리케이션이 무엇일까?
그렇다면 위에서 언급한 최소 구성인 Master DBMS와 Slave DBMS는 각각 어떤 역할을 담당할까?
기본적인 리플리케이션 구조는 아래와 같다.
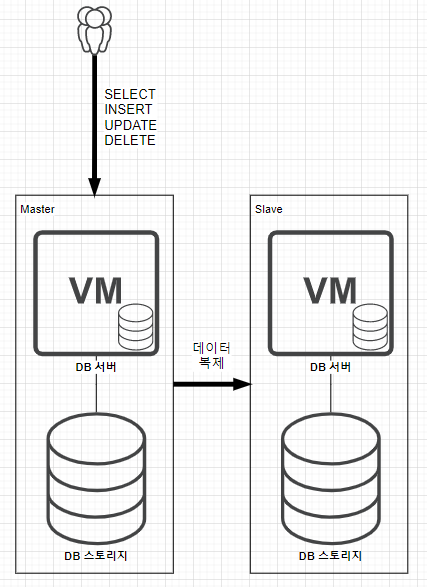
Master에 CRUD 동작이 일어나면, 해당 변경사항을 Slave에 반영하는 구조이다. 그러나 이런 구성은 Slave는 단순히 Master의 변경사항을 받아 복제만 하기 때문에, Slave DB 서버가 논다는 단점이 있다. 위 사진과 같은 구조일 경우 Master DB에만 부하가 쏠리게 되어 문제가 생길 가능성이 높아진다.
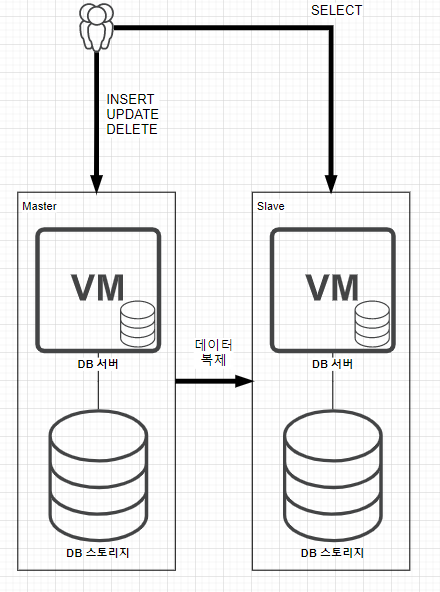
그래서 일반적으로 위 사진과 같은 구조로 리플리케이션 구조를 갖춘다. 이 구조에서 Master DB 서버와 Salve DB 서버의 역할은 아래와 같다.
Master DBMS 의 역할
웹 서버로부터 등록/수정/삭제 (CUD)의 요청을 담당하게 된다. 이렇게 받은 요청에 대한 처리를 한 후, 즉시 Slave DB 서버에 변경된 데이터를 전달한다.
Slave DBMS 의 역할
Master DBMS 로 부터 받은 데이터를 반영하고, 주로 읽기 (R)에 대한 요청을 담당하게 된다. 그림상에서 Slave DB 서버는 한 개 이지만, 서비스에 맞게 Slave DB 서버를 여러개 만들수도 있다.
참고로 많은 서비스에서 읽기 요청(R)의 비율이 60~70% 정도를 차지한다고 한다.
장점
위와 같이 리플리케이션 구조를 가져가게 된다면, CUD에 대한 요청과 R에 대한 요청들을 Slave DB 서버들에 분산시킬 수 있으므로 성능 향상을 기대해볼 수 있다.
단점
리플리케이션에도 단점은 존재하는데, 각각의 서로 다른 서버로 운영하다 보니 버전 차이를 관리해주어야 한다. 또한 Master DB 서버에서 Slave DB 서버로 데이터를 동기화 할때 비동기 방식으로 동기화를 진행하기 때문에, 일관성있는 데이터를 얻지 못할 수 도 있다(동기 방식으로 사용이 가능하긴 하지만, 성능이 느려질 수 있다). 마지막으로는 Master DB 서버가 다운 될 경우 복구 및 대처가 까다롭다는 단점이 있다.
