Chapter 04. 데이터 요약하기
04-1 통계로 요약하기
기술통계 구하기
- 판다스 데이터프레임에서 기본적인 몇 가지 기술통계를 자동으로 추출해 주는
describe()메서드 - 원하는 위치의 값을 보고 싶다면
percentile매개변수에 보고싶은 백분위를 리스트로 전달 - 열의 데이터 타입이 수치가 아니라면
include매개변수에 데이터 타입을 지정
평균 구하기
- 데이터 값을 모두 더한 후 데이터 개수로 나눈 값
- 하지만! 어떤 기준으로 평균을 계산하는 지에 따라 조금씩 다른 의미를 가질 수 있으므로 산출 과정을 충분히 설명해야 합니다.
- 판다스 -
mean()메서드 - 넘파이 -
average()함수
중앙값 구하기
- 전체 데이터 크기를 순서대로 일려로 늘어 놓았을 때 중간에 위치한 값
- 판다스, 넘파이 -
median()메서드 그리고median()함수 - 중복값을 제거하고 중앙값 구하기 -
drop_duplicates()메서드에median()메서드를 사용
최솟값, 최댓값 구하기
- 데이터 포인트 중 가장 작은 값과 가장 큰 값
- 판다스, 넘파이 -
min(),max()메서드,min(),max()함수
분위수 구하기
- 순서대로 나열된 데이터를 일정한 간격으로 나누는 기준점으로,
- 4분위수는 데이터를 4등분하여, 25%, 50%, 75%에 위치한 값입니다.
- 판다스 -
quantile()메서드 - 이 중
interpolation매개변수를 이용하여 중간 값을 보간하여 계산할 수 있음
분산 구하기
- 데이터가 평균에서 얼마나 멀리 퍼져 있는지를 알려 줍니다.
- 구하는 방법은 각 데이터 포인트를 평균에서 뺀 다음 제곱한 후 전체 데이터 개수로 나누어 구합니다.
- 판다스, 넘파이 -
var()메서드 / 함수
표준편차 구하기
- 분산의 제곱근으로 데이터의 분포 정도를 알려주지만, 원본 데이터와 단위가 같기 때문에 분산보다 해석하기 쉽습니다.
- 판다스, 넘파이 -
std()메서드 / 함수
최빈값 구하기
- 데이터에서 가장 많이 등장하는 값을 의미합니다.
- 판다스 -
mode()메서드 - 넘파이 -
unique()함수는 배열에서 고유한 값을 찾아 주고return_counts매개변수를True로 바꿔주면 고유한 값의 등장횟수를 반환함, 그리고 나서argmax()함수를 사용하면 최빈값을 구할 수 있음
04-2 분포 요약하기
오늘도 미션을 주시는 이사님...
산점도 그리기
import matplotlib.pyplot as pltscatter()함수- 투명도 조절하기 -
alpha매개변수
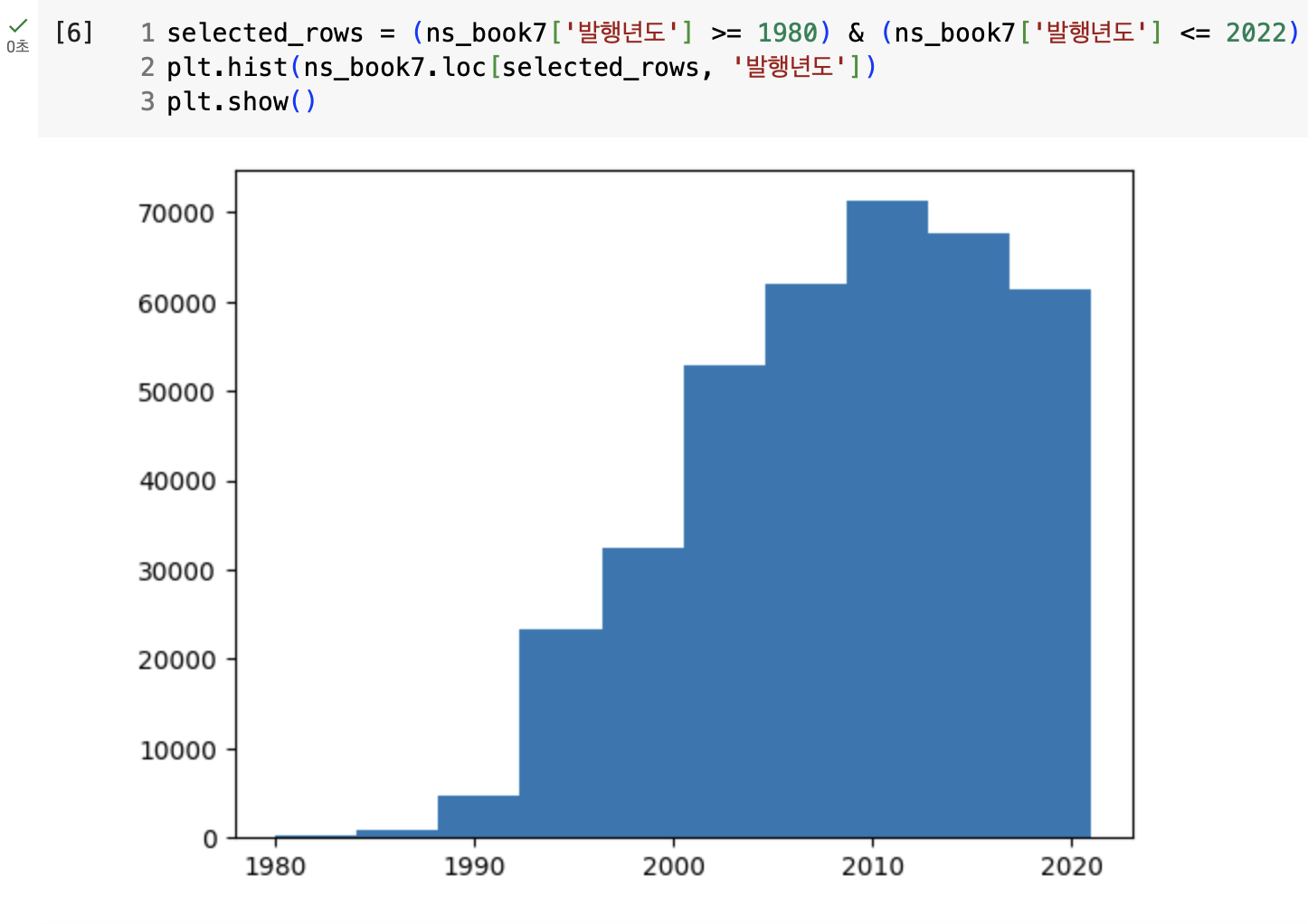
히스토그램 그리기
hist()함수bins매개변수 - 구간 지정하기histigram_bin_edges()함수 - 넘파이에서 제공하는 히스토그램의 구간을 확인하기 위한 함수randn()함수 - 넘파이에서 제공하는 표준정규분포를 따르는 랜덤한 실수를 생성,seed()함수와 같이 사용하면 유사난수를 재연할 수 있음- 구간 조정하기 -
yscale()함수에log를 지정하면 로그 스케일로 변환 가능,xscale()함수도 사용 가능
상자 수염 그림 그리기
boxplot()함수- 수평으로 그리려면
vert매개변수를False로 전달 - 수염 길이 조정하기 -
whis매개변수 전달
아악 이사님... (다음 시간에 계속)

끄아아아아 할 수 있다
유익한 글이었습니다.