[CHAPTER 02. 딥러닝 영상분석의 시작, CNN]
합성곱 심층 신경망(Convolutional Neural Network : CNN)
- 딥러닝 영상분석에서 가장 기본적이고 핵심적인 기술
- 콘볼루션 네트워크라고도 불림
* 콘볼루션 신경망이란 ?
1. 인간의 눈을 대신할 수 있는 인공지능
= 이미지의 공간 정보를 잃지 않고, 인간의 시각처럼 이미지의 특징을 추출해 대상을 인지할 수 있는 딥러닝
2. 시각 세포 연구를 밝혀낸 후, 사람의 시각 인지 과정을 모방해 발전됨
3. 컴퓨터 비전 분야에서 독보적인 방법으로 사용됨
4. 다양한 형태의 데이터에서 원하는 특성을 추출하는데 좋은 성능을 보여줌
1. 왜 딥러닝 영상분석에서 CNN이 중요한가 ?
CNN은 입력 데이터인 영상의 특징을 매우 정확하게 추출하는 방법 !!
- CNN 이전엔 영상분석을 위해 일반적인 심층 신경망 방법 사용
- 근래 발달한 모든 딥러닝 영상분석의 기본은 CNN
1) 영상분석에서 입력 데이터의 특징
이미지 데이터 = 넓이 x 높이 x 색상 채널의 행렬 데이터
이미지에서 형태적인 특징을 추출하는 방법
= 단순히 픽셀 데이터의 행렬값 자체에 대한 기존 분석 방법
- 캐스케이드 분류기 (OpenCV 프로그램)
- K 최근접 이웃 알고리즘 (데이터 마이닝 방법 = 대량의 데이터에서 의미 있는 패턴이나 관계를 찾아내는 과정)
but 사진의 형태가 일반적이지 않으면 좋은 검출 결과를 얻기 어려움 !!

* 기존 분석 방법(=행렬 데이터 이용)으로는 일반적이지 않은 고양이 형태로 전체 고양이의 특징을 분석하기 어려움
2) FC 레이어와 Conv 레이어
FC(Fully Connected) 레이어란 ?
= 기존 심층 신경망에서 입력 레이어의 각 뉴런은 다음 레이어의 모든 출력 뉴런에 연결되는 방식

- 여러 층으로 중첩된 행렬곱의 식
--> 행렬곱의 계산 형태는 모든 요소 간의 곱셈 계산이 이뤄지는 형태 - 모든 노드가 완전히 연결되어 계산됨
이미지 데이터에 행렬곱 계산을 적용하려면 이미지를 벡터 형태로 변경해야함**
--> 벡터 형태로 변경하면 이미지는 모든 가로세로 색상에 대한 픽셀값이 하나의 벡터 데이터로 일렬화됨
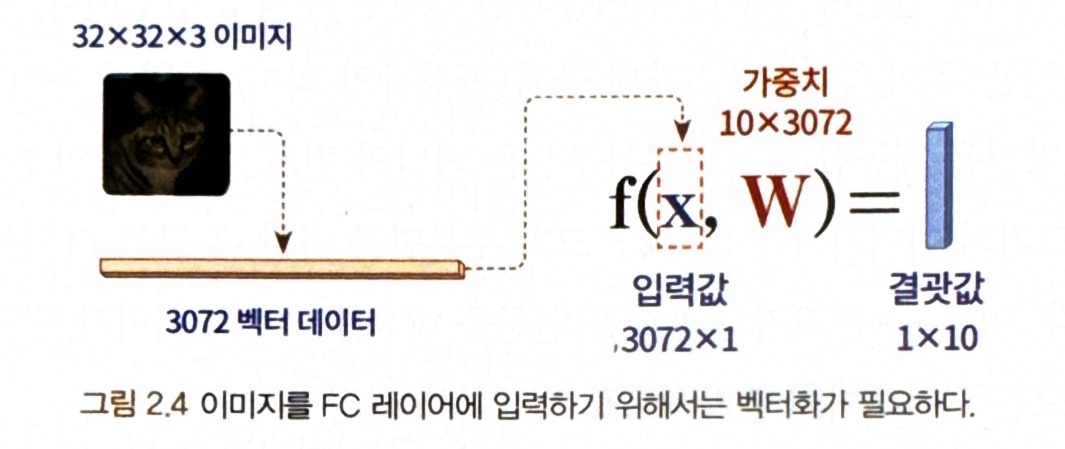
** 이 과정에서 공간 정보를 모두 잃게 되는 문제점이 생김 !!
Conv 레이어란 ?
= 콘볼루션 신경망은 행렬곱이 아닌 Conv 레이어라고 하는 콘볼루션 계산을 하는 레이어를 가짐.
콘볼루션 계산이란 ?
= 차원이 동일한 두 개의 배열을 함께 곱해('합성곱') 차원이 동일한 세 번째 배열을 만드는 방법을 제공
- 콘볼루션 레이어에선 입력 데이터의 가로세로 색상 채널의 형태를 그대로 유지한 상태로 딥러닝 연산 수행
--> 이미지의 공간 정보가 사라지지 않음.
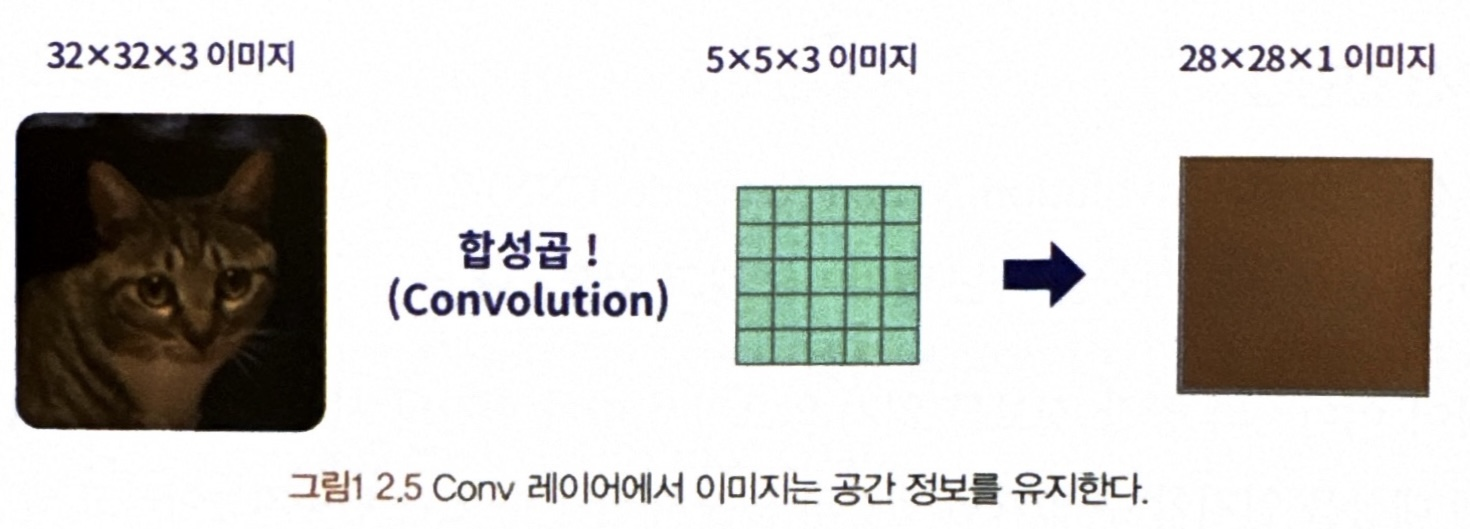
CNN은 입력된 이미지에 대한 계산 방법이 기존 FC 레이어와 달리 공간 정보를 잃지 않는 구조 !!
2. CNN 이해하기
Conv 레이어에서 입력 데이터는 벡터화 없이 이미지 형태 그대로 이뤄짐
가중치는 배열이 아닌 작은 크기의 필터와 같은 형태(=FC 레이어의 가중치 배열과 같음)
- 입력 데이터 : 32x32x3 이미지
- 커널(필터,가중치 역할) : 5x5x3 이미지
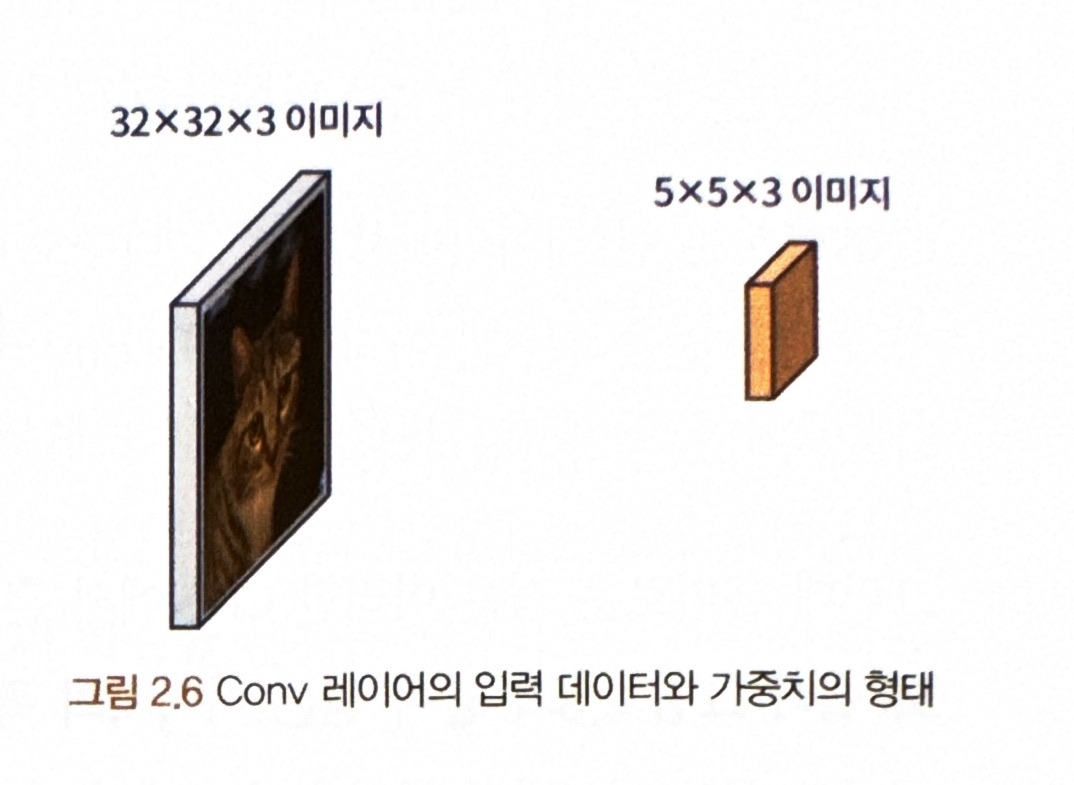
* 커널의 마지막 차원은 항상 입력 데이터의 색상 차원과 동일해야함!! (3으로 동일)
1) 활성화 맵과 특징 맵의 차이
닷 프로덕트(Dot product)란 ?
= 콘볼루션 과정에서 커널은 입력 이미지의 픽셀들과 하나씩 곱한 후 합산되는데 이 합산된 값을 닷 프로덕트라 함.
- 커널은 이미지 공간에서 위치 이동을 하면서 계속 콘볼루션 과정을 가짐.
활성화 맵이란 ?
= 생성된 닷 프로덕트가 모여서 활성화 맵(28x28x1)이 이뤄짐
= 필터를 사용한 연산 결과로 새로운 이미지가 생성됨
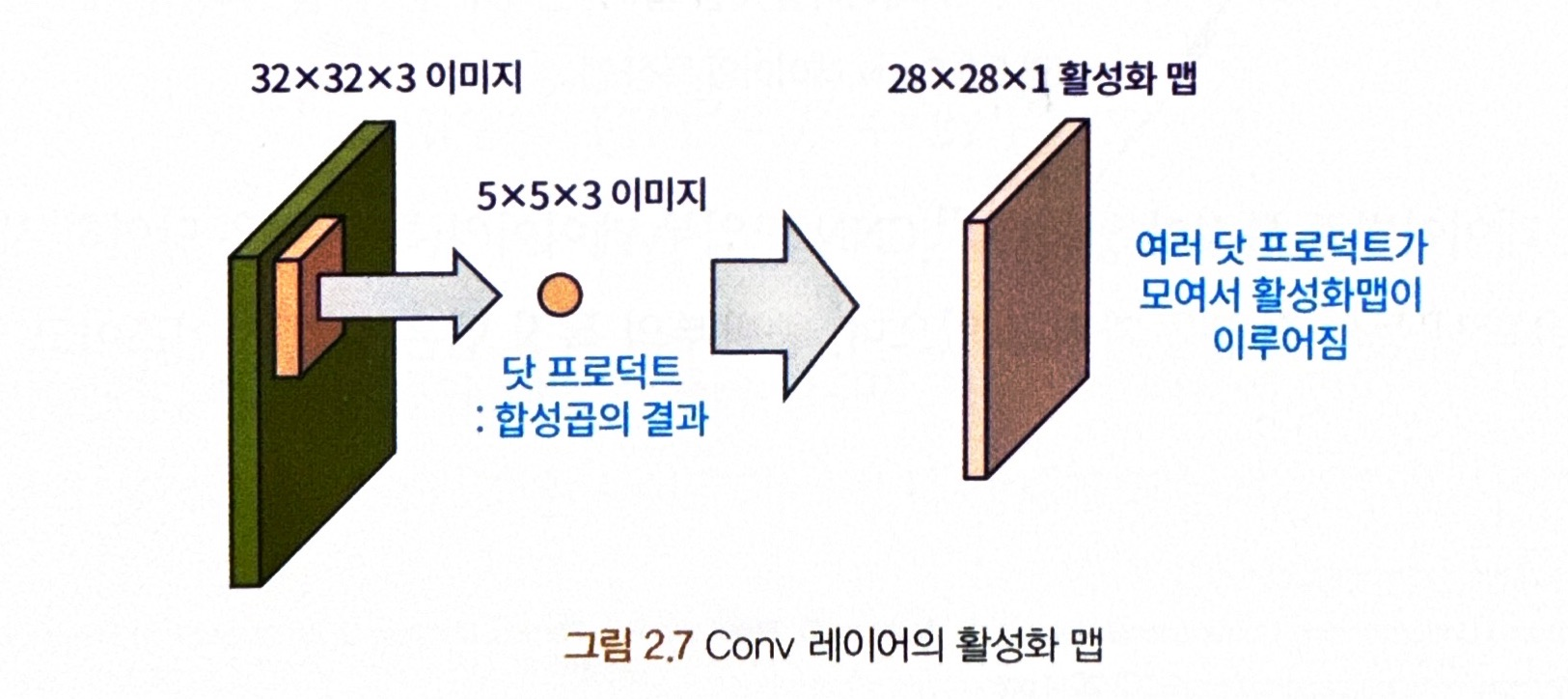
* 이러한 활성화 맵은 Conv 레이어의 산출물로서 다음 레이어의 입력값 역할을 함
- CNN에선 한 레이어에서 커널을 다수로 사용해 커널의 개수와 동일한 활성화 맵을 산출
--> 이유 : 필터가 많을수록 각 필터가 다른 특징을 추출하고, 필터의 개수만큼 활성화 맵이 생김 - 이러한 과정에서 Conv 레이어를 깊게 할수록 활성화 맵 개수는 늘고 사이즈는 작아짐
특징맵이란 ?
= CNN에서 훈련이 완료돼 결과가 나오는 시점에서, 원본 이미지의 특징들을 추출해서 가지고 있는 활성화 맵을 특징 맵이라고 함.
- 특징 맵은 레이어별로 특징이 있음
- CNN 도입부 특징 맵 : 큰 사이즈, 윤곽선 등의 특징
- CNN 중반부 특징 맵 : 중간 사이즈, 얼룩 무늬 등 패턴의 특징
- CNN 후반부 특징 맵 : 작은 사이즈, 눈,창문,바퀴 같은 구체적인 특징
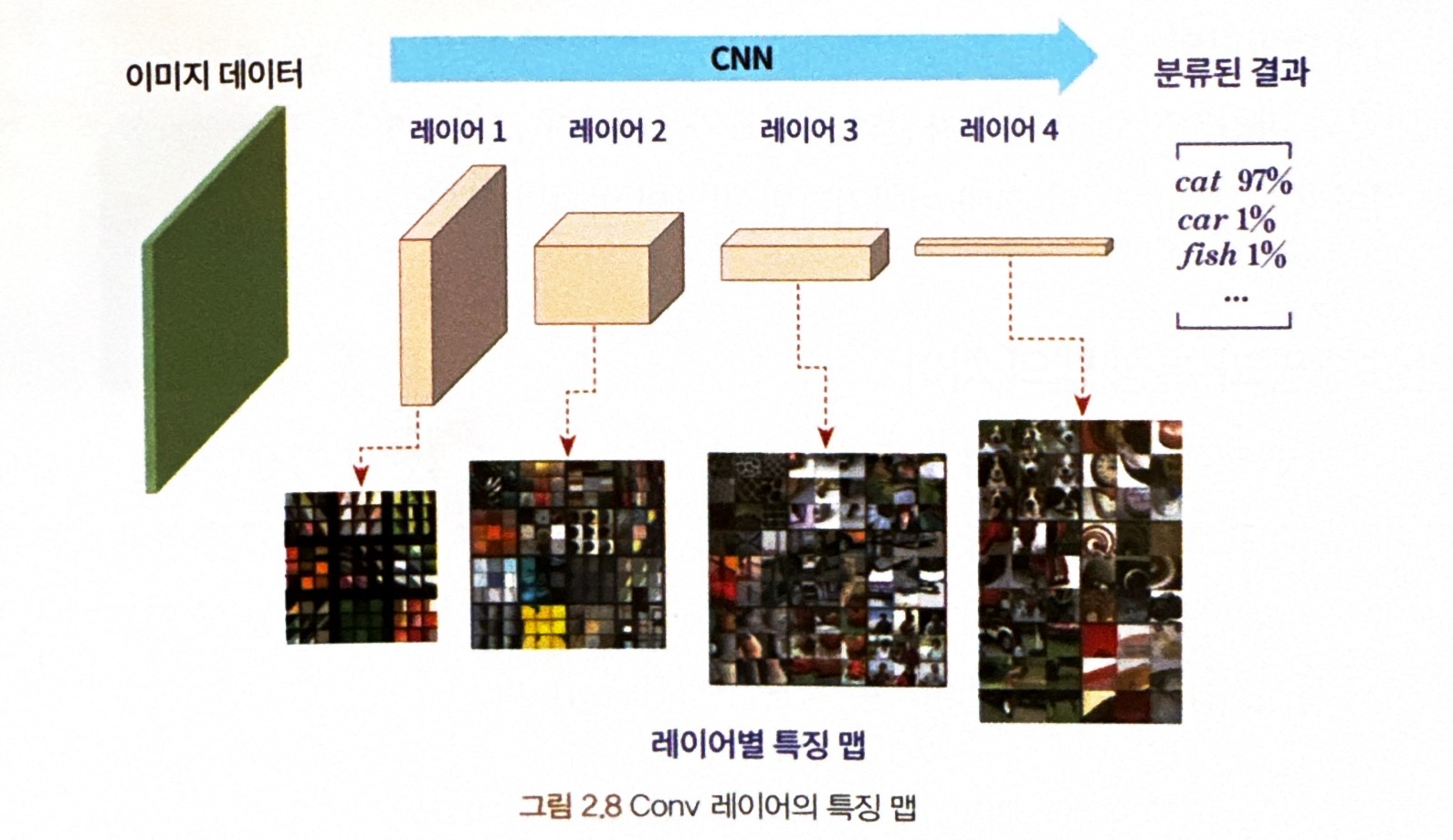
** 레이어를 깊게 할수록 대용량 데이터를 이용해 학습 속도를 빠르게 할 수 있음!!
** 다양한 학습데이터로 훈련해서 개의 특징 이해하고 분류 X --> 신경망을 깊게 함으로써 계층적으로 분해해 학습
2) Conv와 Pooling 레이어의 역할
Conv 레이어의 역할이란 ?
= Conv 레이러에서 콘볼루션 계산을 하는 동안 활성화 맵의 사이즈를 점점 줄어들게 한다.
활성화 맵 사이즈 : W2 x H2
** 활성화 맵 사이즈는 아래와 같은 요인에 따라 결정됨
- 입력 사이즈 : (W1 x H1)
- 커널 사이즈 : F
- 콘볼루션 과정에서 커널이 공간 이동하는 사이즈 : S (스트라이드)
** 콘볼루션 계산시, 활성화 맵 사이즈 공식
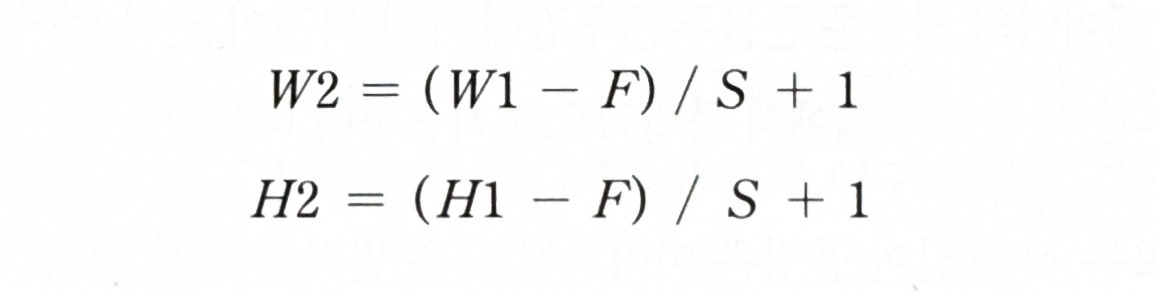
--> 마지막 레이어에 도달하면 섬네일 정도로 작은 사이즈의 특징 맵 상태가 됨
** 특징 맵의 사이즈가 작으면 좋은 이유
- 최종 분류를 위해 소프트맥스를 계산할 때 마지막 레이어의 맵(=특징맵)은 분류 클래스 개수와 동일한 벡터로 만들어야 됨
** 소프트 맥스는 고차원 데이터를 확률 분포로 변환하는 함수
ex) 최종적으로 10개의 클래스로 분류를 하고자 하면 마지막 레이어 맵은 1x10 벡터가 돼야 함.
--> 그 이유 : 1x10 벡터를 만들어야 소프트맥스 함수로 각 클래스의 예측 확률을 계산할 수 있음!!- 따라서 특징 맵의 사이즈는 작을수록 연산량이 줄어들어 계산하기 좋음 (특징 맵의 크기가 크면, 이를 분류 클래스의 개수만큼의 벡터로 변환하는 과정에서 많은 연산이 필요함)
<분류 결과가 산출되는 과정>
ex) 핸드폰 카메라로 찍은 사진(1024x768의 사이즈)을 10가지 동물 중 하나로 분류한다고 하자.
1. 거대한 입력 데이터가 오직 CNN 과정만으론 사이즈 10의 벡터로 축소시키긴 시간,비용 측면에서 어려움
2. 따라서 적당한 CNN 과정을 마치고 그 결과로 특정맵을 얻어냄.
3. 얻어진 특정맵에 FC 레이어를 2~4번 사용함해서 사이즈 10의 벡터까지 축소한다.
4. 축소된 벡터에 소프트맥스 함수를 사용해 분류 결과가 나옴
Pooling 레이어의 역할이란 ?
= 콘볼루션과 같이 계산 과정이 전혀 없이 사이즈가 줄어들게 하는 것
= 각 활성화 맵에서 독립적으로 작동하며 다운샘플링이라고도 불림
Pooling은 이미지에 작은 필터를 써서 필터 사이즈 내의 픽실에 대해 원칙에 따라 한 개의 픽셀값만 선택하고,
그 선택된 픽셀값만 남기는 방식으로 사이즈를 줄이는 방식 !!
ex) Max Pooling 과정
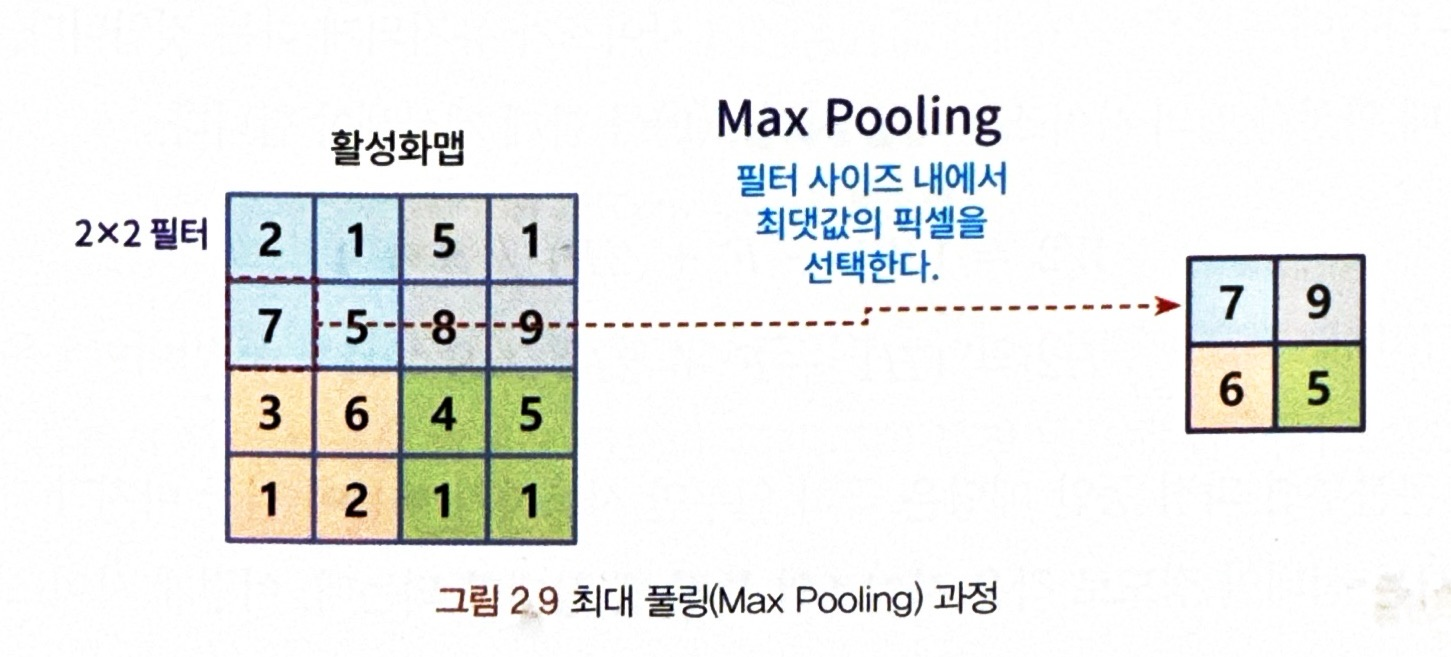
- 풀링에는 최소, 평균, 최대 등의 종류가 있음
- 딥러닝에선 풀링을 주로 사용 --> 추출된 특징을 가장 잘 보존한 상태로 사이즈가 줄어듦.
3. 딥러닝 학습 과정 준비
1) 데이터세트 준비
= 데이트세트는 학습해 완성활 모델을 위해 가장 적합하고 좋은 데이터가 대량으로 필요
- 전체 연구 개발 기간에서 데이터세트 준비 기간이 오래 걸림
- 따라서 초기 연구엔 오픈 데이터세트를 많이 이용
2) 데이터 전처리
= 통계,머신러닝,딥러닝을 하기 전에 항상 데이터 전처리가 필요함
- 일반 데이터의 경우 : 전체 데이터의 값이 음수 or 양수로 치우치지 않게 주성분 분석, whitening 변환을 해줘야함
- 이미지 데이터의 경우 : 평균값 빼기(Subtract Mean)을 해준다.
3) 오버피팅
= 특정 데이터세트에만 적합하게 훈련되어 실제 데이터에서는 잘 예측하지 못하는 상태(=과적합)
오버피팅을 피하는 방법
1. 데이터를 학습용 데이터, 테스트 데이터, 평가 데이터로 분할하기
(평가 데이터는 전체 데이터의 5~25% 정도로 분리해 학습 과정에서 별도로 이용함)
--> 기본적인 과적합 발생을 막아주는 역할
2. 가중치에 대한 정규화를 해줌
= 학습 과정에서 큰 가중치에 대해 그에 상응하는 큰 페널티를 부과해 오버피팅을 억제
ex) L1,L2 정규화 or 엘라스틱(L1+L2)
4) 활성화 함수
= 한 노드에서 이전 레이어의 계산된 결괏값이 들어올 때 이를 바로 다음 레이어로 출력하지 않고 뉴런의 출력을 모델링하는 활성화 함수를 사용
= 딥러닝 네트워크의 레이어를 다중으로 깊게 구성해 더 정확한 모델을 만들고자 비선형 함수를 사용
(신경망에 비선형성을 더해 비선형이 딥러닝에서 중첩되어 더 복잡한 특징도 표현 가능)
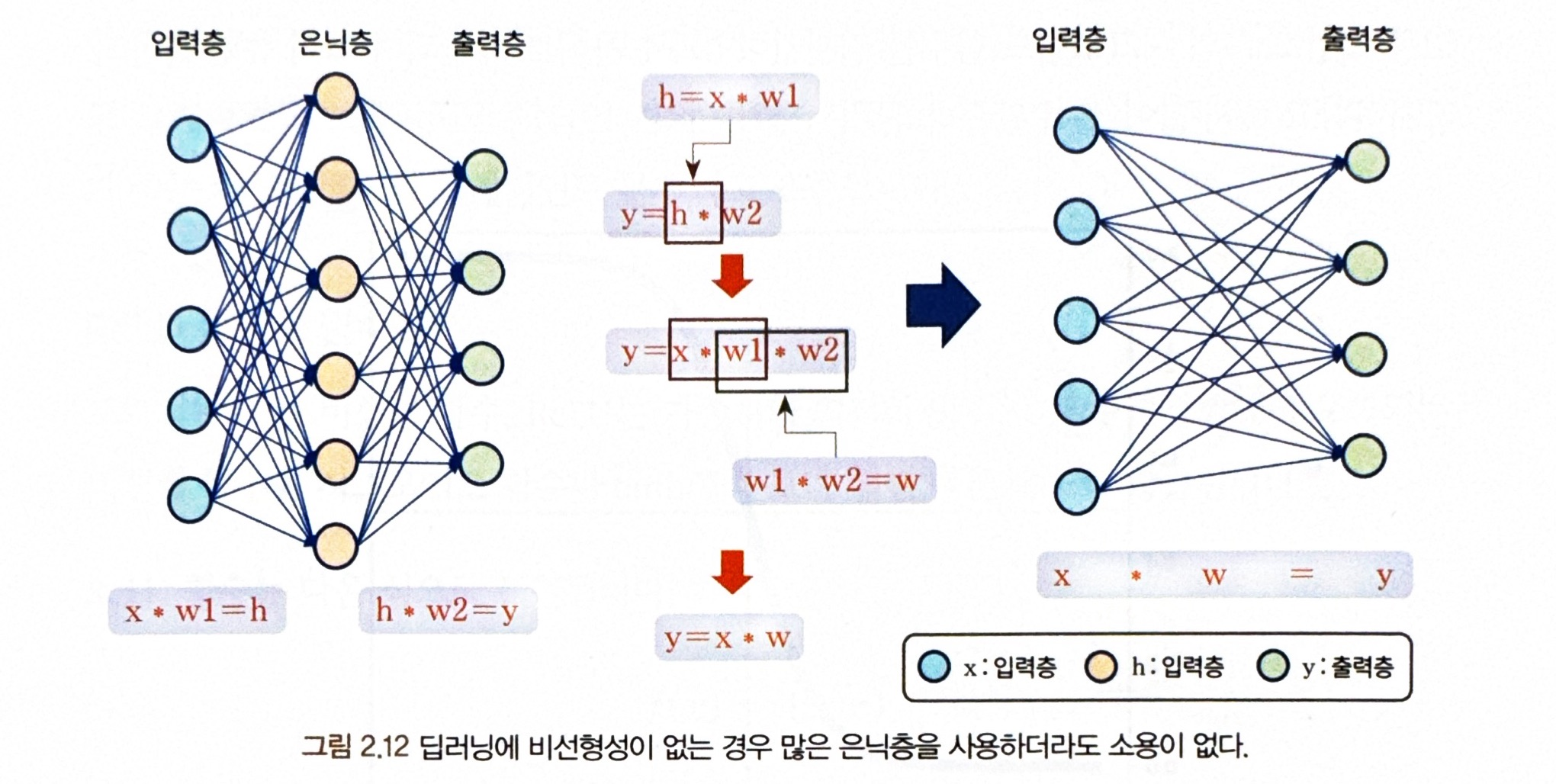
** 딥러닝에 비선형성이 없는 경우 = 많은 은닉층을 사용해도 소용이 없음
= 선형 변환만을 반복하면 결국 결과는 또 하나의 선형 변환이기에 은닉층이 몇 개가 있더라도 실제로 없는 것과 동일!
ex) y=2x라는 함수를 3개의 은닉층을 두어 계산하는 경우
y=2(2(2x)))이라는 선형 변환으로 학습이라는 효과를 얻을 수 없음!!
** 각 은닉층의 뉴런을 선형 함수의 결과에 대해 비선형 함수인 활성화 함수를 적용하면 딥러닝은 하나의 은닉층마다 선형함수 + 비선형 변환의 조합을 가짐 !!
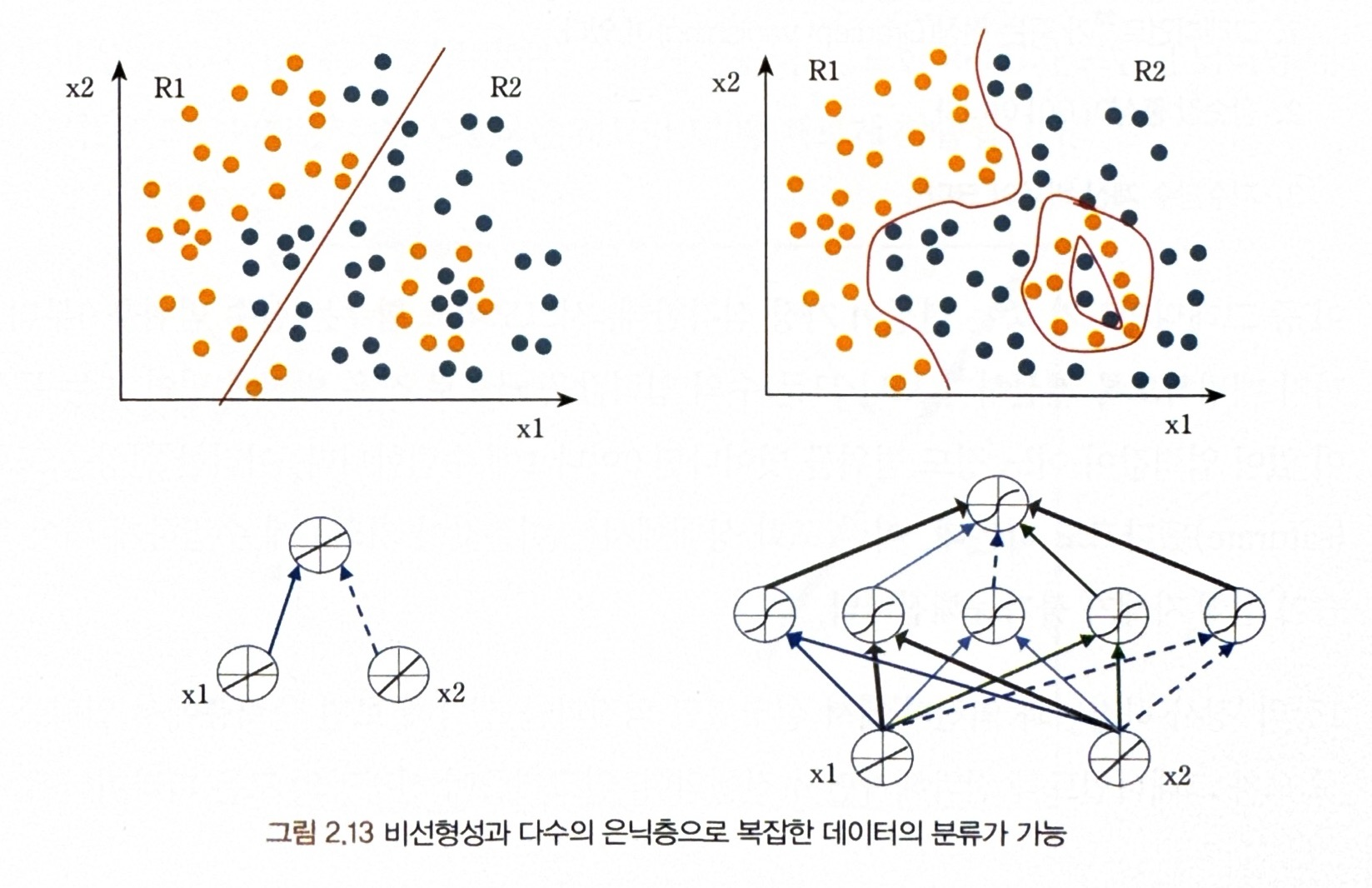
- 2계층 네트워크 분류기(선형 함수)는 선형 판정 경계만 구현 (왼쪽 그림)
- 비선형을 포함한 여러 개의 은닉층을 다층으로 깊게 만들면 복잡한 데이터를 구분하는 임의의 판정 경계를 구현 (오른쪽 그림)
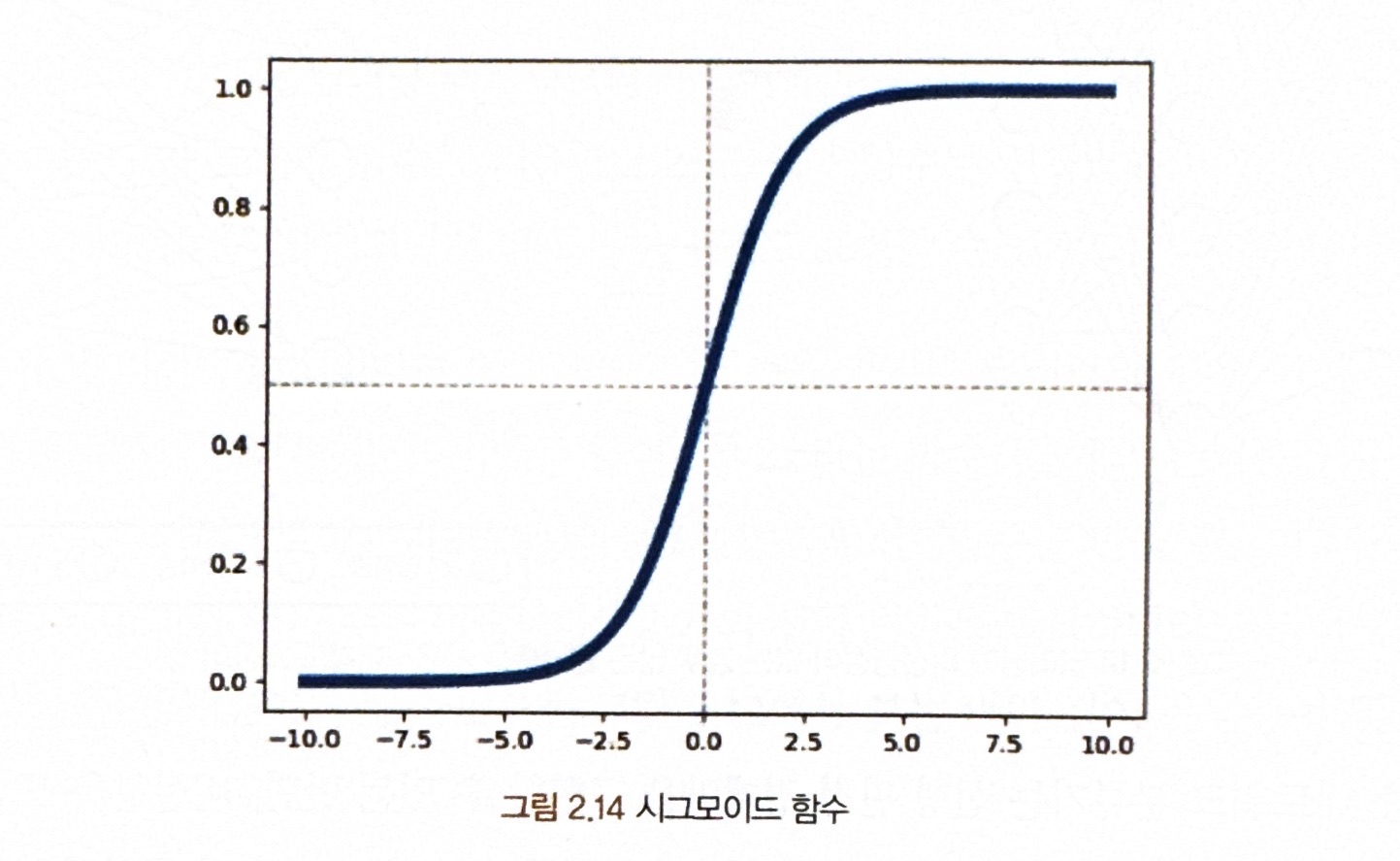
<시그모이드 함수>
= 시그모이드 함수는 결괏값이 0과 1사이로 제한되며 뇌의 뉴런 작용과 유사해 많이 쓰여왔음.
시그모이드 함수의 문제점
- 그래디언트가 죽는 형상이 있음(배니싱 그래디언트 문제)
- 함숫값 중심이 0이 아님
- 지수함수 계산 비용이 큼
* 이중 그래디언트가 죽는 현상이 가장 심각한 문제!!
** 그래디언트가 죽는 현상(=배니싱 그래디언트 문제)
시그모이드 함수는 실수 범위를 0~1까지 매핑하도록 계산하다 보니 모든 수의 입력값을 극도로 작은 범위에 밀어 넣는 특성이 존재
= 입력값이 어느 정도 범위를 벗어나면 0이나 1에 수렴해 이러한 현상을 포화 현상이라고 함
- 그래디언트가 포화 상태되면 미분값이 거의 0에 수렴하게 되어 학습이 진행 자체가 불가능!!!(=배니싱 그래디언트 문제)
<ReLU 활성화 함수>
= 포화되지 않는 비선형 함수
= ReLU는 가중치의 최적화 방법인 경사 하강법에서 포화되는 비선형 함수인 시그모이드나 tanh 함수보다 빠른 속도로 학습됨.
- 컴퓨터 비전과 음성 인식 등의 딥러닝에서 널리 사용
ReLU 활성화 함수의 장점
- 비선형이며 시그모이드 함수와 달리 포화되지 않음
- 배니싱 그래디언트 문제를 방지하는 효과
- 시그모이드 함수를 사용하는 것보다 몇 배 빠르게 학습
* ReLU 함수식
입력이 0보다 작으면 0을 출력하고, 그렇지 않으면 입력과 동일한 출력을 내놓음
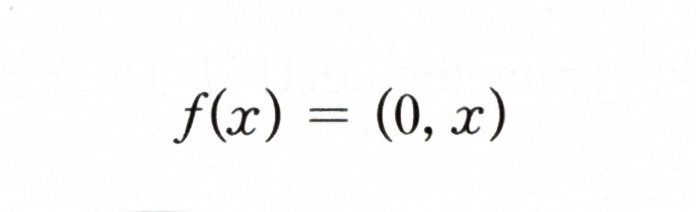
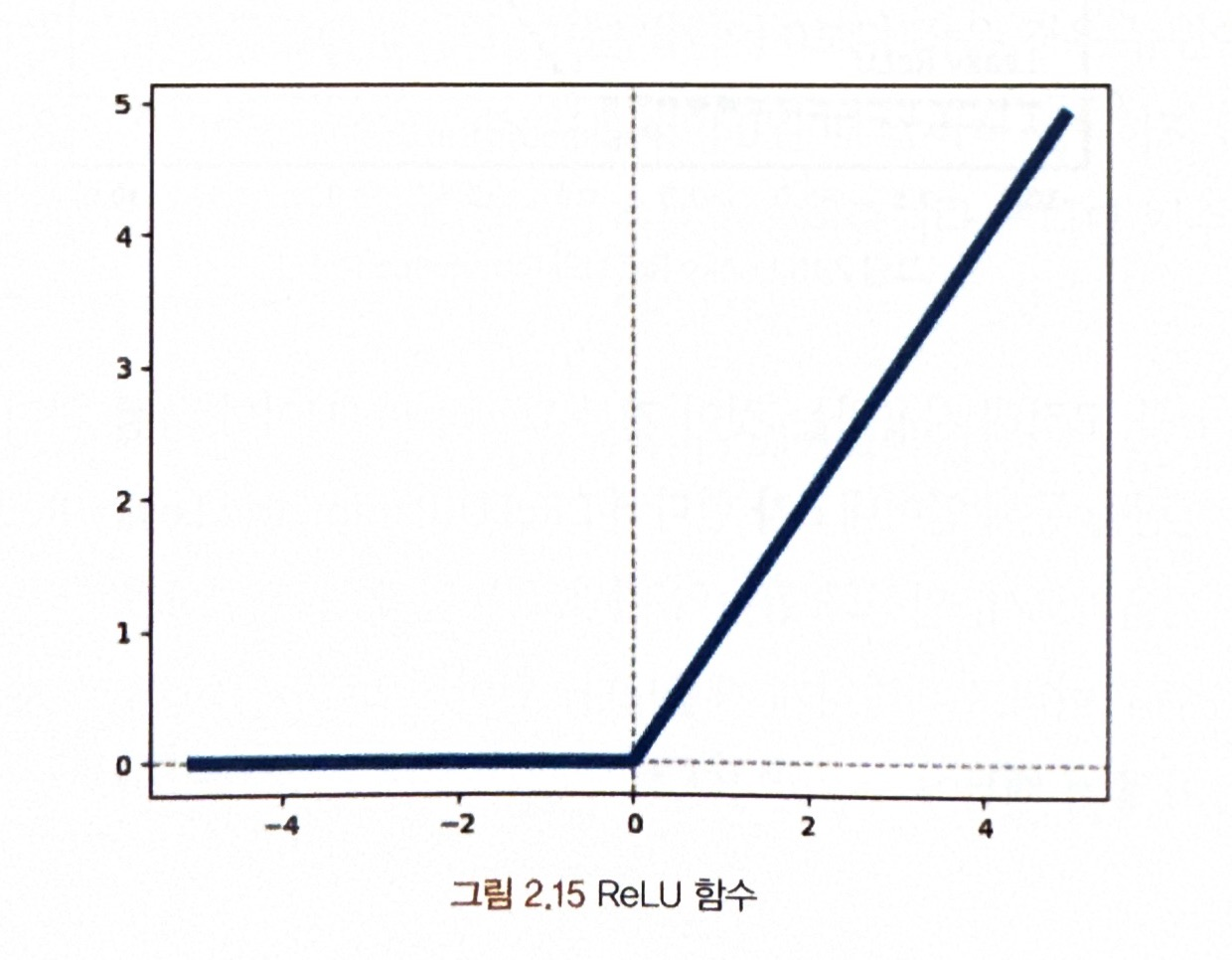
but 입력 데이터에 이미지의 픽셀 데이터와 같은 음수 데이터가 있다면 그래디언트가 0이 되기 때문에 뉴런은 죽는 문제가 생김!! --> 해결하기 위해 Leaky ReLU , ELU 사용
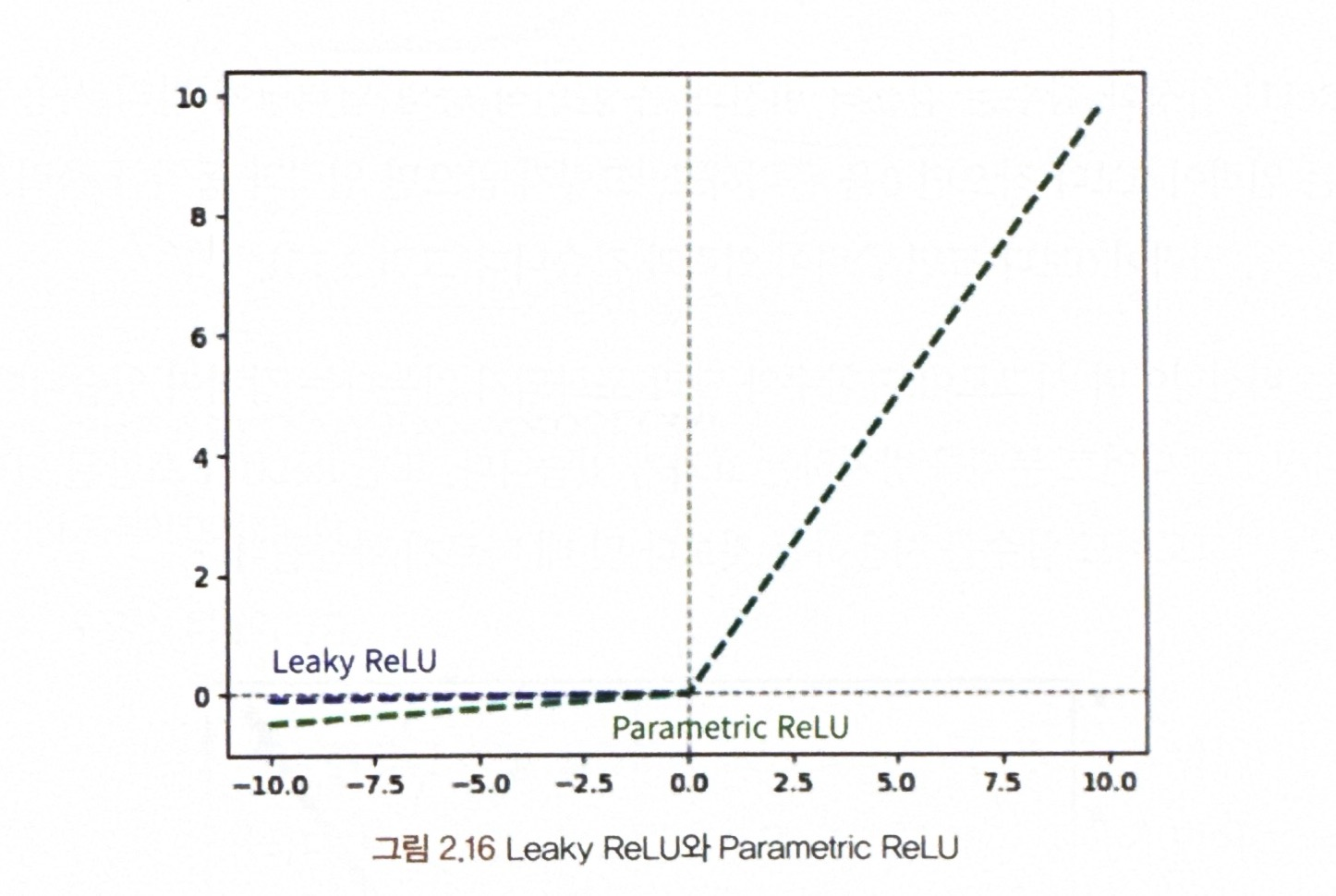
<포화되지 않는 활성화 함수들>
- Leaky ReLU
- ELU
* Leaky ReLU 함수식
- a는 작은 기울기로서, 활성화 함수의 결과로 뉴런이 죽는 현상을 방지해주고 ReLU의 범위를 음수 데이터로 확장해줌
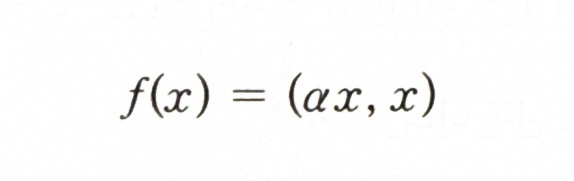
- a를 고정해 사용하는 것이 기본 Leaky ReLU이며, a를 하이퍼파라미터로 해 역전파로 훈련을 통해 얻어내면 PReLU(=Parametric LEaky ReLU)가 됨.
- 일반적으로 a를 0.01로 사용하는 Leaky ReLU가 성능이 좋음
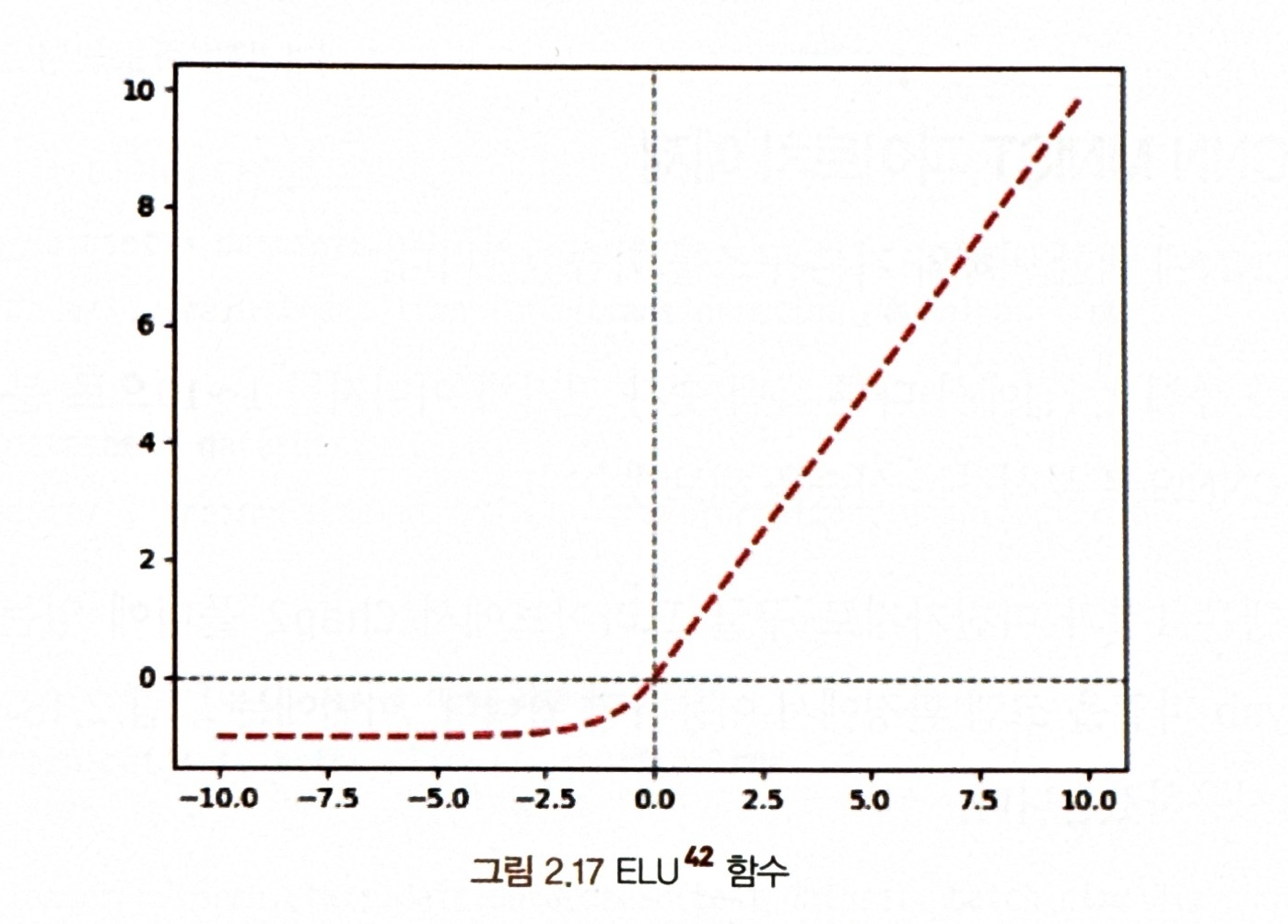
* ELU 함수식
= Leaky ReLU와 유사하게 ELU는 음숫값에 대해 작은 기울기를 갖지만, 직선 대신 로그 곡선을 사용
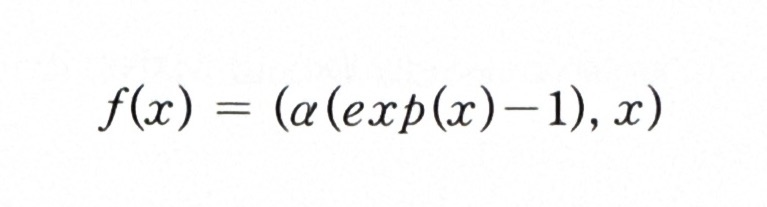
- 입력이 0보다 작은 경우 : 평균 출력을 0에 가깝게 출력해 준다.
- 입력이 0일 때 : 급격히 변동하지 않고 모든 구간에서 출력이 매끄럽게 나와 경사 하강법의 속도를 높여줌(Leaky ReLU와 비교하면 더 매끄러움)
- 단점 : 지수함수를 사용하기에 계산 비용이 높아짐