✅Section04. 데이터 세트 분할 및 모델 성능 평가 지표
📌 Train/Test 데이터 세트 분할
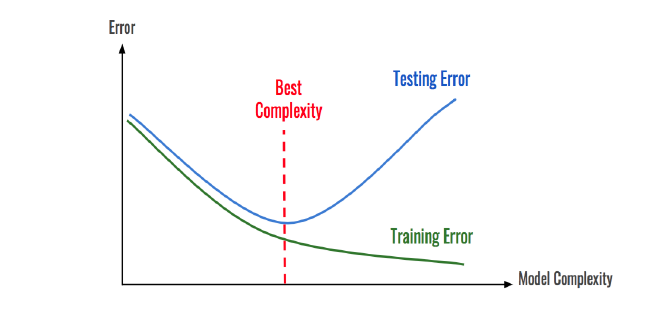
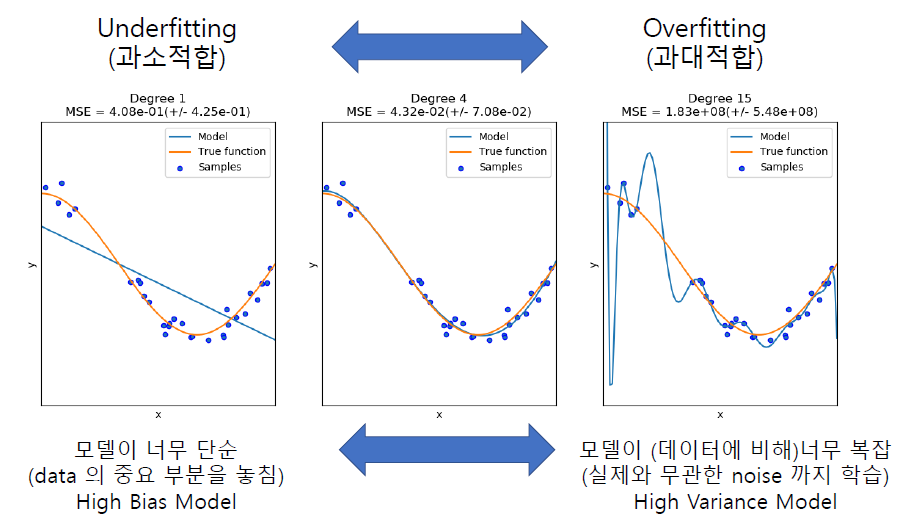
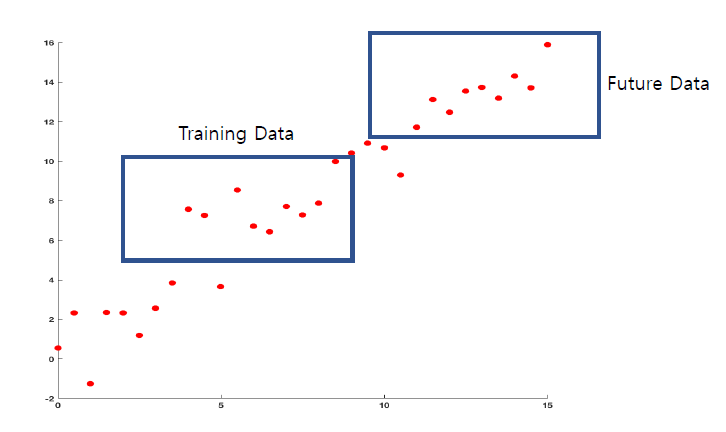
🏷️Overfitting 과 Underfitting
- 과적합 : 학습 데이터에만 너무 잘 맞춰진 상태라, 테스트 데이터에선 오류가 높게 나는 경우
- 과소적합 : 반대로 모델이 너무 단순해서 학습 데이터 조차 패턴을 충분히 학습하지 못한 경우
** 사진과 같이 학습, 테스트셋에서 모두 에러가 최소화되는 지점을 찾아야함
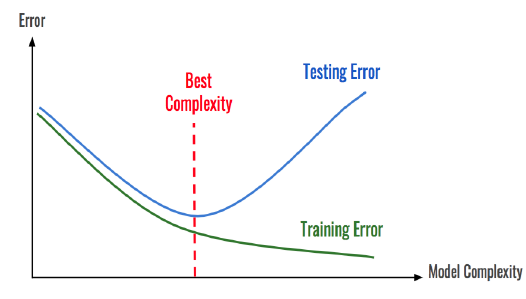
🏷️Bias-Variance Trade-Off
머신러닝의 세 가지 Error Source
1. 학습 데이터와 실제 데이터 분포의 차이에 의한 에러 --> Variance(분산)
2. 근사치로 만들어낸 모델과 실제 함수의 차이에 의한 에러 --> Bias(편향)
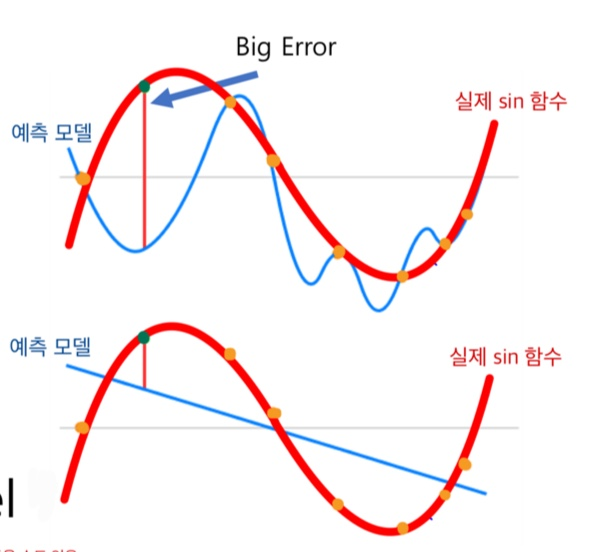
- 무조건 모델이 복잡하다고 좋은게 아님!!
- 목적에 맞게 복잡한 모델 사용할지, 단순한 모델을 사용할지 결정해야함
3. Noise에 의한 에러 --> 이건 제거할 수 없음
📢 분산을 줄이려면 데이터셋의 크기를 늘이고, 편향을 줄이려면 모델의 복잡도를 올린다.
Bias-Variance Trade-off
= 편향을 줄이려면 모델의 복잡도를 올려야되는데 모델의 복잡도를 올리면서 과적합이 되지 않으려면 데이터가 많아져야함.(돈,시간이 들어가 데이터를 한정적으로 쓸 수 밖에 없음)
📢 현실에선 데이터를 무한으로 얻을 수 없고, 실제 함수를 알 수 없으니 간접적인 방법을 사용함 --> Cross Validation , Precision/Recall/F1-Score
🏷️Training & Testing Set
✏️ Training set
= 모델을 훈련시키는데 사용하는 데이터
= 새로운 데이터가 훈련 데이터셋과 다를 경우 문제가 발생
= 훈련 세트 내에서 교차 검증 세트를 구성함 (데이터가 부족할 떄)
✏️ Testing set
= 학습한 머신러닝 모델을 테스트하기 위해 사용하는 데이터
= 미래의 데이터인 것처럼 간주
⚠️ 주의할 점) 훈련 세트와 테스트 세트는 섞이면 안되고 동일한 분포를 유지(=같은 데이터셋에서 분할만 했기 때문에)
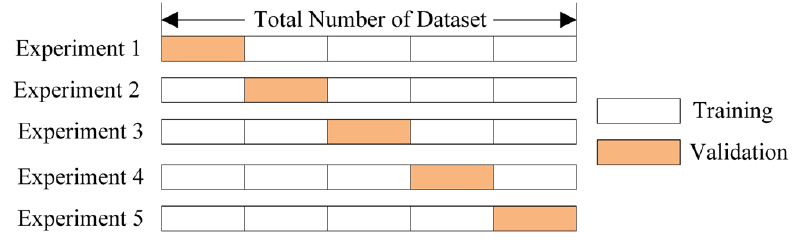
🏷️Cross Validation (교차검증)
= 훈련셋을 여러 개의 서브 셋으로 나누고 각 모델을 이 서브세트의 조합으로 훈련시키고 나머지 부분을 검증용으로 사용
- 데이터의 수가 적은 경우에 사용하는 기법
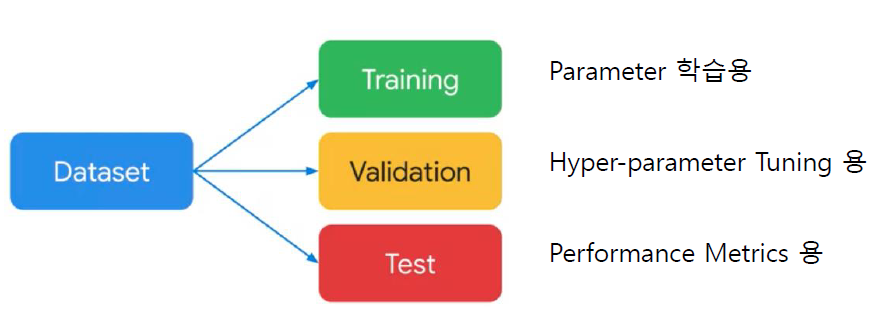
🏷️Dataset Split - 3 splits
일반적으로 3개로 나누는 것이 이상적이지만 데이터가 충분하지 않을 경우에 트레인용 , 테스트용 2개로 나눔.
📌 지도학습 모델의 분류 성능 평가
🏷️Confusion Matrix (혼동 행렬)
= 모델이 예측한 결과와 실제 정답을 비교해, 맞춘 경우와 틀린 경우를 각각 분류해 나타낸 표
- Classification 분류 성능의 정확성 측정
- 우리의 목표는 99%의 정상 데이터, 1%의 비정상 데이터가 있을 때, 비정상 데이터를 얼마나 잘 맞췄는지 측정하는 것
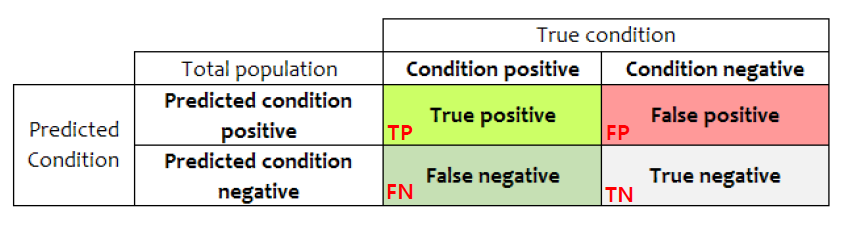
단순 정확성 : 전체 데이터 중에서 제대로 분류된 데이터의 비율
Accuracy = (TP + TN) / (TP+TN+FP+FN)
🏷️Confusion Matrix를 이용한 분류 모델 성능 평가(Precision, Recall)
📌 Precision(정밀성) = TP / (TP + FP)
Positive로 예측한 내용 중에, 실제로 Positive의 비율
--> 모델이 샘플을 True로 분류했을 때 얼마나 자주 맞추는가 ?
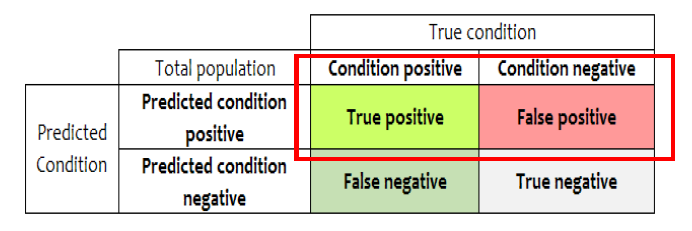
** 빨간 박스가 모델이 Positive이라고 예측한 부분의 전체를 의미함
--> 이 중에서 True positive의 비율 !
📌 Recall(재현율) = TP / (TP + FN)
전체 Positive 데이터 중에서 Positive로 분류한 비율
--> Positive case를 놓치고 싶지 않은 경우의 성능을 측정
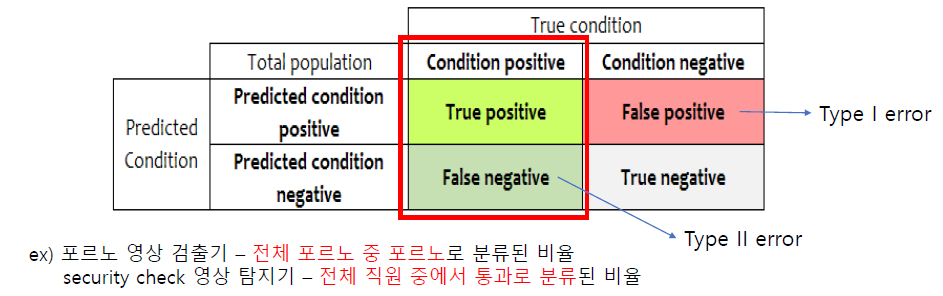
🏷️Precision/Recall Trade-off
내가 Precision(정밀성)을 높일 것이냐, Recall(재현율)을 높일 것이냐 목적에 따라서 Thresholds(기준)을 정해준다 !!
기준을 높이면 Precision(정밀성)은 올라가지만, 그만큼 Recall(재현율)이 감소함.
ex) Thresholds을 50% 이상으로 설정한 경우
- 5라고 예측한 전체 데이터 : 5개
- 전체 5의 개수 : 6개
- 예측한 게 실제로 5인 경우: 4개
- Precision : 4/5 = 80%
- Recall : 4/6 = 67%
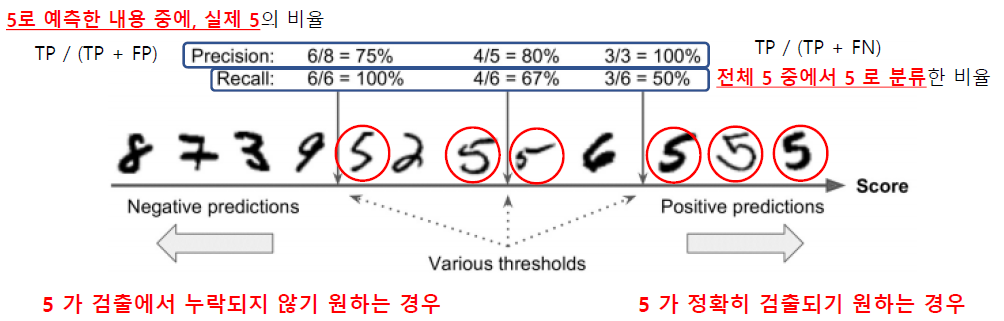
- 신뢰 수준을 높이고 싶으면(정확도) Precision을 높이고, Recall을 낮춤
- 너무 많은 case를 놓치고 싶지 않은 경우 Recall을 높이고 Precision은 낮춤
🏷️ F1-Score : 전체적인 성능 측정에 활용 (조화 평균)
0~1 사이의 값, 1에 가까울 수록 성능이 좋음.
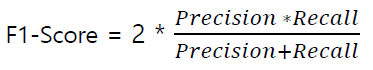
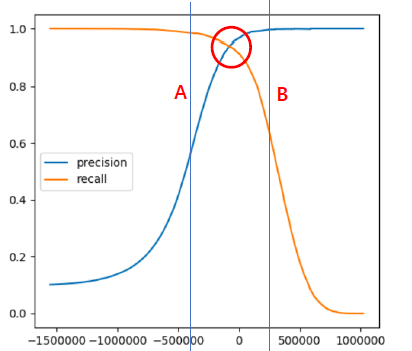
- 그림과 같이 precision, recall이 모두 높은 지점을 찾아야함.
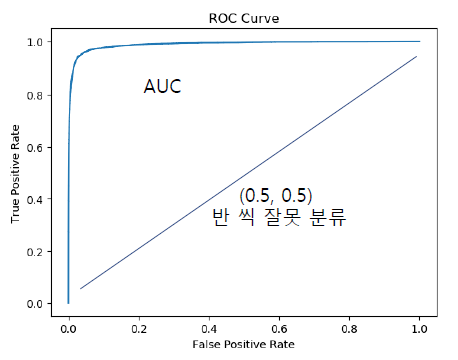
🏷️ROU Curve(수신자 조작 특성 곡선)
- ROC_AUC 라도고 불림
- roc_auc_score를 이용하여 여러 개의 모델 분류기 간의 성능 비교가 가능
--> 아래 면적이 클수록 좋은 분류기임.