✅Section03. 전통적 머신 러닝 - 지도학습 모델 part 1
📌머신러닝 End-to-End 과정
🏷️머신러닝 과정
문제 정의 --> 데이터 준비 --> 모델 선택 --> 모델 작성 --> 모델 평가 --> 모델 개선 --> 결과 보고
🏷️ Model 작성 순서
1단계) 라이브러리 선언 : sklearn, numpy, pandas, matplotlib, etc
2단계) 데이터셋 로드 : csv, sklearn.datasets, etc
3단계) 데이터 내용 파악 : shape, statistics, visualize
4단계) Train / test dataset 분할 : sklearn, manual
5단계) Feature Scaling(정규화)
6단계) Model 객체 생성하기
7단계) Model 훈련하기 : fit()
8단계) Model 평가 : 평가지표 출력, plotting
9단계) Best Model 선택
📌선형 회귀 모델 설명
🏷️단변수 선형 회귀
= 한 개의 변수로 결과 예측 ex) 혈압으로 당뇨병 여부 예측
- 단변수 선형 회귀 모델은 시각화가 가능
- x (입력데이터), y (정답)가 주어지고 w, b가 미지수 --> w, b를 추정해야함
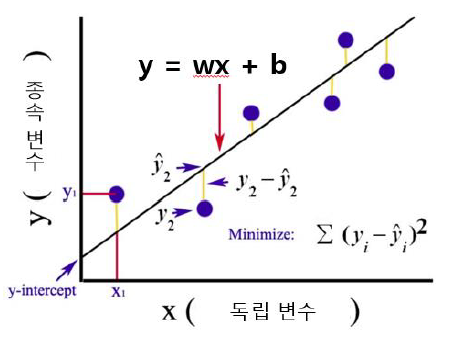
🏷️비용 함수
y = wx + b --> 가설, 모델
-
데이터들을 가장 잘 표현한 모델 라인을 그려야함
-
비용 함수의 목적 : 가설 또는 우리가 설정한 모델이 얼마나 틀렸는지 측정
-
오차 : (실제 데이터의 값) - (예측값)
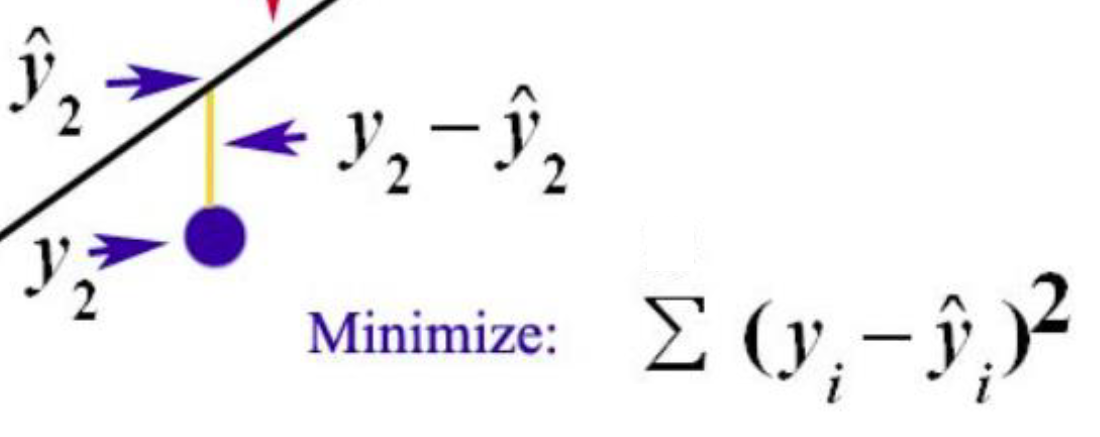
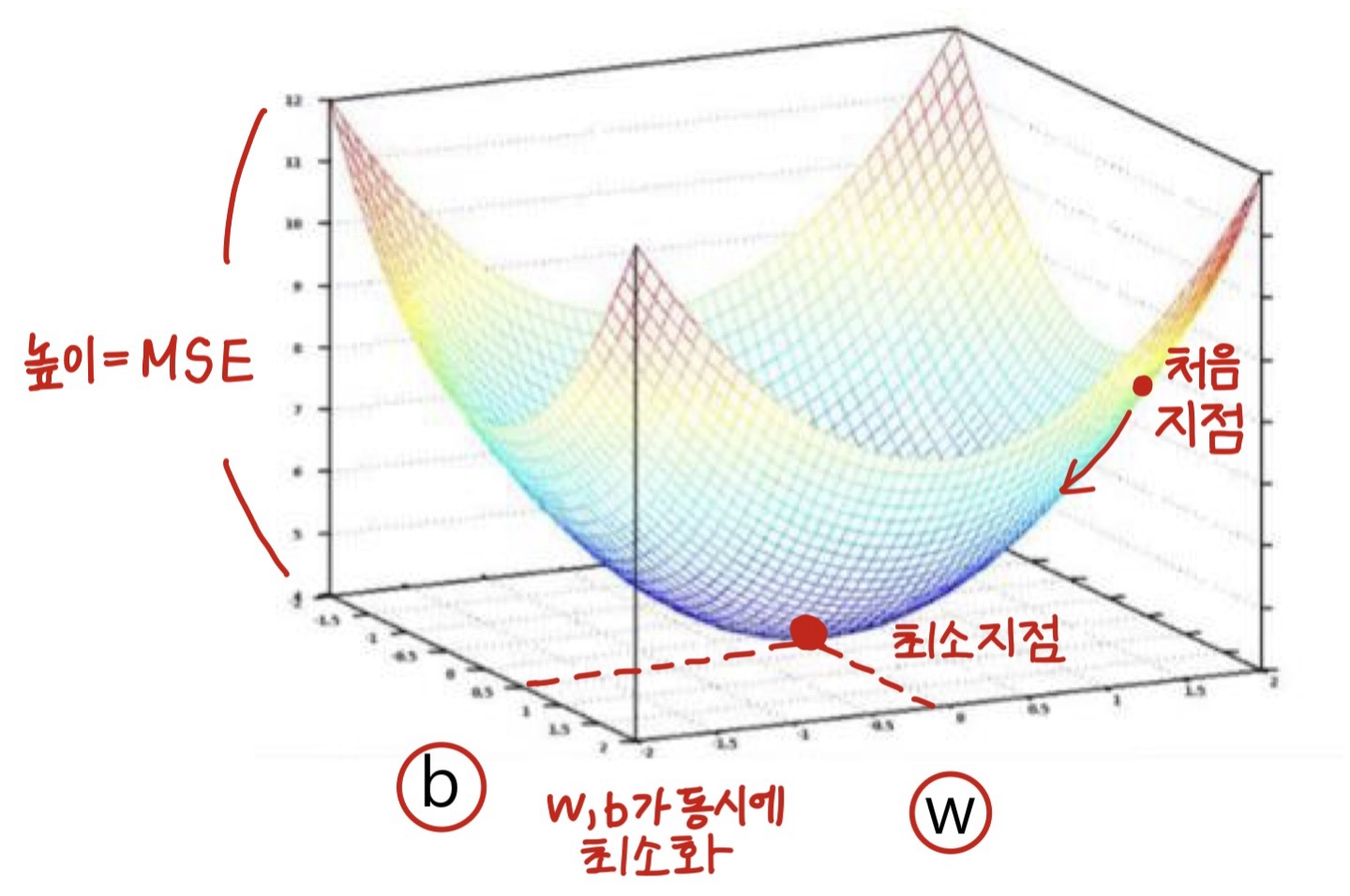
📢 평균제곱오차(MSE)
= 실제 값과 예측 값의 차이를 제곱한 뒤 평균을 낸 값
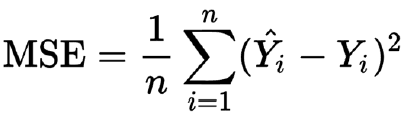
아래 그림의 MSE 그래프를 최소화하는 w와 b를 최적화함.
🏷️선형 회귀의 Accuracy(정확도) 측정
- 평가기준 : R2 score (결정계수)
from sklearn.metrics import r2_score0 <= R2 <= 1 , 1에 가까울수록 정확하고, 훈련이 잘되었음.

🏷️다변수 선형 회귀
선형 회귀모델과 달리 변수가 X1,X2,X3..다변수임

📌실습) 선형 회귀 모델 - 당뇨병 진행률 예측
1. 라이브러리 선언
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn import datasets, linear_model
from sklearn.metrics import mean_squared_error, r2_score2. 당뇨병 데이터셋 로드
파이썬의 딕셔너리 형태로 내장되어 있음
dia = datasets.load_diabetes()
dia3. 데이터 내용, 구조 확인
print(dia.DESCR) # 데이터셋에 대한 설명을 알고 싶을 때
dia.feature_names # 피처 이름 확인
dia.data.shape # 데이터 구조 확인
dia.target.shape # 정답(target) 구조 확인
df = pd.DataFrame(dia.data, columns = dia.feature_names)
df.head() # 데이터프레임 첫 5행 확인 4. 시각화를 하기 위해 피처 1개 선택
📢 시각화를 하기 위해 10가지 피처 중 1개만 선택 (BMI 선택)
dia_X = df['bmi'].values
dia_X.shape # (442,) vector 형태로 이뤄져 있음📢 sckit learn의 입력 데이터는 Matrix 형태, 2차원 Array 형태로 만들어줘야함.
dia_X = df['bmi'].values.reshape(-1,1)
# -1로 설정해주면 자동으로 차원으로 맞춰놓음
dia_X.shape # (442,1) 2차원 배열 형태로 reshape됨.5. 데이터셋을 훈련/검증용으로 분할
직접 배열 인덱싱으로 분할하는 방법
📢 입력 데이터(feature)를 훈련/검증용으로 분할하기
dia_X_train = dia_X[:-20] # 앞에서부터 20개
dia_X_test = dia_X[-20:] # 뒤에서부터 20개
# train 데이터 422개, test 데이터 20개로 나뉘어짐.
dia_X_train.shape, dia_X_test.shape✅ 실행결과 : ( ( 442 , 1 ) , ( 20 , 1 ) )
📢 정답 데이터(label, target)를 훈련/검증용으로 분할하기
dia_y_train = dia.target[:-20]
dia_y_test = dia.target[-20:]
dia_y_train.shape, dia_y_test.shape✅ 실행결과 : ( ( 442, ) , ( 20, ) )
6. Linear Regression 모델 학습
📢 sklearn model 이용
이미 스케일링 된 상태, 이제 모델에 입력해서 모델 훈련하는 단계
📢 모델 인스턴스를 생성한 후, fit 함수를 이용해서 모델 훈련
# 인스턴스 생성
regr = linear_model.LinearRegression()
# X_train과 거기에 매칭되는 정답 데이터를 주고 모델 훈련시킴
regr.fit(dia_X_train, dia_y_train) 
7. 모델 예측 결과
# 테스트로 분할했던 20개 데이터를 여기에 입력 해줌
y_pred = regr.predict(dia_X_test)
y_pred # 모델이 예측한 값
# dia_y_test 우리가 알고 있는 정답 레이블 
8. 시각화
모델이 예측한 값이랑 정답이 얼마나 비슷한지 시각화해보자.
# 실제 데이터에 대한 산점도 시각 , 파란색 점은 실제 데이터
plt.scatter(dia_X_test, dia_y_test, label = "True value")
# 빨간색이 모델이 예측한 회귀 라인
plt.plot(dia_X_test, y_pred, color = "r", label = "Predicted")
plt.xlabel('bmi')
plt.ylabel('Progress') #진행률
plt.legend() # 범례 표시 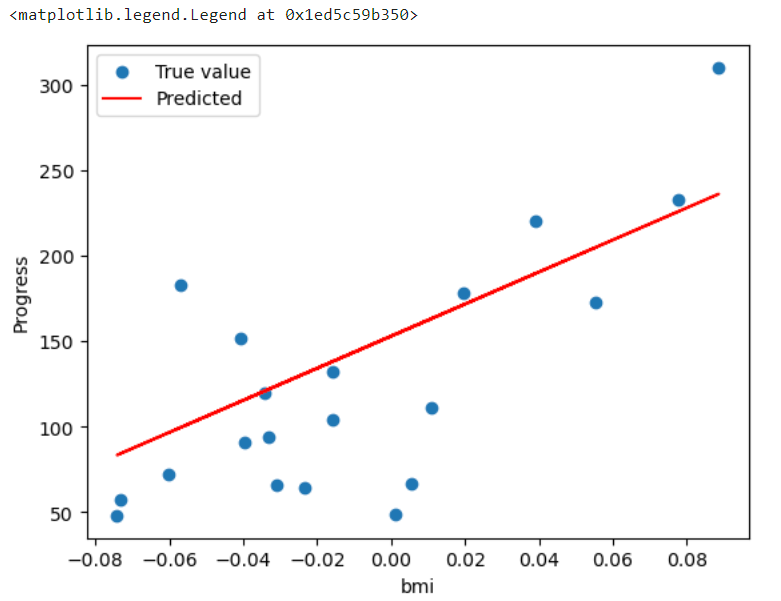
9. 정확도 평가, R2 계산
# 매개변수에 정답 레이블, 모델 예측값을 넣어준다.
r2_score(dia_y_test, y_pred) # R2 계산
mean_squared_error(dia_y_test, y_pred) # MSE 계산R2_Score : 0.47257 (약 47%의 정확도를 가짐)
📢 다변수 선형회귀 모델 실습
= 10개의 피처를 다 사용한 경우
dia_X = df.values # 모든 피처를 다 선택 R2 점수 :0.5850⭐ 결론 : 단변수(BMI)를 쓴 경우보다 모든 피처를 다 사용할 때 정확도가 더 높게 나옴
📌K-최근접 이웃 알고리즘
🏷️KNN(K-Nearest Neighbors) 이란 ?
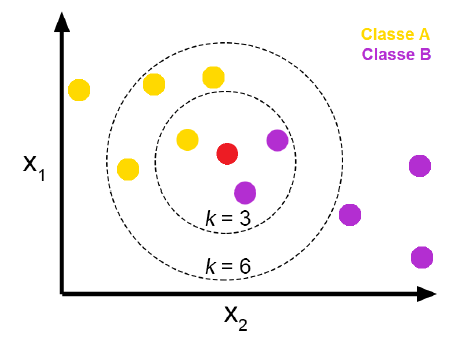
= 새로운 데이터를 가장 가까운 K개의 이웃 데이터의 레이블들 중에 가장 많은 것으로 분류하는 방식
- 다른 관측치과의 유사성에 따라 분류
ex) K = 3일 때, 가장 가까운 3개의 이웃 데이터 중 클래스A 1개, 클래스B 2개 --> 새로운 데이터는 클래스B로 분류됨.
📝 장점 : 이해하기 쉬움
📝 단점 : 데이터셋이 커지면 학습 속도가 느려짐, 이상치/결측치의 영향이 큼
🏷️KNN 알고리즘
1단계) K값을 선택한다.
2단계) Unknown case와 모든 데이터 포인트 간의 거리를 계산한다
- 피타고라스 정리에 의한 유클리드 거리 계산을 함.
3단계) 훈련 데이터셋에서 unknown 데이터 포인트와 가장 가까이 있는 K개의 관측치를 선택함
4단계) unknown 데이터 설정
[분류의 경우] K개의 가장 가까운 이웃들의 label 중 가장 많은 것을 unknown 데이터 포인트의 클래스로 분류함 (= classification)
[회귀의 경우] K개의 가장 가까운 이웃들의 레이블 값의 평균을 예측된 값으로 계산함 (=regression)
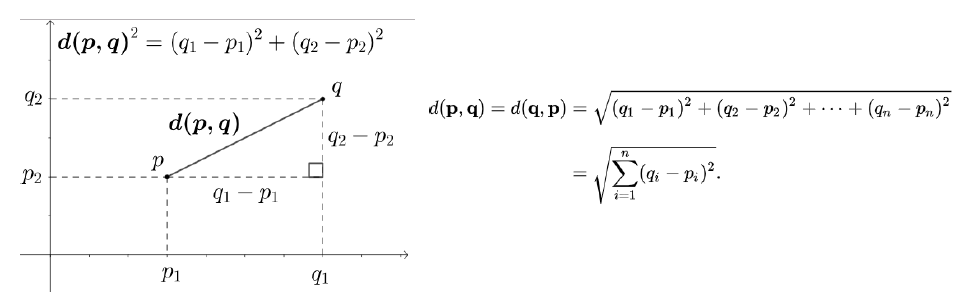
📌실습) K-최근접 이웃 모델 - 붓꽃 데이터 분류
✅ iris dataset
4가지의 피처 (꽃받침의 길이, 꽃받침의 너비, 꽃잎 길이, 꽃잎 너비) 으로 꽃의 종류를 3종류로 구분함 (setoda / versicolo / virginica)
1. 라이브러리 선언
import numpy as np
from sklearn.datasets import load_iris
from sklearn.neighbors import KNeighborsClassifier2. 데이터셋 로드 / 내용 확인
- 데이터셋 로드
iris = load_iris()
iris- 데이터 내용 확인
iris.data.shape
iris.feature_names, iris.target_names # 0,1,2이 매칭
# 0 : setosa , 1 : versicolor, 2 : virginica
X = iris.data[:,:2]
y = iris.target
X.shape, y.shape
# 실행결과 : (( 150, 2) , (150, ))
3. 데이터셋을 훈련, 검증용으로 분할
📢 sklearn에서 지원하는 train_test_split 기능 사용
test_size = 0.2로 주면 80%는 훈련 세트, 20%는 테스트 세트로 분리됨
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X,y, test_size = 0.25, random_state = 100)
X_train.shape, X_test.shape, y_train.shape, y_test.shape # 150을 8(120):2(30)으로 나눠줌.
((150, 2), (150,)) 훈련 데이터, 정답 레이블이 각각 80 : 20 으로 분할돼서 총 4개로 분할됨.
✅ 실행 결과 : ((112, 2), (38, 2), (112,), (38,))
4. KNN 객체 생성 / 모델 학습
- KNN 객체 생성
📢 neighbors.KNeighborsClassifier(n_neighbors, weights=weights)
- 젤 중요한 파라미터 n_neighbors : K 이웃을 몇 개 줄지
- weight : uniform (모든 이웃의 가중치를 동일하게 취급), distance( 이웃의 거리에 반비례하여 가중치 조정)
clf = KNeighborsClassifier(n_neighbors=15, weights = "distance")
clf.fit(X_train, y_train)
- 모델 학습
y_pred = clf.predict(X_test)
y_pred # 예측한 값5. 예측의 정확도 평가
from sklearn.metrics import accuracy_score
accuracy_score(y_test, y_pred
정확도 점수 : 0.8157..
🌟 전통적인 머신러닝은 파라미터 조정하는 과정이 중요함
--> 어떻게 최적의 하이퍼파라미터를 찾는지 (=하이퍼파라미터)
6. 시각화
📢 matplotlib
색깔로 종류를 구분해 시각화를 해줌
# y_train이 0인 것만 골라내서 분리한 인덱싱.
plt.scatter(X_train[y_train == 0, 0] , X_train[y_train ==0, 1] , label = 0)
# y_train = 1 인 것을 골라냄
plt.scatter(X_train[y_train == 1, 0] , X_train[y_train == 1, 1] , label = 1)
# y_train = 2인 것만을 골라냄.
plt.scatter(X_train[y_train == 2, 0] , X_train[y_train == 2, 1], label = 2)
# for문으로 구현하기
for i in range(3):
plt.scatter(X_train[y_train == i,0] , X_train[y_train == i , 1])
plt.plot(X_test[20, 0] , X_test[20,1] , c = "r" , marker = "x" , markersize = 20)
plt.legend()
plt.xlabel("Sepal Length")
plt.ylabel("Sepal Width")
clf.predict(X_test[20:21])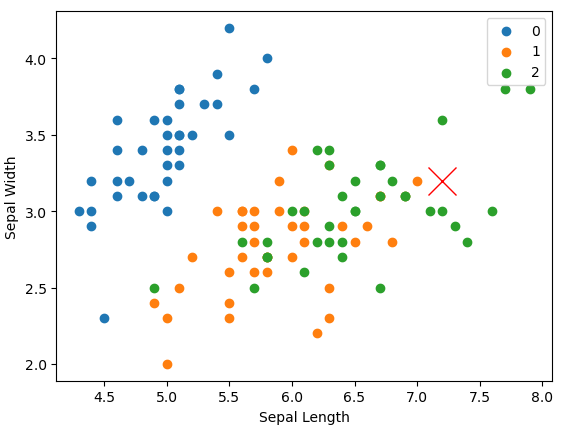
📢 seaborn
matplotlib보다 더 쉽게 시각화할 수 있음
검정색으로 표현된 것은 데이터가 없는 부분, 환한 부분은 데이터가 많은 부분
ex) 14에 해당하는 칸은 100% 다 맞춘 경우 (예측한 세토사가 다 세토사였던 것)
import seaborn as sns
plt.figure(figsize = (5,4))
ax = sns.heatmap(cm , annot = True, fmt = 'd')
ax.set_title("Confusion Matrix")
ax.set_ylabel("True")
ax.set_xlabel("Predicted")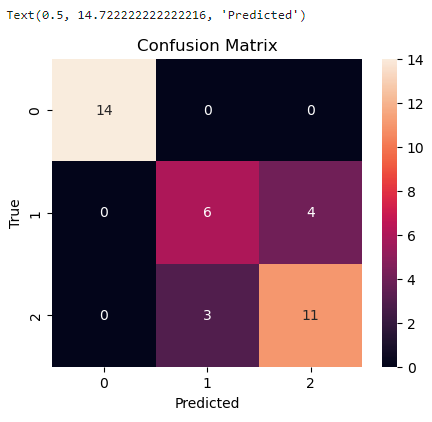
📌결정 트리 알고리즘
🏷️Decision Tree (결정나무)
= 모든 가능한 결정 경로를 트리 형태로 구성
= 계속 노드에서 Yes/No 물어보면서 조건, 범위를 줄여나가는 방식
- node : test를 의미
- branch : test의 결과에 해당
- leaf node : 분류 결과에 해당
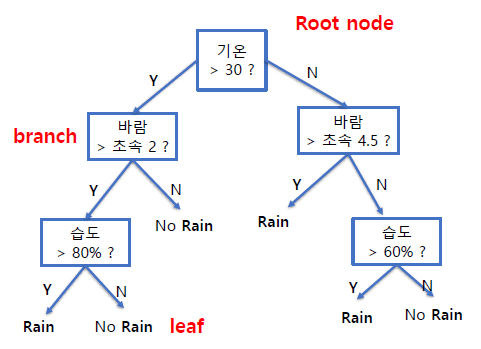
📝 장점 : 화이트 박스 모델 (=모델이 왜 그런 결과가 나왔는지 설명 가능함) , 데이터 전처리 불필요
📝 단점 : 과적합 되기 쉬움, 훈련 데이터의 작은 변화에도 민감
🏷️Decision Tree 알고리즘의 종류
✏️ ID3 : 기본적인 알고리즘. 정보 이득을 이용한 트리 구성
✏️ CART (Classification And Regression Tree)
--> Gini 불순도에 기반한 트리 구성
✏️ C4.5, C5.0 --> ID3 개선
✏️ 기타 : CHAID, MARS
🏷️엔트로피, 정보 이득
📢 엔트로피란 ?
= 주어진 데이터 집합의 혼잡도. 즉, 우리가 갖고 있지 않은 정보의 양
- 데이터가 깔끔하게 구분되어 있으면 학습할 필요 X
--> 엔트로피가 작음 - 0~1 사이의 값, 가장 혼잡도가 높은 상태 = 1
< 엔트로피 공식>

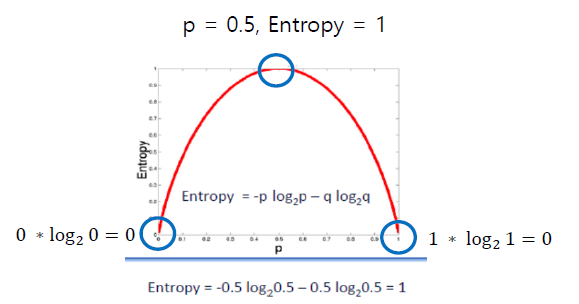
⭐ 결정 트리에선 엔트로피가 높은 상태에서 낮은 상태가 되도록 데이터를 특정 조건을 찾아 구분함
📢 정보 이득이란 ?
= 데이터에 대한 추가 정보를 통해 시스템의 엔트로피가 감소한 정도를 나타내는 값
정보 이득 = Entropy(Parent) – (weight) * Entropy(Child)
ex) 경사도의 정보 이득 계산
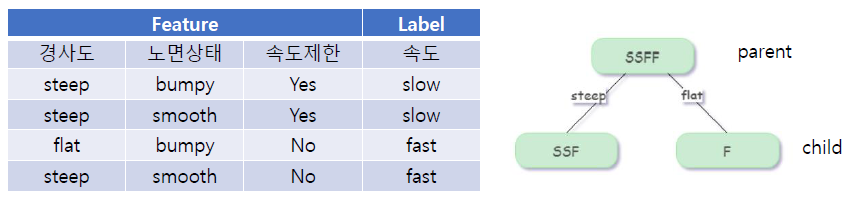
- Entropy(Parent) = - {0.5 log2(0.5) + 0.5 log2(0.5)} = 1
- Entropy(Child/steep) = - {0.667 log2(0.667) + 0.334 log2(0.334)}= 0.918
- Entropy(Child/flat) = - {0 + 1 log2(1)} = 0
- Entropy(가중평균) = ¾0.918 + ¼0 = 0.688
✅ 결론) 정보 이득 = 1 – 0.688 = 0.312
🏷️Decision Tree 알고리즘 (ID3)
- Initial open node 를생성하고 모든 instance 를 open node 에 넣는다.
- Open node 가 없어질 때까지 loop
-분할할 open node 선택
-information gain 이 최대인attribute(feature) 선택
-선택된 attribute 의 class (Y, N) 별로 instance sort
-sort 된 item 으로 새로운 branch 생성
-sort 된 item 이 모두 하나의 class 인 경우 leaf node close
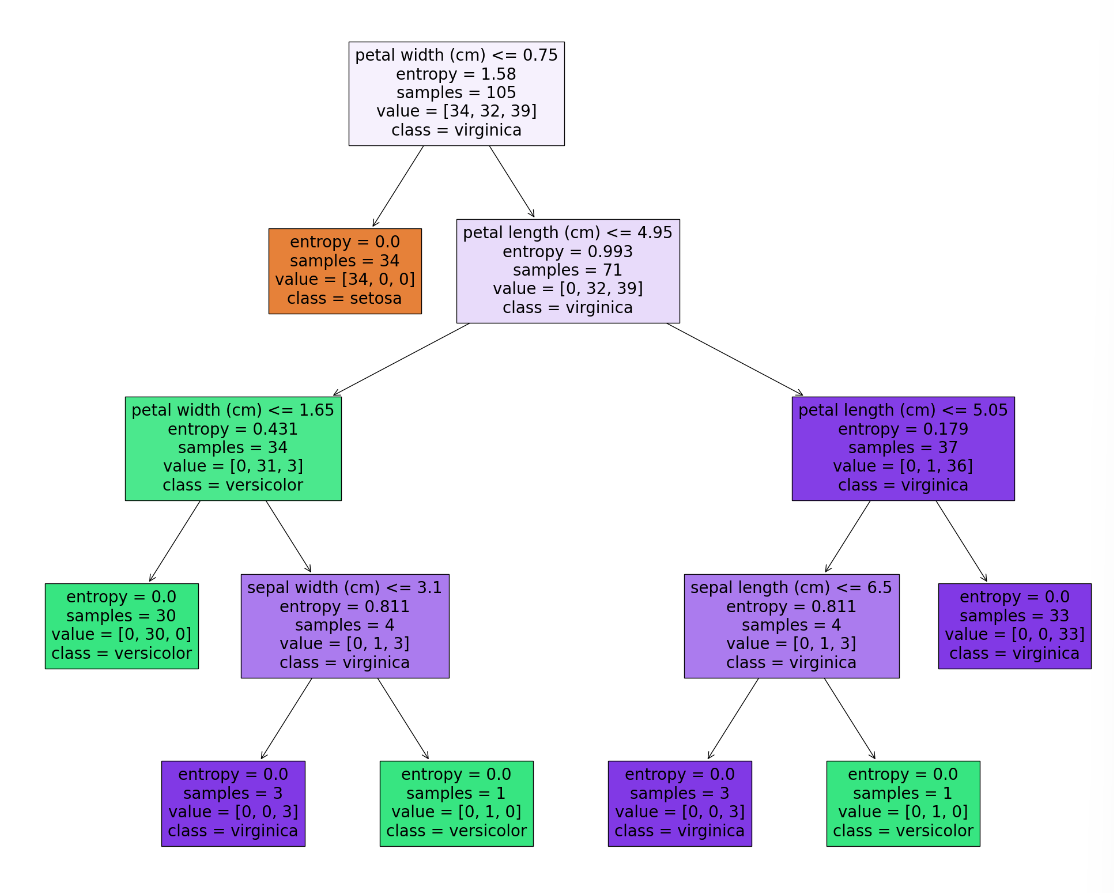
📌실습) Decision Tree 모델 작성 및 시각화 - 붓꽃 데이터 분류
Decision Tree 알고리즘을 이용하여 꽃의 종류 분류
1. 라이브러리 선언
from sklearn.datasets import load_iris
from sklearn import tree
iris = load_iris()2. 데이터셋을 훈련/검증용으로 분할
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size = 0.3, random_state = 0)
X_train.shape, X_test.shape, y_train.shape, y_test.shape3. 모델 학습 / 예측
- 모델 학습
clf = tree.DecisionTreeClassifier(max_depth = 2 , criterion = "entropy")
# entropy로 적용하면 ID3 알고리즘으로 적용이 되는거임.
clf.fit(X_train, y_train) # 훈련 데이터용 피처(X_train), 라벨(y_train)으로 모델 훈련을 진행해야함.!!- 예측하기
y_pred = clf.predict(X_test)
y_pred- 정확도 평가 : 91.11%
accuracy_score(y_test, y_pred)4. 트리 시각화
- max_depth = 2로 설정 --> 두 단계만 시각화
import matplotlib.pyplot as plt
plt.figure(figsize = (25,20))
# # 언더 스코어(_)를 하나 주는 이유는 반환 값을 받을때 변수로 받아주지 않으면 지저분하게 찍힌다(?)
_ = tree.plot_tree(clf, feature_names = iris.feature_names,
class_names = iris.target_names, filled = True)
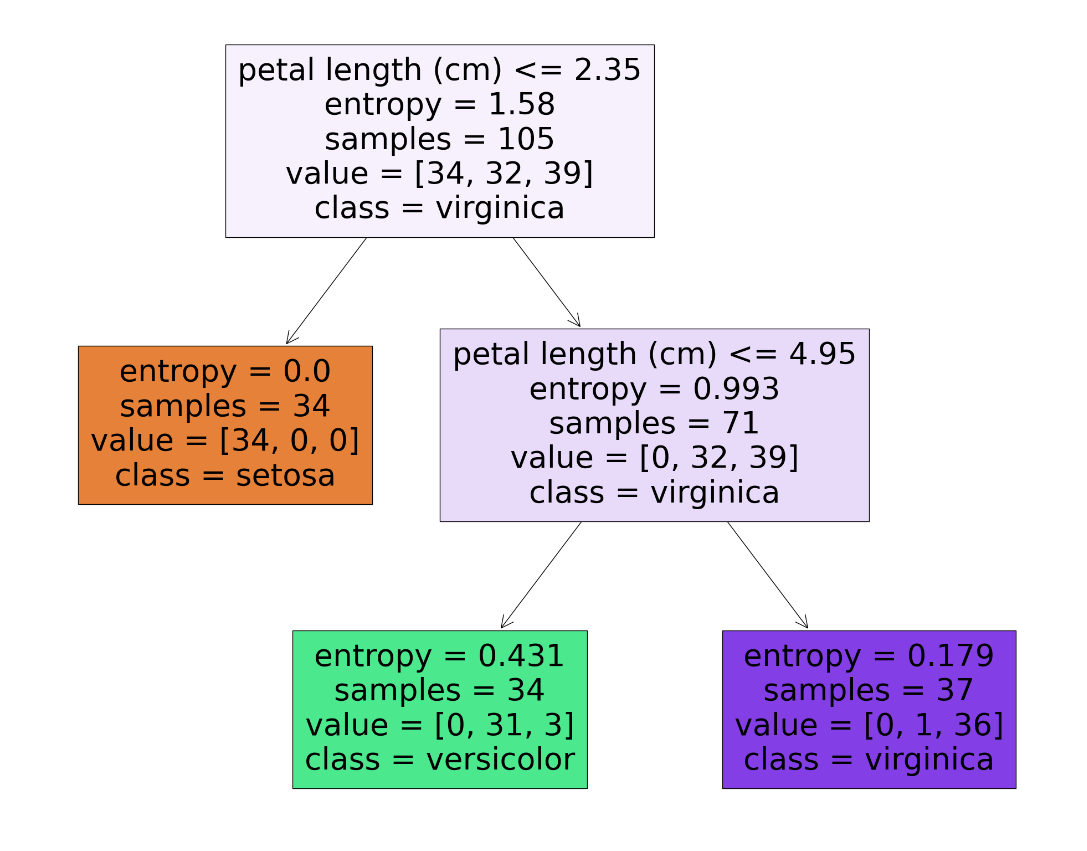
- 모든 단계의 트리를 시각화하고 싶으면 max_depth = None