현재 진행하고 있는 졸프 DB에서 문제점이 있다.
분명 나는 한국소설, 과학 소설, 로맨스, 자기계발, 에세이 카테고리만 진행해서 가져왔지만, 이상한 책들이 BOOK 테이블에 존재한다.
예를 들어, 발레 관련 책이 한국 소설 카테고리에 존재하다던가.. 그 당시에 알라딘 API가 처음이었던 내가 여러번 불러오면서 꼬였던게 아닐까 싶다. 그래서 방학인 지금 다시 해보기로!
우선 내가 그당시에 작성했던 도서 DB 구축 블로그 글은 아래
졸프 도서 DB 구축
우선 기존에 있는 DB의 문제점
1. 로컬 DB와 연동서버 DB가 자동으로 업데이트가 안된다
- 로컬 DB(MySQL, H2 등)는 각 PC에 독립적으로 존재
- 따라서 로컬에서 데이터 삽입하거나 서버에서는 반영되지 않음
- 테스트 데이터, 마이그레이션, API 테스트 중 데이터 불일치가 생김
2. BOOK 테이블에서 각 책들이 카테고리에 맞지 않게 들어와있다.
나는 오늘 이 두가지 문제점을 해결해볼 예정!
문제점 1은 AWS RDS라는 서비스를 이용해서 해결해볼 예정이다. 모두가 접근할 수 있는 중앙 DB이기에 협업에서 편하게 진행해볼 수 있다.
1. BOOK 테이블 재구축
우선은 BOOK 테이블을 뒤엎는 것부터!
전체적인 과정은 이렇게 진행할 예정이다
전체 계획 요약
1. 로컬 DB 백업 (book 테이블 포함 전체 or 부분 백업)
2. 로컬 book 테이블 초기화 + 알라딘 API로 재삽입
3. 동작 확인 후, RDS 연결로 교체
1단계: 로컬 DB 백업
난 혹시 몰라서 DB 전체와 BOOK 테이블 2개를 백업해놓았다
#전체 DB 백업
mysqldump -u root -p your_db > backup.sql
#book 테이블만 백업
mysqldump -u root -p your_db book > book_backup.sql
2단계: 로컬 book 테이블 초기화 및 알라딘 API 재삽입
(1) book 테이블 데이터 삭제
이 부분에서 여러 테이블에 현재 외래키가 걸려있다. 나는 기존 데이터들은 유지하고 책 데이터만 바꾸고 싶었기에 참조 테이블의 book_id만 NULL로 초기화하는 방식을 사용했다.
#참조 테이블의 book_id=NULL 설정
UPDATE question SET book_id = NULL;
UPDATE user_book_read SET book_id = NULL;
UPDATE user_book_reading SET book_id = NULL;
UPDATE user_book_wish SET book_id = NULL;
UPDATE user_recommended_book SET book_id = NULL;
#책 테이블 데이터 삭제
DELETE FROM book;
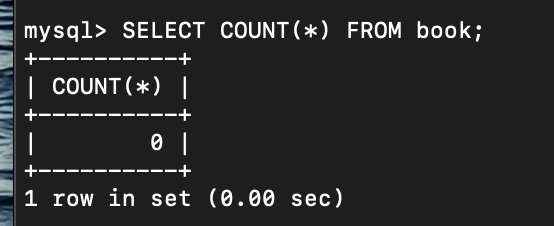
책 데이터 삭제 완료!
그리고 현재 API 불러오는 코드와 알라딘 API 문서를 한번 보았다.
알라딘 API 문서
내가 가져올 API는 상품 리스트 API이다. 근데 여기에는 제약이 걸려있다. 
한 페이지에 최대 50개! 하지만 내 코드에서는 최대 100개로 걸려있었고, 이 부분에서 오류가 발생할 수 있다. 그래서 50으로 제한하고, 무한루프로 돌던 코드를 50개씩 4번만 돌릴 수 있도록 수정
while (page <= 4) {
String url = String.format(
"http://www.aladin.co.kr/ttb/api/ItemList.aspx?ttbkey=%s&QueryType=ItemNewSpecial&MaxResults=50&start=%d&SearchTarget=Book&output=js&CategoryId=%d&Version=20131101",
ttbKey, page, categoryId
);그리고 ML과 연동을 위해서는 판매지수까지 필요하기 때문에 그 부분까지 가져와야한다. 우선 DB에 해당 칼럼 추가 후 판매지수 부분까지 가져올 수 있도록 했다.
// 판매지수(salesPoint) 파싱 추가
Integer salesPoint = null;
if (item.get("salesPoint") != null) {
try {
salesPoint = Integer.parseInt(item.get("salesPoint").toString());
} catch (NumberFormatException ignored) {}
}
book.setSalesPoint(salesPoint);근데 지금 output=js으로 받고 있지만,JSONP는 일반적인 JSON 포맷이 아니므로, 특정 상황(특히 XML 또는 타입 강제 주입)에서는 RestTemplate이 파싱에 실패할 수 있다고 하여 output=xml로 수정하기로 결정!
| 항목 | output=js (JSONP) | output=xml |
|---|---|---|
| 표준 JSON | X (JSONP) | O |
| 파싱 방식 | 강제 Map 파싱 | XML → 객체 매핑 가능 |
| 안정성 | 불안정 | 매우 안정적 |
| DTO 사용 | 어려움 | 쉽게 가능 |
| 보안 | JSONP는 보안상 비추천 | 안전함 |
이렇게 변경할 예정이다.
| 항목 | 변경 전 | 변경 후 |
|---|---|---|
| 응답 포맷 | output=js | output=xml |
| 응답 타입 | Map 파싱 | DTO 파싱 (Jackson XmlMapper) |
| 파싱 방식 | RestTemplate<Map> | RestTemplate<String> + XmlMapper.readValue() |
| DTO 정의 | 없음 | XML 매핑용 DTO 정의 필요 |
이렇게 고쳐보았고, 다시 불러와봤는데 과학 소설 카테고리에 이상한 책들이 들어가있다..그래서 서칭을 해보니
내 코드 중
book.setGenre(genre);
이건 API 호출 시 전달된 장르명(예: "과학소설")을 그대로 저장하는 방식이다. 문제는 알라딘 API가 반환하는 책이 정말 해당 장르에 맞는 책인지 확신할 수 없다는 점.
그래서 포스트맨에서
http://www.aladin.co.kr/ttb/api/ItemList.aspx?ttbkey=ttbsally1023p1354001&QueryType=ItemNewSpecial&MaxResults=1&start=1&SearchTarget=Book&output=xml&CategoryId=50992&Version=20131101을 불러보았더니
<?xml version="1.0" encoding="UTF-8"?>
<object xmlns="http://www.aladin.co.kr/ttb/apiguide.aspx">
<title>알라딘 주목할 만한 신간 리스트 - 비평/칼럼</title>
<link>https://www.aladin.co.kr/shop/common/wnew.aspx?NewType=SpecialNew&BranchType=1&CID=50992&partner=openAPI</link>
<logo>http://image.aladin.co.kr/img/header/2011/aladin_logo_new.gif</logo>
<pubDate>Tue, 15 Jul 2025 03:59:40 GMT</pubDate>
<totalResults>31</totalResults>
<startIndex>1</startIndex>
<itemsPerPage>1</itemsPerPage>
<query>QueryType=ITEMNEWSPECIAL;CategoryId=50992</query>
<version>20131101</version>
<searchCategoryId>50992</searchCategoryId>
<searchCategoryName>비평/칼럼</searchCategoryName>
<item itemId="367308497">
<title>재·수·없·는 KBS - KBS 9시 뉴스 앵커가 직접 TV 수신료를 걷는 이유</title>
<link>https://www.aladin.co.kr/shop/wproduct.aspx?ItemId=367308497&partner=openAPI&start=api</link>
<author>김철민 (지은이)</author>
<pubDate>2025-07-15</pubDate>
<description>TV 수신료 분리 징수라는 한편의 거대한 부조리극이 시청자들 일상에 어떻게 투영됐는지 증언하는 생생한 내부자 경험담이다. KBS 수신료국에서 겪었던 개인적 경험을 적었지만, 공영방송과 TV 수신료라는 사회적 의제를 재점화시켜 보고자 시도한 치열한 노력이었다.</description>
<isbn>K232030992</isbn>
<isbn13>9791194267348</isbn13>
<priceSales>16920</priceSales>
<priceStandard>18800</priceStandard>
<mallType>BOOK</mallType>
<stockStatus></stockStatus>
<mileage>940</mileage>
<cover>https://image.aladin.co.kr/product/36730/84/coversum/k232030992_1.jpg</cover>
<categoryId>51066</categoryId>
<categoryName>국내도서>사회과학>비평/칼럼>언론비평</categoryName>
<publisher>디페랑스</publisher>
<salesPoint>280</salesPoint>
<adult>false</adult>
<fixedPrice>true</fixedPrice>
<customerReviewRank>0</customerReviewRank>
<subInfo>
</subInfo>
</item>
</object>으로 나왔다.
요청한 CategoryId=50992는 과학소설이지만 실제로는 51066 (사회과학 > 언론비평)이다.
결론: 알라딘의 ItemNewSpecial API는 "지정한 카테고리의 하위 항목 중 일부"만 줄 수 있음
즉, 50992 = 과학소설로 요청했어도, 알라딘이 그 범주 안의 최신 특선 도서 중 일부만 주는데, categoryId나 categoryName이 전혀 다른 하위 카테고리일 수 있다.
해결방안
- genre 필드에 실제 응답된 카테고리를 반영하기
기존코드:
book.setGenre(genre); // 요청했던 장르명: "과학소설"
수정후 코드:
book.setGenre(item.getCategoryName()); // 응답에서 받은 실제 장르명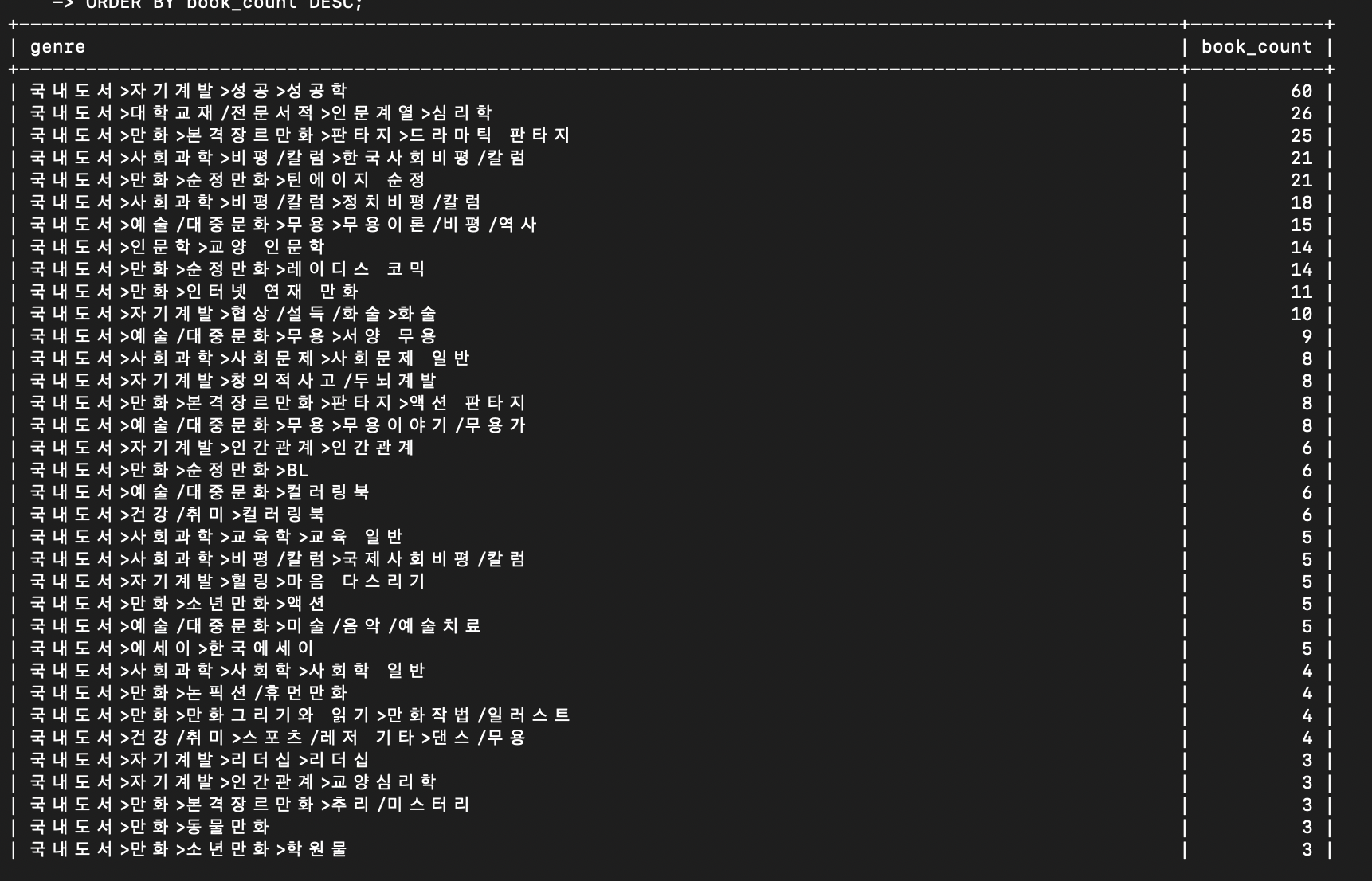
그랬더니 이런 식으로 나온다.
뭔가 이상하다... 자세히 보니 카테고리 ID가 잘못되었다. 귀찮아서 알라딘 API 카테고리 아이디 문서 지피티에게 주고, 찾아달라고 했는데 단단히 잘못되었다. 우선 장르 이름을 기존 코드
(book.setGenre(genre);)로 바꿔주고 진행하였더니 정상적으로 진행되었다. 베스트셀러 기준으로 책을 받아왔고 총 1500개의 책을 받아왔다.
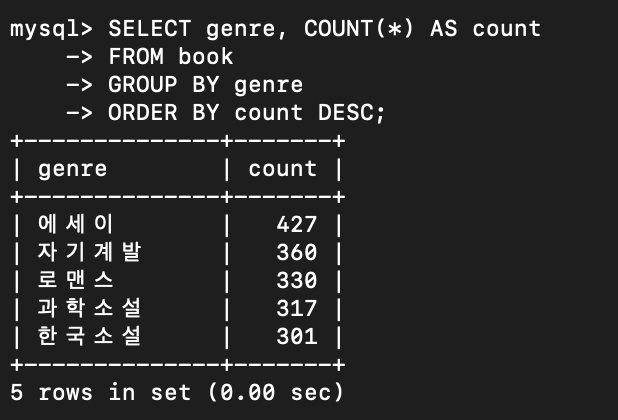
현재 책의 개수! 장르는 기존대로 에세이, 자기계발, 로맨스, 과학소설, 한국소설 이 5개로 지정한대로 가져왔다!
그러면 위에서 언급했던 2. BOOK 테이블에서 각 책들이 카테고리에 맞지 않게 들어와있다. 문제는 해결 완!
그리고 위에서 book_id=NULL 처리 했던 데이터들은 모두 지워졌다.
2. RDS로 연결
우선 RDS 데이터 베이스 생성!
우선 현재 플젝에서 ML 추천 서비스, GPT API를 이용한 질문 생성 서비스를 진행하고 있기 때문에 이 부분을 고려해서 RDS 성능을 정해야한다.
ML 추천 서비스 구조 요약
| 기능 | 설명 |
|---|---|
| 1. 도서 추천 | 사용자 취향 조사 후, 추천 도서 목록 생성 → DB 저장 |
| 2. 질문 생성 | 개별 도서 설명(description)을 기반으로 질문 자동 생성 → DB 저장 |
→ 두 기능 모두 실시간 API 호출이 아니라, 사전 생성 + DB 저장 방식
질문 생성 플로우 예시
[Spring 백엔드] or [관리용 서버]
│
├─▶ 책 정보(description 포함) ML 서버로 전달
│
└─▶ ML 서버에서 질문 생성 (BERT 등 사용)
↓
결과 JSON 형식으로 반환
↓
Spring 서버에서 RDS (question 테이블) 저장
주요 특징 정리
- 추천과 질문 생성 모두 백엔드 or 관리용 서버가 ML 서버를 비동기 호출
- 생성된 추천 도서 & 질문은 DB에 저장 (읽기/쓰기는 적절히 분산됨)
- 사용자 단에서는 단순 조회만 수행 (트래픽 부하 낮음)
- ML 서버는 별도 EC2에서 구동
결론
RDS 설정 추천 요약 (ML 추천 + 질문 생성용)
| 항목 | 선택 기준 |
|---|---|
| 템플릿 | Dev/Test → 비용 효율 중심 |
| 배포 옵션 | Single-AZ-> 질문 생성·추천 생성이 지연되어도 치명적 X |
| 인스턴스 타입 | db.t4g.micro-> 질문/추천 저장 작업 + 사용자 조회를 충분히 감당 |
| 스토리지 | 20~30GB GP2 시작, 자동 확장 ON |
| 백업 설정 | 1일 이상 유지 권장 (질문·추천 재생성 부담 덜기 위해) |
| 자격 증명 | Self-managed 선택 → ML 서버에서 DB 연결 용이함 (ID/PW 직접 관리) |
그리고 현재 로컬 DB 백업 받아서 RDS에 작업 완료!
좀 오래 걸렸던 DB 뒤엎기 완료...
