1. 학습내용
오늘도 이어서 Azure 에 다양한 기능들에 대해 배워보았다.
(windows 빼면 거의 리눅스 환경으로 돌아감.)
Azure에 스토리지(Storage)를 만들수 있는데 거기에 관해 간단하게 알아보았다.
Azure Storage Account
-비정형 및 반정형 데이터를 저장하는 저장소
-뛰어난 내구성(99.999999999%)과 가용성(99.99%)을 제공 (퍼센테이지 많큼 깨지지 않음,가용성이 다운되지 않는다는 뜻)
-제한 없는 저장소 용량
-손쉬운 엑세스
-높은 성능
-다음 4가지 서비스를 제공
Blob(object storage), Files(File share), Table(key-value store),
Queue(Simple queue)
Azure Storage 서비스
Azure Container(Blobs) (이미지, 텍스트 등 원하는 자료 저장가능)
-http 또는 https를 통해 어디서나 액세스 가능
-텍스트 또는 이진 파일과 같은 대량의 비구조적 데이터 저장 가능
(저장소에 하나하나[각각 key 값과 value 값] 넣을때 기본적으로 url가 생김. 이 주소를 치면 이미지가 다운로드 되면서 보임. 이미지는 별도의 저장소에서 가져오니 웹서버가 훨씬 가볍게 가동한다)
Azure Files
-SMB 3.0을 탱해 어디서나 액세스 가능 (파일을 공유할 수 있는 프로토콜)
-항상 사용 가능한 네트워크 파일 공유 호스트 (회사내 게시판 파일 올릴때 NAS에 올림.)
NAS 는 네트워크 연결형 저장소 이다.
Azure Queues
-http 또는 https를 통해 어디서나 액세스 가능/비동기 통신용 큐 기반 메커니즘 제공
-큐에 최대 64KB 크기의 메시지 저장 가능
Azure Tables
-Http 또는 Https를 통해 어디서나 액세스 가능
-NoSQL 테이블 저장 가능
스토리지는 또 가격별로 지원하는 옵션이 다르다. 그 옵션 중에 데이터 복제 옵션이라는 것도 있다.
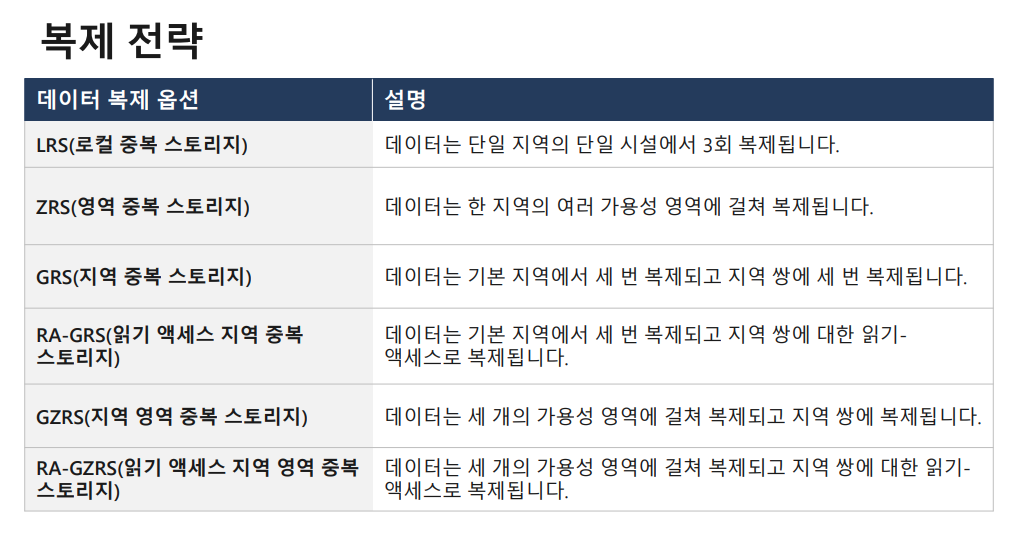
원본이 있으면 원본을 백업 본이 두개가 더 생겨 총 3개의 데이터가 생긴다.
사본이 생기는 정도에 따라 전략이 다르다.
지역이 보통 국가마다 묶여 있는데, 중앙에 복제된 데이터가 생기고, 남은 지역에 또 복제 데이터가 생겨서 거의 데이터가 날아가는 일이 없다고 보면 된다.
앞에서 Blob Storage에 대해 잠깐 언급했는데, 좀 더 자세하게 설명하자면 아래와 같다.
Blob Storage의 일반적인 용도:
-브라우저에 이미지나 문서 직접 제공
-설치 등의 분산 액세스용으로 파일저장
-비디오 및 오디오 스트리밍
-백업 및 복원, 재해 복구, 보관을 위한 데이터 저장
-온-프레미스 또는 Azure 호스팅 서비스에서 분석할 수 있도록 데이터 저장
Blob Service에 포함된 세가지 리소스 유형:
스토리지 계정
스토리지 계정의 컨테이너
컨테이너의 Blob
Block Blob은
데이터 블록으로 구성되며, 한번의 쓰기 작업으로 큰 Blob 동시에 업로드가 가능하다.
Append Blob은
마찬가지로 블록으로 구성도어 있고, 추가 작업에 최적화 되어 있으며, 성능기준에 맞는 로깅에 이상적이다.
blob 컨테이너를 만들때 3가지 방식이 있는데
첫째. private 방식: Storage Account의 인증을 통해 Container dhk Blob에 접근
둘째. Blob: 익명의 사용자에게 Blob에 읽기 권한 부여하는 방식
셋째. Container: 익명의 사용자에게 Container와 Blob에 읽기 권한을 부여한다.
스토리지 가격은 아래의 조건에 따라 다르게 책정된다.
-스토리지 비용
-데이터 액세스 비용
-트랜잭션 비용(얼마나 다운받았는가)
-지역 복제 데이터 전송 비용
-아웃바운드 데이터 전송 비용(검색 결과 전송)
-스토리지 계층 변경
다음은 Azure에 Database에 관해 알아보았다.
Azure의 관리형 데이터베이스 서비스로 유형은 아래와 같다.

저기서 Transaction는 간단하게 설명하면, a,b 두 은행이 있을 때 a에서 돈을 200만원 송금시 -100만큼 차감되고 상대 은행으로 넘어가는 도중에 에러가 발생한다. 그러면 -100이 전송될 수가 없으므로 초기에 먼저 b은행에 돈을 100을 추가시켜 놓는다. 그 다음 -100을 하는것이다. 그런데 -100이 안지워지는 에러가 발생할수도 있다. 그래서 두가지 오류를 막기위해, 송금 과정 전체를 단위로 묶어서 어느 하나라도 문제가 발생시 전체 과정을 취소 시키는 것을 Transaction이다.
저 과정만 처리할수 있게(다른 작업은 못하게) 잠기는 것을, Transaction lock이라 한다.
MySQL에 대해 알아보았다. 우선 Azure에서 제공되는 것을 사용하면 되는데 그것에 대한 설명은 아래와 같다.
-로그는 최대 7일간 보존하며, 7.5GB 초과시 여유공간이 생길때 까지 오래된 파일을 삭제한다.
-Slow query는 기본적으로 비활성화 되어 있으며, slow_query_log를 ON으로 설정해야 한다.
-HA, 확장, 축소시 새로운 Instance를 생성(Downtime) (서비스를 정지시키고 다시 실행)
-응용프로그램의 재시도 연결은 필수
-DTU 계층이 없음
스케일 업해도 더 용량이 필요하다면 데이터를 찢어서 나눠 넣어야 하는 수 밖에 없다.
Azure를 통해 만들어지는 MySQl은 참고로 PaaS 방식이다. MySQL은 참고로 명령어로 다 쳐야 관리할수 있는데, 힘든 점이 많아서, Workbench를 따로 만들었다.
이걸 다운로드 받아서 쿼리 문을 한번 작성해 보았다.
그래서 다운 받으면, Azure에서 만든 MySQL의 DB 서버이름을 복사하고, 비밀번호를 입력해 연결시킨다.
database에 데이터는 표(table)를 만들어서 저장하는게 보통이다. 테이블 간에 서로 관계를 맺는다고 한다. RDB라고 한다. 시스템 전체를 말하는 건 RDBMS라고 한다.
실습용 데이터 파일을 이용해 쿼리문을 작성해 보았다.
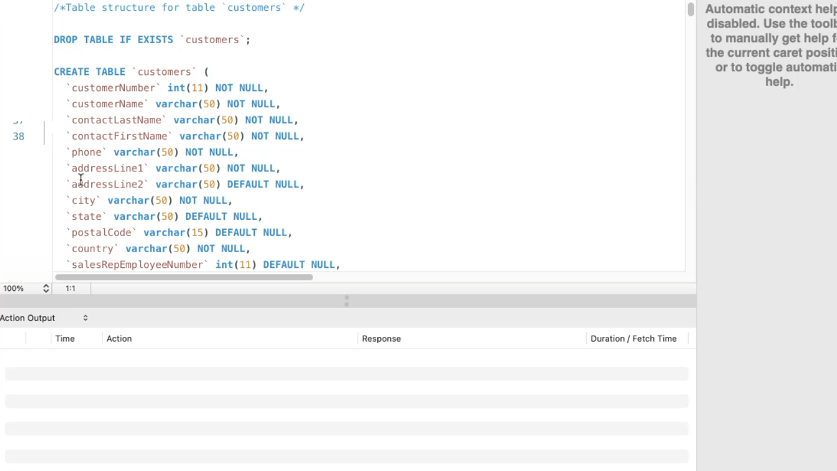
상단에 번개모양 버튼을 누르면 DB에 바로 데이터가 들어간다.
데이터의 전체적인 구조는 아래와 같이 이루어진다.
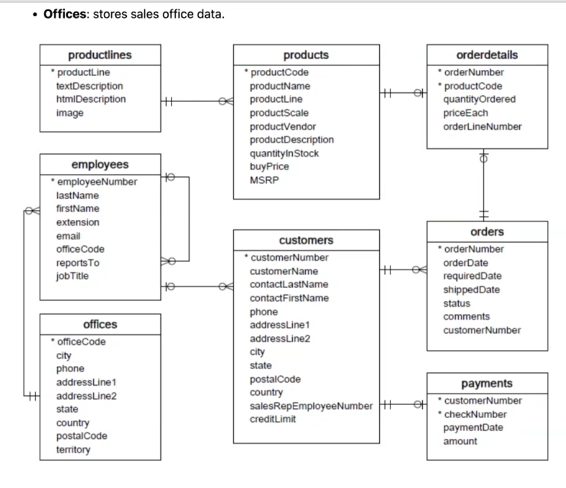
이걸 ERD라고 한다. (테이블들 간에 관계를 나타내는것.) 그림의 박스 하나하나를 나타내는 것을 Entity라고 한다.
데이터를 따로 추려서 뽑는걸을 쿼리문으로 했다.
크게 아래와 같은 명령문이 자주 쓰인다.
SELECT
UPDATE
DELETE
INSERT쿼리문을 작성해 3개의 컬럼 정도 추린 결과다.
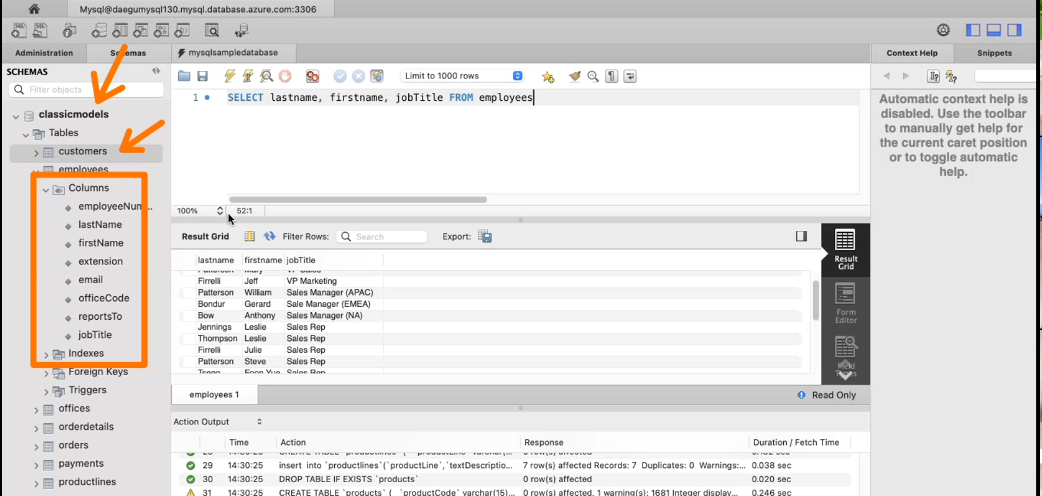
전체는 *을 사용한다.
쿼리는 작성하면 이걸 해석하고(문법체크 같은것), 데이터가 있는지 체크하고, 데이터의 상태를 확인해보고, 쿼리를 실행시킬 수 있는 플랜을 작성한다. 그러면 그때 실행한다.
이 과정을 하나 미리 만들어 주면 DB에서 가져 오는 속도는 훨씬 빨라진다.
이걸 'Stored Procdures'라고 한다. 그런데 이게 쿼리만 저장해 놓은게 아니라. 문법적인처리, 실행 계획 등도 포함하고 있다.
그런데 이것도 가면 갈수록 속도가 느려지는 단점이 있다. 그럼 새로 만들어야 한다.
이유는 DB의 상태가 변하기 때문이다. 요즘은 그래서 안쓰는 경향이 있다.
2. 어려웠던 점 및 해결 방안
클라우드 개념이 아직 자리잡지 못해서 몇가지 개념 사이의 단어들이 이해가 안될때가 있었다.
그래서 그런건 골라서 따로 구글링해 보기로 했다.
쿼리문 중에는 설명을 놓쳐서 이해를 제대로 못한 부분이 있기에 그 부분만 다시 봤다.
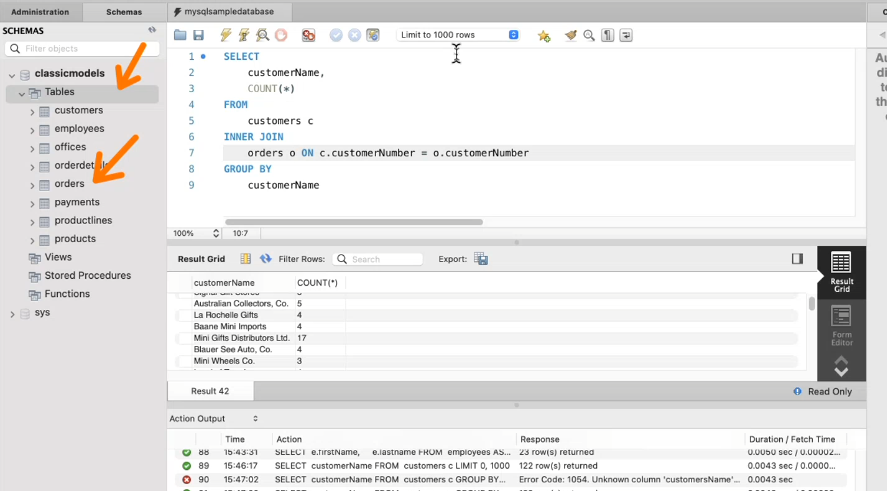
-GROUP BY는 두개의 table에 겹쳐지는 항목을 중심으로 엮는것을 말한다.
또 별개로 table을 묶어야 하기 때문에 JOIN을 쓴다. (교집합 합집합에 따라 JOIN의 명령문이 다르다.
-WHERE가 조건문인데, 특정 단어로 구성된 데이터만 뽑아내는 쿼리문이 뭔지 놓쳐서 다시봤다.
~로 시작해 끝나는 데이터만 뽑을려면 아래와 같이 적는다.
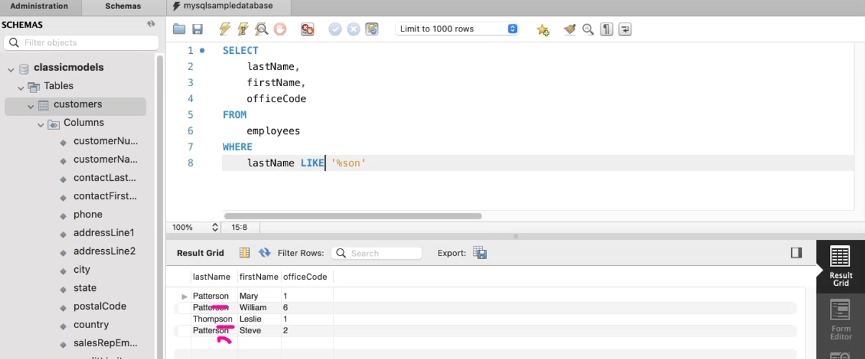
그냥 = 'son'을 하면 'son'만 적힌 값만 뽑힌다.
그런데 저렇게 하면 계산을 오래하기 때문에 자주 쓰이진 않는다.
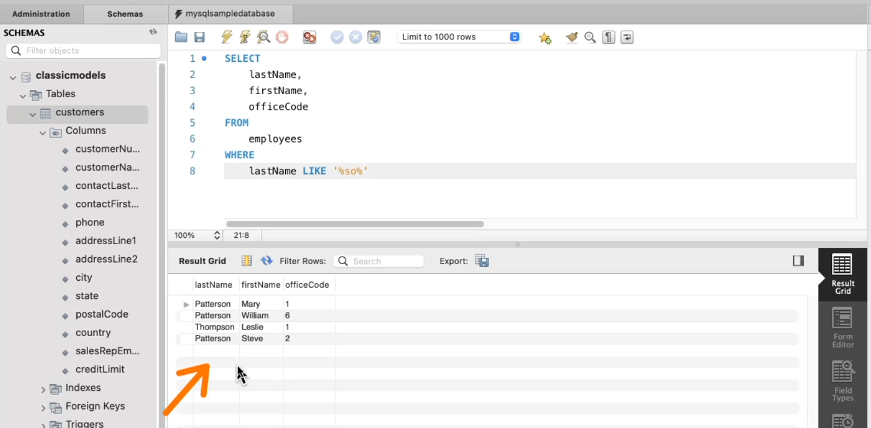
이렇게 해도 비슷하게 나오는 것을 알수 있다.
3. 학습 소감
쿼리문을 오랜만에 다시 접했는데 좀더 쉽다고 느껴졌다. 그래도 정확히 할려면 제대로 공부해 봐야 겠다는 생각이 들었다.
