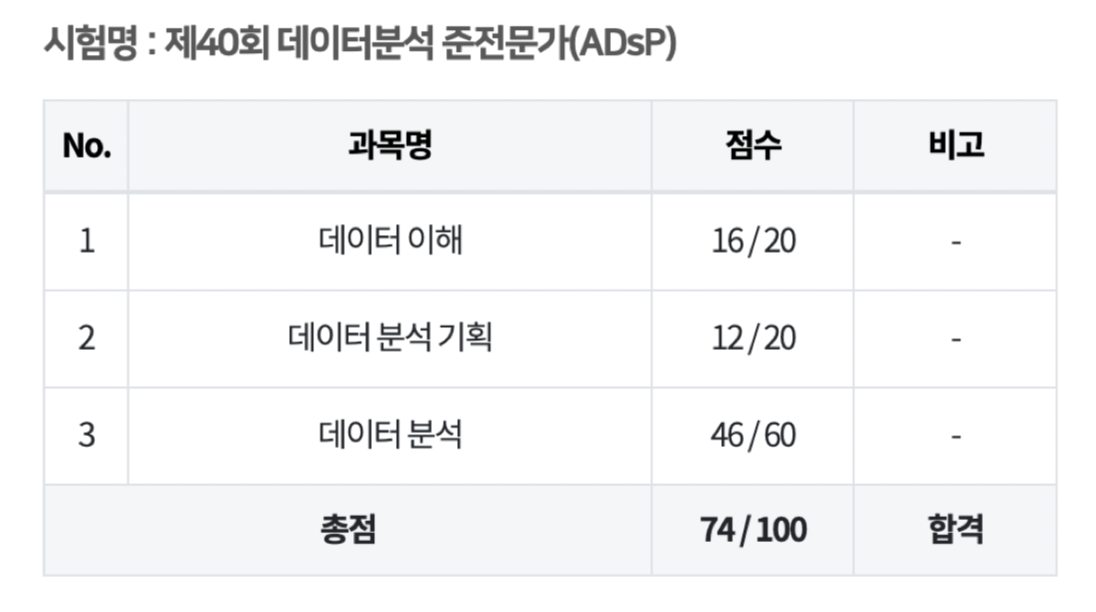
ADsP 40회 74점 합격 / 필수계산식 요약정리

2024년 2월 24일 제 40회 시험 응시. 아현중학교 고사장 전경
최근 4회차(36~39회) 기반 많이 출제된 핵심 개념, 계산식을 정리했습니다.
아래 링크는 데이터 전문가 포럼 네이버 카페에 남긴 후기 입니다.
https://cafe.naver.com/sqlpd/74068
3과목
줄기잎그림
계산량 많지 않음.
히스토그램
- 가로축 : 계급, 세로축 : 도수
- 표본의 크기가 작으면 각 막대의 높이가 데이터 분포의 형상을 잘 표현해내지 못한다.
Box plot
- IQR 계산: Q3(위)-Q1(아래)
- 하한선(Lower Fence) 계산: Q1−1.5×IQR
- 상한선(Upper Fence) 계산: Q3+1.5×IQR
- 중앙값 : 중앙선
관측치 = 자유도 + 1
표본 추출법
- 단순랜덤 : 복원, 비복원
- 계통 : n개의 구간, k개씩 띄어
- 집락 : 군집별
- 층화 : 층을 나눈 뒤 고루 추출
기댓값
- 이산형 확률변수 : E(x) = Σx f(x)
- 연속형 확률변수 : E(x) = ∫x f(x) dx
- 확률의 합은 1
독립사건 곱셈정리
- P(A∩B)=P(A)×P(B)
- 조건부 확률 : P(A|
B) = P(A∩B)/P(B)
배반사건 덧셈정리
- P(AUB)=P(A)+P(B)
분포의 꼬리가 긴 경우
오른쪽 : 중앙값<평균
왼쪽 : 평균<중앙값
범주형/연속형 변수
척도
- 명목 - 성별
- 순서 : 서열 - 학년, 만족도
- 구간(등간) - 온도
- 비율 : 0, 사칙연산 - 무게, 나이 / 정보가 가장 많음
확률분포
- 이산 : 이항, 다항, 포아송, 기하, 베르누이
- 연속 : 지수, t, 카이제곱, F, 정규, 균일
추정
점 추정
- 모집단의 모수를 특정 값으로 추정
구간추정
- 모집단 모수가 포함될 것으로 추정되는 값의 범위
- 신뢰구간
- 신뢰수준 : 모수가 신뢰구간 내에 존재할 확률
제 1종 오류
귀무가설 Ho O인데 X라고 하는 오류
- 잘못될 실제 확률 : p-value
비모수/모수 검정
비모수
- 부호검정, 월콕슨의 순위합 검정, 윌콕슨의 부호 순위 검정,맨-휘트니의 U검정, 런 검정, 스피어만의 순위상관계수
상관분석
- 변수 간 연관성, 관계의 정도 파악
- 인과관계 X
cor()- p-값
공분산
측정단위에 영향- 공분산 표준화하는게 상관계수
피어슨 상관계수
- 원래 값 기반 계산
스피어만 상관계수
- 순위/서열/순서로 변환된 데이터에 기반
- -1~1 값, 0은 상관관계 없음
- 상관계수 절대값 클수록 강한 상관관계
- 비선형관계 포착O
회귀분석
- 기본가정 : 선형성, 등분산성, 독립성, 비상관성, 정규성
- 검정
- 선형성(y-x그래프)
- 등분산성 (잔차 산점도)
- 독립성=자기상관 (Durbin-Watson)
- 정규성 (히스토그램, Q-Q plot, Shaprio-Wilk 검정)
- 검정
lm(formula = y종속~x독립)- 영향력 :
estimate회귀계수절대값 크기 - 통계적 유의미성 : z값 크고 p값 작아야
F-검정전체 회귀모형 유의 : F 통계량 p-valuet-검정각 설명변수 유의 : Pr(>|t|)에 있는 p-value 확인- t값 : 추정값(estimate) / 표준 오차(std.error)
- 변동성 설명력 :
결정계수MultipleR-squared0~1값- 설명되는 변동 비율
- 독립변수의 수가 많아지면 결정계수가 높아지는 단점
- 회귀식 검정
- 귀무가설 : 독립변수의 기울기(회귀계수)가 0.
- 대립가설 : 0이 아님 = 독립변수가 종속변수에 영향을 미친다.
- 로지스틱 회귀분석
glm - 로그오즈(log-odds)
- lasso 회귀모형 : 회귀계수 절대값에 penalty 부여, L1 penalty, lambda(λ)라는 매개변수를 통해 penalty의 정도를 조정,
- 릿지 (L2)
- 최적회귀방정식
- 최적회귀방정식 : 설명변수 선택 (최소화) → 모형선택 → 단계적 변수 선택 (전진선택법
forward후진제거법backward/단계선택법stepwise)
- 벌점화 선택 : 낮은 AIC,BIC 값을 가진 모델이 더 좋은 모델
- 최적회귀방정식 : 설명변수 선택 (최소화) → 모형선택 → 단계적 변수 선택 (전진선택법
분산분석
aov()anova 분산분석- 상관관계 알 수 X
- 두 개 이상의 그룹 간의 평균 차이가 통계적으로 유의미하게 있는지. (t-검정은 2개 집단)
시계열 분석
- 탐색적, 예측적
- 잡음은 무작위적 변동이며 일반적인 원인이 알려져 있지 않다.
- 추세(장기간), 계절성(주기), 순환성(이유 없는 주기), 불규칙변동 요소 설명
- 시계열 정상성
- 모든 시점 평균 일정
- 시점 의존하지 않고 분산 일정
- 비정상 시계열 정상화 :
평균→차분, 분산 → 변환 - 순서
- 시간 그래프 그리기
- 추세와 계절성 제거해 정상화하기
- 잔차에 대해 모델 적합시키기
- 잔차 예측하기
- 예측된 잔차에 추세와 계절성 더해 미래 예측
다차원 척도법 MDS
- 대상들 사이의 유사성/비유사성을 거리로 나타내어 저차원 공간에서 시각화
- 목적 : 복잡한 구조를 이해하기 쉬운 저차원의 공간에 표현하여 데이터의 숨겨진 패턴을 발견하는 것
종류
- 계량적 다차원척도법(Metric MDS)는 비율척도, 구간척도의 데이터를 활용
**비계량적** 다차원척도법(Non-Metric MDS)는**순서척도**의 데이터를 활용
모델의 적합도
스트레스 값이 0.05 이하면 매우 좋은 적합도라 분석 과정을 중단해도 됨.
주성분 분석
Comp.1,2,3,4…
- 변동 설명력 :
Cumulative Proportion은 첫 번째 주성분부터 현재 주성분까지누적된 분산의 비율을 나타냅니다. - 음과 양 상관관계 :
Loadings-1~1 값, 절댓값이 클수록 해당 주성분에 대한 기여도가 더 크다.
데이터 마이닝
학습 과정에서 검정용 데이터를 통해 하이퍼 파라미터를 미세 조정하는데 활용- 모델의
성능 평가에는테스트 데이터를 사용한다
지도/비지도학습
- 지도학습
- 정답 O
분류, 회귀- 의사결정나무, 인공신경망, 일반화선형모형, 선형회귀분석, 로지스틱회귀분석,사례기반추론, 최근접 이웃
- 비지도학습
- 패턴, 구조
군집화, 차원축소- OLAP, 연관성규칙, 군집분석, SOM
의사결정나무
-
과대적합 방지 가지치기
-
지니지수 : 노드의 불순도
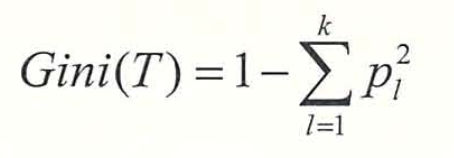
앙상블 기법
- 배깅(Bagging)
단순 임의 반복(복원)추출해 분류기 생성 후 앙상블- 같은 데이터 여러번, 어떤 데이터 추출 X 가능.
- 부스팅(Boosting) : 예측력이
약한모형들을결합하여강한예측모형을 만드는 방법 - 랜덤포레스트(Random Forest)
- 배깅에 더 랜덤 과정 추가
**분류**분석 문제 (여부)- 의사결정나무에서 나타나는
과대적합/과소적합의 문제를 해결
오분류표 계산
- 정확도
실P올P+실N올N - 오분류율
1-정확도 - 특이도 Specificity-
실N올N - 민감도 Sensitivity&재현율 Recall-
실P올P - 정밀도 Precision-
P예실P - F1-정밀재현 Recall&Precision
2*{(정*재)/(정+재)}
실P : 실제 Postive(True) 중에
올P : 올바르게 Postive(True)로 예측한 거
예P : 예측 Postive로 중에
실P : 실제 Postive 인 거인공신경망
활성화함수
활성화 함수는 입력 신호의 총합을출력 신호로 변환하는 함수- 뉴런은
활성화 함수를 이용해출력을 결정 - 종류
- 시그모이드 함수
단층신경망에서활성화 함수로 사용하면로지스틱 회귀모형과 작동원리가 유사- 결과값 : 0~1 사이의 값
- 계단, ReLU
- Softmax :출럭값이 여러 개이고 목표치가 다범주
- 시그모이드 함수
군집분석
- 유사성
분류 - 군집의 개수나 구조에 대한
가정 없이데이터들 사이의거리를 기준으로군집화를 유도 - 집단 간
이질성과 집단 내동질성이 모두높아지는방향으로 군집
1. 계층적 군집 분석
최단연결법은평균연결법에 비해계산량이 적다- 최장연결법
- 와드연결법 :
오차제곱합 - 결과 → 덴드로그램
- 비계층적 군집분석
- K-means K-평균 군집
모든 개체가 군집으로 할당될 때까지 위 과정들을반복군집개수,객체선택 → 가까운 군집중심에 할당 →평균계산 →반복- 군집수 정하기 :
집단 내 제곱합 그래프 - 이상치에 민감 → 평균 대신
중앙값사용 (k-medoids 군집화 알고리즘)
- K-means K-평균 군집
- 혼합 분포 군집 : EM 알고리즘
- SOM 자기조직화지도
- 고차원 데이터를 저차원의 뉴런으로 정렬하여 지도의 형태로 형상화
- 하나의
전방 패스를 사용
거리계산
연속형 변수
-
유클리디안 거리
절대값제곱합루트
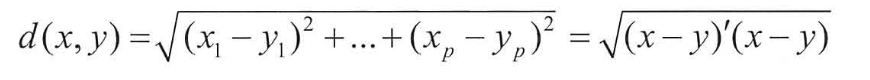
-
맨하탄 거리
절대값합
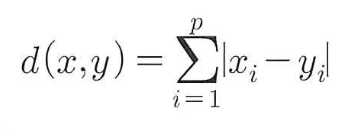
-
민코우스키 거리
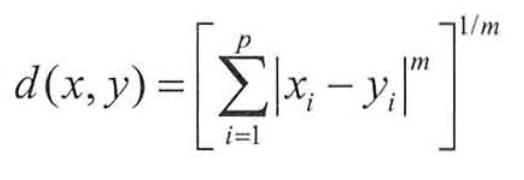
-
표준화 거리, binary 거리, 마할라노비스 거리, 체비셰프 거리, 캔버라 거리, 민코우스키 거리
범주형 변수
- 자카드거리, 자카드계수, 코사인거리, 코사인 유사도
연관분석
- 조건→결과 = A→B
지지도 : P(A∩B)=A,B 동시에 있는 것만 다 더하기/전체
신뢰도 : P(A∩B)/P(A) = 지지도/P(A)
향상도 : 신뢰도/P(B)
1,2과목
-
페타<엑사<제타<요타
페엑제요 -
비정형-반정형(메타데이터,스키마)-정형
-
DB : 통합 데이터 = 중복된 데이터 X
-
공통화→표→연→내면화
공표연내 -
DIKW랑 간단예시 적어두고 보면서 비교 (머리로만 생각하면 헷갈림)
데이터 : 사실
정보 : 가공, 관계, 패턴인식 ex. A마트가 더 싸다
지식 : 패턴이해, 예측 ex. 저렴한 A마트에서 사야겠다
지혜 : 아이디어 ex. A마트가 대부분 더 싸겠지?
-
위험대응: 회피, 전이, 완화, 수용 (관리X) -
데이터 거버넌스 체계 > 데이터 표준화 : 데이터 표준 용어 설정, 명명 규칙 수립, 메타 데이터 구축, 데이터 사전 구축 등의 업무
-
분석과제 “
우선순위” 고려요소 -분석기술능력 X- 전략적 중요도 - 전략적 필요성, 시급성
- 비즈니스 성과 ROI
- 실행용이성 - 투자용이성, 기술용이성
-
분석과제 “
적용범위/방식” 고려요소 -투입비용 X, 실행용이성 X업무내재화적용수준분석 데이터적용수준기술적용수준
-
분석 수준 진단
- 성과는 X
- 분석 수준 진단 결과 사분면 분석
준비도/성숙도
정착형,확산형(성숙O),도입형 (준비O), 준비형
-
분석 성숙도 진단
- 비즈니스, 조직 및 역량, IT
- 도입, 활용, 확산, 최적화
- 기업문화 X 서비스 X 경쟁사 및 유사업종과 비교 X
-
상향식 : 발견, 통찰 / Design Thinking : 발산 수렴 반복
-
Volume/Variety/Velocity (난이도/투자비용요소)
- Value (시급성-비즈니스효과)
우선순위 1등
-
데이터 분석 조직 구조
- 집중구조 : 별도조직
- 기능구조 : 분석조직X
- 분산구조 : 부서별 분석조직 배치
-
데이터 거버넌스 구성요소 : 원칙(Principle), 조직(Organization), 프로세스(Process)
-
핀테크 빅데이터 활용 핵심 → 신용도 평가 → 분류, 예측
