그래프를 구성하는 모든 꼭짓점(Vertex)들을 체계적으로 방문하여 탐색하는 자료 검색 방법.
일반적으로 깊이 우선 탐색(Depth First Search)과 너비 우선 탐색(Breadth First Search) 두 종류가 많이 사용된다.
(전위 운행법, 중위 운행법, 후위 운행법 등은 이 글에서는 생략한다.)
DFS (Depth First Search)
한 노드를 시작으로 인접한 다른 노드를 탐색하기를 반복하여 끝까지 탐색하면 다시 상위 레벨의 다른 노드에서 탐색을 이어가며 모든 Vertex를 방문한다.
-
'깊이 우선 탐색'이라는 말 그대로 깊은 곳으로 우선 탐색을 진행하는 방식.
-
First In Last Out 방식의 Stack과 중복 처리를 방지하기 위해 이미 접근했던 Vertex를 저장하는 방식을 활용한다.
[예시 1]
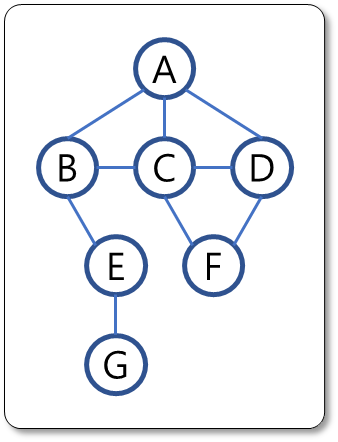
- 깊이 우선 탐색
- 탐색 시작점
A를stack과seen에 각각 저장stack = [A],seen = {A}
- 탐색을 마친
A는stack에서 제거 후A와 인접하는 vertex들B, C, D를stack과seen에 각각 저장stack = [D, C, B],seen = {A, B, C, D}
stack에 마지막으로 저장된B를 탐색 후 제거하며B와 인접하는A, C, E중seen에 속하지 않은E를stack과seen에 각각 저장stack = [D, C, E],seen = {A, B, C, D, E}
-
stack에 마지막으로 저장된E를 탐색 후 제거하며E와 인접하는B, G중seen에 속하지 않은G를stack과seen에 각각 저장stack = [D, C, G],seen = {A, B, C, D, E, G} -
stack에 마지막으로 저장된G를 탐색 후 제거하고G와 인접하는E는 이미seen에 저장되어 있으므로 따로 처리하지 않음stack = [D, C],seen = {A, B, C, D, E, G} -
stack에 마지막으로 저장되어 있는C를 탐색 후 제거하며C와 인접하는A, B, D, F중seen에 속하지 않은F를stack과seen에 각각 저장stack = [D, F],seen = {A, B, C, D, E, F, G} -
stack에 마지막으로 저장된F를 탐색 후 제거하고F와 인접하는C, D는 이미seen에 저장되어 있으므로 따로 처리하지 않음stack = [D],seen = {A, B, C, D, E, F, G} -
stack에 마지막으로 저장된D를 탐색 후 제거하고D와 인접하는A, C, F는 이미seen에 저장되어 있으므로 따로 처리하지 않음stack = [],seen = {A, B, C, D, E, F, G} -
stack에 남은 것이 없으므로 탐색 종료.
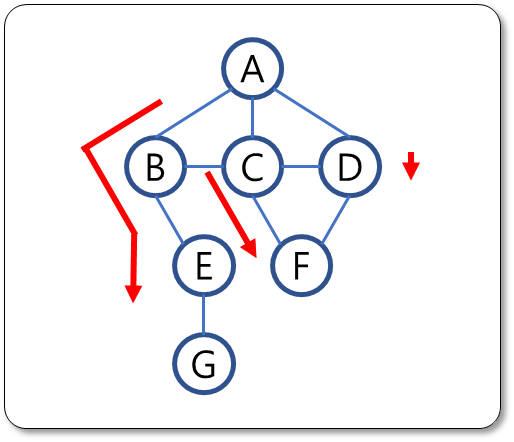
- [예시 1]의 그래프 깊이 우선 탐색 처리 순서:
A, B, E, G, C, F, D
BFS (Breadth First Search)
한 노드를 시작으로 인접한 다른 노드를 탐색하기를 반복하여 같은 레벨의 노드 탐색이 끝나면 하위 레벨의 다른 노드에서 탐색을 이어가며 모든 Vertex를 방문한다.
-
'너비 우선 탐색'이라는 말 그대로 옆으로 우선 탐색을 진행하는 방식.
-
First In First Out 방식의 Queue와 중복 처리를 방지하기 위해 이미 접근했던 Vertex를 저장하는 방식을 활용한다.
[예시 2]
- 너비 우선 탐색
-
탐색 시작점
A를queue와seen에 각각 저장queue = [A],seen = {A} -
A의 탐색을 마치고queue에서 제거 후 인접한 vertex들B, C, D를queue와seen에 각각 저장queue = [B, C, D],seen = {A, B, C, D} -
queue의 맨 처음 값인B를 탐색 후 제거하며 인접한A, C, E중seen에 속하지 않은E를queue와seen에 각각 저장queue = [C, D, E],seen = {A, B, C, D, E} -
queue의 맨 처음 값인C를 탐색 후 제거하며 인접한A, B, D, F중seen에 속하지 않은F를queue와seen에 각각 저장queue = [D, E, F],seen = {A, B, C, D, E, F} -
queue의 맨 처음 값인D를 탐색 후 제거하며 인접한A, C, F는 이미seen에 속해 있으므로 따로 처리하지 않음queue = [E, F],seen = {A, B, C, D, E, F} -
queue의 맨 처음 값인E를 탐색 후 제거하며 인접한B, G중seen에 속하지 않은G를queue와seen에 각각 저장queue = [F, G],seen = {A, B, C, D, E, F, G} -
queue의 맨 처음 값인F를 탐색 후 제거하며 인접한C, D는 이미seen에 속해 있으므로 따로 처리하지 않음queue = [G],seen = {A, B, C, D, E, F, G} -
queue의 맨 처음 값인G를 탐색 후 제거하며 인접한E는 이미seen에 속해 있으므로 따로 처리하지 않음queue = [],seen = {A, B, C, D, E, F, G} -
queue에 남은 것이 없으므로 탐색 종료.
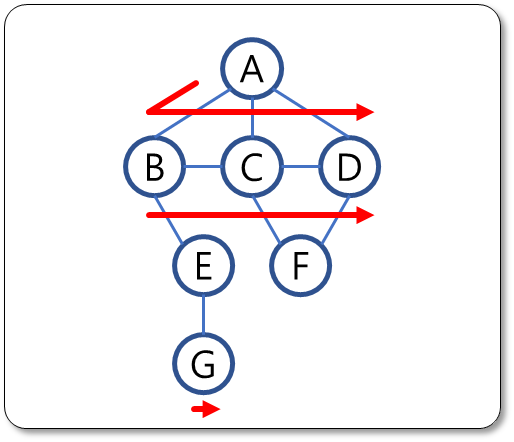
- [예시 1]의 그래프 너비 우선 탐색 처리 순서:
A, B, C, D, E, F, G
