ChannelTransformer - code
CTrans.py
ChannelTransformer
channel_embedding
channel_embedding
channel_embedding
channel_embedding
encoder
Reconstruct
Reconstruct
Reconstruct
Reconstruct
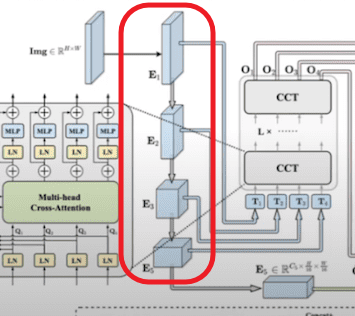 - embeddings1, embedding2, embeddings3, embeddings4
- embeddings1, embedding2, embeddings3, embeddings4
2. ChannelTransformer
class ChannelTransformer(nn.Module):
'''
채널 트랜스포머의 큰 골격이 되는 클래스.
패치 사이즈를 입력으로 받음.
임베딩
'''
def __init__(self, config, vis, img_size, channel_num=[64, 128, 256, 512], patchSize=[32, 16, 8, 4]):
super().__init__()
self.patchSize_1 = patchSize[0] # 32
self.patchSize_2 = patchSize[1] # 16
self.patchSize_3 = patchSize[2] # 8
self.patchSize_4 = patchSize[3] # 4
self.embeddings_1 = Channel_Embeddings(config,self.patchSize_1, img_size=img_size, in_channels=channel_num[0])
self.embeddings_2 = Channel_Embeddings(config,self.patchSize_2, img_size=img_size//2, in_channels=channel_num[1])
self.embeddings_3 = Channel_Embeddings(config,self.patchSize_3, img_size=img_size//4, in_channels=channel_num[2])
self.embeddings_4 = Channel_Embeddings(config,self.patchSize_4, img_size=img_size//8, in_channels=channel_num[3])
self.encoder = Encoder(config, vis, channel_num)
self.reconstruct_1 = Reconstruct(channel_num[0], channel_num[0], kernel_size=1,scale_factor=(self.patchSize_1,self.patchSize_1))
self.reconstruct_2 = Reconstruct(channel_num[1], channel_num[1], kernel_size=1,scale_factor=(self.patchSize_2,self.patchSize_2))
self.reconstruct_3 = Reconstruct(channel_num[2], channel_num[2], kernel_size=1,scale_factor=(self.patchSize_3,self.patchSize_3))
self.reconstruct_4 = Reconstruct(channel_num[3], channel_num[3], kernel_size=1,scale_factor=(self.patchSize_4,self.patchSize_4))
def forward(self,en1,en2,en3,en4):
emb1 = self.embeddings_1(en1)
emb2 = self.embeddings_2(en2)
emb3 = self.embeddings_3(en3)
emb4 = self.embeddings_4(en4)
encoded1, encoded2, encoded3, encoded4, attn_weights = self.encoder(emb1,emb2,emb3,emb4) # (B, n_patch, hidden)
x1 = self.reconstruct_1(encoded1) if en1 is not None else None
x2 = self.reconstruct_2(encoded2) if en2 is not None else None
x3 = self.reconstruct_3(encoded3) if en3 is not None else None
x4 = self.reconstruct_4(encoded4) if en4 is not None else None
x1 = x1 + en1 if en1 is not None else None
x2 = x2 + en2 if en2 is not None else None
x3 = x3 + en3 if en3 is not None else None
x4 = x4 + en4 if en4 is not None else None
return x1, x2, x3, x4, attn_weights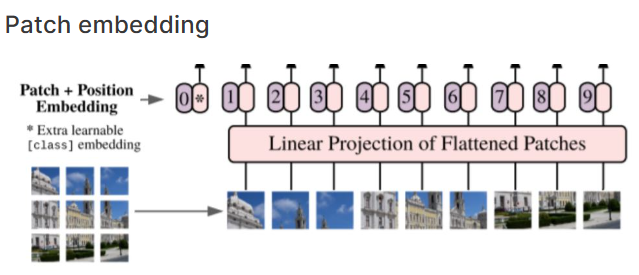
2-1. Channel Embedding
class Channel_Embeddings(nn.Module):
"""Construct the embeddings from patch, position embeddings.
"""
def __init__(self,config, patchsize, img_size, in_channels):
super().__init__()
img_size = _pair(img_size) # 이미지 사이즈로 튜플을 만듬.
patch_size = _pair(patchsize) # 패치 사이즈로 튜플을 만듬.
n_patches = (img_size[0] // patch_size[0]) * (img_size[1] // patch_size[1]) # 전체 이미지에 대해 패치의 사이즈를 나눠서 패치의 갯수를 셈.
self.patch_embeddings = Conv2d(in_channels=in_channels,
out_channels=in_channels,
kernel_size=patch_size,
stride=patch_size)
# out channels가 in channels와 같은데 왜 그런지 모르겠음...?!
self.position_embeddings = nn.Parameter(torch.zeros(1, n_patches, in_channels))
self.dropout = Dropout(config.transformer["embeddings_dropout_rate"])
def forward(self, x):
if x is None:
return None
x = self.patch_embeddings(x) # (B, hidden. n_patches^(1/2), n_patches^(1/2))
x = x.flatten(2)
x = x.transpose(-1, -2) # (B, n_patches, hidden)
embeddings = x + self.position_embeddings
embeddings = self.dropout(embeddings)
return embeddings
2-2. Encoder
class Encoder(nn.Module):
def __init__(self, config, vis, channel_num):
super(Encoder, self).__init__()
self.vis = vis
self.layer = nn.ModuleList()
self.encoder_norm1 = LayerNorm(channel_num[0],eps=1e-6)
self.encoder_norm2 = LayerNorm(channel_num[1],eps=1e-6)
self.encoder_norm3 = LayerNorm(channel_num[2],eps=1e-6)
self.encoder_norm4 = LayerNorm(channel_num[3],eps=1e-6)
for _ in range(config.transformer["num_layers"]):
layer = Block_ViT(config, vis, channel_num)
self.layer.append(copy.deepcopy(layer))
def forward(self, emb1,emb2,emb3,emb4):
attn_weights = []
for layer_block in self.layer:
emb1,emb2,emb3,emb4, weights = layer_block(emb1,emb2,emb3,emb4)
if self.vis:
attn_weights.append(weights)
emb1 = self.encoder_norm1(emb1) if emb1 is not None else None
emb2 = self.encoder_norm2(emb2) if emb2 is not None else None
emb3 = self.encoder_norm3(emb3) if emb3 is not None else None
emb4 = self.encoder_norm4(emb4) if emb4 is not None else None
return emb1,emb2,emb3,emb4, attn_weights2-3. Reconstruct
class Reconstruct(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, scale_factor):
super(Reconstruct, self).__init__()
if kernel_size == 3:
padding = 1
else:
padding = 0
self.conv = nn.Conv2d(in_channels, out_channels,kernel_size=kernel_size, padding=padding) #
self.norm = nn.BatchNorm2d(out_channels)
self.activation = nn.ReLU(inplace=True)
self.scale_factor = scale_factor
def forward(self, x):
if x is None:
return None
B, n_patch, hidden = x.size() # reshape from (B, n_patch, hidden) to (B, h, w, hidden)
h, w = int(np.sqrt(n_patch)), int(np.sqrt(n_patch))
x = x.permute(0, 2, 1)
x = x.contiguous().view(B, hidden, h, w)
x = nn.Upsample(scale_factor=self.scale_factor)(x)
out = self.conv(x)
out = self.norm(out)
out = self.activation(out)
return out
