CFG는 Context free language를 나타내기 위한 notation이다.
재귀적 형태를 나타내는데 용이하다.
CFG의 구성
- Terminal: 대체될 수 없는 기본 symbol들을 의미한다. 보통, 토큰 이름 == terminal이 된다.
- Non-terminal: 다른 non-terminal이나 terminal로 대체될 수 있는 syntactic variable이다.
- Start symbol: 하나의 non-terminal로, 대개 첫번째 rule의 non-terminal이다.
- Production(→): Non-terminal이 대체될 때의 규칙이다.
CFG 규칙
(통상)
- Non-terminal은 대문자로, terminal은 소문자로 작성한다.
- Non-terminal, terminal, 𝜖을 포함한 일련의 문자열은 로 작성한다.
e.g.
Terminal = {+, id, *, (, )} 일 때,
e.g., 등을 나타내는 CFG는 다음과 같이 나타내질 수 있다.
Derivation
- derivation()은 replacement를 나타낸다.
- 는 0번 이상의 derivation을 나타낸다.
- 은 가장 왼쪽의 non-terminal부터 대체한다.
- 은 가장 오른쪽의 non-terminal부터 대체한다.
예를 들어, 에 대해 를 만들어보자
- left-most derive
- right-most derive
Token validation test
- CFG 의 start symbol 에 대해, 라면 는 의 sentinel form이다.
- sentinel form 가 terminal으로만 이루어졌다면 는 의 sentence form이다.
- 는 CFG 의 language이다. ()
(token 집합 등의) 입력 문자열이 에 포함된다면, 입력이 에 대해 valid하다고 할 수 있다.
좋은 CFG의 조건
- 모호성이 없다
- left recursion이 없다
- 각각의 non-terminal에 대해, 특정 input symbol로 부터 단 하나의 production만 선택 가능하다.
모호성 제거
에 대해, id*id+id를 나타내는데 다음 두가지 모두 가능하다.
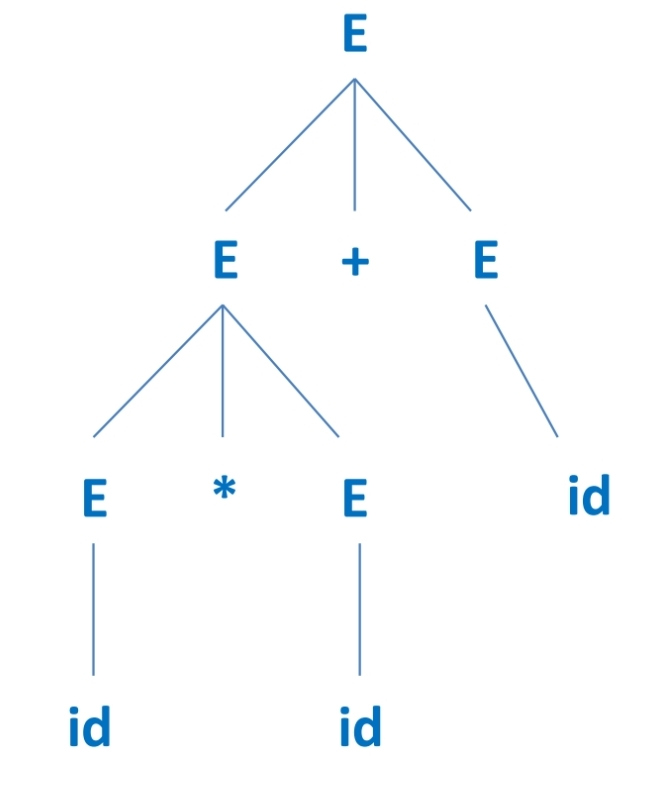 | 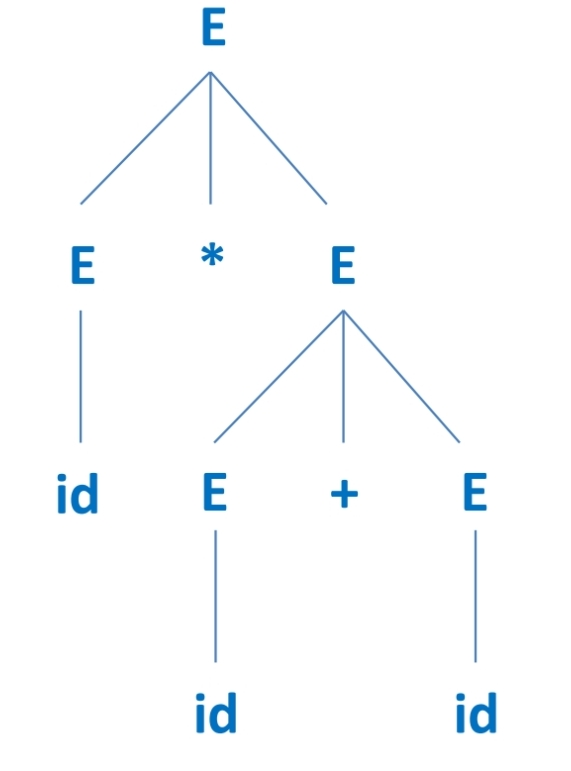 |
|---|
위와 같이 여러 tree로 나타낼 수 있는 CFG는 비효율적이다.
*가 +보다 더 높은 우선순위를 가진다는 것을 명시하면, 모호성이 제거된다.
Left-recursion 제거
(: nonterminal, : non-terminal&terminal로 이루어진 모둔 sequence) 를 포함한 문법을 left recursive grammar라고 한다.
e.g.
, 로 보면, left recursion 형태임을 알 수 있다.
이를 해결하기 위해, left-recursion을 형태의 right recursion으로 변환할 수 있다.
e.g.
- 새로운 non-terminal 를 만들고, 모든 에 대해 production rule 를, 그리고 을 추가한다.
- non-terminal 에 대해, 모든 에 대한 production rule을 추가한다.
단일 선택 보장: Left factoring
의 경우, 첫번째에서 가 중복, 두번째에서 가 중복되는 것을 볼 수 있다.
이 모호성을 제거하기 위해, left factoring을 적용할 수 있다.
- non-terminal 에 대해, 가장 긴 공통 접두사 를 찾는다.
에 대해, - 형태의 모든 production을 으로 대체한다.
- 2에서 대체된 production에 대해, 형태의 새로운 production을 추가한다.
- 모든 non-terminal에 대해 더이상 공통 접두사가 없을때까지 1-3을 반복한다.
AST(Abstract Syntax Tree)
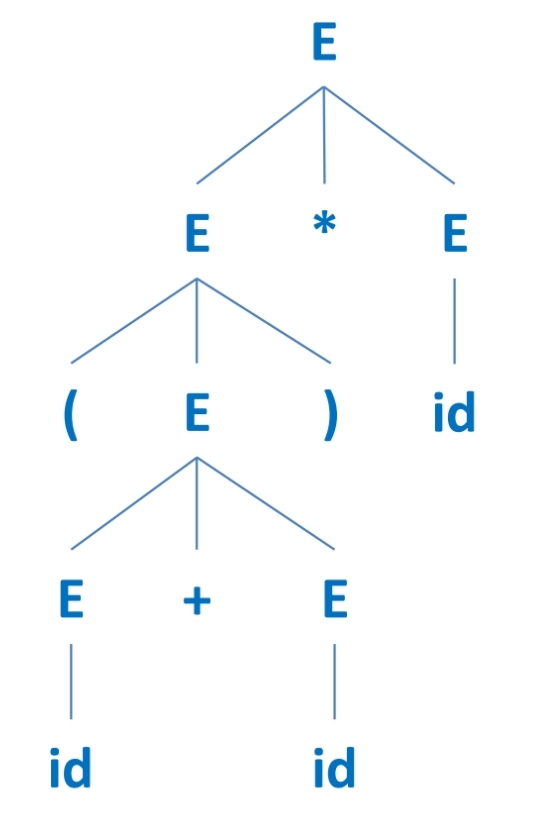
다음 parse tree에서, 할 수 있는 추상화 작업은 다음과 같다
-
Single-successor node
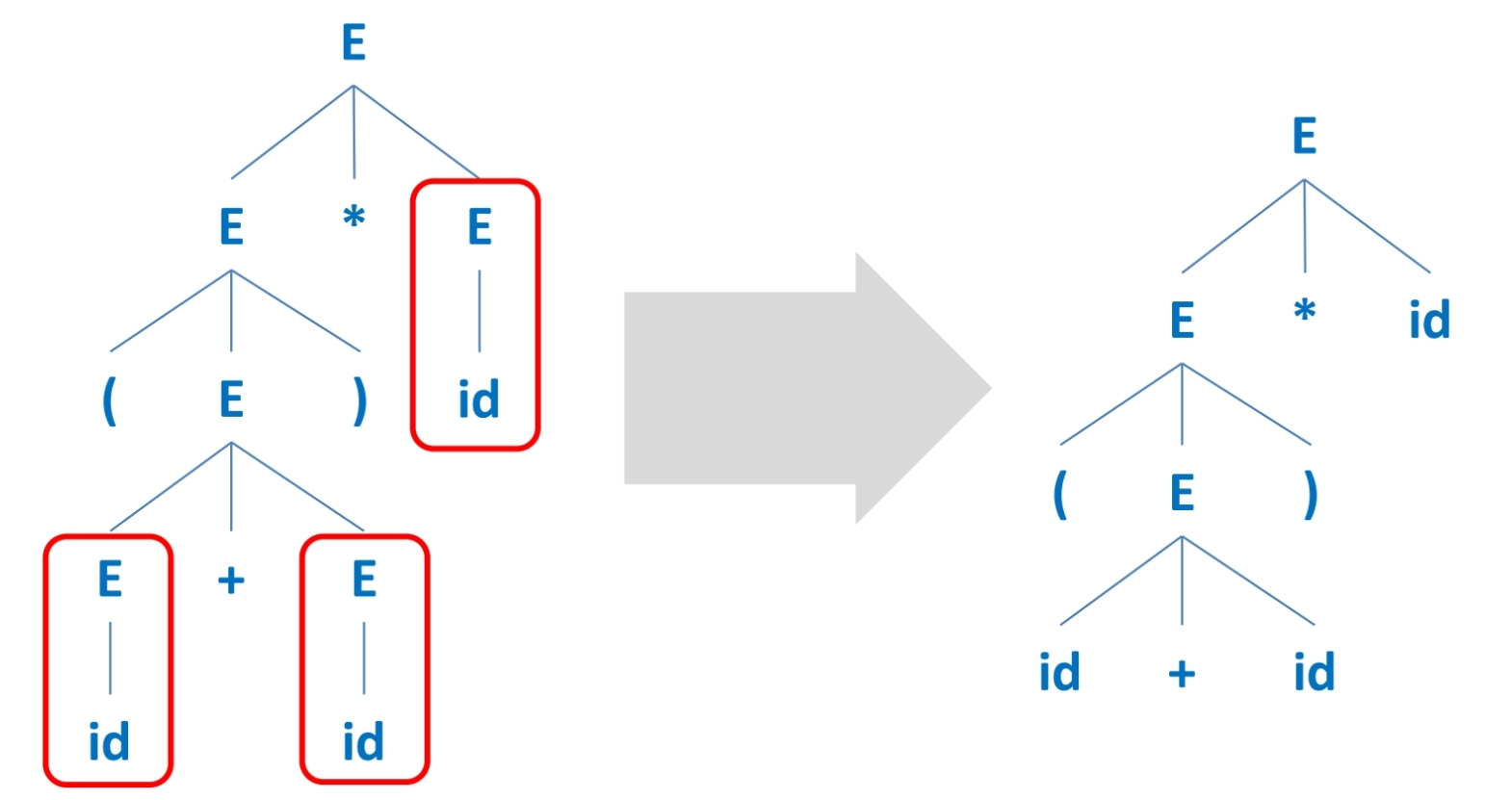
자식을 하나만 가지는 노드를 자식 노드 하나로 합친다. -
문법적 디테일 (괄호, 콤마 등)
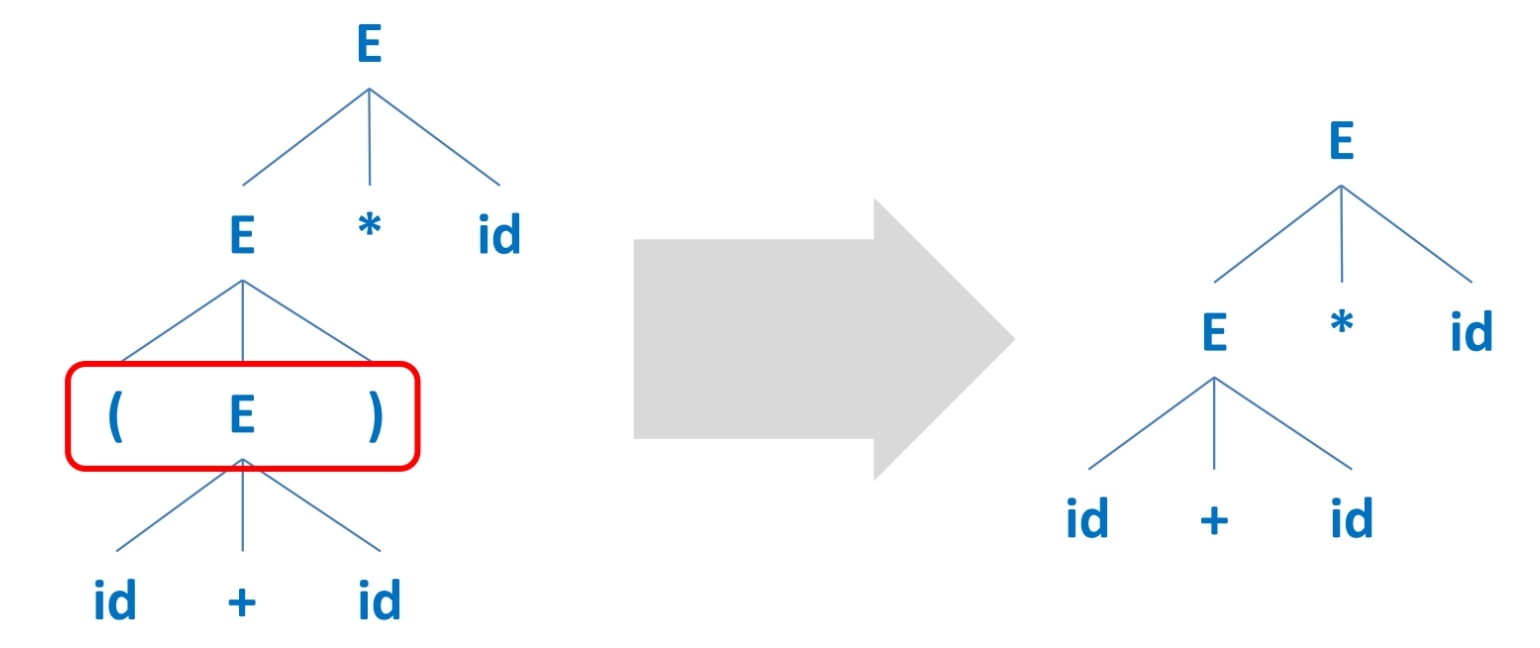
parse tree가 이미 문법적 디테일을 설명해주기 때문에, 제거해도 된다. -
연산자를 자식으로 가지는 non-terminal

AST Construction
문법적 production과 관련된 액션인 Semantic action을 만든다.
e.g. CFG :
| Production | Semantic action |
|---|---|
| E.node = new Node('+', E1.node, E2.node) | |
| E.node = new Node('*', E1.node, E2.node) | |
| E.node = E1.node | |
| E.node = new Leaf(id, id.value) |
