컴파일러
1.[Compiler] 1. Compiler Overview

Machine Language(0&1) -> Assembly -> Higher-level Language 순으로 인간 친화적이며 개발이 쉽다.Higher-level language 중에서도 C-C++-Java-Python 등의 순서로 더 higher level이다.Hi
2.[Compiler] 2. Lexical Analyzer Overview

Lexical Analyzer가 하는 일 소스 프로그램의 입력 캐릭터를 읽는다. lexeme라고 불리는, 의미있는 문자열로 입력 문자를 그룹화한다. 토큰의 시퀀스를 생성한다. symbol table에 토큰의 정보를 저장한다. 토큰들을 syntax analyzer로 전송
3.[Compiler] 2.1. Regular Languages
Regular language ⊂ Context-free language ⊂ Context-sensitive language ⊂ Recursively enumerable languageAlphabet(Σ) : 기호들의 유한 집합$Letter = {\\Sigma}^L =
4.[Compiler] 2.2. Finite Automata
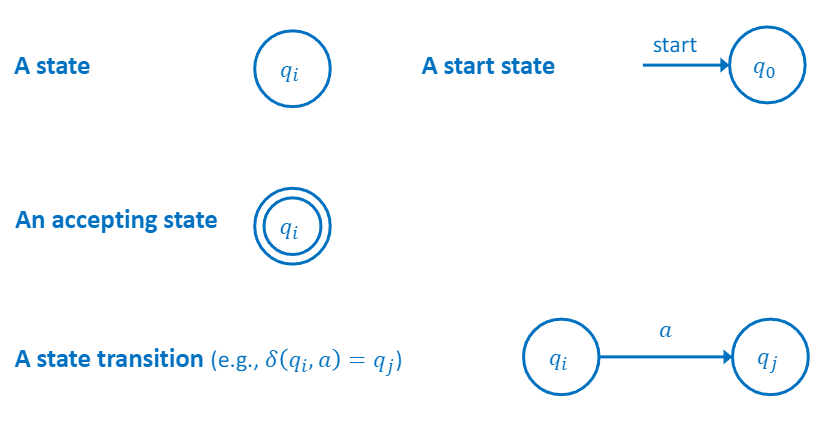
토큰 인식을 위한 구현정규식의 형태로 지정된 패턴을 기반으로 입력을 Accept/Reject 함$M={Q,\\Sigma,\\delta,q_0,F}$state들의 유한집합 $Q={q_0,q_1,q_2,\\dots ,q_i}$입력 기호의 집합, 입력 알파벳 $\\Sigma
5.[Compiler] 3. Syntax Analyzer Overview
Syntax Analyzer는 주어진 토큰들의 집합이 유효한지 판단하고, 트리 형태의 중간 표현을 생성한다. token을 분석할 때 사용한 regular expression는 이 분석에서 충분하지 않기에, context-free language를 사용한다.
6.[Compiler] 3.1. CFG(Context Free Grammars)
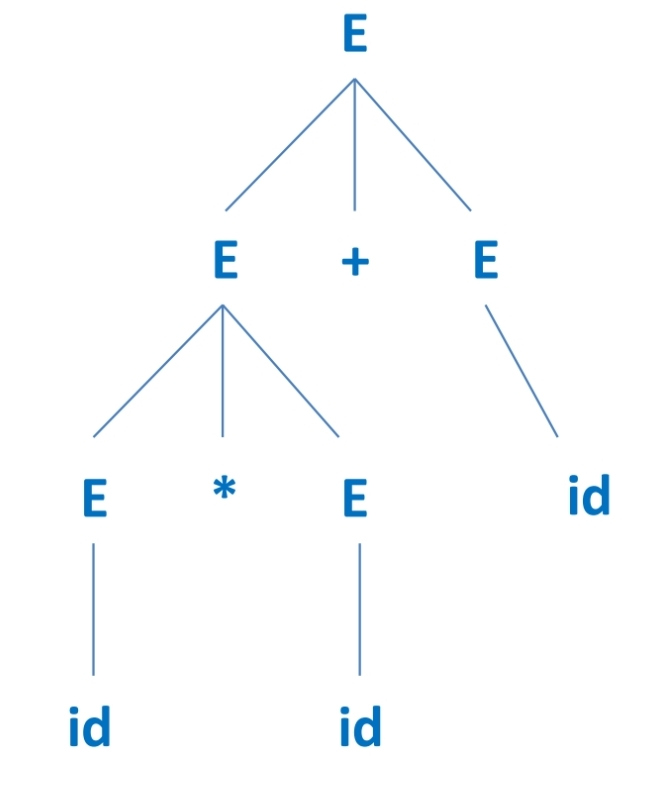
CFG는 Context free language를 나타내기 위한 notation이다. 재귀적 형태를 나타내는데 용이하다. CFG의 구성 Terminal: 대체될 수 없는 기본 symbol들을 의미한다. 보통, 토큰 이름 == terminal이 된다. Non-termi
7.[Compiler] 3.3. LR Parser (Bottom-up Parser)
LL Parsing과 반대로, right derivation에서 작동하며, 반대로 작동한다. 따라서 production이 아니라, reduction을 하는 것이다. Left factoring과 left-recursive 제거가 필요 없다. Shift-reduce