혼자 공부하는 컴퓨터 구조 + 운영체제를 읽고 공부한 내용입니다.고급언어와 저급언어
컴퓨터는 C,C++, java, python 같은 프로그래밍 언어를 이해할 수 없다.
우리가 쓰는 프로그래밍 언어는 사람이 이해하기 쉽게 만들어 졌다.
이렇게 사람이 이해하기 쉽게 만든 언어를 고급언어라고 한다.
대부분의 프로그래밍 언어가 고급언어에 해당이 된다.
컴퓨터 이해하고 실행하는 언어를 저급언어라고 한다.
저급언어는 명령어로 이루어져 있다.
저급언어에는 2가지가 있는데 기계어와 어셈블리어가 있다.
기계어는 0과 1의 비트로 이루어진 언어이다.
가독성을 위해서 16진법으로 표현이 되기 한다.
어셈블리어는 2진법과 16진법으로 표현된 명령어가 사람이 보기에는 매우 어렵기 때문에 등장을 했다.
그래서 읽기 편한 상태로 변역한 저급언어이다.
예시
기계어
0101 0101
어셈블리어
push rbp
위 예시처럼 0과1의 기계어를 사람이 읽기 편하게 변환한 것이다.
우리가 작성한 프로그래밍 언어의 소스코드가 실행이 되기 위해서는
고급언어를 저급언어로 변환하는 과정이 필요하다.
이 과정에는 2가지가 있다.
컴파일 방식과 인터프리트 방식이다.
컴파일 방식을 작동하는 프로그래밍 언어를 컴파일언어,
인터프리트 방식으로 작동하는 프로그래밍 언어를 인터프리트 언어라고 한다.
컴파일 언어
컴파일 언어는 소스코드 전체가 저급언어로 변환이 되는데 이과정을 컴파일이라고 한다.
이 컴파일을 수해하는 도구를 컴파일러라고 한다.
이 컴파일이라는 과정을 거쳐서 나온 저급언어 소스코드가 목적 코드라고 한다.
인터프리터 언어
인터프리터 언어는 소스코드를 한 줄씩 저급언어로 변환을 한다.
이렇게 한 줄씩 저급언어로의 변환을 도와주는 도구를 인터프러터라고 한다.
컴파일 언어와 인터프리터 언어의 차이점
둘의 차이점은 컴파일은 전체를 인터프리터는 한 줄씩 저급언어로 컴파일을 하는 것이다.
그렇기 때문에 오류가 발생하는 것에도 차이가 있다.
컴파일 언어에 경우 한 부분이라고 오류가 발생을 하면 컴파일에 실패한다.
인터프리터 언어에 경우 한줄 씩 변환을 하기 때문에 오류가 난 부분의 이전 부분들은 잘 실행이 된다.
또 컴파일은 전체를 한 번에 하기 때문에 컴퓨터가 읽는 속도 빠르지만
인터프리터 언어는 한 줄 한 줄 하기 때문에 컴파일보단 느리다.
예시로
친구에게 영어로 된 책을 설명을 해줄 때
컴파일은 책 전체를 변역한 변역 본을 친구에게 주는 것이고
인터프리터는 글 한 줄 한 줄을 설명하면서 알려주는 것이다.
링킹
링킹은 저급언어로 변환 된 목적 파일에 외부에서 가져오는 기능이있다면 그 기능을 연결 짓는 작업을 말한다.
예를 들면
목적 파일 main에 더하기 기능을 외부에서 가져오고 있다면 바로 실행할 수 없다.
외부에서 가져오는 더하기 기능을 연결 시켜주는 링킹을 거치고 실행이 된다.
명령어 구조
명령어는 명령어가 수행할 연산, 연산 코드를 담고 있는 연산 코드 필드와 연산에 사용될 데이터 혹은 데이터가 담긴 주소인 오퍼랜드를 담은 오퍼랜드 필드로 구성되어져 있다.
오퍼랜드
오퍼랜드는 연산에 사용될 데이터 혹은 데이터의 주소가 온다.
주소는 메모리의 주소가 될 수도 있고 레지스터의 주소가 올 수도 있다.
대부분의 직접적인 데이터보다 메모리나 레지스터의 주소가 온다.
그래서 오퍼랜드 필드를 주소 필드라고 부르기도 한다.
오퍼랜드는 명령어 안에 하나도 없을 수 있고 하나만 있을 수 있고 여러개 있을 수 있다.
오퍼랜드 필드에 갯수의 따라 0-주소 명령어, 1-주소 명령어 등등으로 불린다.
연산코드
연산 코드는 명령어를 수행할 연산을 의마한다.
연산의 코드의 종류는 많이 있지만 기본적으로 크게 4가지 유형으로 나눌 수 있다.
1. 데이터 전송
2. 산술/논리 연산
3. 제어 흐름 변경
4. 입출력 제어
주소 지정 방식
명령어는 n비트로 길이가 있다.
그 중 연산코드는 m만큼 차지를 한다면 오퍼랜드 필드가 가질 수 있는 크기는 n-m만큼만 가질 수 있다.
그렇기 때문에 데이터의 연산 코드의 크기가 클 수록 데이터가 차지하는 크기가 작아진다.
또한 오퍼랜드는 여러개가 올 수 있기 때문에 오퍼랜드 한 개당 차자할 수 있는 크기가 더 작아진다.
그런데 여기에 메모리의 주소를 담는다면 데이터의 크기가 저장한 메모리의 주소의 크기 만큼 더 커진다.
예시로
16비트의 명령에서 연산 코드가 4비트를 차지하다면 갯수에 따라 저장한 데이터의 크기에 따라 다르겠지만12비트를 사용할 수 있다.
이 오퍼랜드 필드 부분에 데이터가 아닌 데이터가 담긴 메모리 주소을 넣어보자
이 때 이 메모리 주소에 16비트까지 저장을 할 수 있다면 크기가 12비트에서 16비트로 늘어난 것이다.
이처럼 연산할 데이터가 저장된 위치의 주소를 유효 주소라고 한다.
오퍼랜드 필드에 데이터가 저장된 위치를 명시하는 방법을 주소 지정 방식이라고 한다.
즉시 주소 지정 방식
연산할 데이터를 오퍼랜드 필드에 직접 명시하는 방식이다.
테이터의 크기가 작아지는 단점은 있지만 빠르다는 장점이 있다.

직접 주소 지정 방식
유효 주소를 직접 명시하는 방식이다.
즉시 주소 지정 방식은보다는 데이터의 크기가 커졌지만은 아직까지 유효 주소를 표현하는데 제한이 생길수 있다.
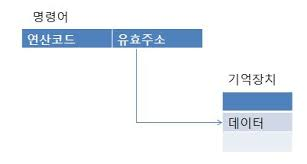
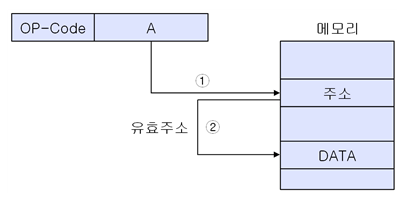
간접 주소 지정 방식
유효 주소의 주소를 오퍼랜드에 명시를 하는 것이다.
연산할 데이터가 10번지 주소에 저장이 되어 있다.
그리고 3번지 주소의 이 데이터의 주소 10번지가 저정이 되어 있다.
이 3번지 주소를 오퍼 랜드에 저장을 하는 것이다.
레지스터 주소 지정 방식
연산에 사용 될 데이터를 저장한 레지스터를 오퍼랜드에 명시하는 방법이다.
직접 주소 지정 방식과 비슷하다.

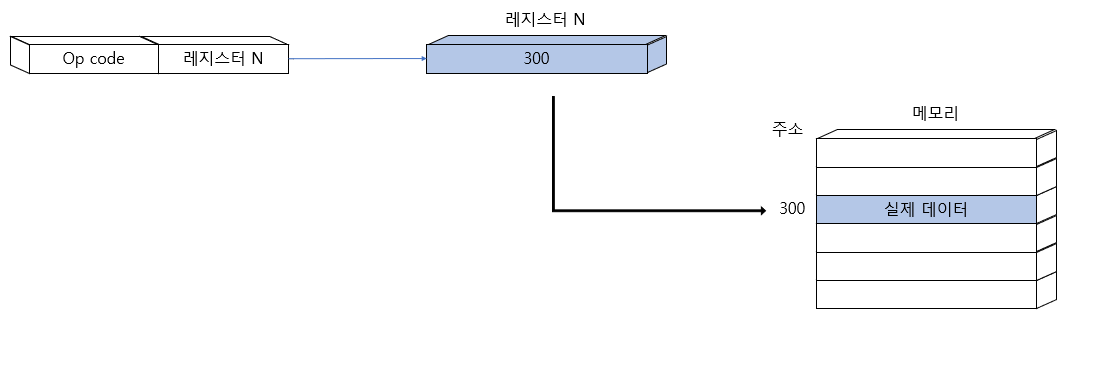
레지스터 간접 주소 지정 방식
연산에 사용 될 데이터를 저장한 메모리 주소를 레지스터에 저장하고 이를 레지스터를 오퍼랜드에 저장을 하는 방식이다.
간접 주소 지정 방식과 비슷하다.
스택과 큐
스택
스택은 한쪽의 입구가 막힌 통과 같은 저장 공간이다.
그래서 데이터가 들어온 쪽으로 나가게 되어 있다.
즉, 들어오는 입구와 나가는 출구가 같다.
그래서 LIFO(Last in First Out) 자료 구조이다.
나중에 들어온 데이터가 먼자 나가는 구조를 가진다.
큐
큐는 양쪽이 모두 뚫여 있는 저장 공간이다.
한 쪽으로 데이터가 들어오고 다른 한 쪽으로 데이터가 나간다.
FIFO(First In Last Out)자료 구조로 먼저 들어온 데이터가 먼저 나가는 구조이다.
