References
Main Idea: Factoring state value function & action adv function
Q-value function을 state value function ()와 에서 각 action이 갖는 action advantage function ()로 분리한다. → 해당 Factoring(요인 분해)의 main benefit은 기존 강화학습 알고리즘을 변형하지 않고 여러 행동에 걸쳐 학습을 일반화할 수 있다는 것이다. 즉, 값을 추정하고 update하면서 경험해보지 않은 다른 행동들에 대한 가치에도 영향을 끼칠 수 있게되었다.
Background for Dueling Network
정책 하에서 Q-value와 state value는 다음과 같이 정의된다.
이때 번 식은 dynamic programming에 의해 다음과 같이 계산할 수 있다.
번식을 우리에게 익숙한 벨만 방정식의 형태로 풀어 쓰면 번과 같다. (참고:Q(s,a)와 V(s)의 Bellman Equation)
이때 최적의 Q-value를 라고 하자. Deterministic policy에서는 이며 즉, 이다. 이때 function은 아래의 벨만 방정식을 만족한다.
Q-value와 State value를 이용해서 action advantage value를 정의할 수 있으며 다음과 같다:
이때 식 에 의해서 이다.
The Dueling Network Architecture
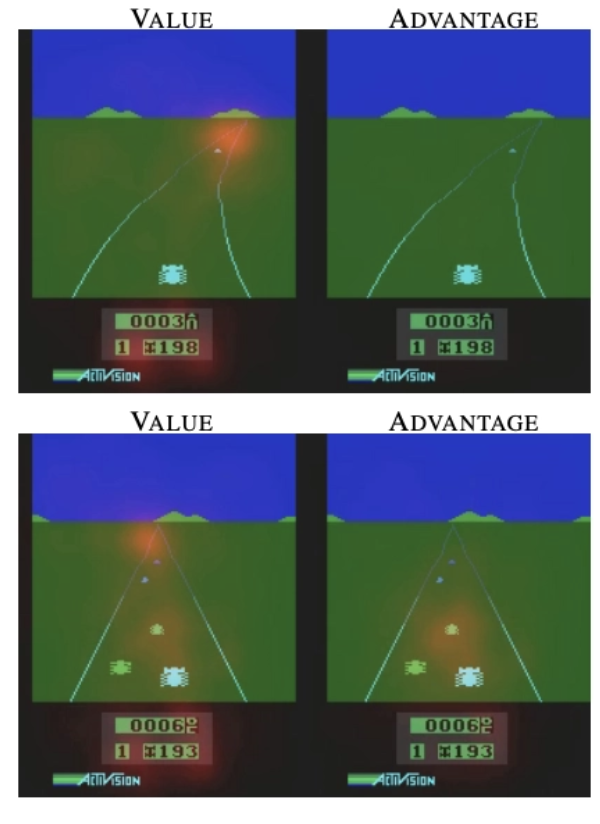 [Figure 1]. Value and advantage saliency maps (red-tinted overlay) on the Atari game Enduro, for a trained dueling architecture.
[Figure 1]. Value and advantage saliency maps (red-tinted overlay) on the Atari game Enduro, for a trained dueling architecture.
Figure 1은 Dueling network에서 value stream과 action advantage stream이 어느 부분에 집중하고 있는지를 알 수 있다. 장애물이 없는 상황(1행)과 앞에 장애물이 등장하는 상황(2행)에서 각 stream의 saliency map에서 알 수 있듯이, value stream은 도로 상황 자체에 주목을 한다. 이에 반해 advantage stream은 오직 장애물이 있을때만 충돌을 피하기 위해 주의를 기울이도록 학습된다. 위 실험의 핵심은 “수 많은 state에서 각 action선택의 가치를 일일이 추정할 필요가 없다”이다. 하지만 bootstrapping based algorithms에서는 를 잘 추정하는 것이 매우 중요하다.
Bootstrapping based algorithms란 자신의 현재 예측값을 다음 상태에 대한 예측값으로 업데이트 하는것을 의미한다. DQN에서 target값은 와 같이 산출된다. 그렇다면 왜 bootstrapping based algorithm에서는 를 잘 추정하는 것이 중요할까?
→ 와 같다. 식 과 식 또한 정확한 값을 계산하려면 결국 과 값에 따라서 계산되는 것을 알 수 있다. 그래서 bootstrapping based algorithms에서는 상태가치값을 잘 추정하는 것이 중요하다.
기존 DQN, DDQN에서는 값을 정확하게 추정하려면 값을 개별적으로 정확하게 추정을 해야 했다. 하지만 이는 앞서 설명했던 이유로 비효율적이다. Dueling Architecture는 와 action에 대한 를 분리하여 학습하고자 한다. [Figure 2]은 각각 기존의 Q-network architecture와 Dueling Q- network architecture이다.
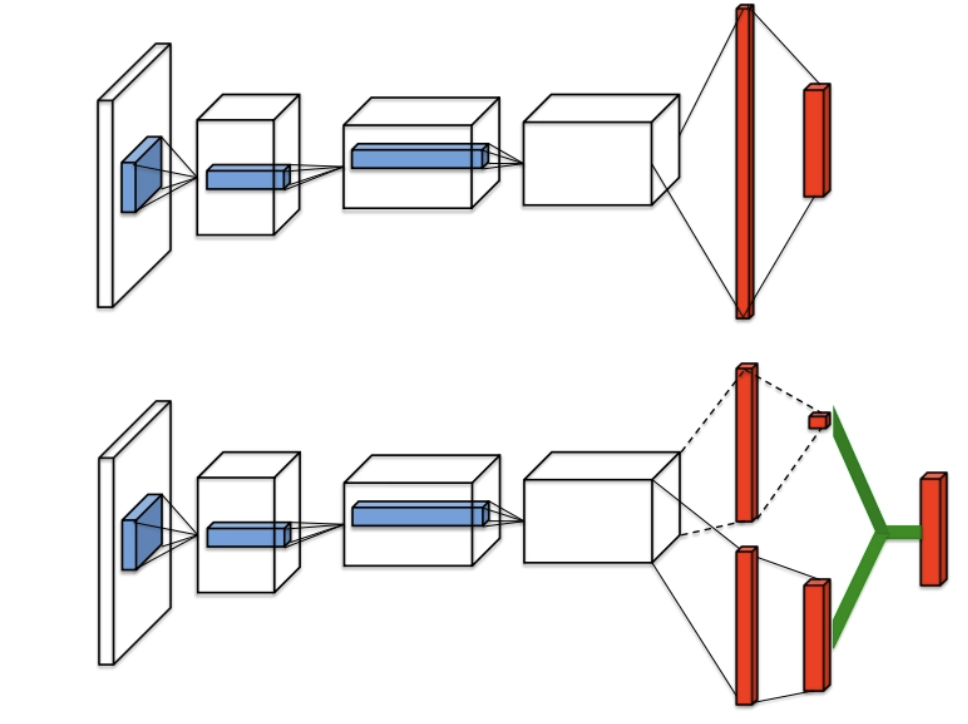 [Figure 2]. 위에 그림은 기존의 DQN에서 쓰이던 single stream Q-network이고, 아래 2개의 stream으로 이루어진 것이 dueling network의 architecture이다.
[Figure 2]. 위에 그림은 기존의 DQN에서 쓰이던 single stream Q-network이고, 아래 2개의 stream으로 이루어진 것이 dueling network의 architecture이다.
Dueling network architecture의 끝단을 보면 2가지 stream으로 나뉘어져서 scalar값인 와 state 에서 선택할 수 있는 각 action 에 대한 값으로 나뉜다. 이후 aggregate를 통해 이 두값이 결합되며 최종 값을 계산하게 된다. 는 policy network의 weights를 의미하고, 는 각각 action advantage stream의 weights와 value stream의 weights를 의미할 때 aggregate layer를 통해서 최종 Q-value를 계산하는 방법으로는 아래의 3가지 방법이 제시가 된다.
식 은 unidentifiable problem을 발생시킨다. 즉, 주어진 값을 고유한 값과 값으로 분리해낼 수 없다 (어떤 값이 주어졌을때 를 만족하는 쌍은 무수히 많다). Unidentifiable problem을 해결하기 위해 제시하는 방법이 식 이다. 일 때 이므로 식 에서 일 때, 와 같다. 즉, 에서 상태가치값은 에서 최적의 에 대한 Q-value를 의미하게 되며 이는 곧 최적 상태 가치값을 의미하게 된다. 이에따라 는 상태가치를 추정하게 되며, 다른 stream은 action advantage value를 추정하게 된다.
Definition of Optimal State Value and State Value.
식 에서는 의 평균값이 0이 되도록 강제한다. 이에 따라 의 의미는 식 에서 가지고 있던 “최적 상태 가치 값”이라는 의미를 잃어버리고 대신 “에서 Q(s,a)의 평균값”이라는 의미를 가지게 된다. 그에 따라 와 가 정답에서 상수만큼 벗어나게 된다. 하지만 역전파시에 식 는 최적 행동의 advantage값이 바뀌어도 다른 advantage값들이 단지 평균이 변하는 속도에 맞춰서 update를 하면 되기 때문에 훨씬 안정적이다. 따라서 해당 논문 뿐 아닌 대부분 Dueling architecture를 이용한 논문에서는 식 를 채택한다.
Numerical Experiment
모델의 성능과 강건성(단순히 행동의 순서를 암기하는 것이 아닌지)을 테스트하기 위해 30 no-ops와 Human Starts 이렇게 2가지 실험을 진행한다. 30 no-ops는 30회 동안 아무행동도 하지 않고 31회 지점부터 Agent가 게임을 하기 시작하는 것으로 starting point를 무작위로 만들어 주기 위해 한다. Human starts는 30 no-ops보다 좀 더 강건한 성능 지표를 얻기 위해 사용된 방법으로, 실제 사람이 플레이한 게임중 일부분을 sampling을 하여 그 지점을 시작 지점으로 삼는다. 알고리즘 별 결과는 아래와 같다.
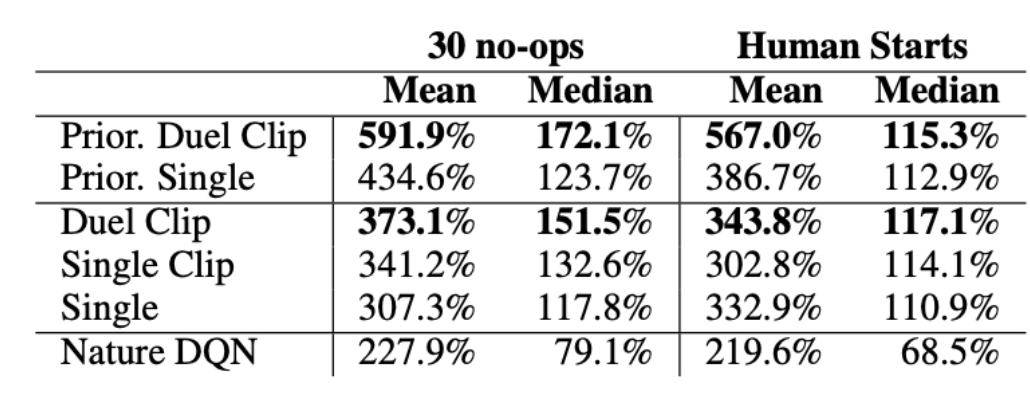 [Table 1] Human Performance 대비 각 algorithm의 performance table. 이때 Prior은 PER적용 여부, Clip은 gradient clipping적용 여부를 나타낸다.
[Table 1] Human Performance 대비 각 algorithm의 performance table. 이때 Prior은 PER적용 여부, Clip은 gradient clipping적용 여부를 나타낸다.
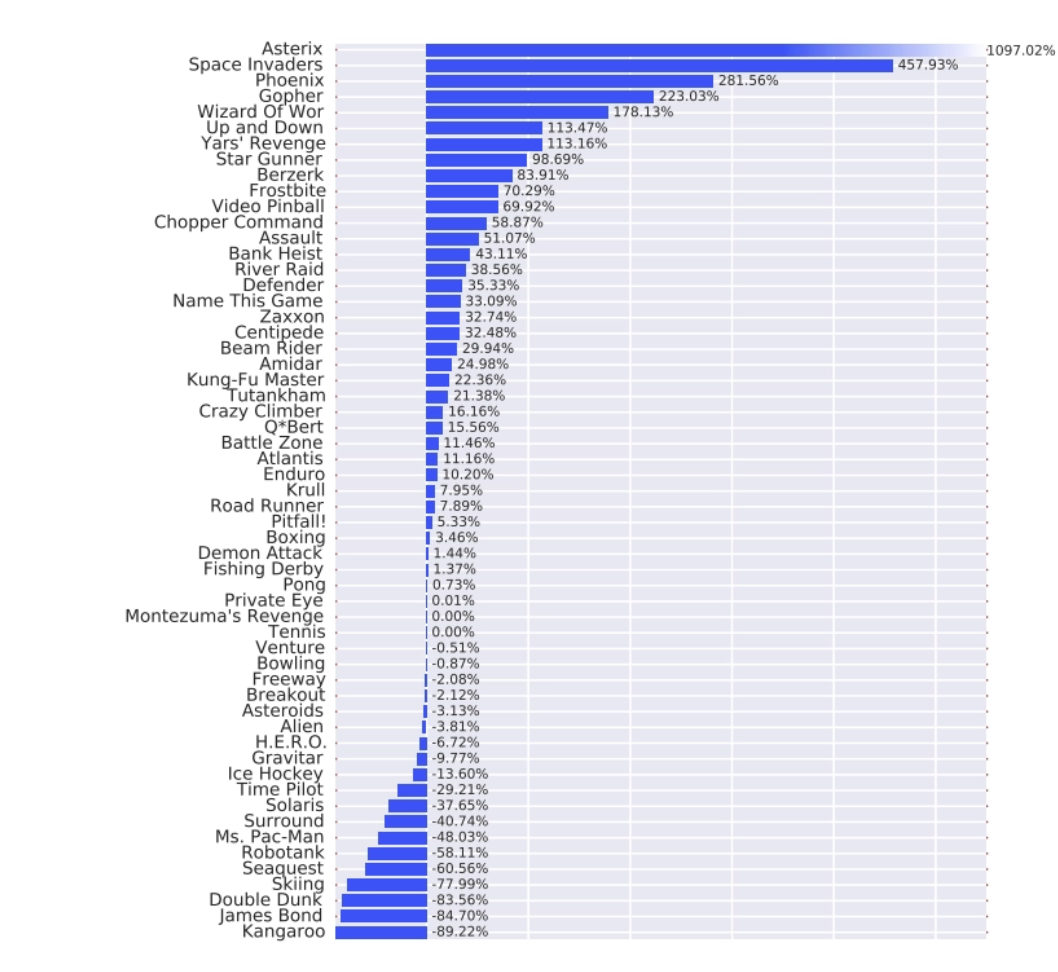 [Figure 5] PER을 적용했을때 개별 atari game에서 baseline대비 dueling architecture의 성능. 이때 baseline알고리즘은 Prioritized DDQN이다.
[Figure 5] PER을 적용했을때 개별 atari game에서 baseline대비 dueling architecture의 성능. 이때 baseline알고리즘은 Prioritized DDQN이다.
Figure 5에서도 Table 1에서 확인한 것과 동일한 결과를 볼 수 있다. 일부 게임을 제외 하고는 dueling architecture를 적용한 알고리즘이 더 좋은 성능을 보이는 것을 볼 수 있다. 이때 사용한 지표는 과 같다.
Implementation
Dueling architecture를 적용한 알고리즘과(Dueling DQN, Dueling DDQN) 이전의 single stream 알고리즘(DQN, DDQN)들은 Network architecture를 제외한 나머지 코드들은 완전히 동일하다. 아래 코드를 통해서 구현상 어떤 차이점이 있는지 알아보자
Code1. Single stream network code and dueling network code.
# Single Stream (DQN, DDQN)
class DeepQNetwork(nn.Module):
def __init__(self, n_actions):
super().__init__()
self.in_channels = 4
self.n_actions = n_actions
dim_head = 128
# Convolusion layers
self.features = nn.Sequential(
nn.Conv2d(self.in_channels, 32, kernel_size=8, stride=4),
nn.ReLU(),
nn.Conv2d(32, 64, kernel_size=4, stride=2),
nn.ReLU(),
nn.Conv2d(64, 64, kernel_size=3, stride=1),
nn.ReLU(),
nn.Flatten()
)
cnn_out_dim = 64 * 7 * 7
# Fully connected layers
self.fc = nn.Sequential(
nn.Linear(cnn_out_dim, dim_head),
nn.ReLU(),
nn.Linear(dim_head, dim_head // 2),
nn.ReLU(),
nn.Linear(dim_head // 2, n_actions)
)
def forward(self, state):
features = self.features(state)
q_values = self.fc(features)
return q_values
def get_q_values(self, state):
if state.dtype == torch.uint8:
state = state.float() / 255.0
q = self.forward(state)
return q
# Dueling architecture
class DuelingQNetwork(nn.Module):
def __init__(self, n_actions):
super().__init__()
self.in_channels = 4
self.n_actions = n_actions
dim_head = 128
self.shared = nn.Sequential(
nn.Conv2d(self.in_channels, 32, kernel_size=8, stride=4),
nn.ReLU(),
nn.Conv2d(32, 64, kernel_size=4, stride=2),
nn.ReLU(),
nn.Conv2d(64, 64, kernel_size=3, stride=1),
nn.ReLU(),
nn.Flatten()
)
cnn_out_dim = 64 * 7 * 7
self.value_head = nn.Sequential(
nn.Linear(cnn_out_dim, dim_head),
nn.ReLU(),
nn.Linear(dim_head, dim_head//2),
nn.ReLU(),
nn.Linear(dim_head//2, 1)
)
self.adv_head = nn.Sequential(
nn.Linear(cnn_out_dim, dim_head),
nn.ReLU(),
nn.Linear(dim_head, dim_head//2),
nn.ReLU(),
nn.Linear(dim_head//2, n_actions)
)
def forward(self, state):
shared = self.shared(state)
value = self.value_head(shared)
advs = self.adv_head(shared)
return value, advs
def get_q_values(self, state):
if state.dtype == torch.uint8:
state = state.float() / 255.0
value, advs = self.forward(state)
advs_mean = advs.mean(dim=-1, keepdim=True)
q = value + (advs - advs_mean)
return q결과적으로 두 아키텍처의 핵심적인 차이는 forward() 및 get_q_values()의 흐름에서 드러난다. 기존 Deep Q Network에서는 single stream으로 Q-value를 직접 추정하는 반면, Dueling Network는 forward() 단계에서 와 를 분리하여 추정한다. 이후 get_q_values() 이후 식 의 연산을 거쳐 최종 로 병합되는 Dueling 아키텍처만의 구조적 특징을 확인할 수 있다.
