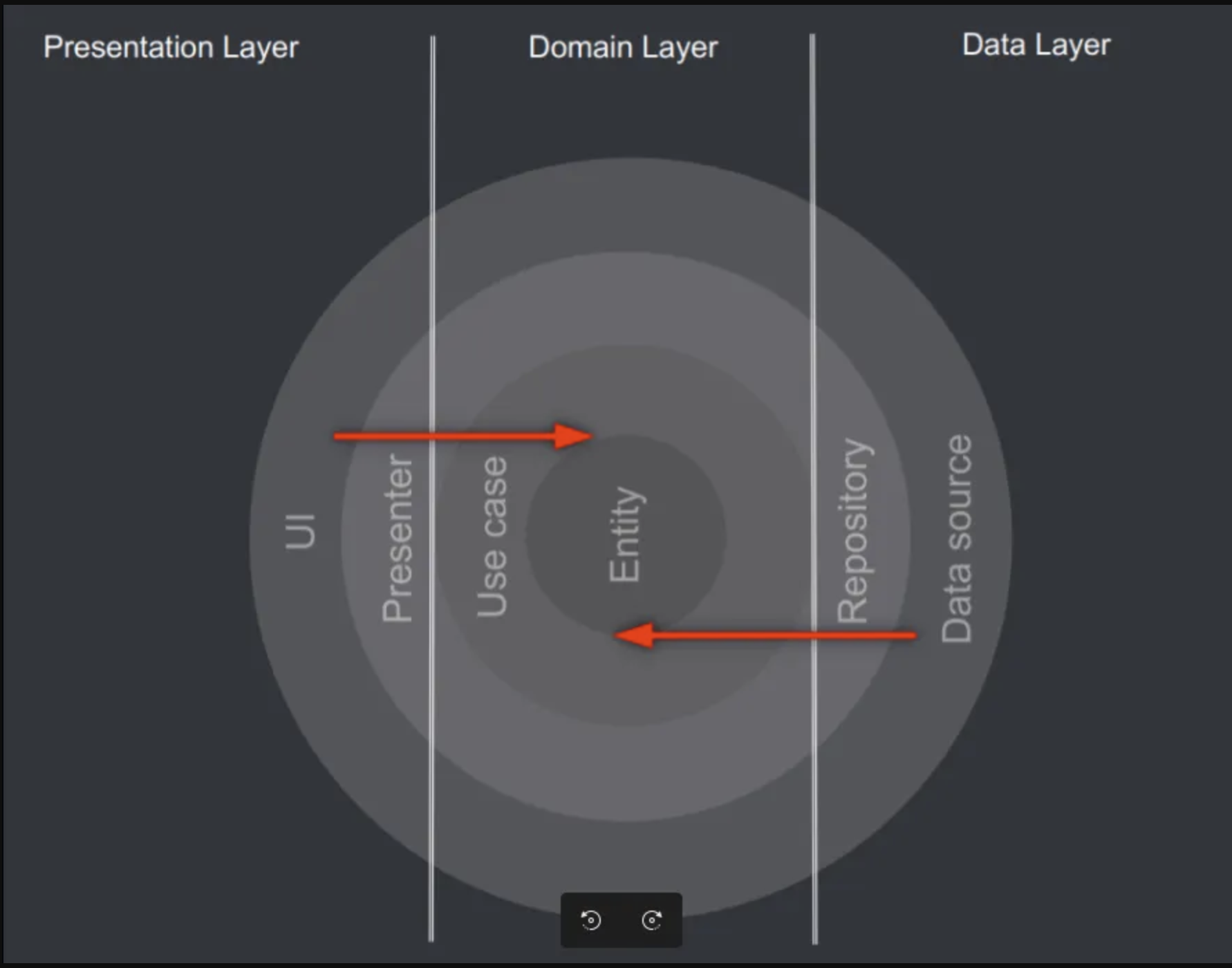
소프트웨어 개발에서 아키텍처는 프로젝트의 뼈대를 구성하는 중요한 요소 중 하나다. 그중에서도 클린 아키텍처(Clean Architecture)는 소프트웨어의 유지보수성과 확장성을 극대화하기 위해 제안된 설계 원칙이다.
이번 글에서는 필자가 실제 운영하고 있는 서비스에서 클린 아키텍처를 적용하면서 경험한 시행착오를 돌아보고, 이를 통해 얻은 인사이트를 공유하려 한다.
Keyword 및 중점 내용
- 클린 아키텍처
- Entity 와 Model의 분리
- Model 과 1:1 대응한 Entity 설계 방식
개요
클린 아키텍처의 핵심 개념은 의존성 역전(Dependency Inversion) 원칙을 기반으로 하여, 비즈니스 로직과 프레젠테이션, 데이터 접근 등의 관심사를 분리하는 것이다. 이를 통해 도메인 로직을 프레임워크나 UI로부터 독립적으로 설계할 수 있으며, 테스트가 용이하고 변경에 강한 구조를 만들 수 있다.
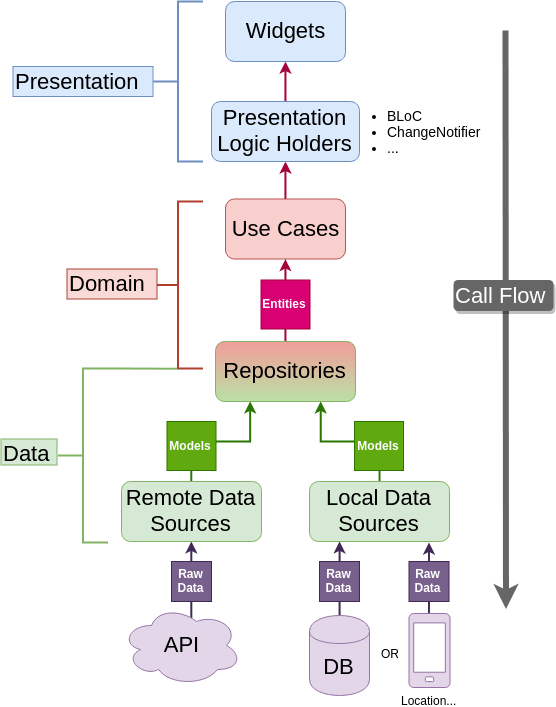
필자는 클린 아키텍처의 레이어는 다음과 같이 구성할 수 있다.
- Data Layer
- DB, 웹서비스, 디바이스 내부 DB 등 외부 Data Source(Local, Remote)로부터 데이터를 핸들링하는 레이어- Data Sources : REST API, 로컬 DB, Shared Preferences 등에서 데이터를 가져오는 클래스
- Models : 데이터를 표현하는 모델 클래스(JSON 직렬화 / 역직렬화 포함)
- Repository (구현체) : N개의 Data Source 를 다루며 Domain Layer의 Repository Interface 를 구현한 클래스
- Domain Layer
- 앱의 핵심 비즈니스 로직을 처리하는 레이어- Entities : 애플리케이션의 핵심 데이터를 표현하는 객체
- Use Cases : 특정 기능을 수행하는 서비스 로직
- Repository interfaces : Data Layer와의 의존성을 줄이기 위한 추상화 계층
- Presentation Layer
- UI 및 상태 관리를 담당하는 레이어- bloc : 상태 관리 및 UI 로직 처리
- Pages : 화면
- Widgets : 재사용 가능한 UI 컴포넌트
문제 상황 정의
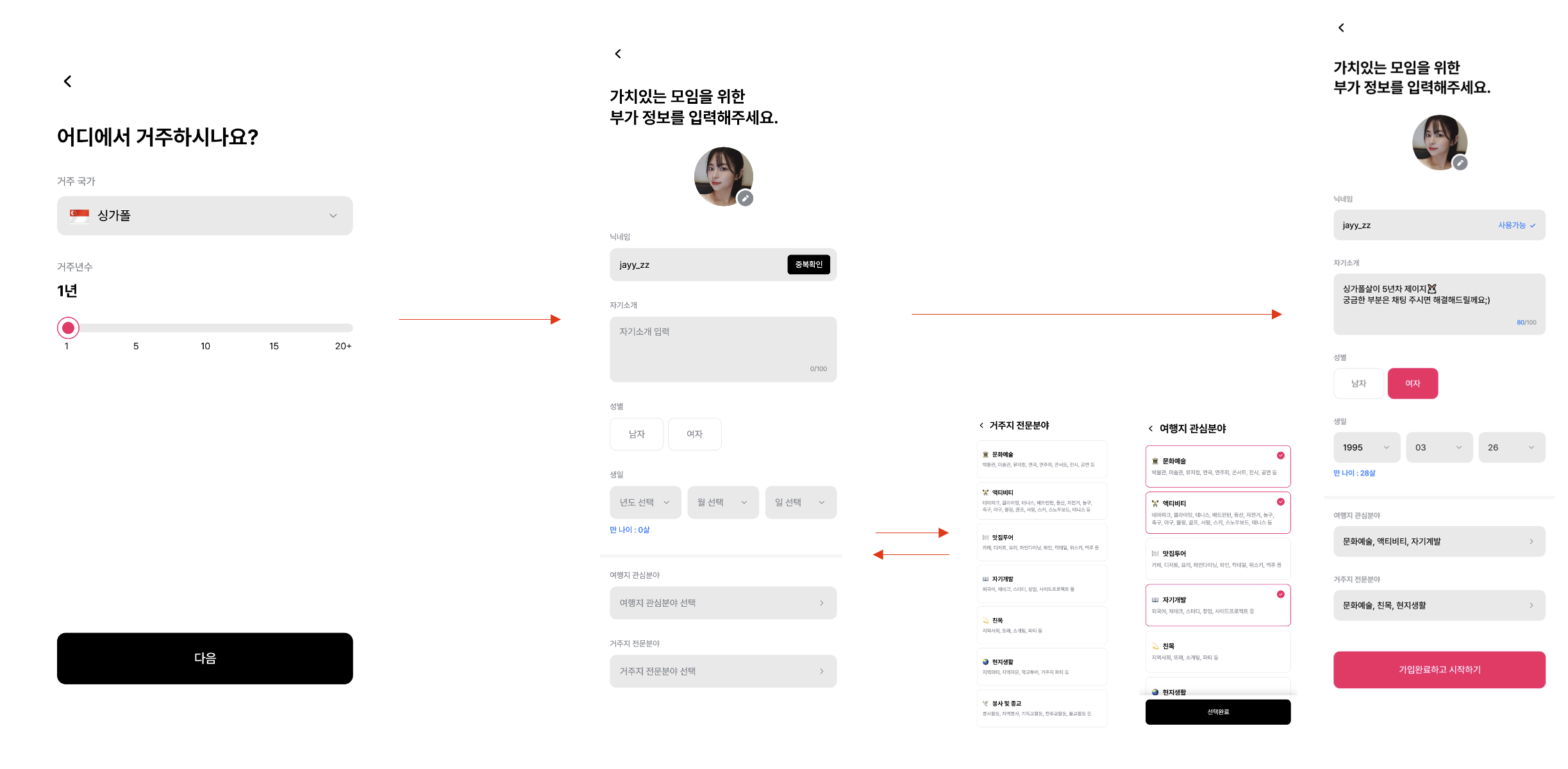
회고록의 이해를 돕기 위해 실제 운영하고 있는 서비스의 일부 기능 중 하나를 가져왔다. 해당 화면은 사용자가 프로필을 만드는 과정을 나타낸 것으로, 4개의 페이지를 통해 수집된 13개의 데이터를 서버로 전송해야 하는데 이 때 필요한 데이터는 다음과 같다.
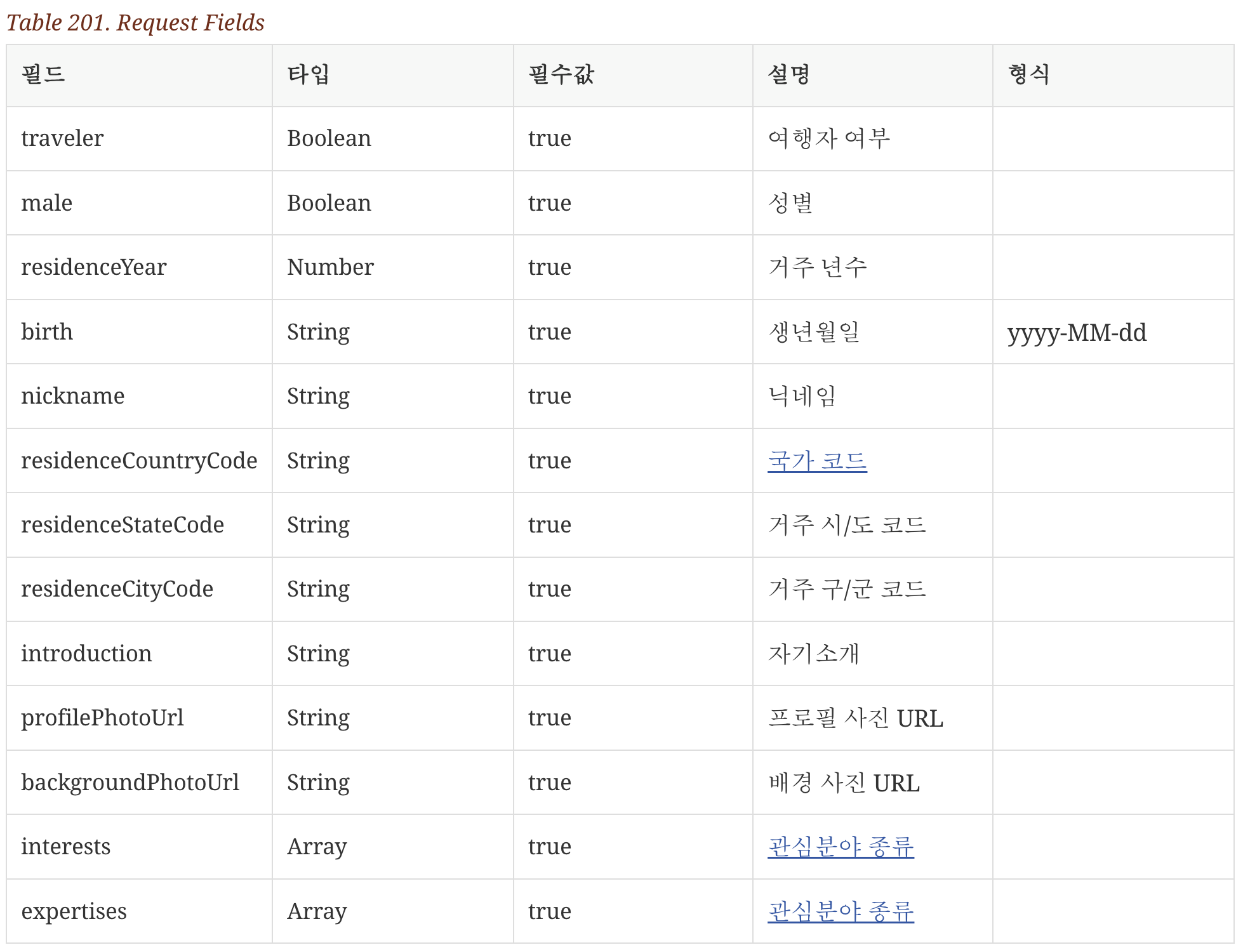
여기서 주목해야 할 점은 String profilePhotoUrl 과 String backgroundPhotoUrl 인데, 프로필 생성 요청을 보내기 이전에 우선 S3에 업로드를 한 뒤, 해당 이미지가 저장되어 있는 다운로드 URL 을 받아와야 한다. 그 이후 해당 URL 을 위에서 언급한 profilePhotoUrl, backgroundPhotoUrl 에 값을 할당한 뒤 프로필 생성 요청을 보내야 한다. 즉 다음 사진과 같은 로직을 수행해야 한다.

자체 서버(해당 서비스 운영 서버)로 우선 PreSigned URL을 요청해서 받아온 뒤에 해당 URL 로 이미지를 업로드를 하는 로직은 AwsUploadMediaUseCase 라는 Usecase 에 구현을 해놓았다. 1~2번을 수행한 결과로 해당 이미지가 업로드가 된 URL을 받게 되는데 이 형태는 cdn이 붙어 있는 URL 형태이며 이를 가지고 String profilePhotoUrl 과 String backgroundPhotoUrl에 알맞게 할당해 준 뒤 나머지 입력 데이터들(11개)를 가지고 프로필 생성 요청을 보내는 예시이다. 해당 과정을 클린 아키텍처 적용을 했을 때 겪었던 시행착오들을 가지고 Domain의 Entity를 어떻게 설정했고, Presentation-Domain-Data Layer 의 Call Flow 에 따라 설명하겠다.
첫번째 시행착오: Entity <-> Request/Response 1:1 대응
- ProfileCreateRequestEntity 설계
class ProfileCreateRequestEntity {
bool? traveler;
bool? male;
int? residenceYear;
String? birth;
String? nickname;
String? residenceCountryCode;
String? residenceStateCode;
String? residenceCityCode;
String? introduction;
String? profilePhotoUrl;
String? backgroundPhotoUrl;
List<String>? interests;
List<String>? expertises;
}우선 해당 Entity 를 Request DTO 와 1:1 대응하여 구성한 이유는 다음과 같다.
- 프로필 생성 API 를 호출할 때 4개의 화면에서 총 13 개의 데이터를 수집해야 하는데, 이를 저장할 데이터 객체가 필요하며 유지보수가 용이하다.
- 데이터 변환을 최소화할 수 있다. (Entity <-> Model)
위의 두 가지 이유로 Data Layer 의 Model 과 1:1 대응하는 Entity 를 만들어 해당 Entity 를 Presentation Layer 에서 사용하였고, UI 의 입력값들을 상응하는 Entity 의 필드에 값을 할당해주었다. 이 때까지만 해도 클린 아키텍처에서 핵심적인 원칙 중 하나인 의존성 방향이 항상 바깥쪽 원에서 안쪽 원으로 향해야 하기 때문에 UI(가장 바깥쪽)에서 Entity(가장 안쪽)에 의존해도 된다고 생각해서, 해당 Entity 를 Presentation Layer 에서도 사용했었다.
또한 해당 Entity 를 가변 객체로 만든 이유는 UI의 입력값에 변경이 잦기 때문에 해당 객체의 값을 적은 비용으로 수정하기 위함이다. 해당 Entity 를 불변 객체로 만들어서 사용할 경우 사용자가 UI의 입력값을 변경할 때마다 해당 Entity의 객체를 복사하여 교체하거나 copyWith() 함수를 추가로 만들어 되는 점이 번거롭다고 판단하여 가변 객체로 만들어 사용하였다.
- Presentation Layer
- profile_create_event.dart
sealed class ProfileCreateEvent extends Equatable {
const ProfileCreateEvent();
}
class CreatePersonalProfile extends ProfileCreateEvent {
const CreatePersonalProfile({
required this.userId,
requiired this.entity
});
final int userId;
final ProfileCreateRequestEntity entity;
List<Object?> get props => [userId, entity];
}- profile_create_bloc.dart
class ProfileCreateBloc extends Bloc<ProfileCreateEvent, ProfileCreateState> {
final AwsUploadMediaUseCase awsUploadMediaUseCase =
serviceLocator<AwsUploadMediaUseCase>();
final CreateMyProfileUseCase createMyProfileUseCase =
serviceLocator<CreateMyProfileUseCase>();
ProfileCreateBloc() : super(ProfileCreateInitial()) {
on<CreatePersonalProfile>(_createPersonalProfile);
...
}
Future<void> _createPersonalProfile(CreatePersonalProfile event,
Emitter<ProfileCreateState> emit) async {
emit(ProfileCreateLoading());
/// 이미지 업로드 이후 다운로드 URL 저장할 변수들
late String profilePhotoUrl;
late String backgroundPhotoUrl;
// 이미지 S3 업로드 로직 생략(위의 두 변수에 URL 할당하는 작업)
...
/// Entity 의 profilePhotoUrl, backgroundPhotoUrl 교체
/// (기존) 이미지가 저장되어 있는 경로(앨범에서 가져오므로 해당 파일의 경로가 들어가 있음)
/// (변경) Download URL
final profileCreateEntity = event.entity;
profileCreateEntity.profilePhotoUrl = profilePhotoUrl;
profileCreateEntity.backgroundPhotoUrl = backgroundPhotoUrl;
/// 프로필 생성 요청
final result = await createMyProfileUseCase.execute(event.userId, profileCreateEntity);
result.when(
success : (data) {
emit(ProfileCreateSuccess(data));
},
failure: (error) {
emit(ProfileCreateFailure(error));
}
);
}
}- Domain Layer
- profile_create_response_entity.dart
class ProfileCreateResponseEntity {
final int userId;
final String nickname;
final bool traveler;
/// 일부 필드 생략
...
const ProfileCreateResponse({
required this.userId,
required this.nickname,
required this.travler,
...
});
/// 일부 비즈니스 로직 생략
...
}- create_my_profile.dart
class CreateMyProfileUseCase {
final ProfileRepository profileRepository;
CreateMyProfileUseCase({required this.profileRepository});
Future<Result<ProfileCreateResponseEntity>> execute(int userId, ProfileCreateEntity entity) {
return profileRepository.createMyProfile(userId, entity);
}
}- profile_repository.dart
abstract class ProfileRepository {
Future<Result<ProfileCreateResponseEntity>> createMyProfile(int userId, ProfileCreateEntity entity);
/// 다른 함수들 생략
...
}- Data Layer
- profile_create_request_model.dart
class ProfileCreateRequestModel with _$ProfileCreateRequestModel {
factory ProfileCreateRequestModel({
required bool traveler,
required bool male,
required int residenceYear,
required String birth,
required String nickname,
required String residenceCountryCode,
required String residenceStateCode,
required String residenceCityCode,
required String introduction,
required List<String> interests,
required List<String> expertises,
required String profilePhotoUrl,
required String backgroundPhotoUrl,
}) = _ProfileCreateRequestModel;
factory ProfileCreateRequestModel.fromJson(Map<String, dynamic> json) =>
_$ProfileCreateRequestModelFromJson(json);
}- profile_create_response_model.dart
class ProfileCreateResponseModel with _$ProfileCreateResponseModel {
factory ProfileCreateResponseModel({
required String nickname,
required bool traveler,
...
}) = _ProfileCreateResponseModel;
factory ProfileCreateResponseModel.fromJson(Map<String, dynamic> json) =>
_$ProfileCreateResponseModelFromJson(json);
}위의 두 Model 클래스를 보면 @freezed 라이브러리를 이용하여 단순히 JSON 직렬화/역직렬화 하는 기능만 담고 있다. 이렇게 되면 Entity 와 Model 의 차이를 혼동할 수 있을 텐데, 필자는 Model 과 Entity 를 다음과 같이 정의하였다.
- Entity : 애플리케이션의 핵심 비즈니스 로직과 도메인 데이터를 가지고 있는 객체.
- Model : JSON 직렬화 / 역직렬화만 담당하며, 비즈니스 로직이 없는 데이터 전송 객체.
다음과 같이 정의한 이유로는, 서버로부터 받은 데이터를 애플리케이션 내부에서 바로 사용하기보다는, 도메인 로직에 맞게 변환하여 관리하는 것이 더 유연하고 확장성이 높기 때문이다.
예를 들어, 서버에서 반환된 JSON 데이터는 API 설계에 따라 구성되며, 이는 애플리케이션이 필요로 하는 도메인 모델(Entity)과 정확히 일치하지 않을 수 있다. API 응답 데이터는 종종 RESTful 또는 GraphQL의 설계 원칙에 따라 최적화되어 있으며, UI 또는 비즈니스 로직을 수행하는 도메인 계층에서 그대로 사용하기에 적절하지 않을 수 있다. 따라서, Model은 서버에서 받은 원본 데이터를 표현하는 역할을 하고, Entity는 해당 데이터를 애플리케이션의 도메인 요구사항에 맞게 변환하여 사용하도록 한다.
이러한 분리를 통해 얻을 수 있는 주요 장점은 다음과 같다.
- 데이터 구조 변경에 대한 유연성
• 서버의 API 응답 형식이 변경되더라도 Model을 조정하면 되며, Entity를 사용하는 비즈니스 로직은 영향을 받지 않는다.
• Entity는 애플리케이션 내부의 도메인 로직을 반영하기 때문에, API 변경에 독립적으로 유지될 수 있다.
- 비즈니스 로직과 데이터 구조의 명확한 분리
• Model은 데이터 전송 객체(DTO)로서 직렬화/역직렬화만 담당하고, 어떠한 비즈니스 로직도 포함하지 않는다.
• Entity는 도메인 규칙을 반영하며, Model과 다르게 비즈니스 로직을 직접 포함할 수 있다.
- 데이터 가공 및 변환 과정의 명확화
• 서버 응답을 받은 후, 애플리케이션이 필요로 하는 형태로 변환하여 Entity에 저장할 수 있다.
• 예를 들어, 서버에서 날짜 데이터를 timestamp 형식으로 반환하는 경우, Model에서는 int 값으로 저장하고, Entity에서는 이를 DateTime 객체로 변환하여 사용할 수 있다.
따라서, Model과 Entity를 구분하는 것은 단순한 코드 구조의 차이가 아니라, 데이터 처리 방식과 애플리케이션의 유지보수성을 고려한 설계 원칙의 일환이다. Model은 네트워크 레이어에서 원본 데이터를 표현하는 역할을 수행하며, Entity는 애플리케이션 내부에서 비즈니스 로직을 반영한 최적의 데이터 구조로 활용되는 것이 이상적인 분리 방식이다.
- profile_repository_impl.dart
class ProfileRepositoryImpl implements ProfileRepository {
final ProfileApi profileApi;
/// Entity <-> Model Mapper
final profileMapper = ProfileMapper();
ProfileRepositoryImpl({required this.profileApi});
Future<Result<ProfileCreateResponseEntity>> createMyProfile(
int userId, ProfileCreateRequestEntity entity) async {
try {
/// ProfileCreateResponseEntity -> ProfileCreateRequestModel 로 변환 후 생성 요청
final result = await profileApi.createMyProfile(
profileMapper.mapProfileEntityToRequestModel(entity));
/// userId, ProfileCreateResponseModel -> ProfileCreateResponseEntity 로 변환 후 리턴
return Result.success(
profileMapper.personalProfileResponseToEntity(userId, result));
} catch (error) {
return Result.failure(NetworkExceptions.getErrorMessage(
NetworkExceptions.getDioException(error)));
}
}- profile_api.dart
class ProfileApi {
final DioClient dioClient;
final DioClientV2 dioClientV2;
ProfileApi({required this.dioClient, required this.dioClientV2});
/// 사용자 프로필 생성
Future<PersonalProfileResponseModel> createMyProfile(
PersonalProfileCreateRequestModel model) async {
try {
final response = await dioClientV2.post(profileUrl, data: model.toJson());
return PersonalProfileResponseModel.fromJson(response);
} catch (error) {
CustomLogger.logger.e('$TAG createProfileRequest() => $error');
throw NetworkExceptions.getDioException(error);
}
}
}Trade-off
Entity를 Request / Response 와 1:1 대응으로 설계한 뒤 서비스를 운영을 했고 몸소 체감한 장단점은 다음과 같았다.
- Pros
- API 기능 별로 필요한 Data Structure를 만듦.
- 유지보수에 용이하다
- Cons
- API 기능 별로 필요한 Data Structure를 만듦.
- 유지보수가 불편하다(서비스 규모가 클수록(API 개수가 많아질수록) 그에 따른 Entity 도 증가)
- Entity 별로 중복된 데이터 필드가 발생한다.
- Presentation Layer 가 Domain Layer의 Entity 에 너무 의존적이다.
우선 장점을 먼저 설명하자면, API에 따라 필요한 Request, Response에 대응하는 Entity를 만들기 때문에, 각 기능에서 필요한 데이터 구조를 명확하게 정의할 수 있다는 점에서 직관적이었다. 위의 프로필 생성 과정에서 보여줬던 4개의 화면을 예로 든다면, 각 화면에서 요구하는 데이터를 별도의 Entity를 통해 적절히 수집할 수 있다. 이를 통해 각 API의 역할이 명확해지고, 특정 기능에 맞춘 최적화된 데이터 구조를 설계할 수 있다.
또한, 각 API의 요청과 응답을 엄격하게 Entity에 매핑함으로써 타입 안정성이 강화된다. API 스펙이 변경될 경우, 변경된 부분을 Entity 레벨에서 바로 감지할 수 있으며, 이를 통해 코드 내에서 데이터 구조의 일관성을 유지할 수 있다. 이는 유지보수의 용이성을 높이는 요소로 작용하며, 특히 개발자가 API의 요청/응답 구조를 빠르게 파악할 수 있도록 도와준다.
추가적으로, Entity가 특정 API 기능과 1:1로 매칭되기 때문에, 서비스 개발 초기 단계에서는 구조를 빠르게 잡고 확장하기 용이하다고 판단하였다. API의 응답 구조와 동일한 형태로 Entity를 구성하면, 변환 과정 없이 바로 데이터를 사용할 수 있어 직관적이며, DTO 또는 별도의 변환 과정 없이도 효율적인 데이터 매핑이 가능하다.
결론적으로, API에 맞춰 Entity를 설계하는 방식은 개별 기능에 필요한 데이터를 정확하게 정의하고, 코드의 가독성과 유지보수성을 높이며, 초기 개발 속도를 높이는 측면에서 유리한 접근 방식이라고 할 수 있다.
그러나 역설적으로 위에서 언급했던 장점이 그대로 단점으로 적용이 되었다.
- API 기능 별로 필요한 Data Structure를 만듦
- 유지보수가 불편하다(서비스 규모가 클수록(API 개수가 많아질수록) 그에 따른 Entity 도 증가)
API가 증가함에 따라 이에 대응하는 Entity도 함께 증가하면서 유지보수의 어려움이 발생했다. 새로운 API가 추가될 때마다 새로운 Entity를 만들어야 하며, 기존 API가 변경되면 관련된 모든 Entity를 수정해야 하는 경우도 많아졌다. 또한, API 간의 데이터 흐름을 추적하기 어려워지면서, 특정 데이터를 어디서 어떻게 변환하고 있는지 파악하는 데 시간이 많이 소요되었다. 이로 인해 생산성이 저하되었으며, Entity 변경 사항이 여러 API에 걸쳐 있을 경우, 하나의 수정이 예상치 못한 버그를 유발하는 경우도 발생했다.
- Entity 별로 중복된 데이터 필드가 발생한다.
각 API 기능에 맞춰 Entity를 구성하다 보니, 특정 데이터 필드가 여러 Entity에서 반복적으로 사용되는 경우가 많았다. 예를 들어 ProfileCreateRequestEntity, ProfileUpdateRequestEntity 등 유사한 객체들이 존재할 경우, 이들 사이에서 id, nickname 등의 필드가 중복될 수밖에 없었다. 이러한 중복 필드를 이용한 비즈니스 로직을 Entity 에 만들었을 때, ProfileCreateRequestEntity, ProfileUpdateRequestEntity 두 Entity 에 마찬가지로 동일한 로직을 구현해야 한다는 점이 불편하고, 유지보수 시 일관성을 유지하기 어렵게 만들었으며 한 필드를 변경할 경우 모든 관련 Entity에서 해당 변경을 반영해야 하는 번거로움이 발생했다. 결과적으로, 데이터의 중복이 코드의 복잡성을 증가시키고, 유지보수 비용을 상승시키는 요인이 되었다.
- Presentation Layer 가 Domain Layer의 Entity 에 너무 의존적이다.
API의 요청 및 응답에 따라 Entity를 설계하다 보니, Presentation Layer에서 직접 Domain Layer의 Entity를 참조하는 경우가 많아졌다. 이는 Presentation Layer가 도메인 로직에 대한 강한 결합도를 가지게 만들었으며, UI의 변경이 Domain Layer의 Entity에도 영향을 미치는 문제를 초래했다. 예를 들어, UI에서 특정 필드가 필요 없거나 다르게 가공되어야 하는 경우에도, 기존 Entity를 직접 사용하면 변경이 어려워지고, 필요 이상으로 많은 데이터를 포함하는 객체를 전달해야 하는 비효율이 발생했다.
특히, API 응답을 기준으로 Entity를 설계하다 보니, UI가 API의 구조에 의존하는 형태가 되어 Presentation Layer와 Domain Layer 간의 분리가 어려워졌다. 결과적으로, API 스펙이 변경될 경우 UI까지 영향을 받는 구조가 형성되었으며, 도메인 로직의 변경이 UI 로직에도 불필요한 영향을 미치는 경우가 발생했다. 이는 클린 아키텍처의 원칙(레이어 간의 분리)에도 위배되는 설계 방식이 되어버렸다.
결론
Entity를 API와 1:1로 대응하여 설계하는 방식은 초기 개발 속도와 API별 최적화된 데이터 구조를 보장하는 측면에서 장점이 있지만, 서비스 규모가 커질수록 유지보수성이 떨어지고 코드 중복이 증가하는 문제가 발생했다. 또한, Presentation Layer와 Domain Layer의 결합도가 높아지는 현상이 나타나면서, 클린 아키텍처의 원칙을 유지하기 어려워지는 부작용도 있었다. 우선 해당 설계 방식을 적용할 시기에 운영하고 있는 서비스의 규모가 꽤 컸었고(화면이 약 80개, API 는 약 100개 정도) 이에 따라 Entity 도 약 150개가 넘어가는 상황이었어서 추가 기획이 들어와 기존의 기능을 변경해야 할 때 유지보수가 매우 힘들었었다. 따라서 새로운 기능 개발에 초점을 맞추기 보다는 기존의 서비스를 잘 운영하면서 유지보수에 용이한 아키텍처를 설계해보자는 생각으로, 위의 언급했던 단점을 보완할 수 있는 방안을 모색해보았고 두 번째 겪었던 시행착오에 대한 얘기는 다음 게시글에서 서술해보려고 한다.
