지난 게시글에 이어 이번에는 두번째로 겪었던 시행착오에 대해 다뤄보고자 한다. Entity와 Model을 1:1 대응하여 설계했던 방법론에서 되려 유지보수가 어렵고 새로운 기능이 추가되거나 기존의 기능을 변경할 때 생산성이 더 저해되는 한계점을 착안하여 이번에는 Entity 와 Model을 1:1 대응하지 않고 좀 더 명확한 역할 분리를 하였다. 이번 게시글에서는 어떻게 Entity를 설계하였고 이에 대한 장단점이 무엇이고 어떻게 보완했는지에 다뤄보겠다.
Keyword 및 중점 내용
- 도메인 중심의 Entity 설계
- 가변 객체 & 불변 객체
- Param
두번째 시행착오: 도메인 중심의 Entity 설계
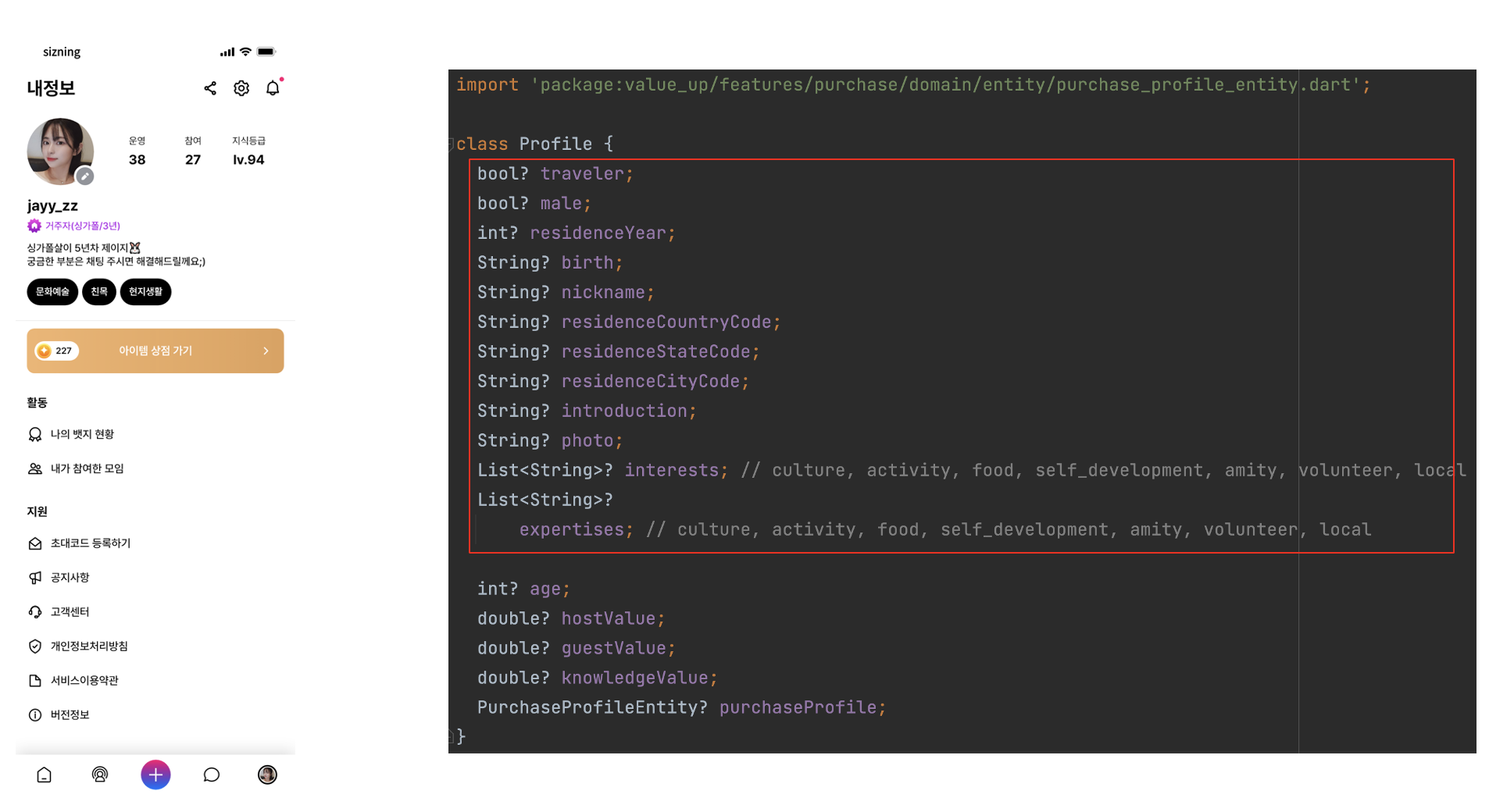
위의 사진은 프로필 화면이다. 오른쪽의 사진을 주목해보면 빨간색 칠한 박스부분이 프로필을 생성했을 당시에 수집했던 데이터들이고, 나머지 데이터들을 포함하여 '프로필' 도메인에서 사용하는 데이터 전부를 담은 내용이다. 즉, Model 과 Entity 를 1:1 대응하여 사용했던 설계방식을 '도메인' 별로 나눠 Entity 를 나누고, 해당 Entity 에는 해당 도메인에서 사용하는 데이터들을 모두 담고 있는 방식으로 설계하였다. 이렇게 설계했을 때 첫번째 시행착오에서 보완할 수 있는 점은 다음과 같다.
- API 별로 Entity 를 생성하지 않아도 되므로 생성해야 하는 Entity 의 수가 현저히 낮아짐.
- 도메인별로 역할이 분리되어 유지보수가 용이함
- 비즈니스 로직에서 데이터의 일관성을 유지할 수 있음
- 각 Entity가 독립적으로 동작할 수 있음
기존 방식에서는 API 요청마다 새로운 Entity를 생성해야 했기 때문에, API가 추가되거나 변경될 때마다 관련된 Entity들도 같이 수정해야 하는 문제가 있었다. 하지만 도메인 단위로 Entity를 나누면, 해당 도메인에서 다루는 데이터가 명확해지고, 새로운 기능이 추가되거나 기존 기능을 변경할 때에도 관련된 Entity를 수정할 필요가 줄어들어 유지보수가 훨씬 용이해지는 장점이 있다. 또한 도메인 중심으로 Entity를 나누면, 해당 도메인에서 사용하는 데이터만 포함하게 되므로 데이터 일관성을 유지하면서도 불필요한 의존성을 줄일 수 있다.
마지막으로 해당 이유가 도메인 중심 설계로 변경하게 된 계기였는데, 아무래도 API별로 Entity를 만들게 되면 서로 다른 API에서 유사한 데이터를 반환할 경우 비슷한 구조의 Entity가 여러 개 생기게 되고, 이로 인해 중복된 코드가 많아지는 문제가 발생하였다. 반면 도메인 기반으로 Entity를 정의하면, 각 Entity가 독립적인 역할을 가지면서도 필요한 경우 공통 속성을 공유할 수 있어 중복을 줄일 수 있는 효과가 있다.
가변 객체 설계 방식의 문제점
위의 Entity 를 보면 우선 모든 필드가 nullable 이다. 이렇게 설계한 이유는 첫번째 시행착오 게시글에서 다뤘던 프로필 생성 예시로 설명해보겠다.
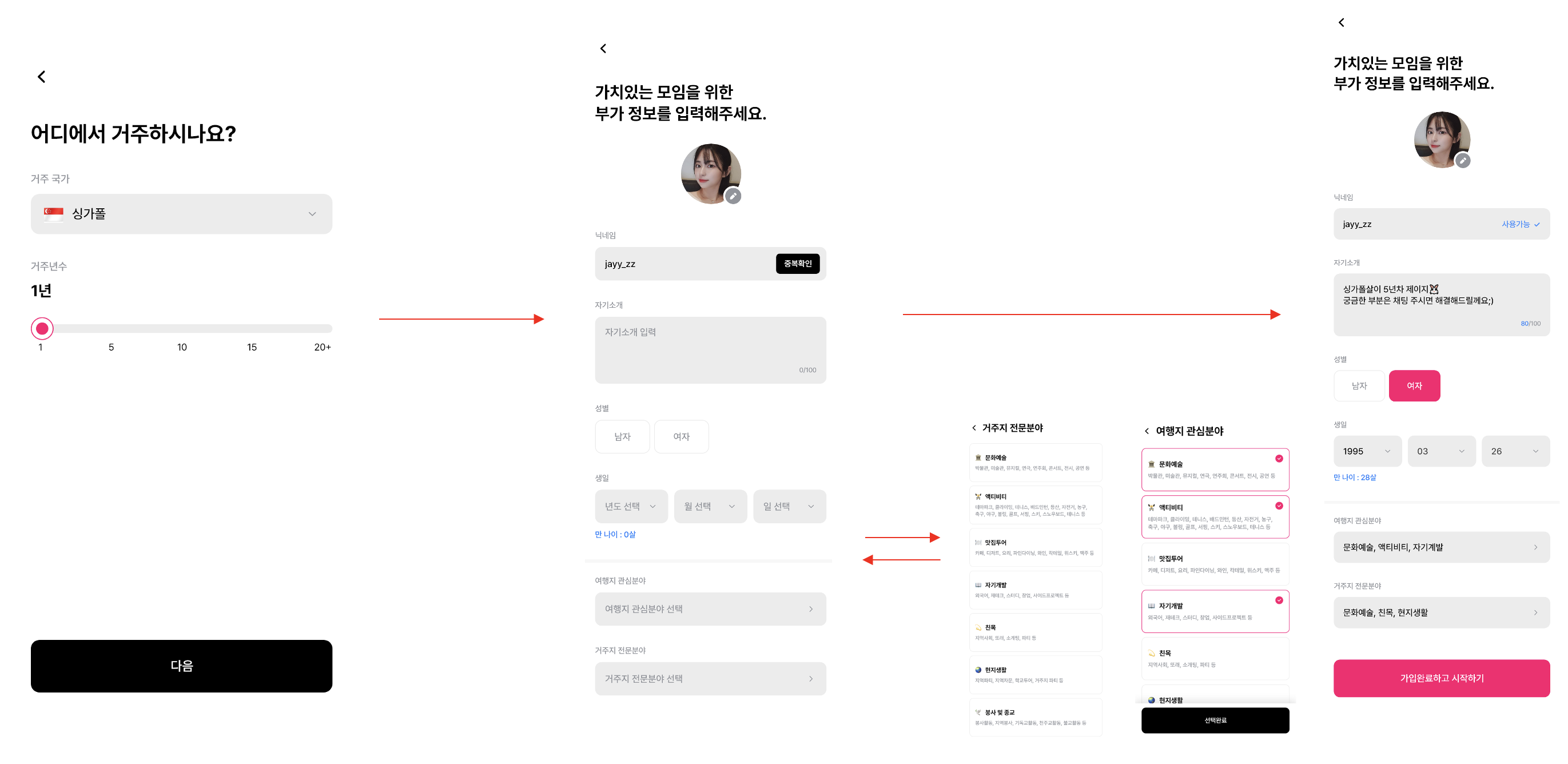
프로필 생성 과정에서 입력 받아야 하는 데이터는 총 13개로, 여러가지 형태의 UI를 통해 입력을 받는다. UI 에서 데이터를 수집해 해당 Entity 에 수집한 데이터를 할당해주게 되는데, 이 때 불변 객체를 만들어 사용하게 되면 UI 입력의 수정이 생길 때마다 매번 Entity 의 객체를 복사하여 값을 업데이트 시켜줘야 하는 부담이 있다. 이에 반해 가변 객체를 사용했을 때는 화면에 해당 Entity 를 import 하기만 하면 UI 업데이트마다 해당 객체를 불러와 값만 바꿔주기만 하면 손쉽게 사용이 가능하다. 예시를 들어보자면 TextField만 보더라도 입력의 변경이 엄청 잦은편인데 이에 따라 객체를 매번 복사하여 업데이트를 해주는 컴퓨팅 비용이 가변 객체를 만들어 사용했을 때보다 부담이 있다고 판단해서 가변 객체를 사용하였다.
그러나 Entity 를 가변 객체로 사용했을 때 문제점은 다소 치명적이었다.
- Thread safe 하지 않다.
- 해당 Entity 를 사용할 경우 매번 필드마다 null 체크가 필요하다.
- API Request 에 사용되는 데이터 필드 수가 Entity 가 가지고 있는 필드 수보다 적기 때문에 화면에서 입력받지 않아도 되는 데이터들에 대해서는 메모리 낭비이다.
가변 객체는 여러 스레드에서 동시에 접근하여 값을 변경할 수 있기 때문에, 멀티스레드 환경에서 데이터 정합성이 깨질 위험이 크다.
void updateProfile(Profile profile) {
// API 응답이 도착하여 프로필 변경
Future.delayed(Duration(milliseconds: 500), () {
profile.nickname = "Sangjin";
print("API 응답에서 닉네임 변경: ${profile.nickname}");
});
// UI에서 사용자가 닉네임을 입력하는 도중
Future.delayed(Duration(seconds: 1), () {
profile.nickname = "Jay";
print("UI에서 닉네임 변경: ${profile.nickname}");
});
}
void main() {
Profile profile = Profile();
updateProfile(profile);
}다음 코드를 예시로 프로그램 시작과 동시에 API 요청을 하고 응답에 따라 UI를 변경하는 첫번째 옵션과 사용자의 입력을 받아 UI를 변경하는 두 번째 옵션이 있다고 가정하자. 첫번째 옵션은 시작한지 500ms 내로 응답이 와서 UI를 변경하고, 두 번째 옵션은 1초 후에 사용자가 업데이트 한다고 할 때, 결과는 다음과 같이 기대할 수 있다.
API 응답에서 닉네임 변경: Sangjin
UI에서 닉네임 변경: Jay그러나 네트워크 특성 상 환경에 따라 API 응답이 언제 도착할지 보장할 수 없기 때문에, 위의 예시 코드처럼 500ms 내로 올 수도 있고, 1000ms 보다 더 오래 걸릴 수 있기 때문에 만일 최종적으로 Jay 로 변경되길 원했지만 Sangjin 으로 변경될 수도 있다. 즉 Race Condition 문제가 발생하여 데이터 정합성이 깨질 가능성이 있다.
두 번째 이유로 null 체크를 매번 할 시 코드의 가독성을 저해하고, 필드 사용 시 field ?? default 값 혹은 if(field != null) 과 같은 처리를 해줘야 해서 번거로운 문제가 있다.
마지막으로는 위의 프로필 생성 과정을 참고하면 해당 화면들에서 입력값을 받아야 하는 필드의 개수는 총 13개지만, Entity에는 불필요한 데이터인 나머지 5개의 필드에 대해서도 동일하게 메모리에 올려야 하니 낭비가 발생하는 문제가 있다.
Param 의 도입
첫번째 시행착오인 Entity <-> Model 1:1 설계 방식을 보완하기 위해 도메인 중심 Entity 설계 방식이 나왔으나, 아직까지 두 방식에서 해결하지 못한 문제점이 있다.
Presentation Layer 가 Domain Layer의 Entity 에 너무 의존적이다.
아직까지 Entity 를 이용하여 UI로부터 수집한 데이터를 저장하고 있는 점에서 Presentation Layer에서 너무 의존적이라는 문제점을 해결하지 못하였다. 따라서 이를 보완하기 위해 Param 을 도입하였다. Param은 쉽게 말하자면 화면 전용 데이터 껍데기 라고 정의하고 싶다. 다시 풀어서 설명하자면, 비즈니스 로직은 없고 UI 로부터 수집한 데이터를 저장 용도로 만든 객체인 것이다. 첫번째 시행착오 게시글에서 설명했었던 비즈니스 로직이 빠져있는 ProfileCreateRequestEntity 라고 생각하면 된다. 화면으로부터는 Param 을 통해 데이터를 저장해서 Domain의 Usecase 함수를 호출할 땐 Entity로 변환하여 사용하면 되므로 더이상 화면이 Entity 에 의존하지 않아도 되는 것이다.
여기까지가 Param 의 개요에 대한 내용이고, 다음 게시글에서 이를 이용해 클린 아키텍처를 어떻게 변형하였는지 설명하도록 하겠다.
