Tigress 가상화 난독화를 적용한 코드에서 Feature를 생성하기 위하여 LLVM Pass를 사용해 보았다.
앞서 포스트에서 분석한 내용을 기반으로 LLVM Pass를 작성하였다. Feature로 삼을 내용은 다음과 같다.
- Dispatch 시작 블록
- Handler 블록
- VM 시작 블록
- VM 영역 종료 Handler
LLVM Pass
LLVM Pass는 LLVM에서 분석과 코드 삽입을 위해 사용하는 모듈이다. 내부에서는 최적화 과정에서 사용하며 코드를 작성하여 직접 필요한 정보를 얻거나 원하는 동작을 수행하는 것이 가능하다.
LLVM Pass는 C++ 언어로 작성하였고, 직접 제작한 여러 제어구조를 가진 대상으로 Pass의 정확성을 검증해 보았다.
또한 찾은 블록에 dummy_function call 명령어를 삽입하여 어셈블리로 컴파일 하여도 탐지가 가능하도록 하였다.
Dispatch
먼저 디스패치 시작 블록을 찾았다. 분석한 결과 디스패치 시작 블록을 중심으로 분석하는 것이 분석에 용이하였다. 디스패치는 앞선 포스트에서 설명한 듯이 가장 많은 진출점을 가지고 있는 특징이 있다.
private:
/// 가장 많은 후행자를 가진 블록을 dispatcher로 식별
BasicBlock* findDispatcher(Function &F) {
const BasicBlock *candidate = nullptr;
unsigned maxSuccs = 0;
for (BasicBlock &BB : F) {
const Instruction *terminator = BB.getTerminator();
unsigned numSuccessors = terminator ? terminator->getNumSuccessors() : 0;
if (numSuccessors > maxSuccs) {
maxSuccs = numSuccessors;
candidate = &BB;
}
}
return const_cast<BasicBlock*>(candidate);
}해당 코드는 디스패치를 찾는 코드다. 함수 내에서 모든 베이직 블록을 순회하며 종려 명령어를 확인한다. 편리하게 getNumSuccessors() 함수를 통해 후행자의 개수를 간편하게 구할 수 있다.
Handler
디스패치에서 분기되는 블록은 핸들러이기 때문에 위에서 찾은 디스패치 블록을 중심으로 후행자 블록들을 순회해 주었다.
std::vector<BasicBlock*> getHandlers(BasicBlock *dispatcher) {
std::vector<BasicBlock*> handlers;
Instruction *terminator = dispatcher->getTerminator();
if (terminator) {
for (unsigned i = 0; i < terminator->getNumSuccessors(); ++i) {
handlers.push_back(terminator->getSuccessor(i));
}
}
errs() << "[*] Found " << handlers.size() << " handler(s)\n\n";
return handlers;
}이렇게 핸들러 블록들을 찾아 주었다.
하지만, 핸들러 블록 중에 switch, 조건 분기 명령어가 존재하는 핸들러가 존재한다.(함수 호출, 분기문) 필자는 해당 블록을 핸들러로 하지 않고 해당 블록에서 분기되는 블록을 핸들러로 간주하였다. 정의하기 나름일 것 같지만 어떠한 동작을 할지 결정하는 부분을 핸들러로 지칭하지 않고 조건에 의해서 실행되는 부분을 핸들러로 보았다.
for (unsigned i = 0; i < SI->getNumSuccessors(); ++i) {
BasicBlock *caseBlock = SI->getSuccessor(i);
Instruction *caseTerminator = caseBlock->getTerminator();
if (caseBlock != dispatcher &&
caseTerminator &&
!hasVMEndPredecessor(caseBlock) &&
!findCallTo(caseBlock, "dummy_function_handler") &&
!findCallTo(caseBlock, "dummy_function_VM_end_handler") &&
hasNonTerminatorInstructions(caseBlock)) {
IRBuilder<> builder(caseTerminator);
builder.CreateCall(handlerFunc);
errs() << "[+] Tagged handler: ";
caseBlock->printAsOperand(errs(), false);
errs() << "\n";
irModified = true;
}
}이 부분이 switch를 처리하는 부분이고,
if (BI->isConditional()) {
// 조건 분기: 핸들러 자체는 태그하지 않고 재귀 탐색
for (unsigned i = 0; i < terminator->getNumSuccessors(); ++i) {
BasicBlock *successor = terminator->getSuccessor(i);
if (successor != dispatcher) {
tagConditionalBranchSuccessors(successor, dispatcher, handlerFunc,
processedBlocks, irModified, 0);
}
}
} else {
// 단일 분기: 핸들러 자체에 태그
if (!hasVMEndPredecessor(handler) && hasNonTerminatorInstructions(handler)) {
IRBuilder<> builder(terminator);
builder.CreateCall(handlerFunc);
errs() << "[+] Tagged handler: ";
handler->printAsOperand(errs(), false);
errs() << "\n";
irModified = true;
}
}
}이 부분이 조건분기를 처리하는 부분이다.
VM Start
가상화 영역의 시작은 디스패치 블록의 직전 블록에서 시작된다. 해당 부분에서는 가상화 영역에서 사용할 array, VPC 등의 값을 세팅하게 된다.
void tagVMStart(Function &F, BasicBlock *dispatcher,
FunctionCallee &startFunc, bool &irModified) {
errs() << "--- Tagging VM Start ---\n";
for (BasicBlock &BB : F) {
Instruction *terminator = BB.getTerminator();
if (terminator && terminator->getNumSuccessors() > 0) {
if (terminator->getSuccessor(0) == dispatcher) {
if (!findCallTo(&BB, "dummy_function_VM_start")) {
IRBuilder<> builder(terminator);
builder.CreateCall(startFunc);
errs() << "[+] Tagged VM_start at BB: ";
BB.printAsOperand(errs(), false);
errs() << "\n\n";
irModified = true;
return;
}
}
}
}
errs() << "[-] No VM_start location found\n\n";
}디스패치 블록을 찾은 다음에 실행되는 코드로, 함수 내 베이직 블록을 순회하며 후행자 블록이 dispatch인지 확인한다. findCallTo 명령어는 dummy_function call을 추가할 때, 중복하여 추가되지 않도록 확인하는 코드다.
VM End Handler
마지막으로 가상화 영역을 종료하는 핸들러인데, 이 부분이 가장 어려웠으며, 코드 또한 가장 길다.
BasicBlock* findUniqueTargetHandler(std::map<BasicBlock*, std::set<BasicBlock*>> &handlerTargets,
BasicBlock *dispatcher,
FunctionCallee &handlerFunc,
FunctionCallee &endHandlerFunc,
bool &irModified) {
std::map<std::set<BasicBlock*>, std::vector<BasicBlock*>> targetGroups;
for (auto &[handler, targets] : handlerTargets) {
targetGroups[targets].push_back(handler);
}
for (auto &[targets, handlersWithSameTargets] : targetGroups) {
if (handlersWithSameTargets.size() == 1) {
BasicBlock *uniqueHandler = handlersWithSameTargets[0];
Instruction *terminator = uniqueHandler->getTerminator();
// dispatcher로 분기하는지 확인
bool branchesToDispatcher = false;
if (terminator) {
for (unsigned i = 0; i < terminator->getNumSuccessors(); ++i) {
if (terminator->getSuccessor(i) == dispatcher) {
branchesToDispatcher = true;
break;
}
}
}
// VM_end_handler 조건 확인
if (!branchesToDispatcher &&
!findCallTo(uniqueHandler, "dummy_function_VM_end_handler") &&
!isa<SwitchInst>(terminator) &&
terminator && isa<BranchInst>(terminator) &&
!cast<BranchInst>(terminator)->isConditional()) {
// 기존 handler 태그 제거 후 end_handler 태그 삽입
if (CallInst *existingHandler = findCallTo(uniqueHandler, "dummy_function_handler")) {
existingHandler->eraseFromParent();
}
IRBuilder<> builder(terminator);
builder.CreateCall(endHandlerFunc);
// errs() << "[+] Tagged VM_end_handler\n";
irModified = true;
return uniqueHandler;
}
}
}
return nullptr;
}targetGroups라는 자료구조가 있다. 해당 자료구조에 각 핸들러의 후행자 블록을 저장하고 순회하며 핸들러의 후행자 블록이 디스패치가 아닌 블록을 찾아 종료 핸들러로 지정한다.
Result
이렇게 작성한 Pass를 가상화 난독화 적용한 코드에 실행하게 되면
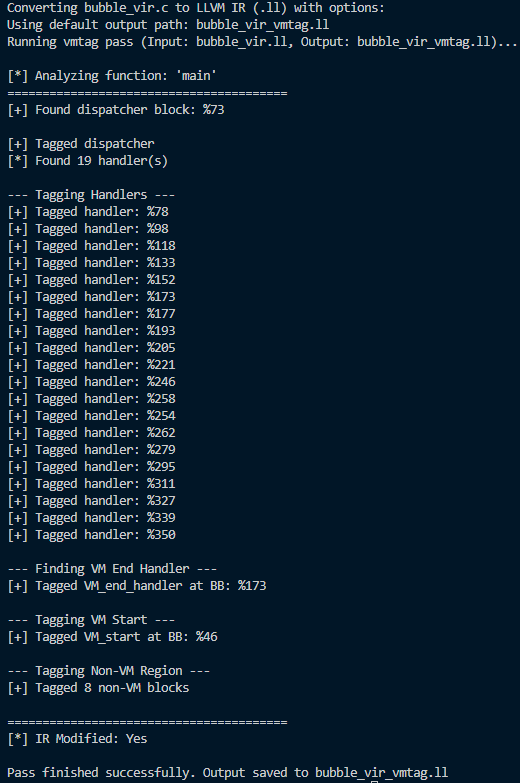
이러한 결과가 나온다. 디스패치 블록은 73번이고 19개의 핸들러가 존재하는 것을 확인할 수 있다. 173번 블록이 VM을 종료하는 핸들러, 46번은 VM 시작 블록 또한 코드로 설명하지 않았지만 가상화 되지 않은 코드들도 태깅해 주었다.
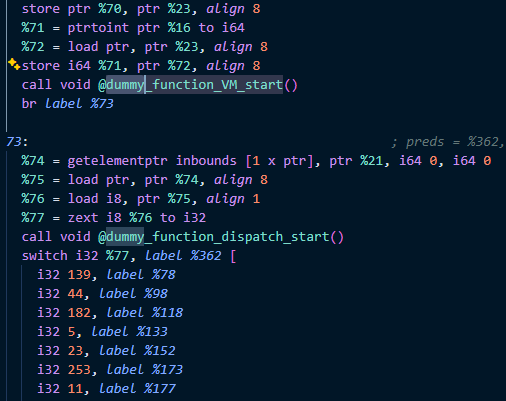
코드 내부에 이렇게 더미 함수 호출코드를 삽입하여 해당 블록의 역할을 탐지할 수 있도록 하였고, Pass가 정상적으로 동작하는 것을 확인하였다.
위 사진은 bubble sort를 대상으로 하였고, factorial, fibonacci, function call 하는 코드들을 대상으로 확인한 결과 모두 정상적으로 동작하는 것을 확인했다.
Optmize
위의 정상적으로 탐지한 케이스들은 모두 LLVM IR로 컴파일 할 때, 최적화 옵션 O0을 적용하여 컴파일 하였다. 하지만 최적화 옵션 O3를 적용하게 되면 Pass 실행 결과에 오류가 발생하게 된다.
VM Start의 경우 main 함수의 에필로그 부분과 VM Start 블록이 합쳐지게 되며, Pass를 탐지한 부분이 main+VM Start가 되게 된다. 이러한 문제는 Pass 내부에서 베이직 블록을 분리한느 방법으로 해결 된다.
두 번째 문제는 가상화 영역을 종료하는 블록의 후행자 블록은 단순 분기로 표현되는 경우가 있다.
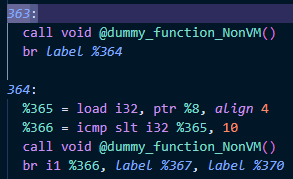
위 사진은 VM end 핸들러에서 분기된 블록인데 더미 함수 호출 명령어를 제외하면 단순 분기만 하는 블록이다. 이는 최적화가 적용되면 사라지게 되며 364번 블록이 VM end 핸들러와 합쳐지는 경우도 발생하게 된다. 그렇게 되면 VM end 핸들러와 original 코드가 구분되지 않게 된다.
이 또한 Pass 내부에서 코드를 분리하여 구분하는 방법을 통해 해결할 수 있다.
