Github API
이번주는 지난주와 이어서 Github API 를 이용하여 switch data set 을 생성하는 코드를 작성하였다.
참조 : https://github.com/rsain/GitHub-Crawler/blob/master/getDataFromGitHub.py
해당 코드를 참조하여 코드를 개발하였고, 쿼리를 이용하여 가져오는 데이터양을 많이 늘릴 수 있었다.
전체 코드는 너무 길어 올리지는 않고 링크만 올렸다.
https://github.com/sangjun19/Deobfuscator/tree/switch_generator
먼저 지난번 방법의 문제는 한 번의 요청으로 가져올 수 있는 데이터 양이 1,000 개로 제한적이 었고, 그 마저도 전부 가져오지 못하는 문제가 있었다. 아래와 같은 이유가 있을 수 있다.
- API 속도 제한
- private 인 경우
- 파일 크기 제한
주 원인은 API 속도 제한이라 생각하였다. 요청간의 시간 간격이 필요하다 생각하였다.
먼저 쿼리의 양을 많이 늘려 데이터 요청을 여러번 할 수 있도록 하였다.
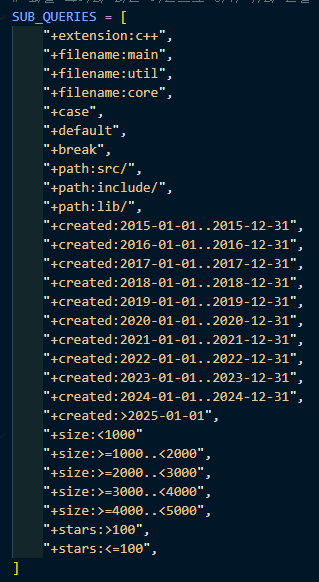
쿼리를 파일의 이름이나, 경로, 생성 날짜, 크기, star 개수 등의 세부 쿼리를 만들어 여러번의 요청을 하도록 해 주었다.
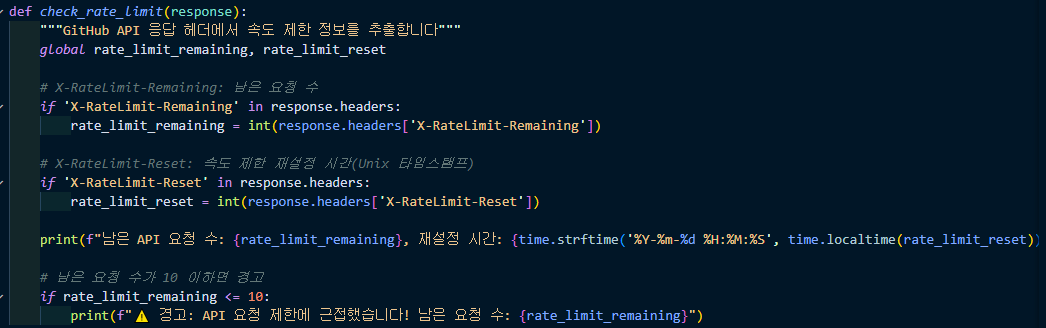
남은 요청 수와 속도를 계속 측정해 주었다. 기번적으로 분당 60 개로 설정하여 요청하였다.
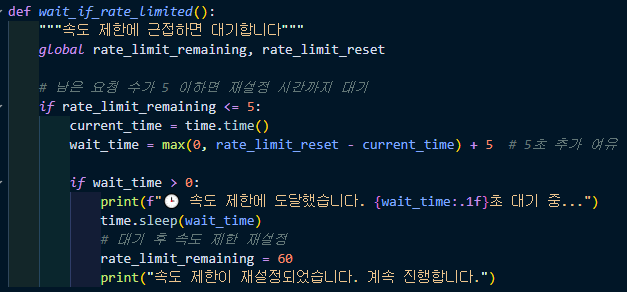
이 부분은 위에서 측정한 값으로 남은 요청수가 5개 이하면 속도 제한을 걸어주는 코드이다.

해당 코드가 실질적으로 코드를 가져오는 부분이다. 이 부분에서 switch 문이 포함돼 있는지 확인하고 파일에 쓰게 된다.
예외가 발생할 경우 exponential_backoff 함수를 이용해 일정 시간을 두고 재시도를 하게 된다.
일부 repository 의 경우 가져올 수 있는 권한이 없다고 뜨는 것을 확인할 수 있었다.
이렇게 C, C++ 두 언어의 코드를 가져왔고

C 는 8817개, C++ 는 7492개 가져올 수 있었다.
conclusion
- 쿼리를 9개에서 16개 까지 증가시켜 보았지만 생각보다 데이터 양이 많이 늘어나지는 않았다.
- 생각보다 403 error 가 뜨는 경우가 많았고, 이전 코드에서는 종료되는 문제를 개선해서 계속해서 가져올 수 있었다.
- 데이터 재요청, 데이터 요청시간 조절등 동작으로 가져오는데 5~6 시간 정도 소요가 되었다.
- 코드를 실행할 때마다 데이터를 가져오는 양이 계속 달라진다.
- 총 데이터의 양은 26189 개이고, C, C++ 코드만 생각하면 17000 개 정도 생성을 하였다.
Todo
- 생성한 코드를 여러 옵션을 이용하여 자동화 난독화 하는 방법을 생각해 봐야 할 거 같다.
- 데이터의 크기가 매우 큰 경우도 있어서 feature 를 뽑거나, 데이터의 크기를 줄이는 방법을 고안할 필요가 있을 것 같다.
- LLM 사용법에 대하여 공부 해야한다.
