실험시 주의사항들
-
H module과 L module이 같나?
-
같으면 TRM
- 세팅: .sh 에서, arch=trm
// .sh 에서, arch=trm으로 하더라도, arch.H_layers=T로 하면, HRM과 같이 됨. - 결과: all_config.yaml 에서, H_layers: 0
- 세팅: .sh 에서, arch=trm
-
다르면 HRM
- 세팅: .sh 에서, arch=hrm
- 결과: all_config.yaml 에서, H_layers: 4
-
-
1-step gradient 유무?
-
없으면, TRM
- 세팅:
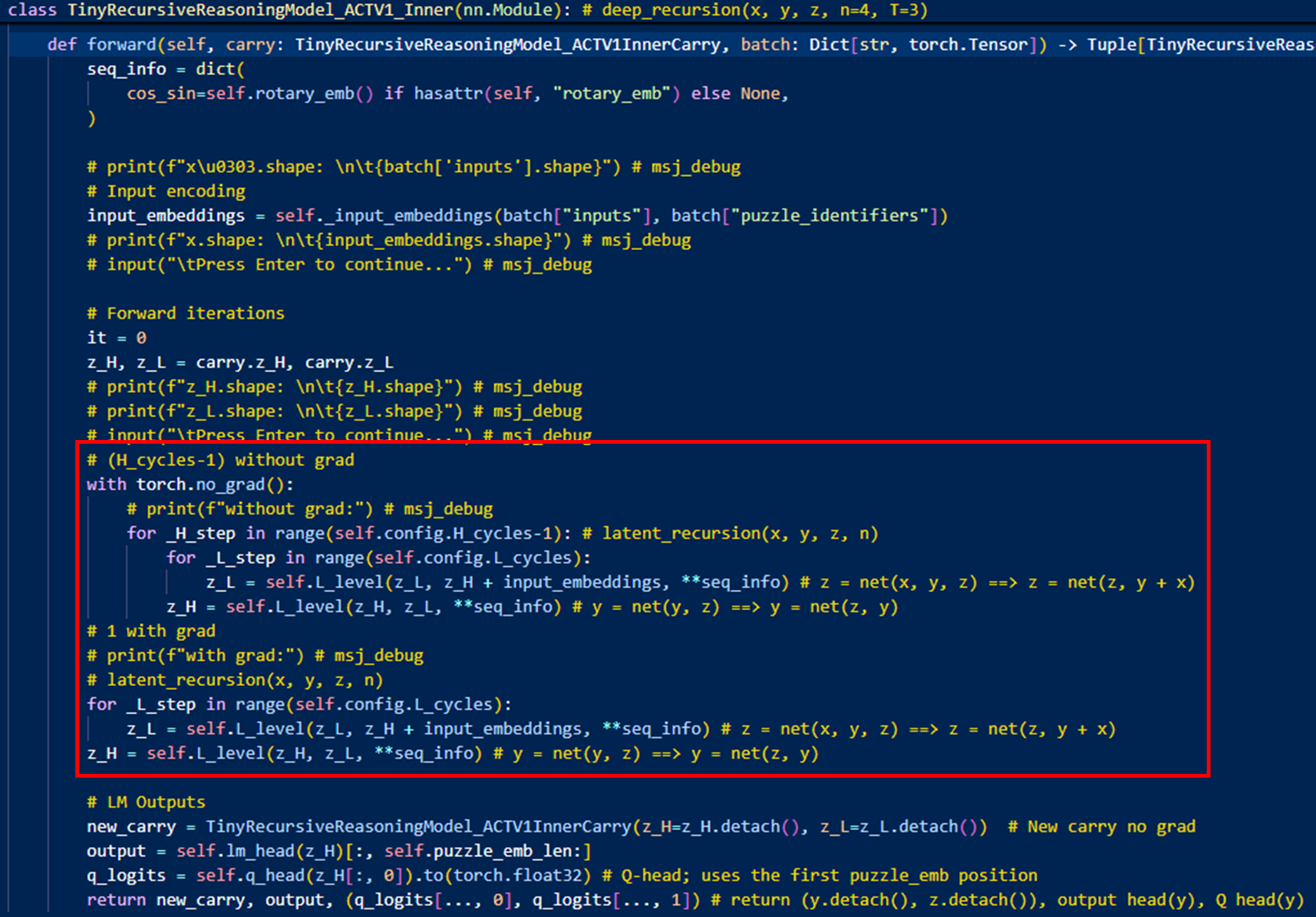
- 세팅:
-
있으면, HRM
- 세팅:
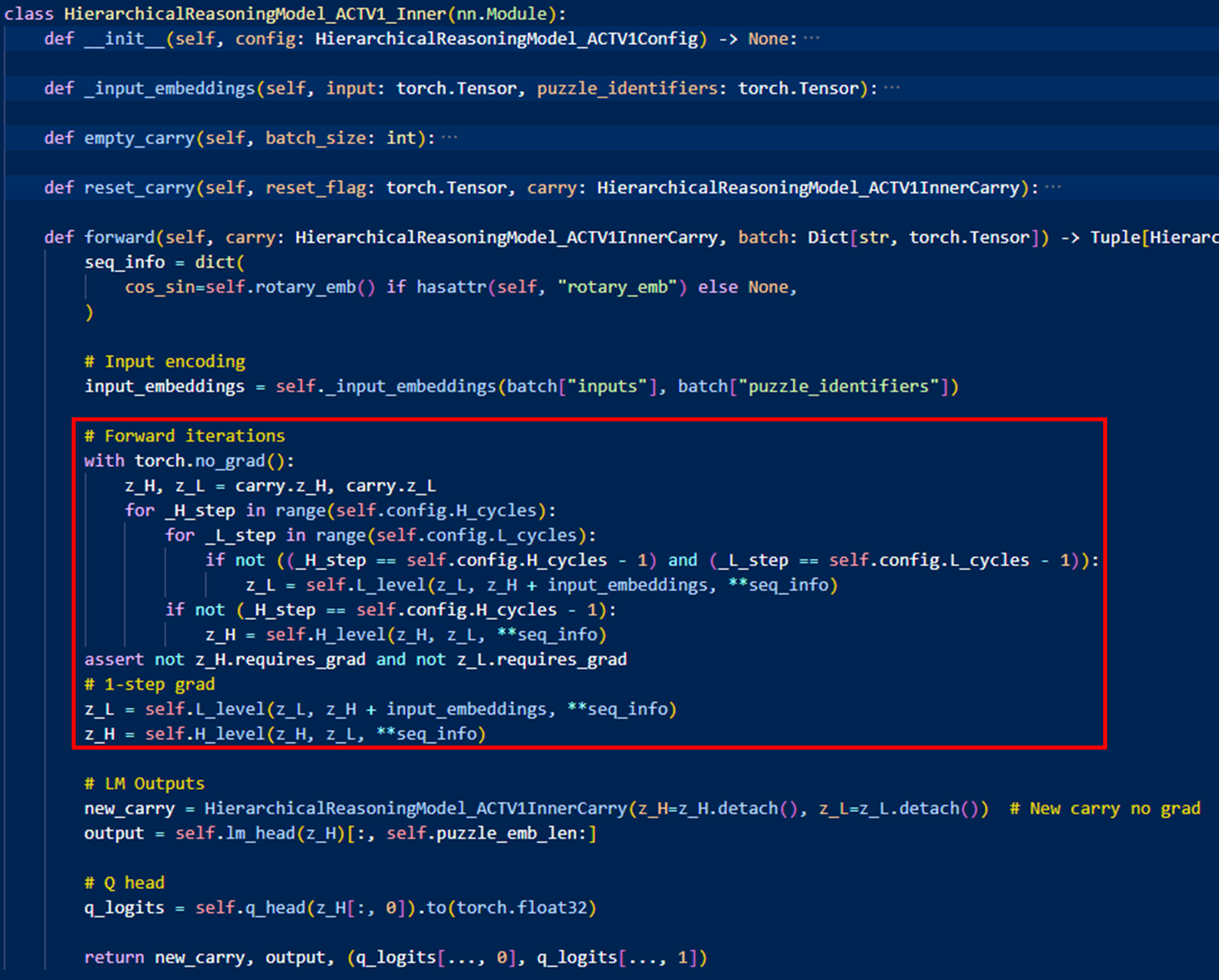
- 세팅:
-
-
ACT에서 continue_loss가 있나?
- 없으면, TRM
- 세팅: .sh 에서, arch=trm
- 결과: all_config.yaml 에서, no_ACT_continue: True
- 있으면, HRM
- 세팅: .sh 에서, arch=hrm
- 결과: all_config.yaml 에서, no_ACT_continue 항목 X
- 없으면, TRM
-
Recurrent 횟수
- T = 3, n = 6 TRM
- 세팅: .sh 에서, arch.H_cycles=3 arch.L_cycles=6
- 결과: all_config.yaml 에서, H_layers: 3, H_layers: 6
- T = 2, n = 2 HRM
- 세팅: .sh 에서, arch.H_cycles=2 arch.L_cycles=2
// TRM 논문에서는 T=3, n=3이 optimal이라고 함. - 결과: all_config.yaml 에서, H_layers: 2, H_layers: 2
- 세팅: .sh 에서, arch.H_cycles=2 arch.L_cycles=2
- T = 3, n = 6 TRM
-
Supervision 횟수
- 인가?
- 세팅: .sh 에서, 별다른 세팅 X
- 결과: all_config.yaml 에서, halt_max_steps: 16
- 인가?
-
Transformer block 수
- 2, TRM
- 세팅: .sh 에서, arch.L_layers=2
- 결과: all_config.yaml 에서, H_layers: 0, L_layers: 2
- 4, HRM
- 세팅: .sh 에서, arch.H_layers=4, arch.L_layers=4
- 결과: all_config.yaml 에서, H_layers: 4, L_layers: 4
- 2, TRM
-
Attention-free?
- O
- 세팅: .sh 에서, 별다른 세팅 X
- 결과: all_config.yaml 에서, mlp_t: True
- X
- 세팅: .sh 에서, 별다른 세팅 X
- 결과: all_config.yaml 에서, mlp_t: False
- O
-
EMA?
-
O
- 세팅: .sh 에서, ema=True
- 결과: all_config.yaml 에서, ema: true
-
X
- 세팅: .sh 에서, 별다른 세팅 X
- 결과: all_config.yaml 에서, ema: false
-
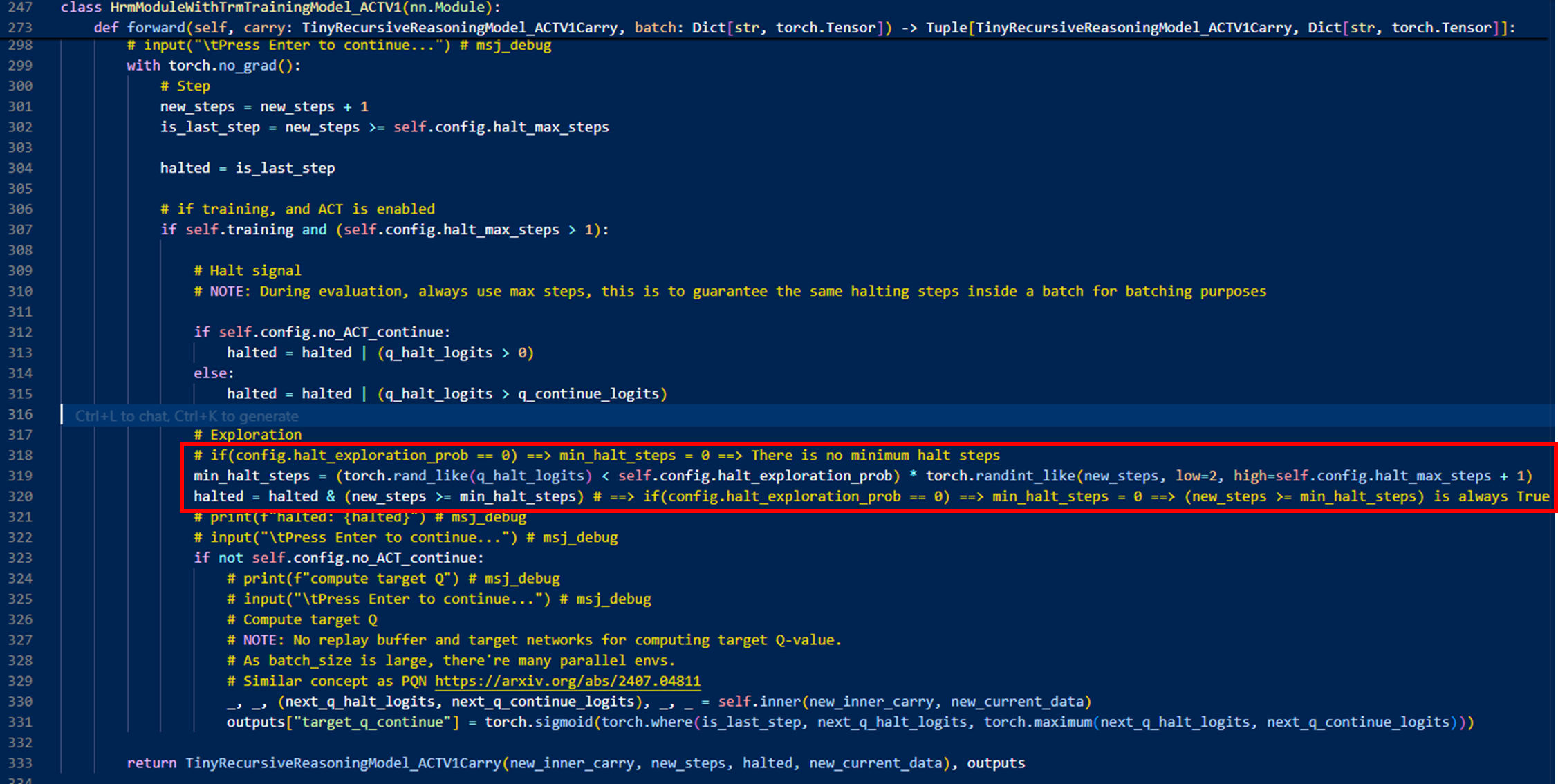
halt_exploration_prob?
⇒ ACT에서 최소 세그먼트 수()(min_halt_steps)는 확률적으로 결정하는데, 그 확률이 halt_exploration_prob임
// sudoku4x4에서, halt_exploration_prob이 0인데,
// 그 뜻은 min_halt_steps가 0이라는 뜻이고,
// halt는 is_last_step 이거나, q_halt_logits > 0 일 때만 한다는 뜻.
Model size
Model size에 관여하는 부분은 3가지가 있다.
1. H_layers
2. L_layers
3. Transformer Block(layer)의 크기
Transformer Block 하나의 크기는
 로 총 3,407,872개
로 총 3,407,872개
-
HRM은
⇒ 대략, -
TRM은
⇒ 대략,
Emulated Depth
Default로
-
HRM은
⇒ -
TRM 논문에서 HRM 이 optimal이라고함
⇒ -
TRM은
⇒
실험
1. H module, L module의 size를 다르게 한다면, 어떤 것의 size가 큰 것이 좋을까?
⇒ H module, L module의 size를 다르게 한다는 뜻은, model 구조가 HRM을 따라간다는 뜻
즉, .
HRM_module_with_TRM_training 실험
로 실험임.
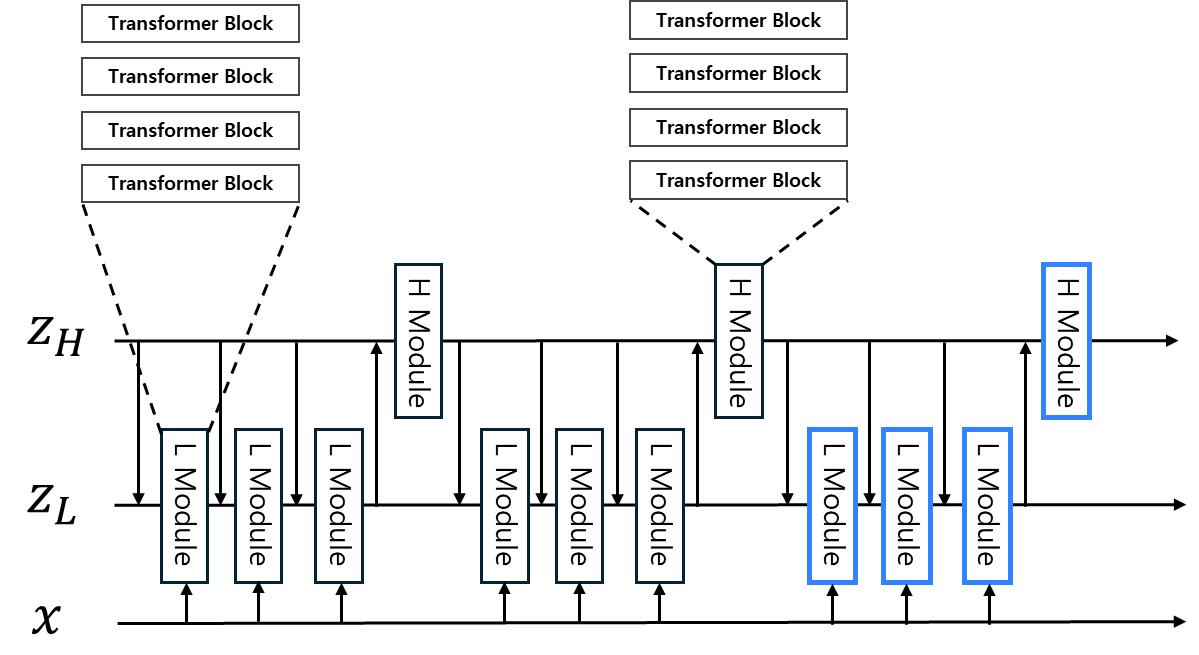
HRM_module_with_TRM_training.sh
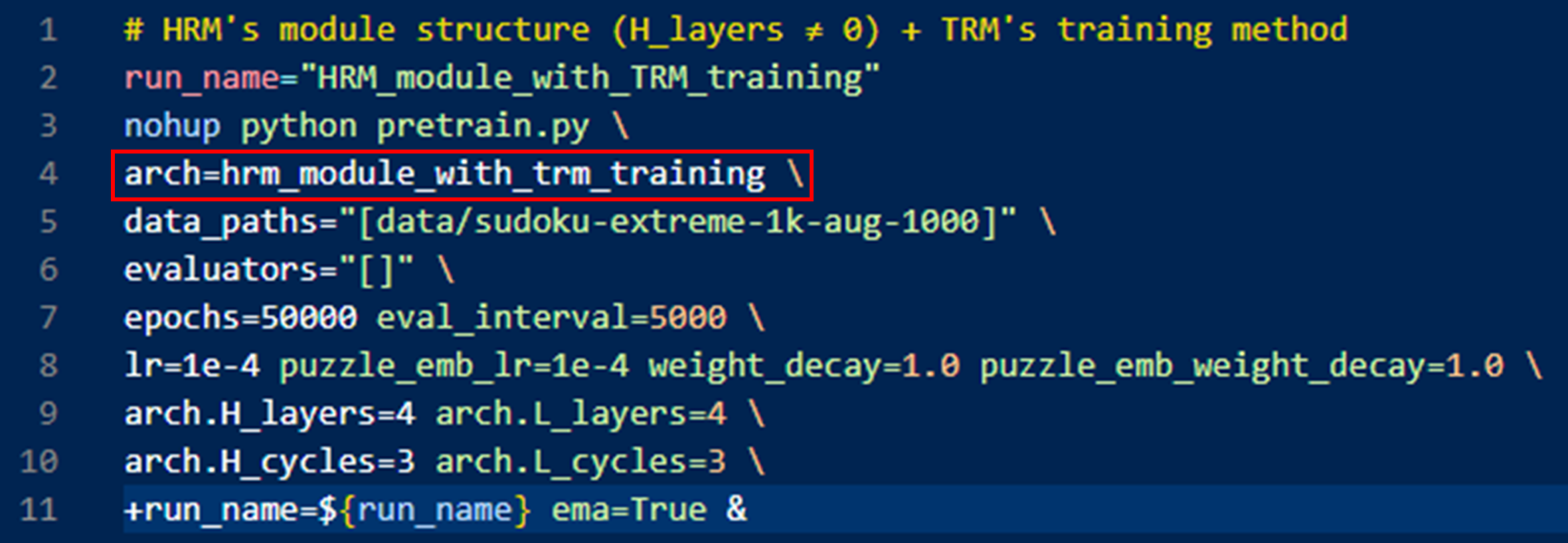
arch로 사용하는 hrm_module_with_trm_training은 다음과 같이 작성함 (config/arch/hrm_module_with_trm_training.yaml)
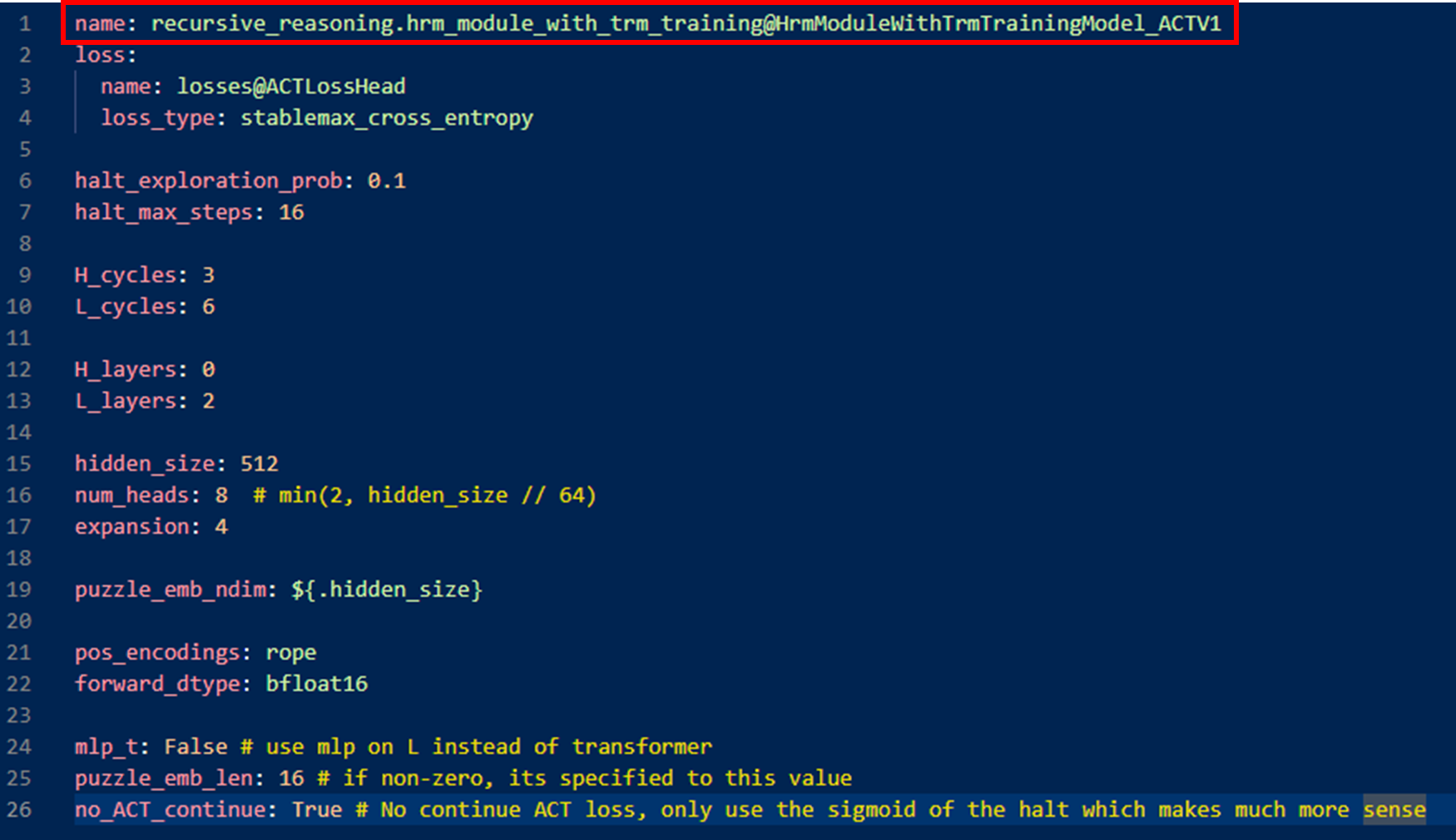
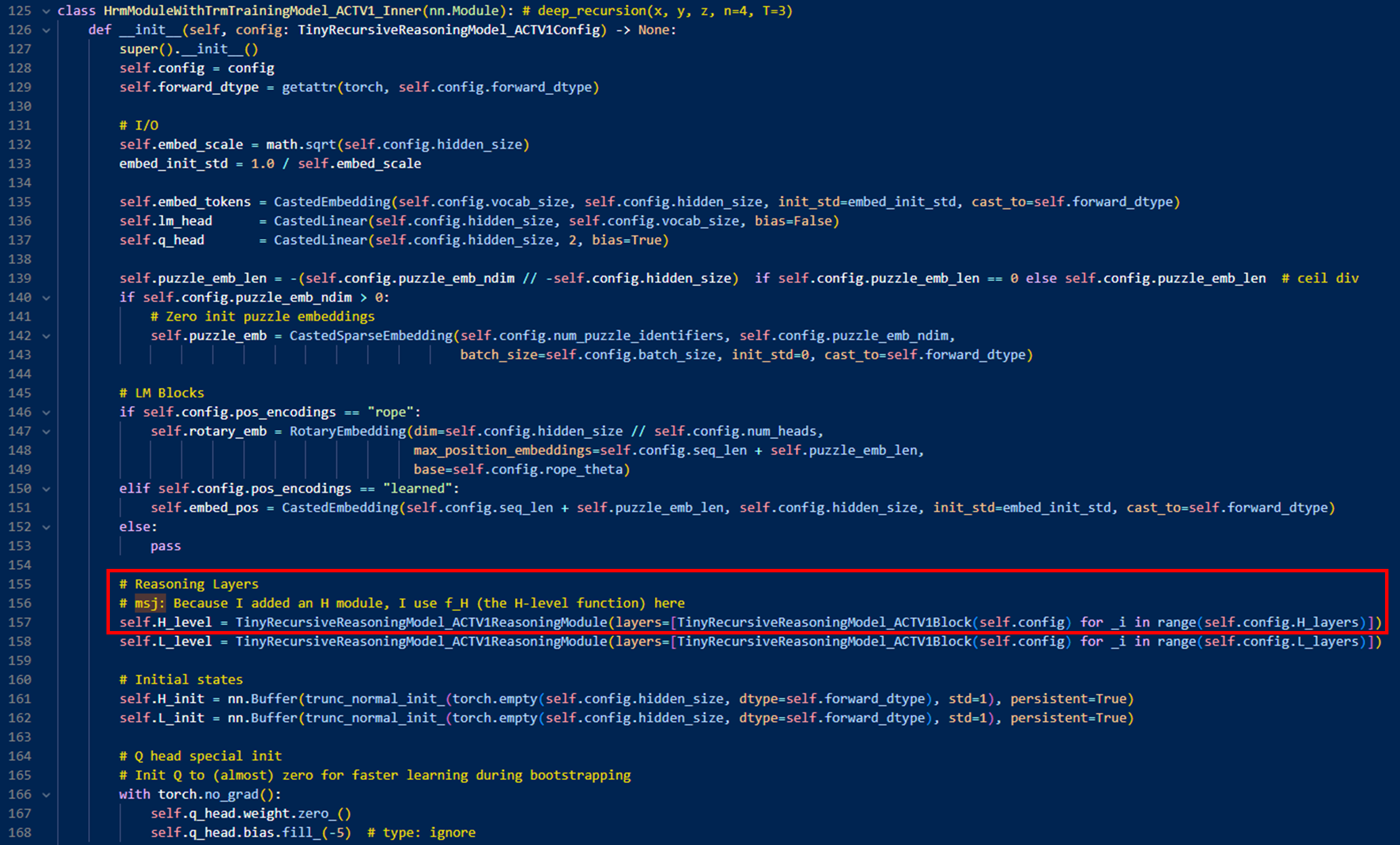
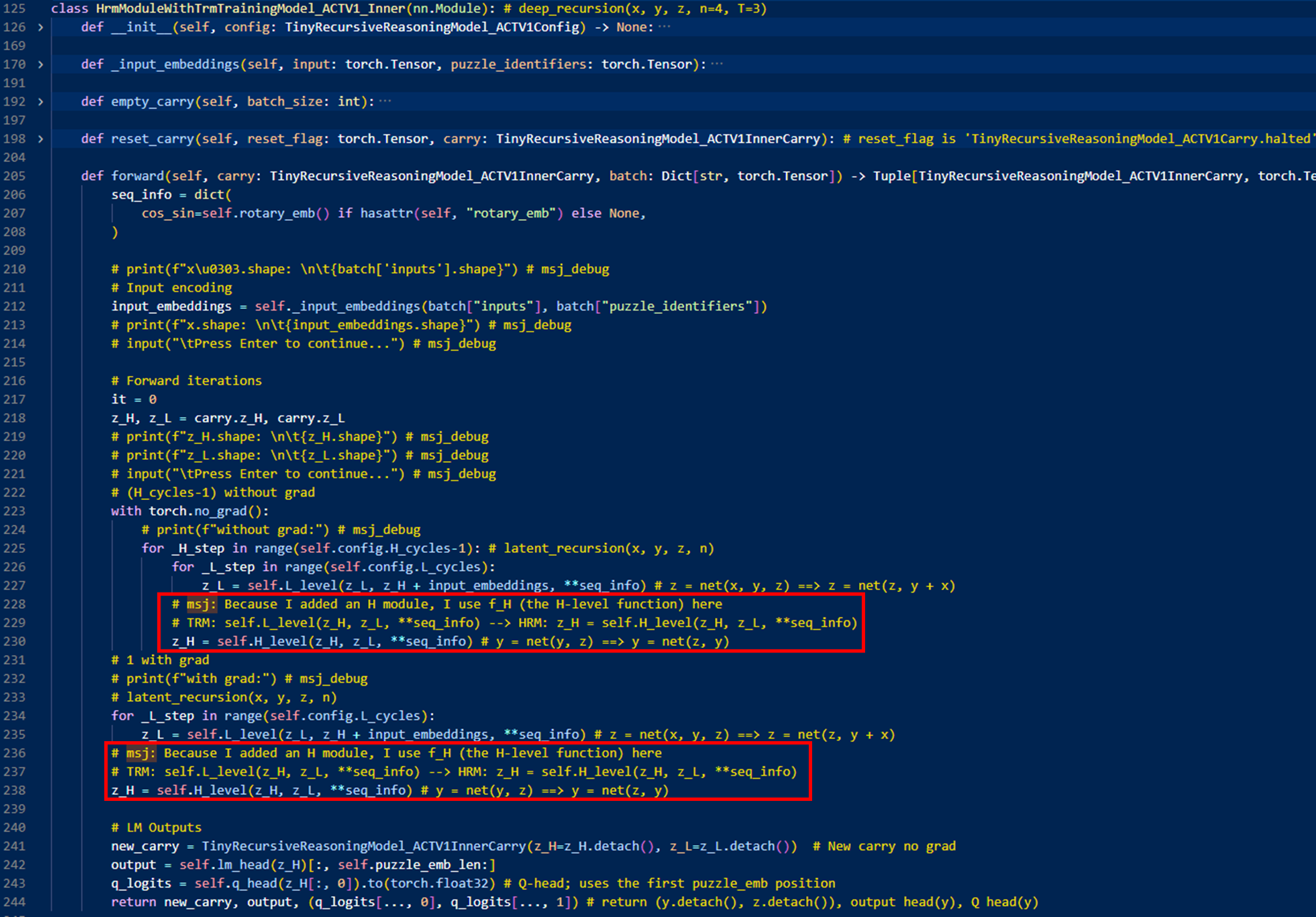
위 name 에서 사용하는 HrmModuleWithTrmTrainingModel_ACTV1은 다음과 같이 작성함(models/recursive_reasoning/hrm_module_with_trm_training.py)
그 결과 다음과 같은 all_config.yaml이 생성 됨
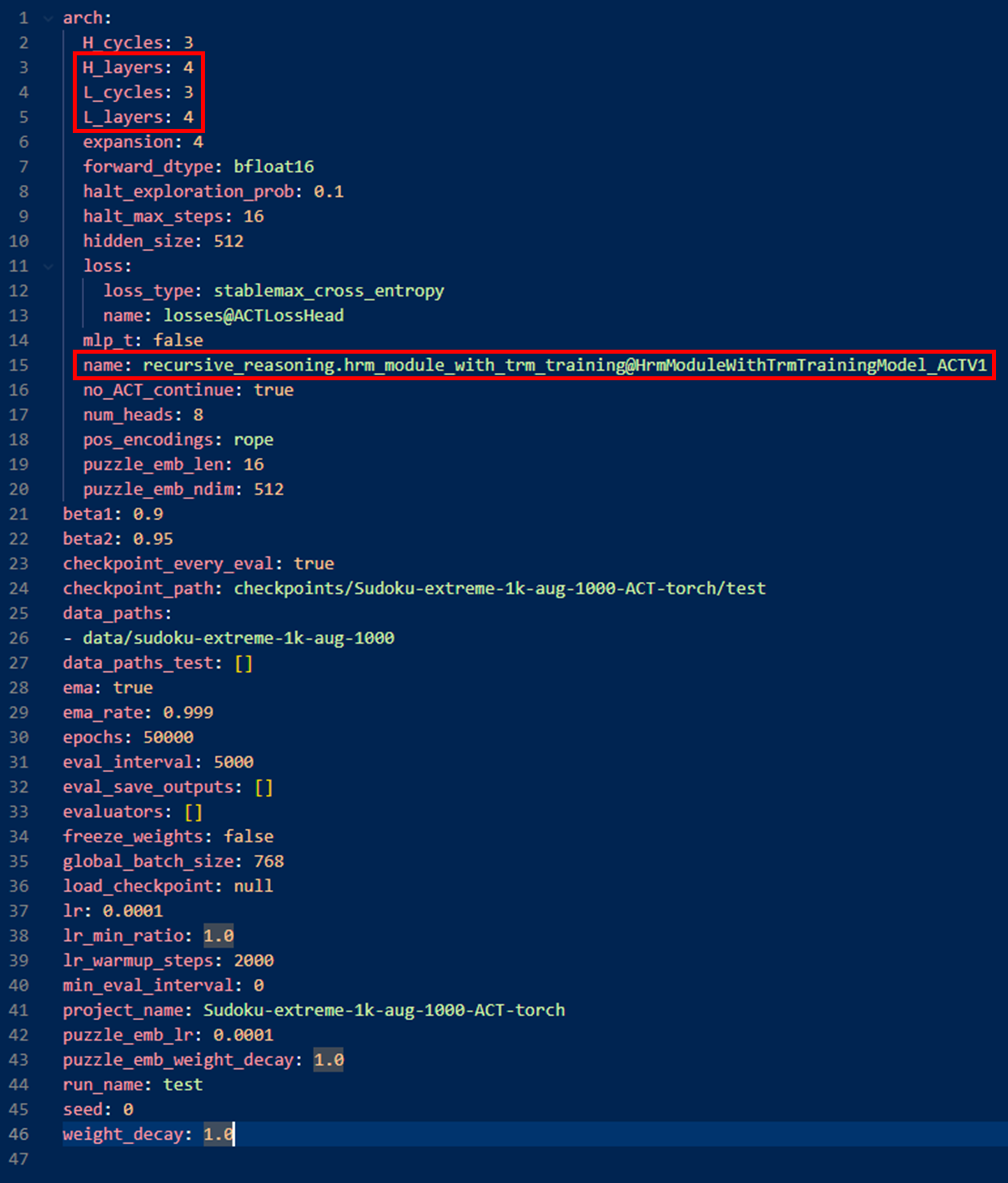
결과 모델:
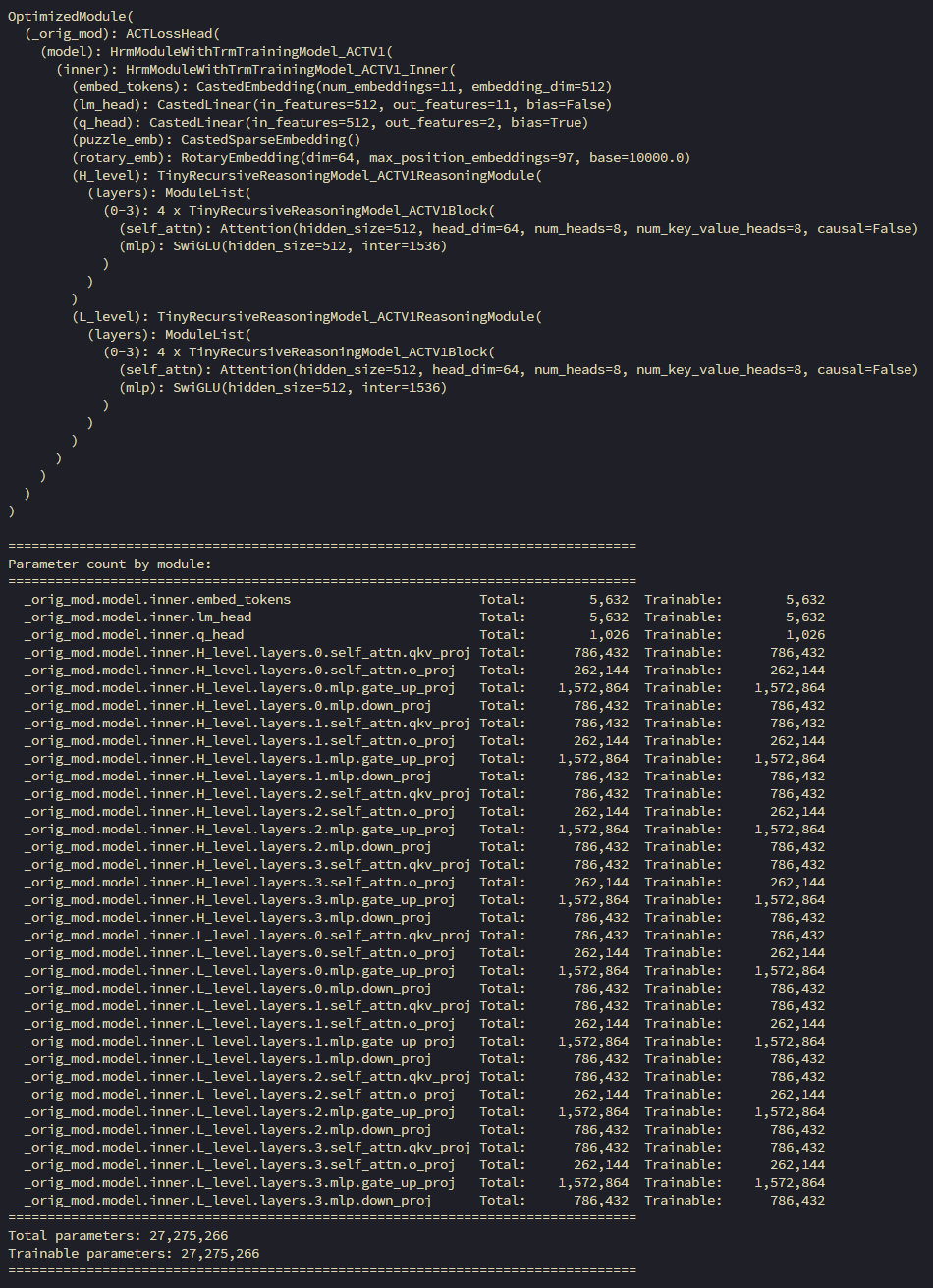
HRM_heavyH_module_with_TRM_training 실험
HRM_heavyL_module_with_TRM_training 실험
2. H module, L module 중 어느 module이 quantization에 더 강건할까?
L module quantization
L_module이 forward pass에서 대다수를 차지한다.
로 로 예시를 들면,
에서 H module 횟수 : L module 횟수 = 1 : 3 임
⇒ L module을 quantization 할 때, H module을 quantization 할 때보다 3배 더 빠를 것임
3. EE
EE에 대해 참고할 것
고려사항
우선 제일 먼저, H_module 끝 마다 출력되는 hidden state를 뽑아서,
정답과 얼마나 유사한지 가시화 + 유사도 검사
즉, overthinking 여부 검사
⇒ 정답과 거의 유사하거나, 유사도가 높으면, EE 가능성 ↑
+
ACT에서 조기 훈련 종료 통계 조사
- 전체 동안의 inference 시간 대비 중간 분류기(?)로 인한 overhead 비율 조사
- 임계값 설정
- 훈련법 설정
- 신뢰도 정의
- 일반화 가능성
일반적으로 임계값은 dataset-dependent함
하지만 내 실험에서는 크게 신경 안써도 ㄱㅊ을 것 같은 이유가 애초에 sudoku가 너무 domain-specific 함
만약 다른 일반적인 task에 대해서 모델을 확장한다면,- 임계값 기반 적응: 미지의 도메인에 따라 임계값을 조정함
- 특징 기반 적응: 모든 계층에서 애초에 도메인 불변 특징을 학습하는 것
